Download as PDF, PPTX



























The document discusses the shift from traditional enterprise computing to cloud computing, emphasizing the differences between elastic and traditional models. It highlights the importance of scaling out rather than scaling up, along with the need for agile practices, self-service, and automation in cloud environments. Key themes include uptime responsibility, failure domains, and the evolution of infrastructure management towards more efficient and flexible solutions.
Introduction to Elastic Cloud concepts and the DevOps Meetup context.
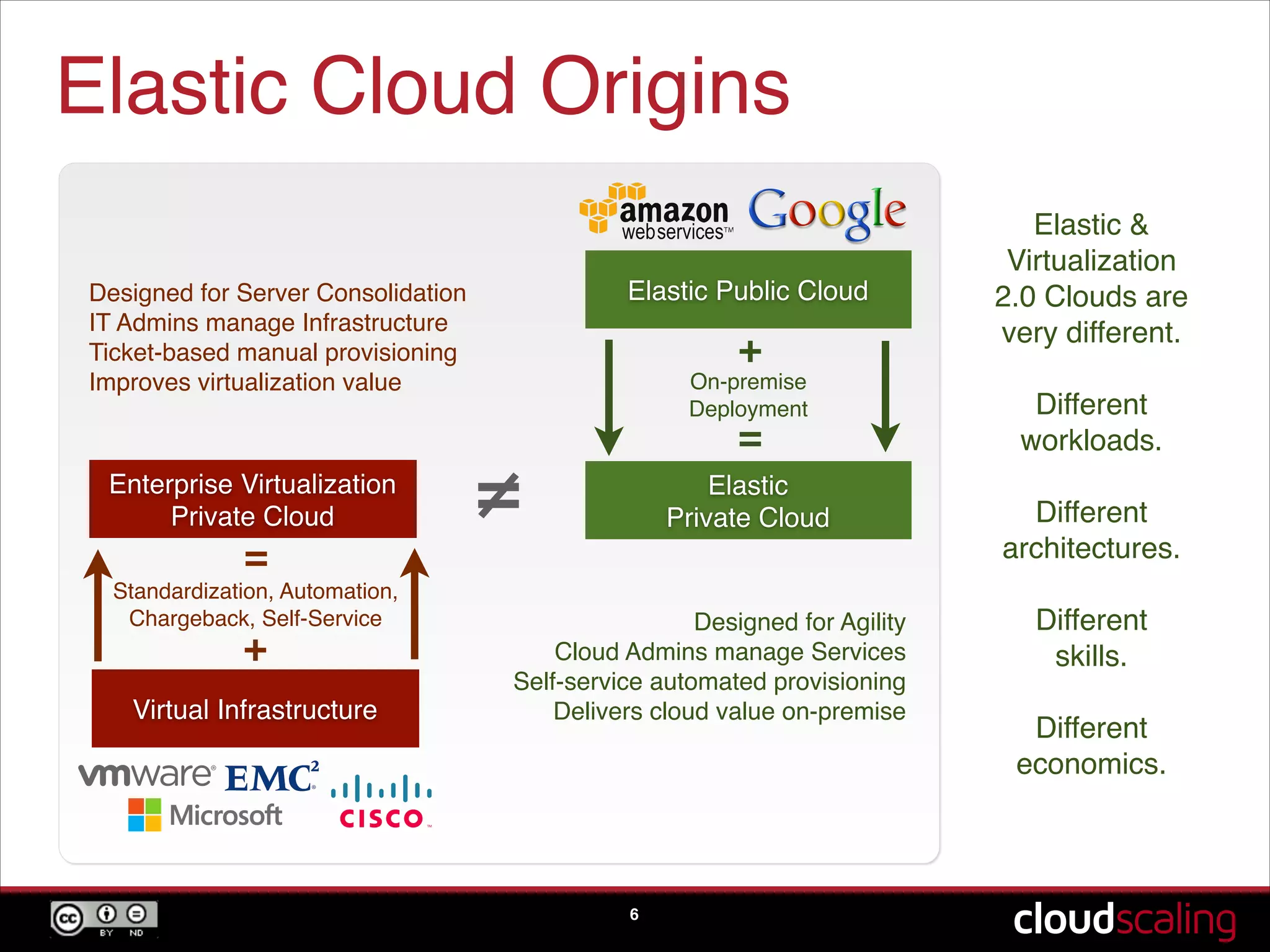
Comparison of traditional enterprise computing with cloud computing, focusing on drive, automation, scale, and flexibility.
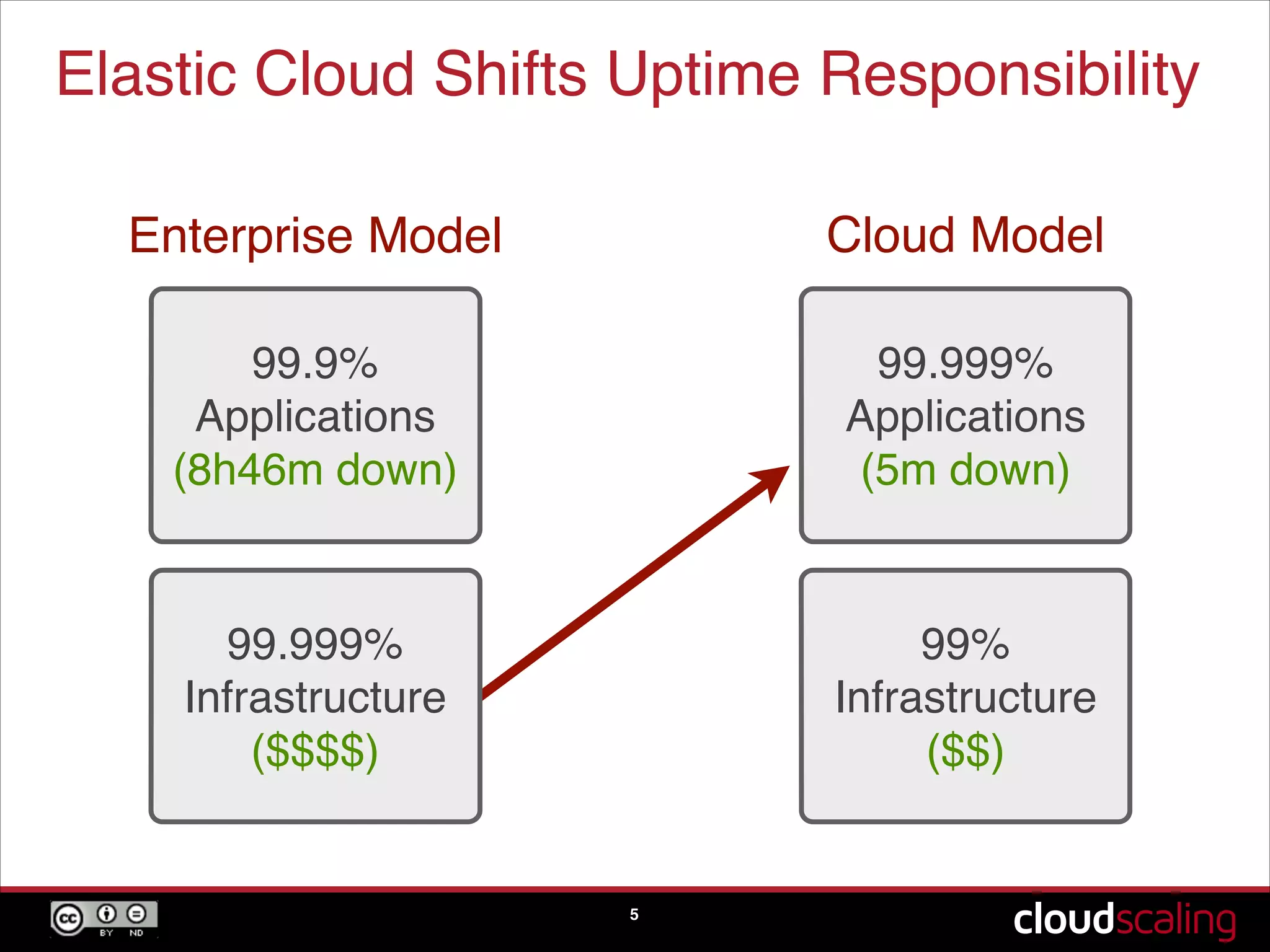
Discussion on uptime responsibilities and differences between enterprise and elastic cloud models regarding failure.
