Download as PDF, PPTX






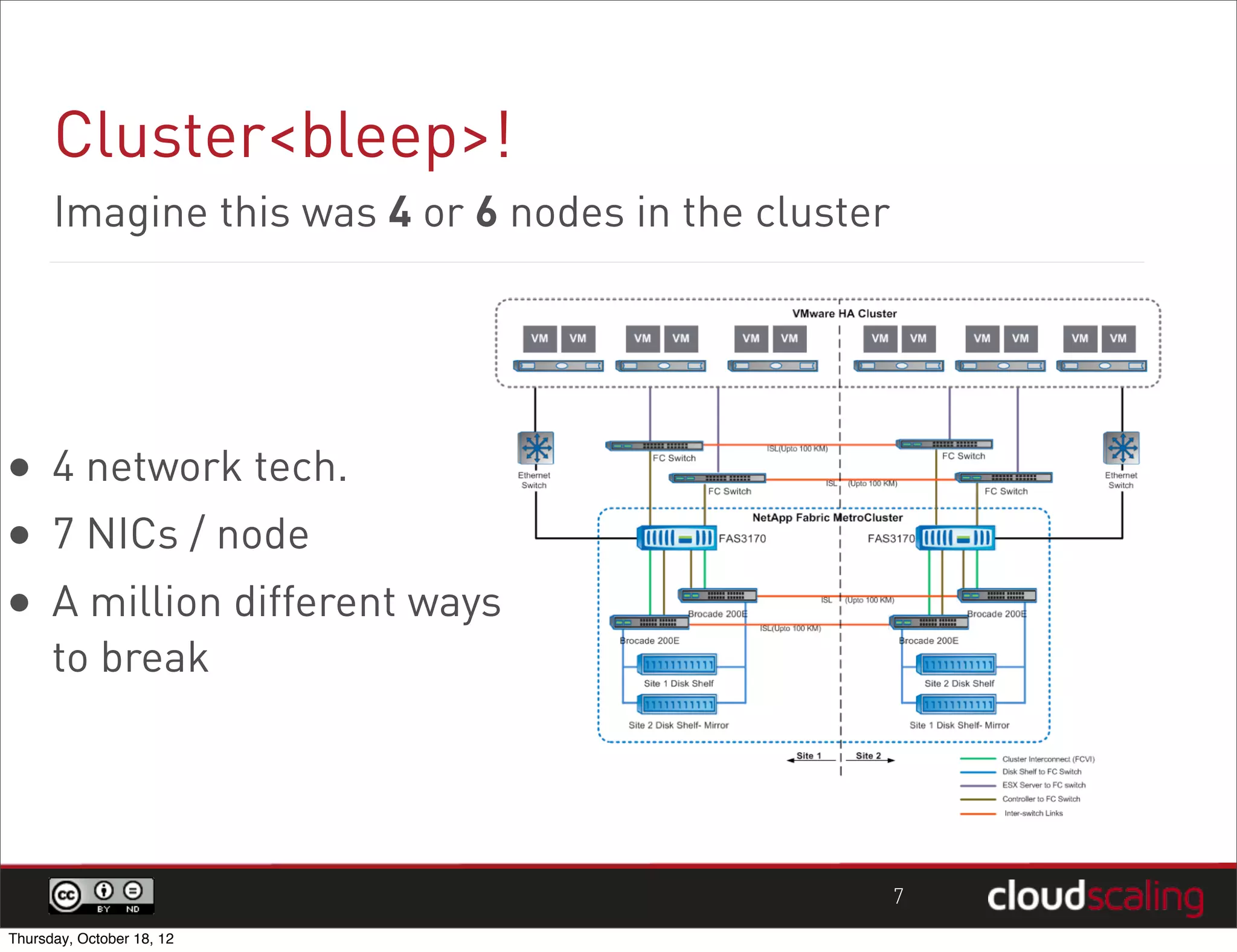



