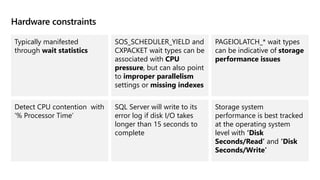
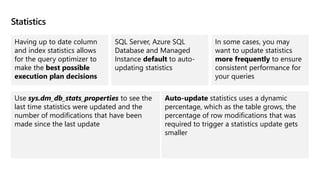
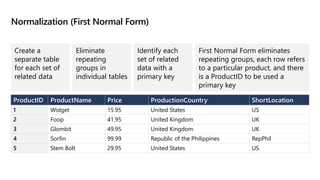
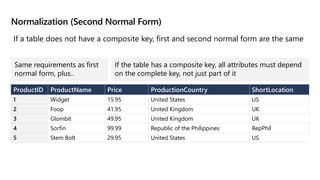
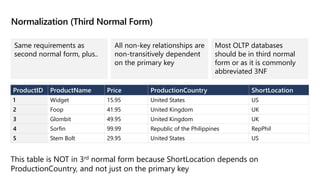
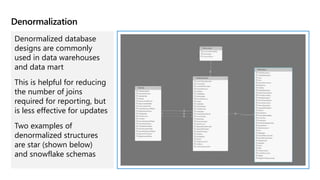
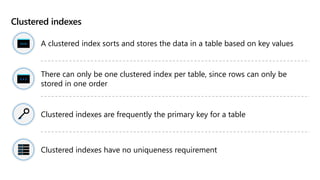
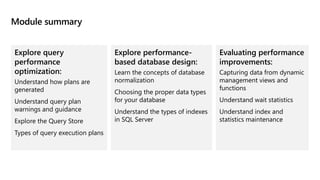
This document provides an overview of Module 5: Optimize query performance in Azure SQL. The module contains 3 lessons that cover analyzing query plans, evaluating potential improvements, and reviewing table and index design. Lesson 1 explores generating and comparing execution plans, understanding how plans are generated, and the benefits of the Query Store. Lesson 2 examines database normalization, data types, index types, and denormalization. Lesson 3 describes wait statistics, tuning indexes, and using query hints. The lessons aim to help administrators optimize query performance in Azure SQL.












![Example: SQL query with a JOIN clause
SELECT [stockItemName],
[UnitPrice] * [QuantityPerOuter] AS CostPerOuterBox,
[QuantityonHand]
FROM [Warehouse].[StockItems] s
JOIN [Warehouse].[StockItemHoldings] sh ON s.StockItemID = sh.StockItemID
ORDER BY CostPerOuterBox;](https://image.slidesharecdn.com/05dp300t00aoptimize-220921220227-29372cb4/85/05_DP_300T00A_Optimize-pptx-13-320.jpg)