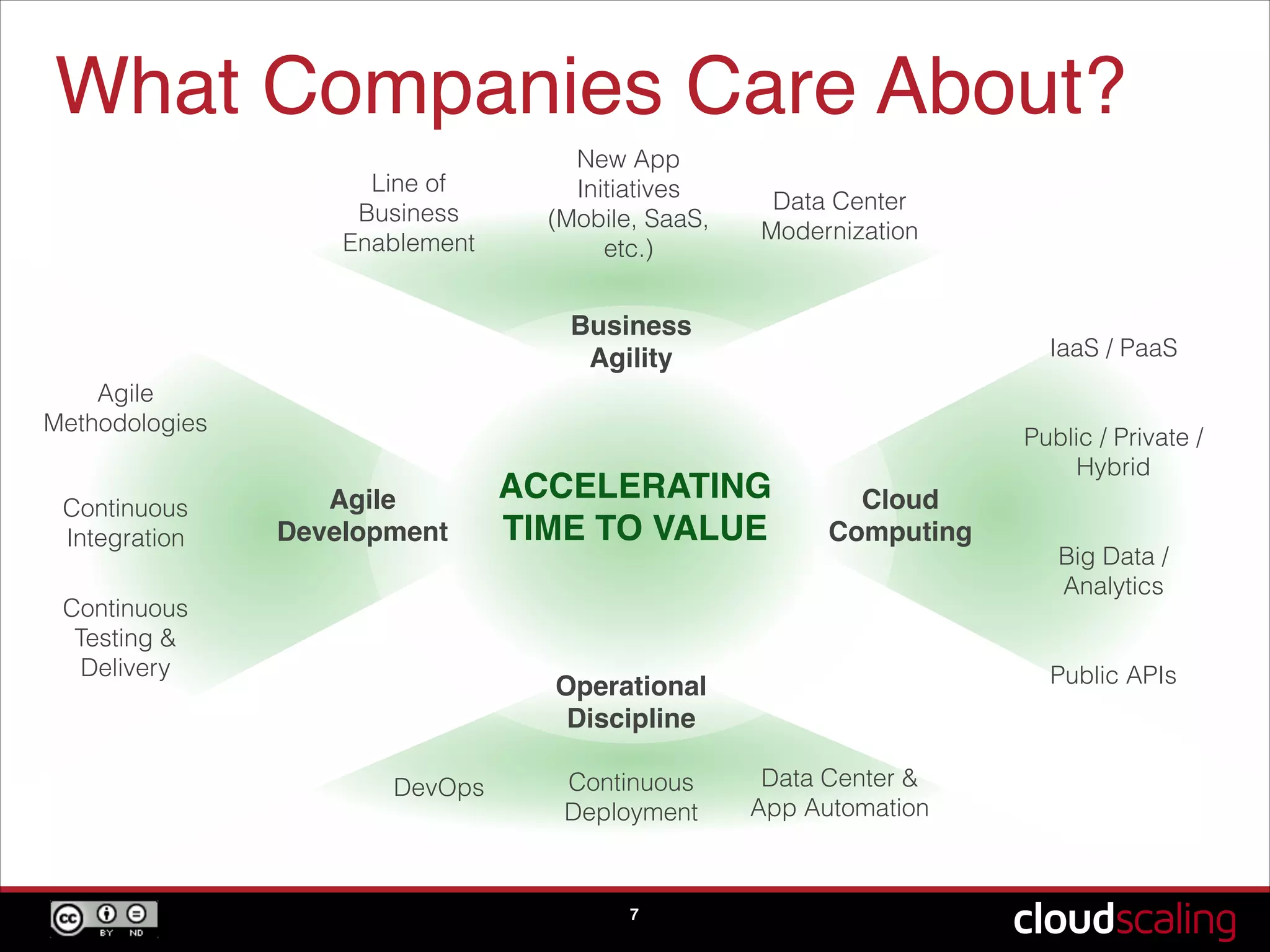
Emphasis on what companies prioritize in cloud computing and the mindset change required for adopting elastic clouds.
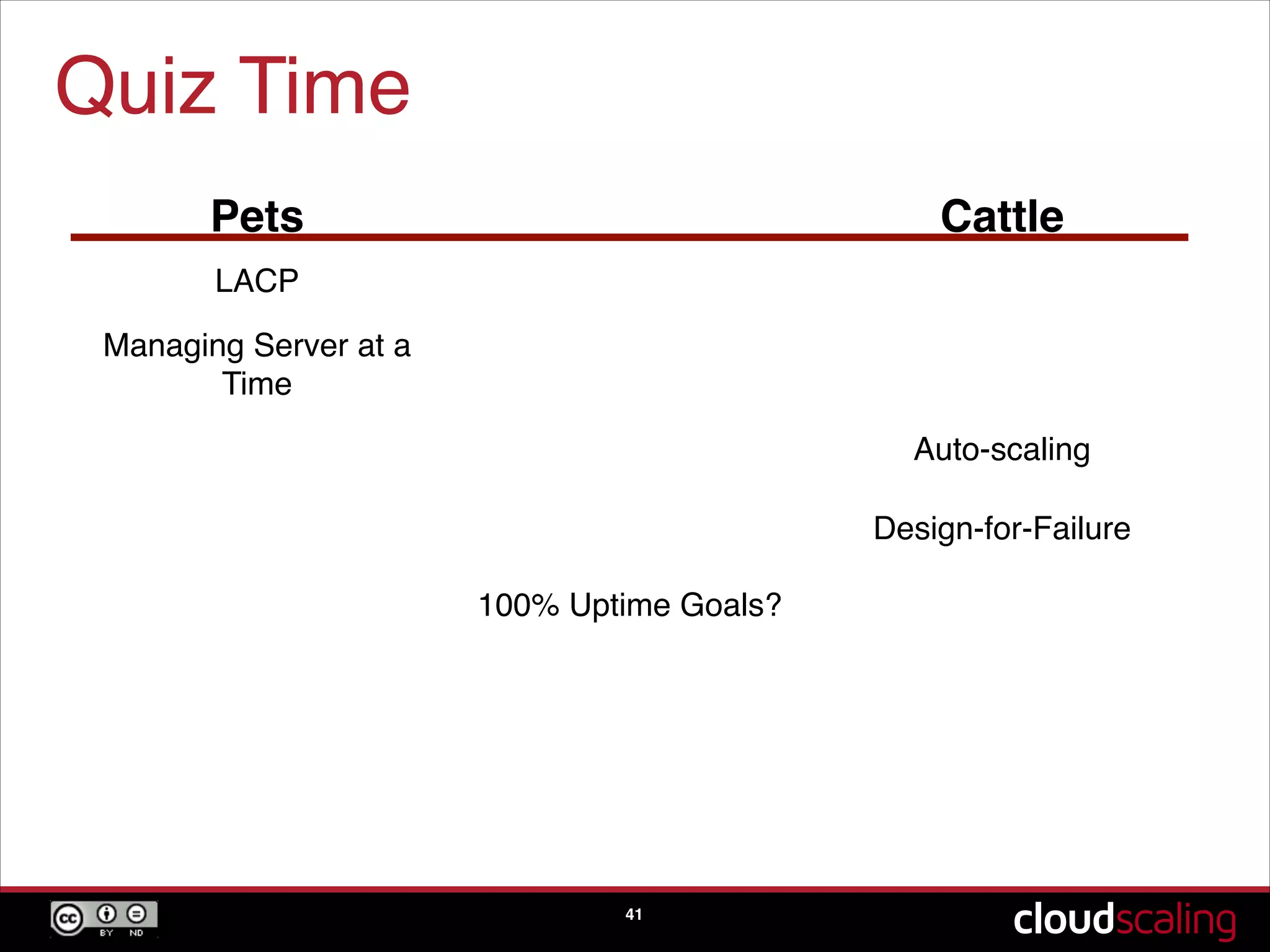
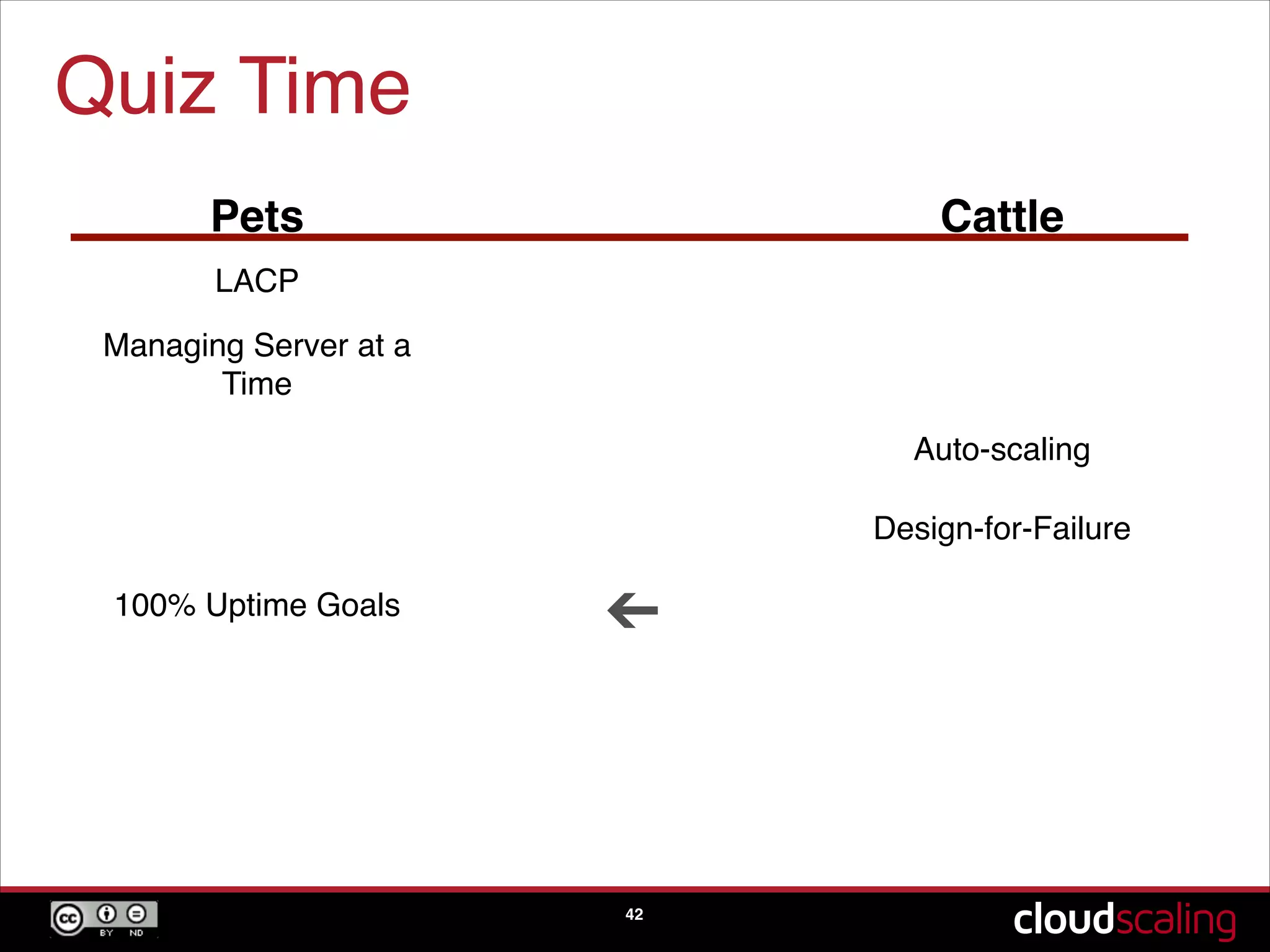
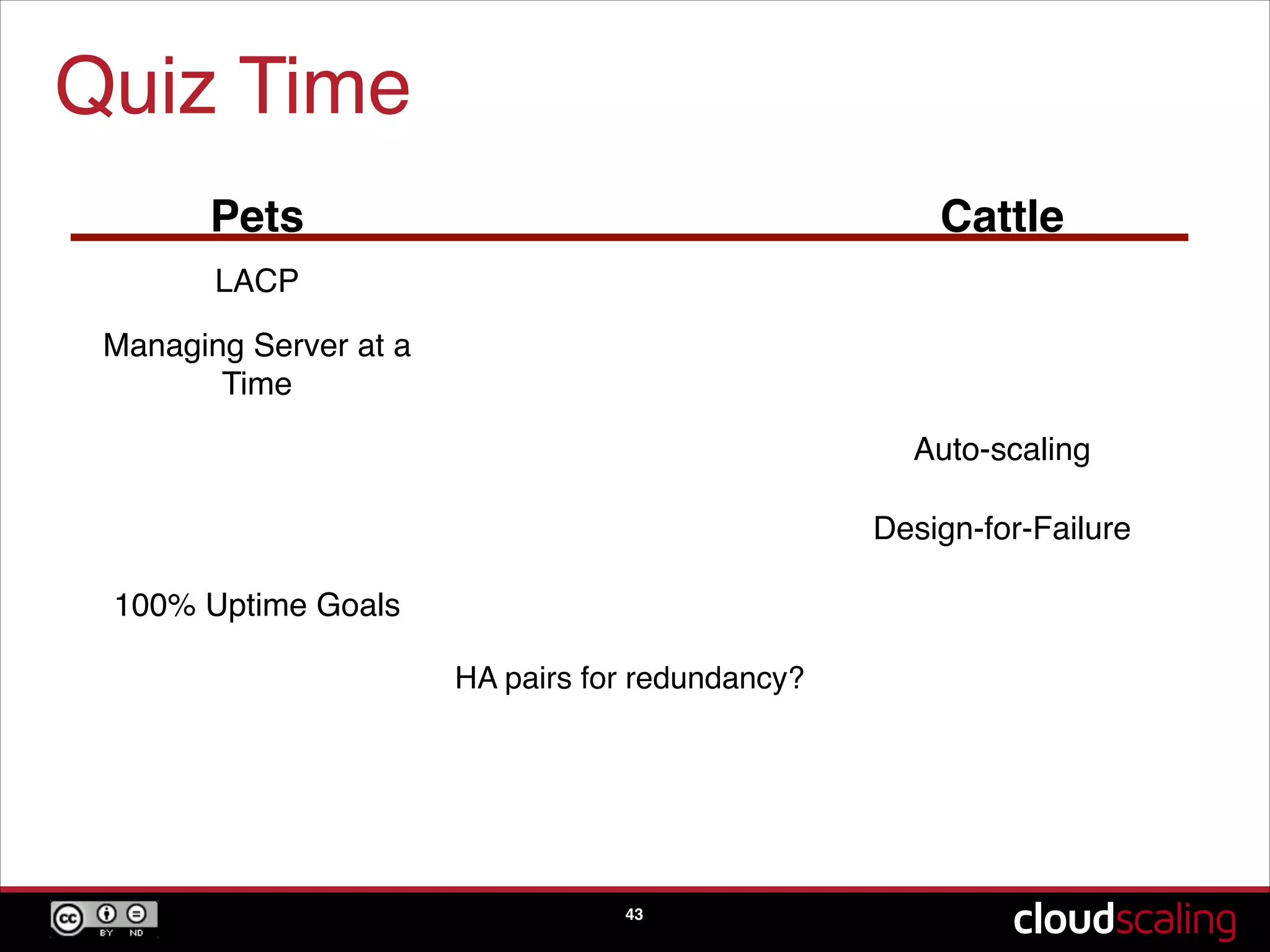