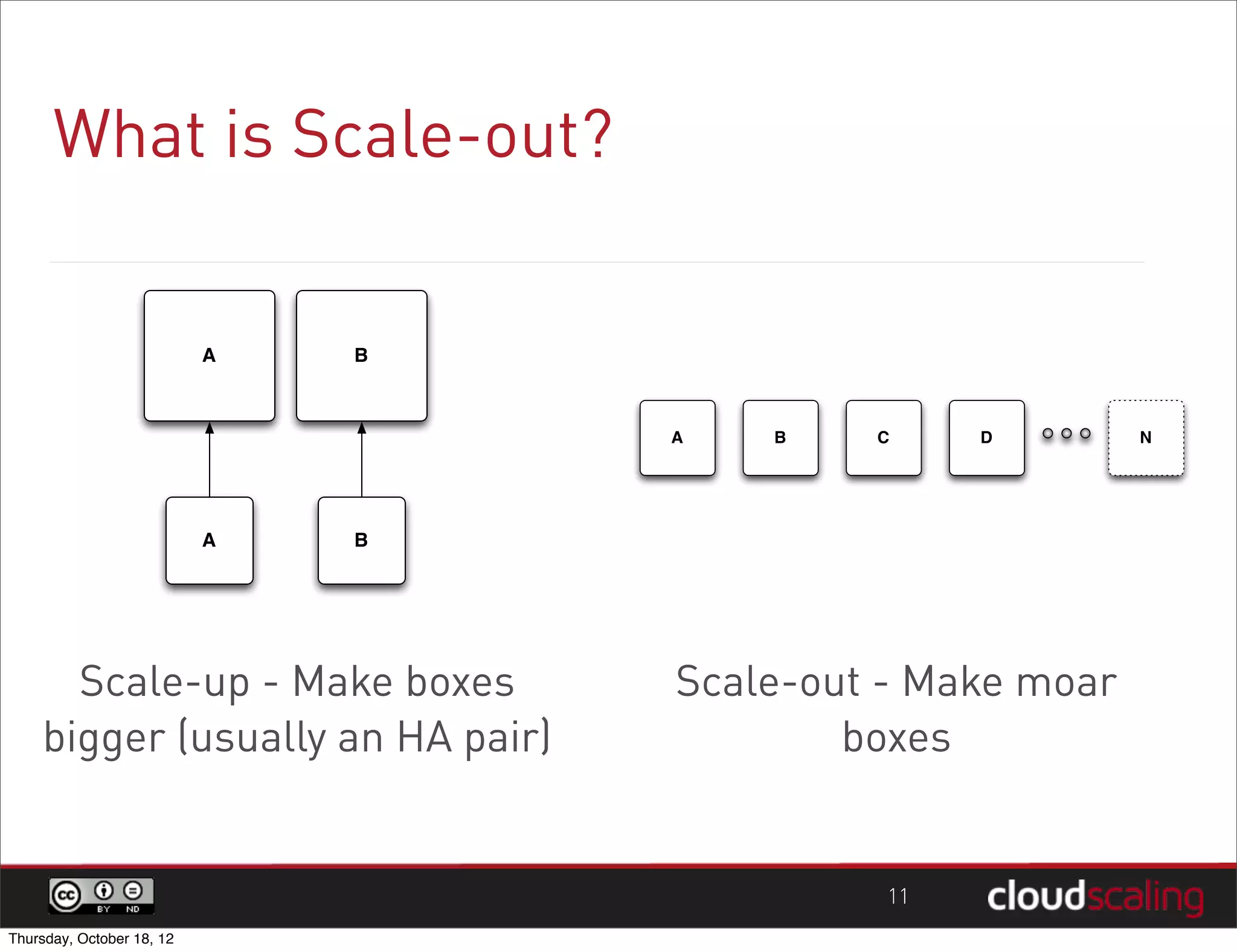

