Downloaded 10 times








































![B.get(X)
Affinity: K -> shard -> [Node]](https://image.slidesharecdn.com/4-171116105706/85/Apache-Ignite-Persistence-Persistence-In-Memory-GridGain-44-320.jpg)





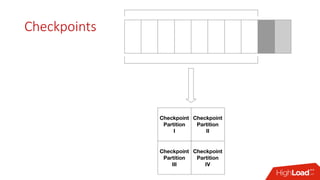






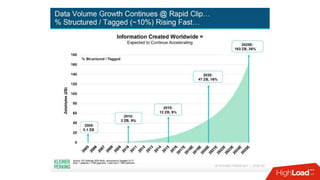
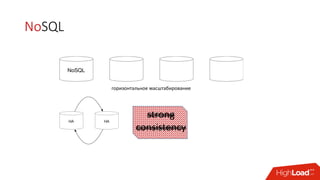
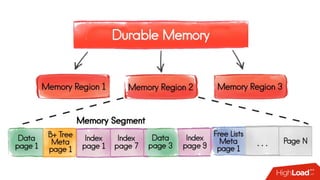
Документ обсуждает необходимость и преимущества обеспечения постоянства данных для in-memory технологий, таких как Apache Ignite, в условиях роста объемов данных. Описываются способы масштабирования вычислительных мощностей и эффективные подходы к хранению и обработке данных, включая использование распределенных SQL и архитектуры памяти. Также рассматриваются особенности работы Apache Ignite, в том числе наличие полной транзакционности и возможности обработки данных на разных уровнях хранения.













