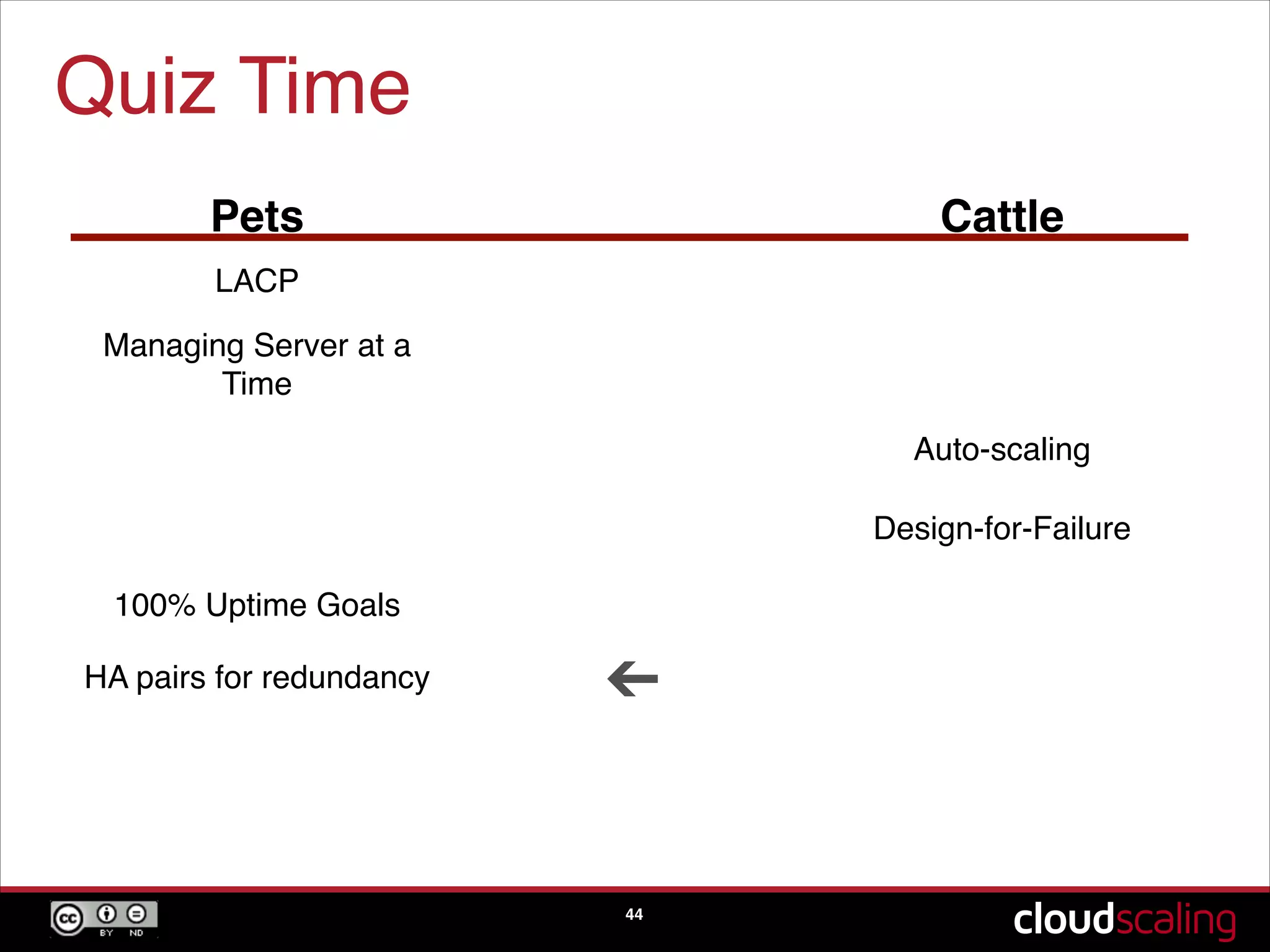
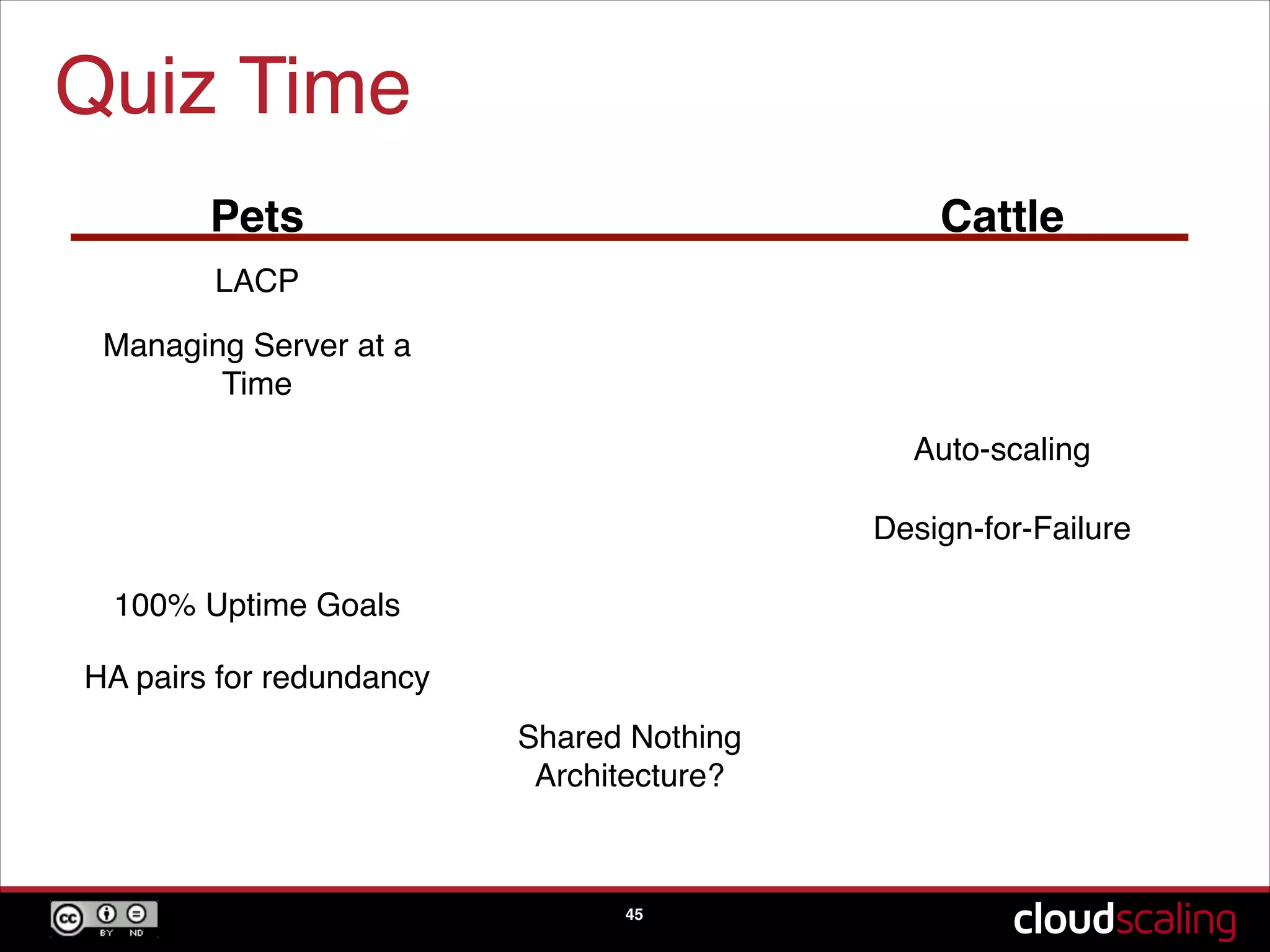
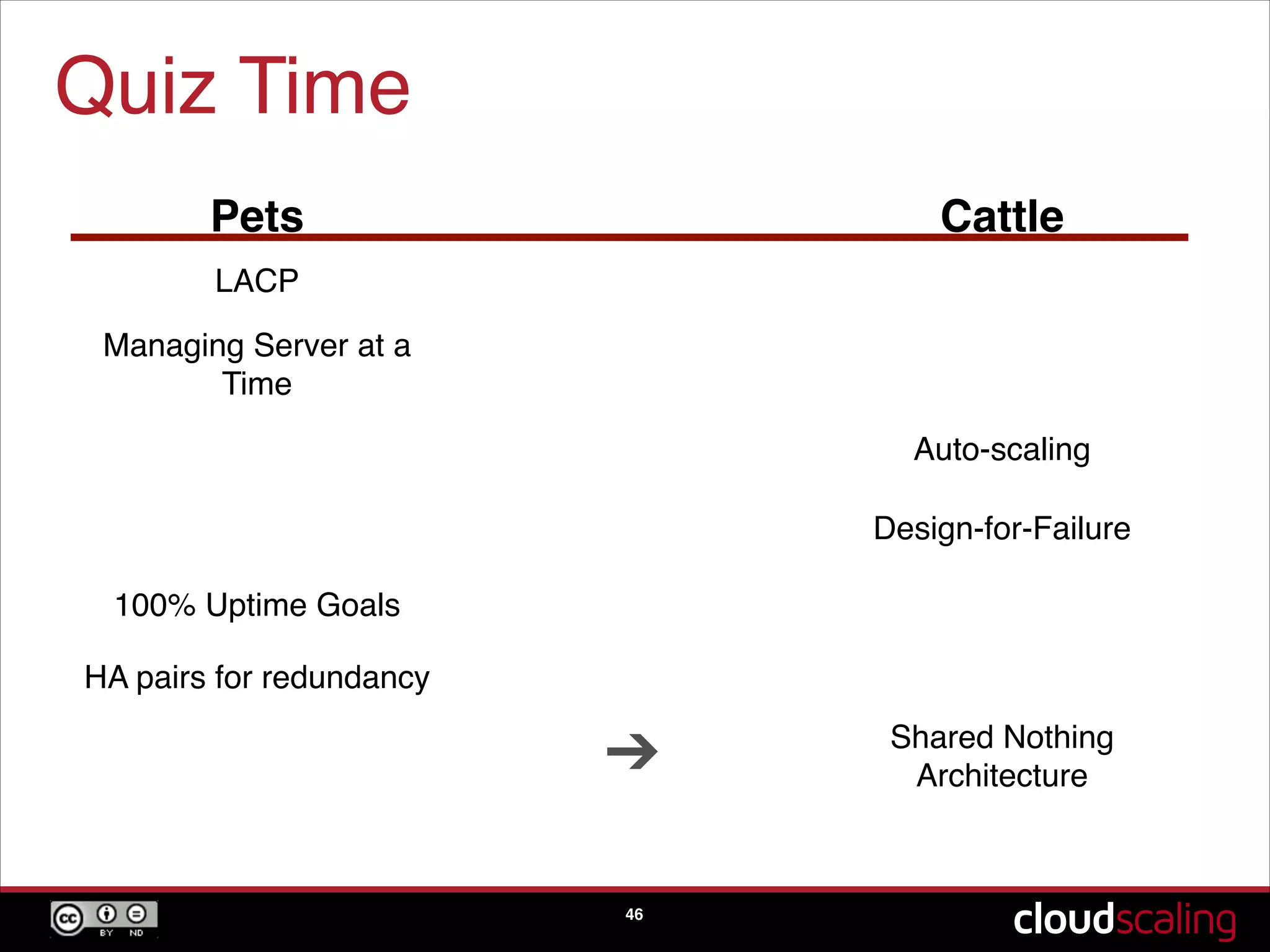
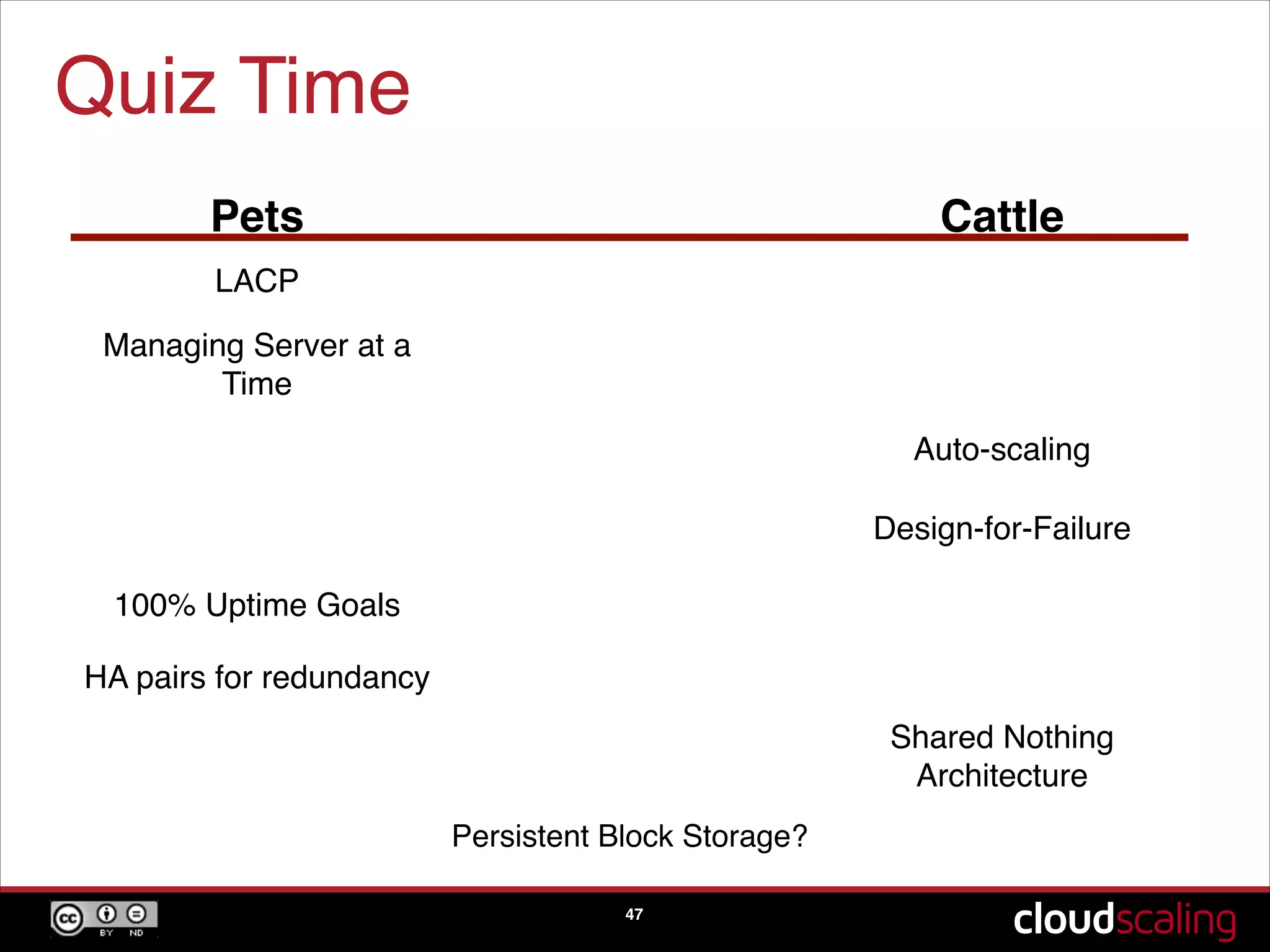
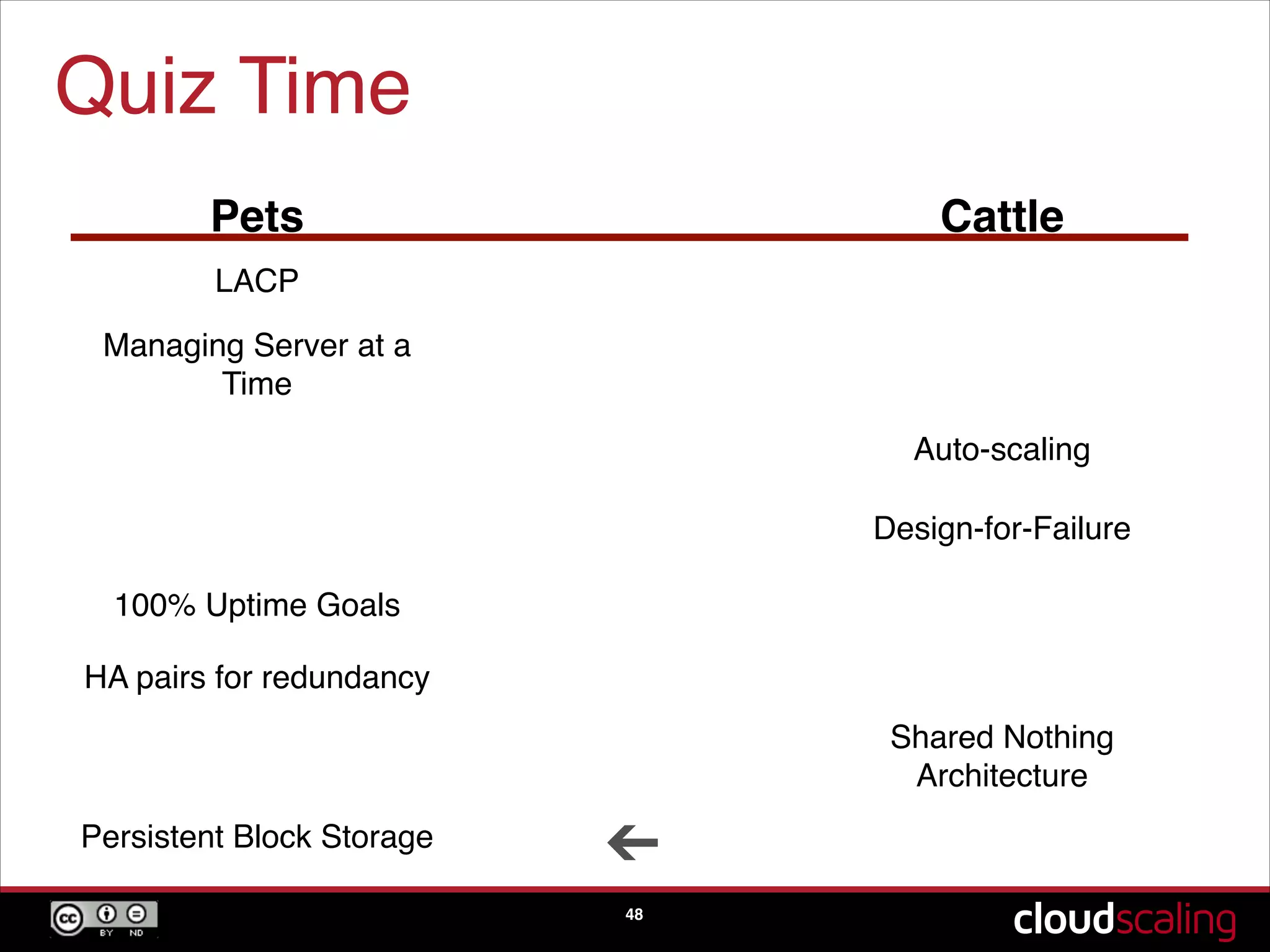
The concept of treating servers as cattle rather