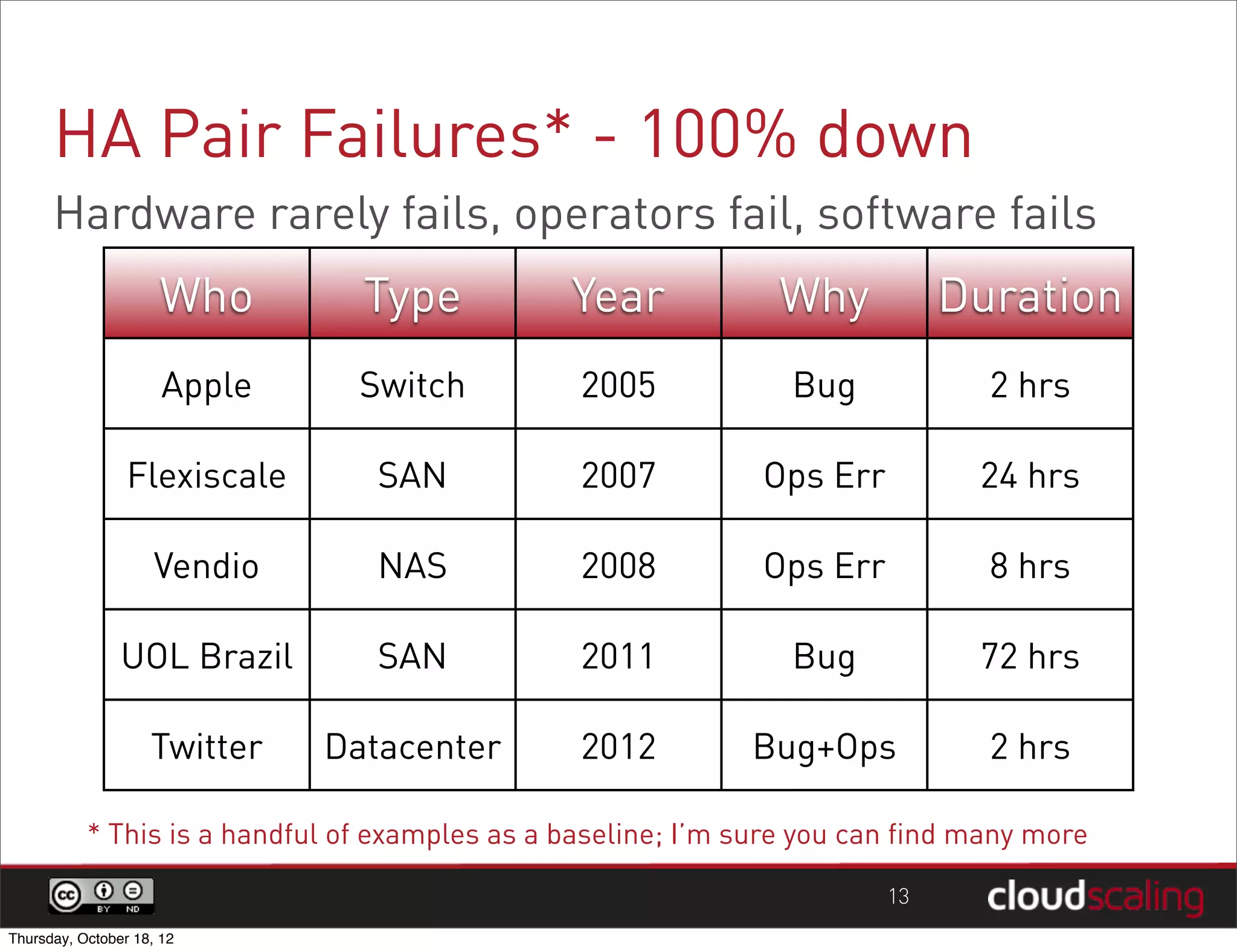



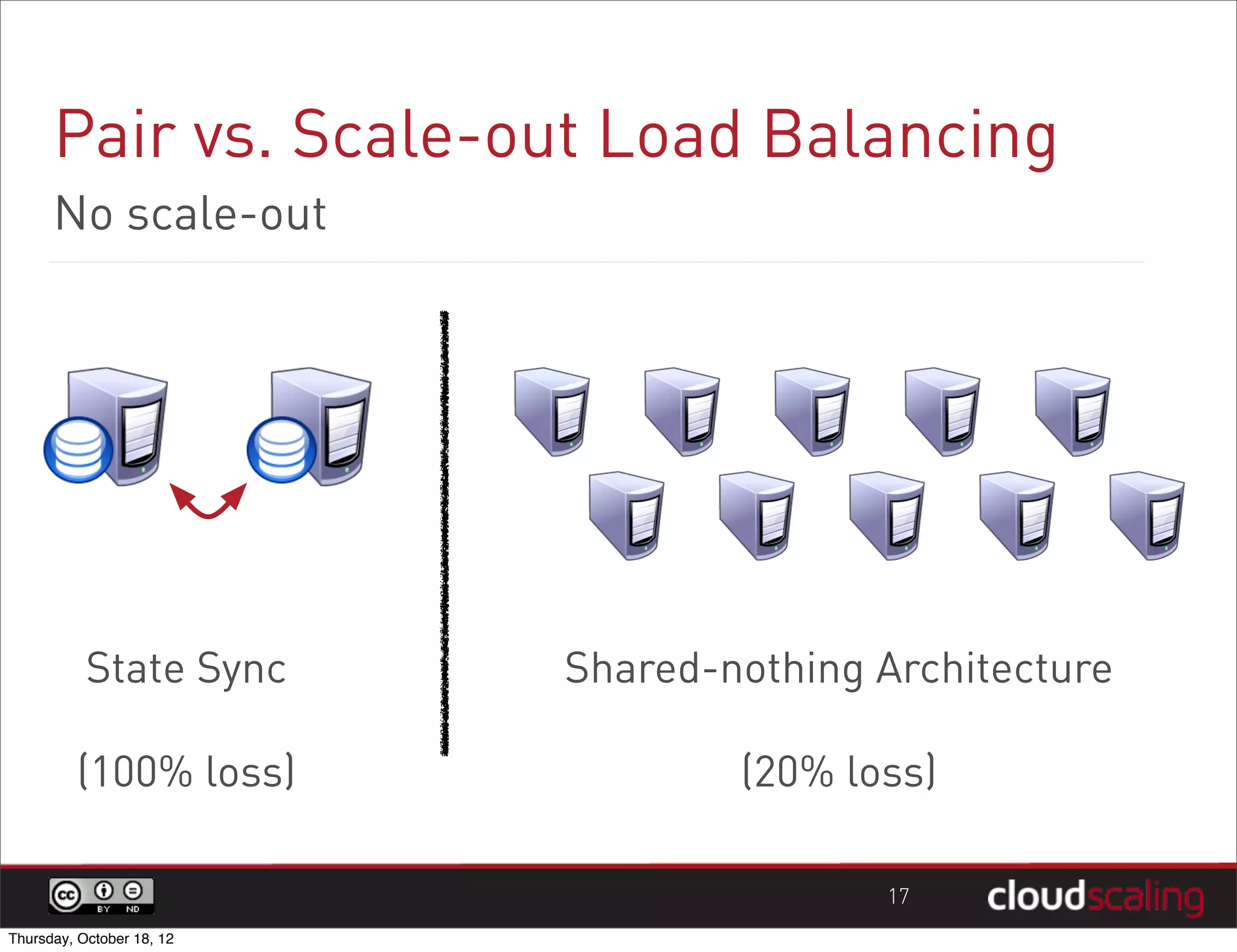

