Download as PDF, PPTX



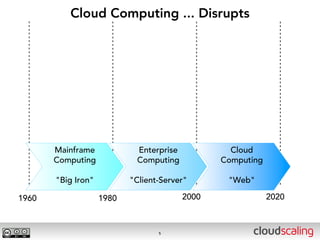
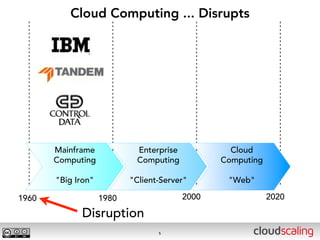
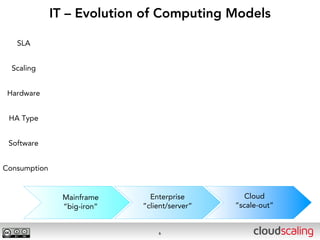
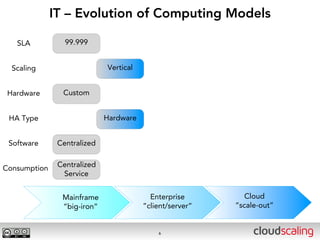
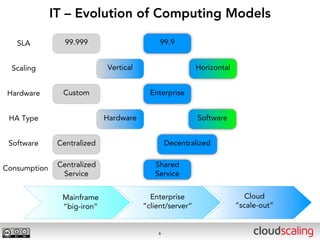
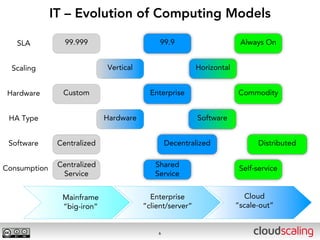


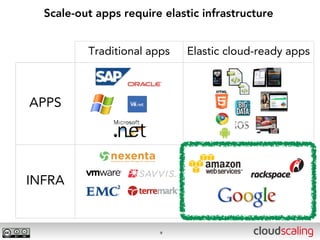
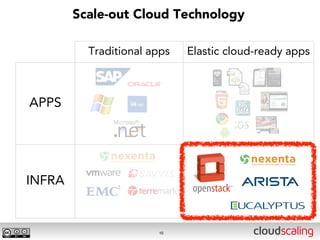
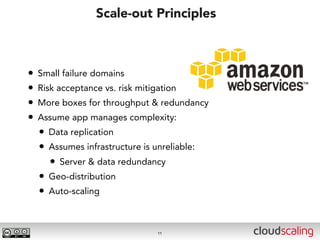

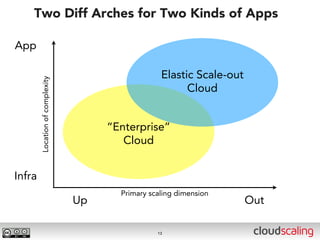

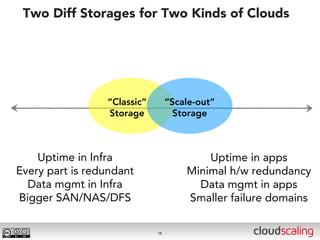
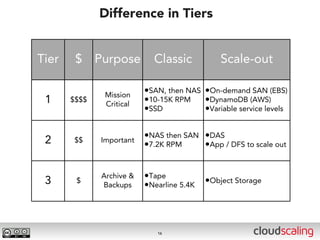

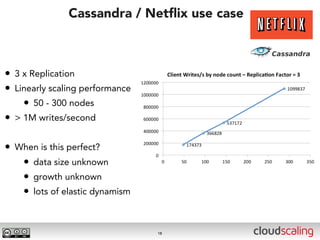





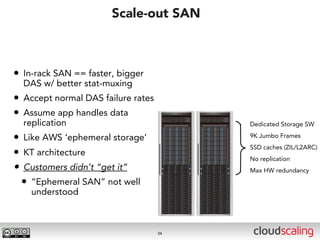
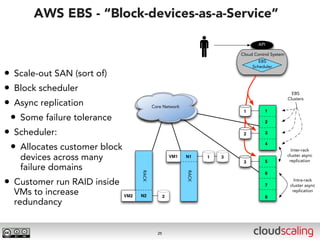
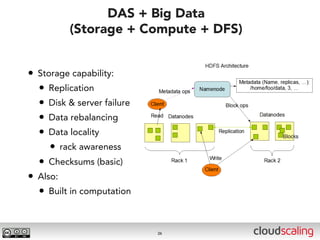
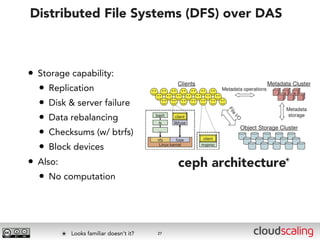

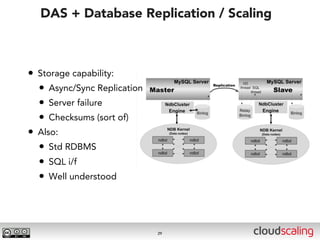
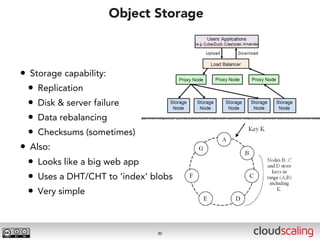






The document discusses the evolution of cloud storage architectures, contrasting traditional 'big-iron' enterprise models with modern elastic scale-out systems that cater to different application needs. It emphasizes the shift in data management from infrastructure to applications and outlines the principles and technologies behind scale-out storage, including the use cases for systems like Cassandra. The conclusion highlights the importance of designing the appropriate storage solutions to effectively support diverse cloud environments.

![[OSDC.tw 2011] The Path to Pass into PaaS -- How We Build the Solution](https://cdn.slidesharecdn.com/ss_thumbnails/osdc-tw-2011-thepathtopassintopaas-110326213502-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