than pets to focus on scale and agility in cloud environments.
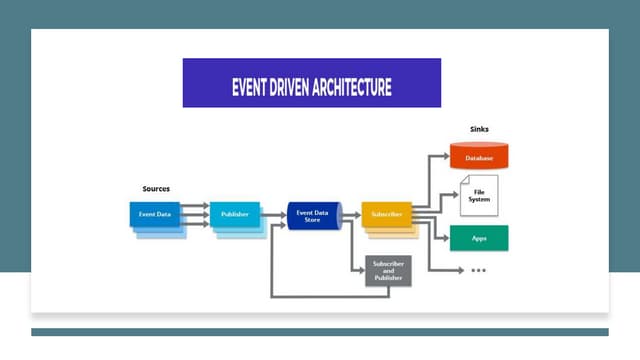
Concept of failure domains; discusses both big and smaller failure domains and the importance of loose coupling.
The significance of open source software in creating flexible, non-lock-in cloud infrastructures and self-management.
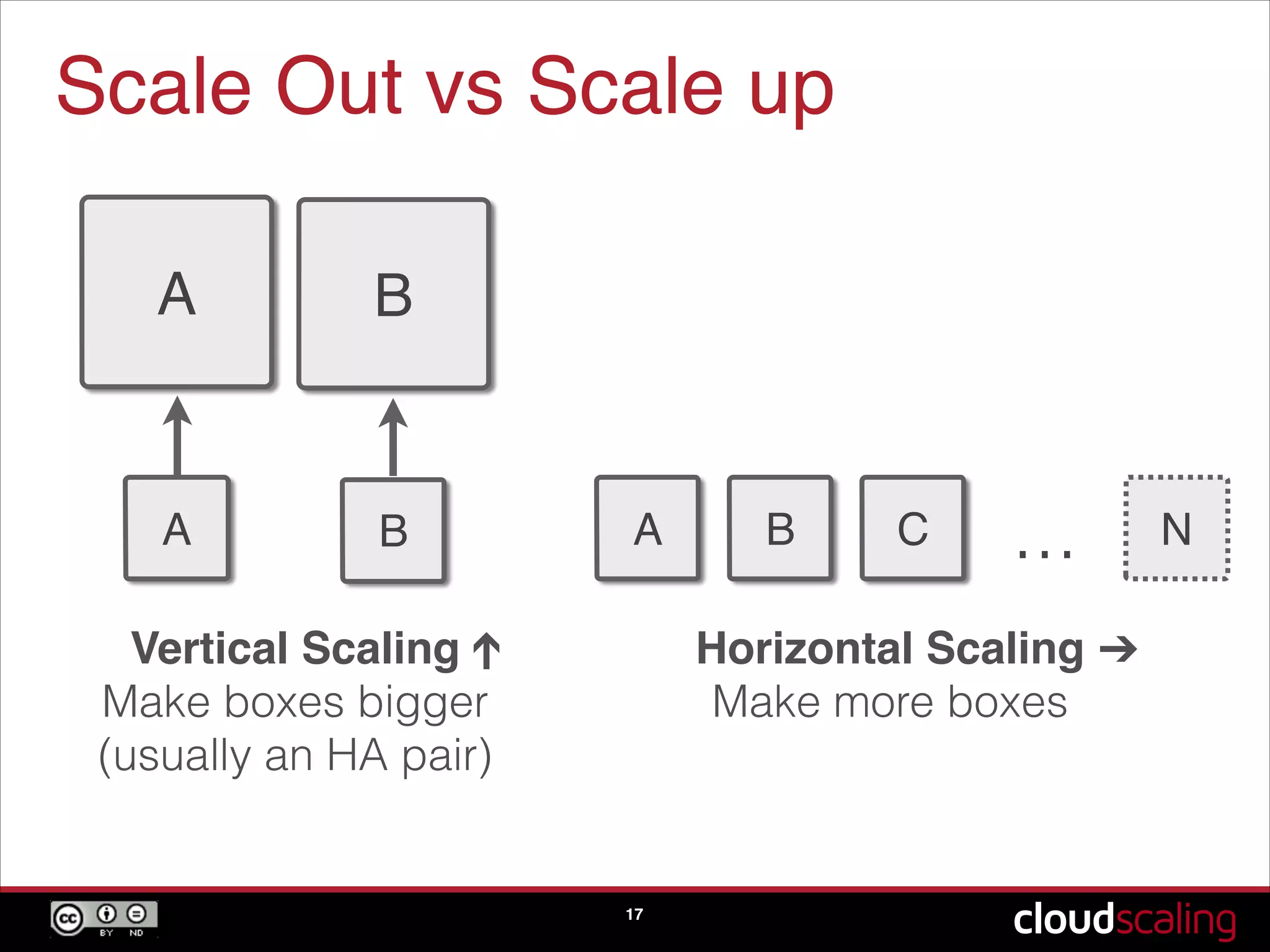
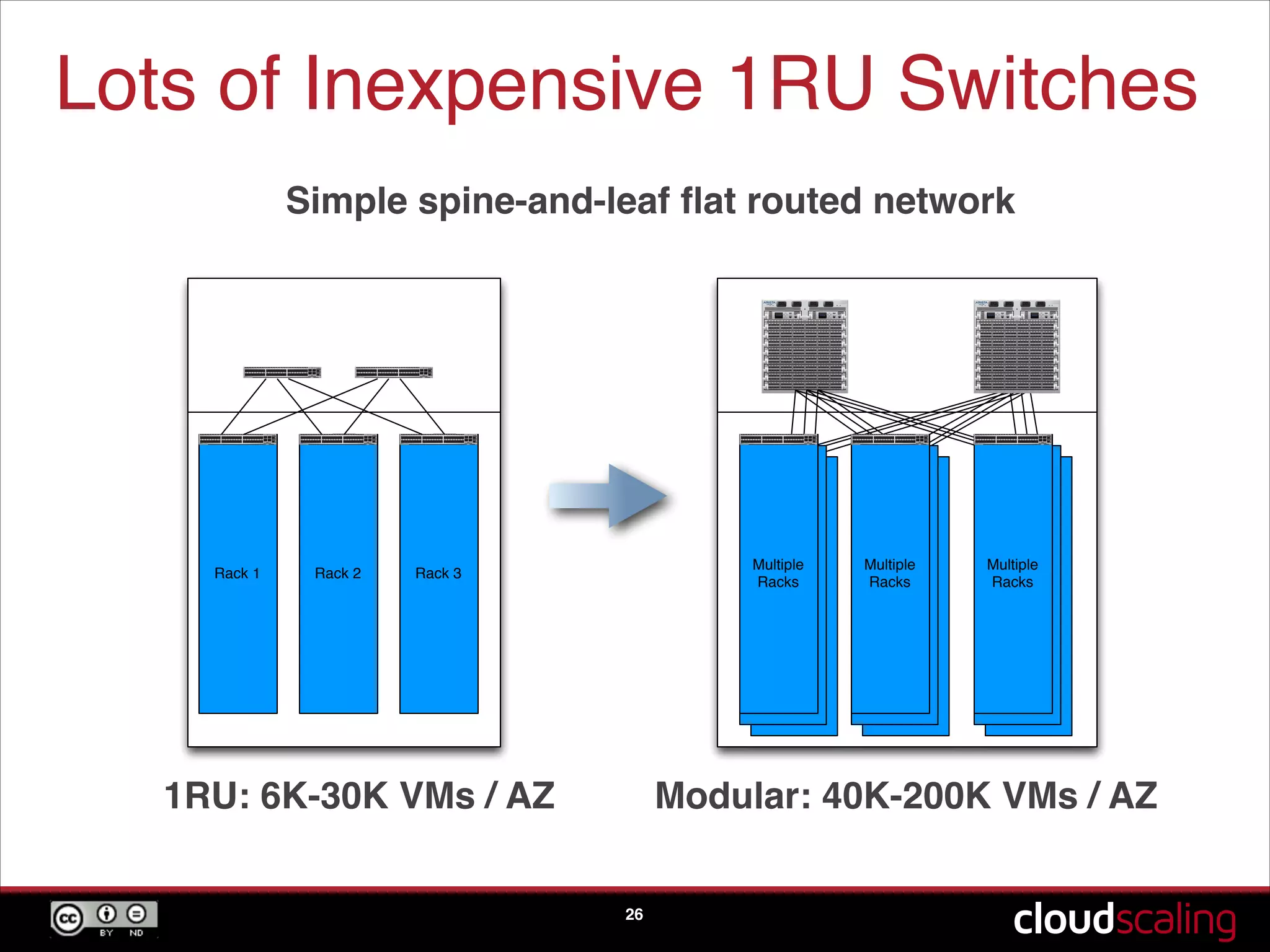
Differences between vertical and horizontal scaling, the operational models of companies buying directly from ODMs.
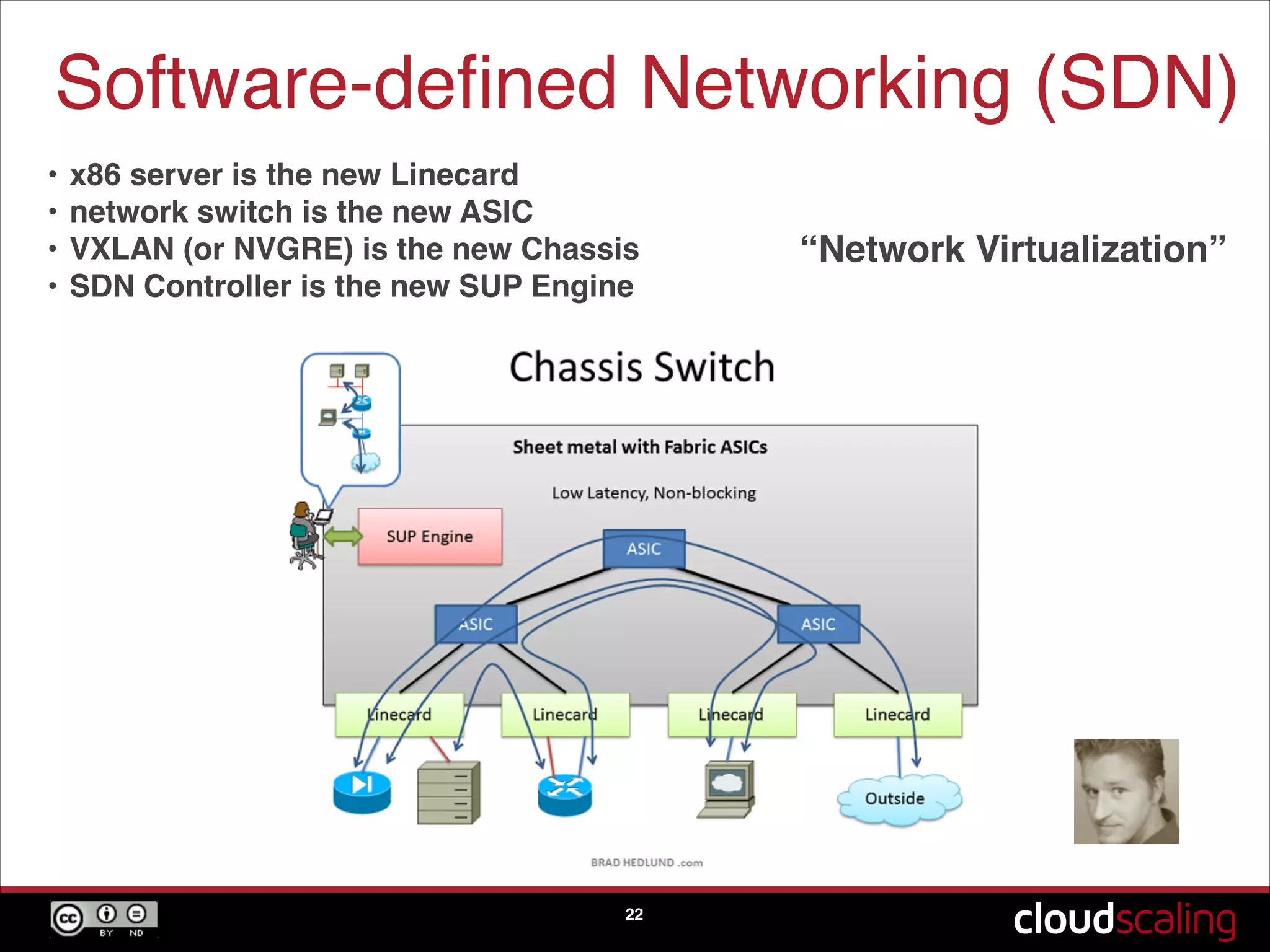
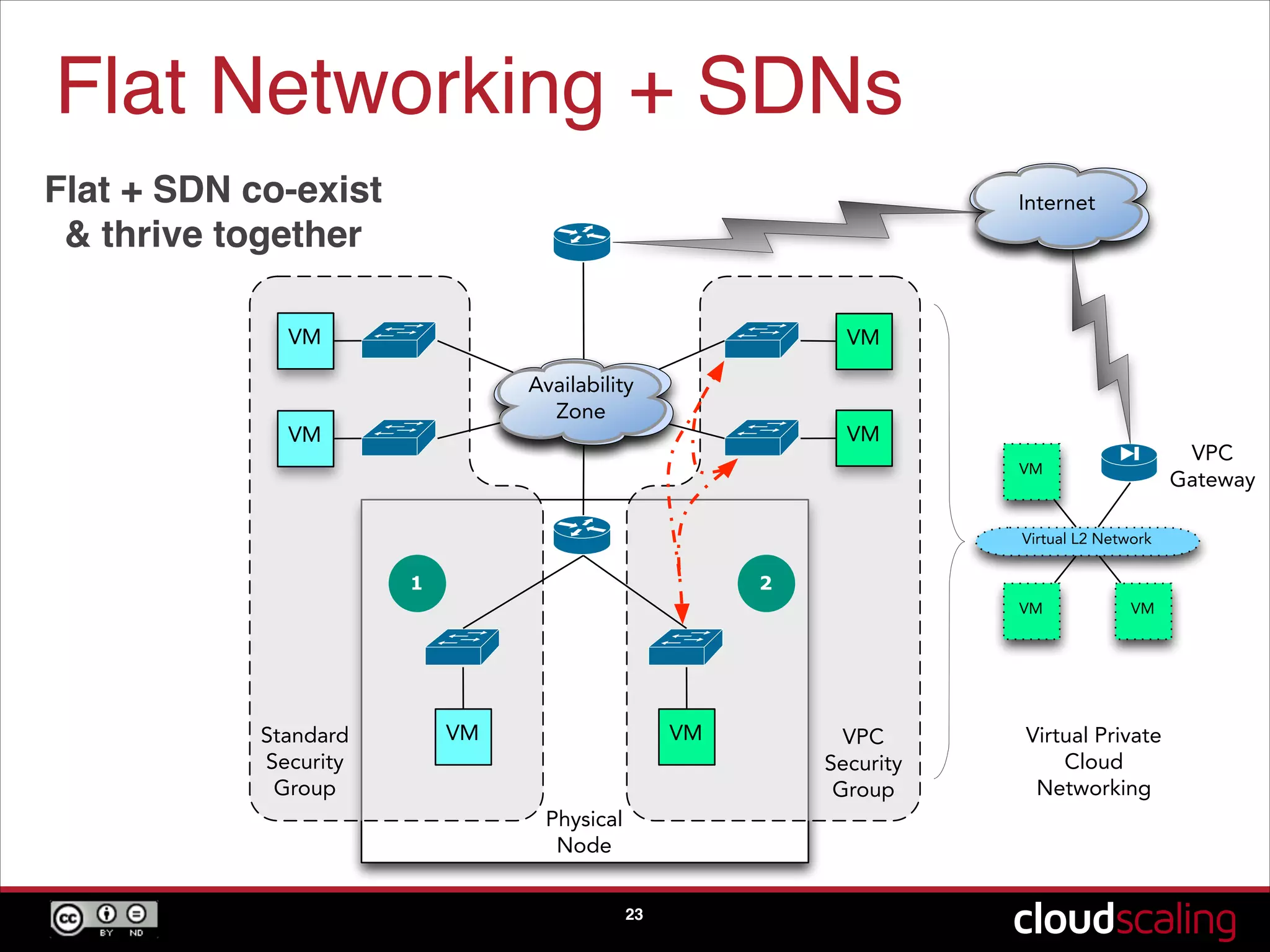
Discussion on networking strategies, including L3 networking and software-defined networking in cloud environments.
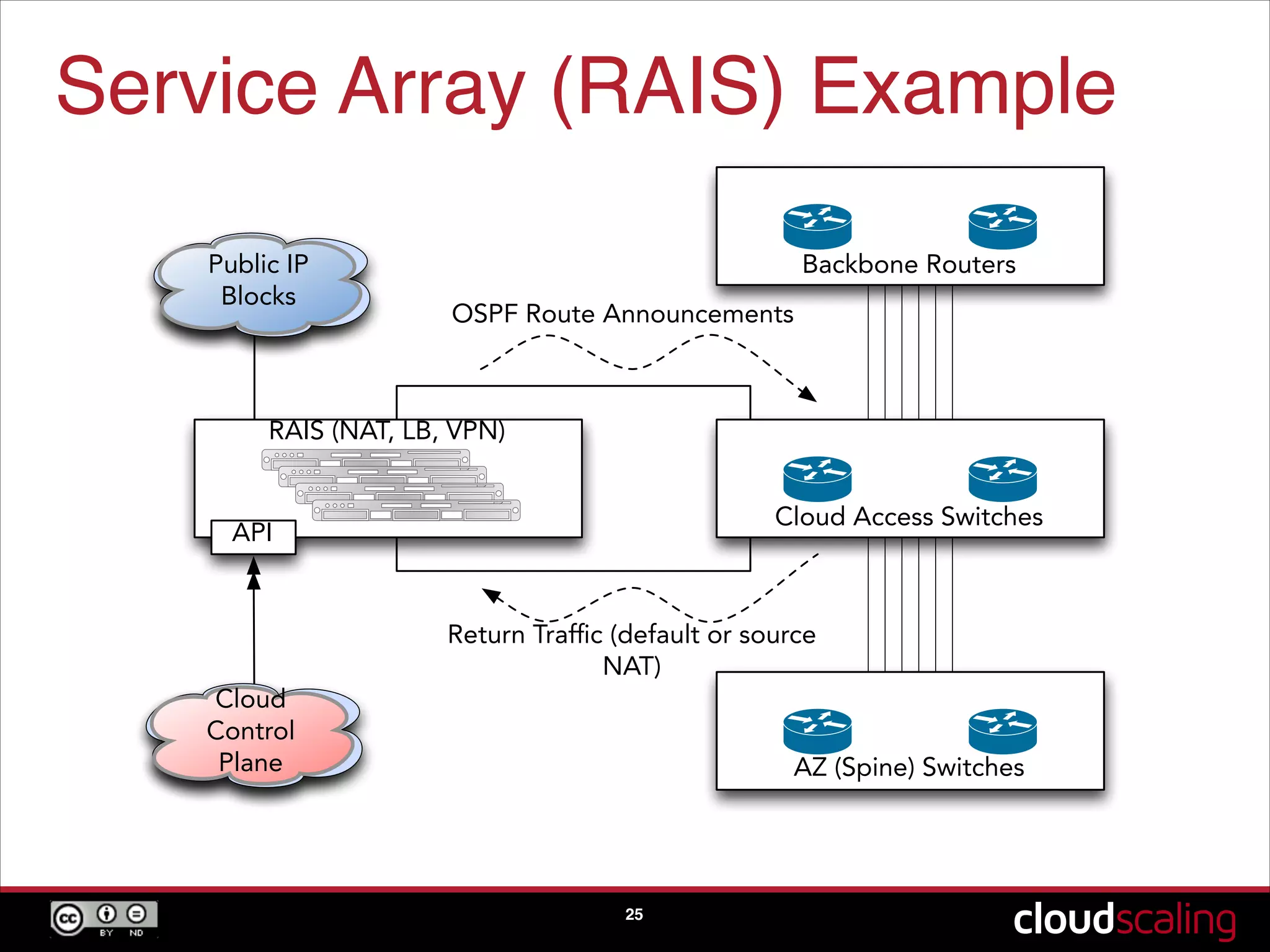
Innovative approaches to redundancy (RAIS) and storage strategies to ensure high availability and minimize failure.
Impact of adding servers on storage I/O, mentions the commoditization of hypervisors and the future direction.
Speculative trends indicating the potential phasing out of hypervisors and moving towards bare metal solutions.A quiz segment reinforcing key concepts discussed about pets versus cattle, scaling, and design-for-failure practices.
Wrap-up with a Q&A session with Randy Bias, allowing for audience interaction and discussion on the topics presented.