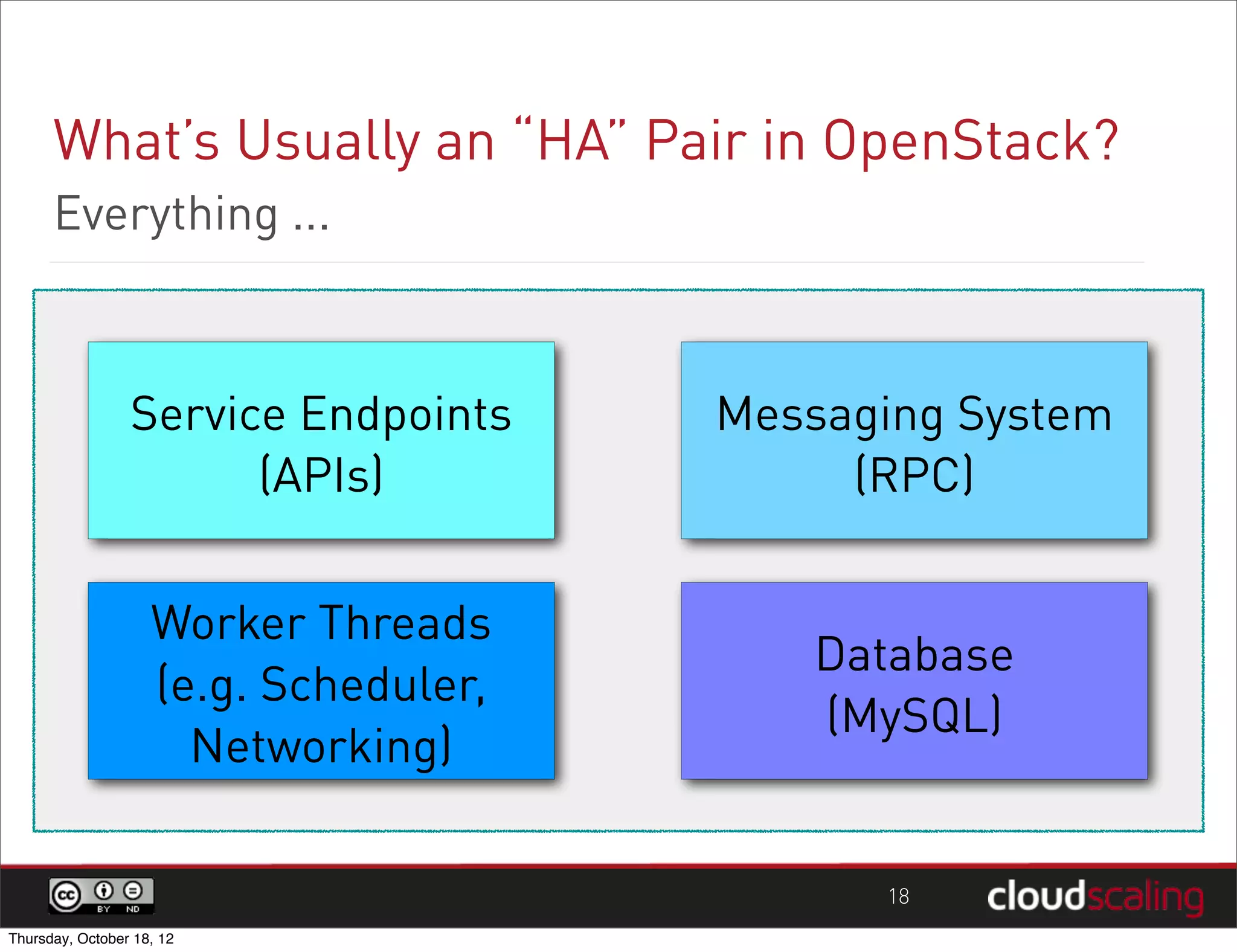
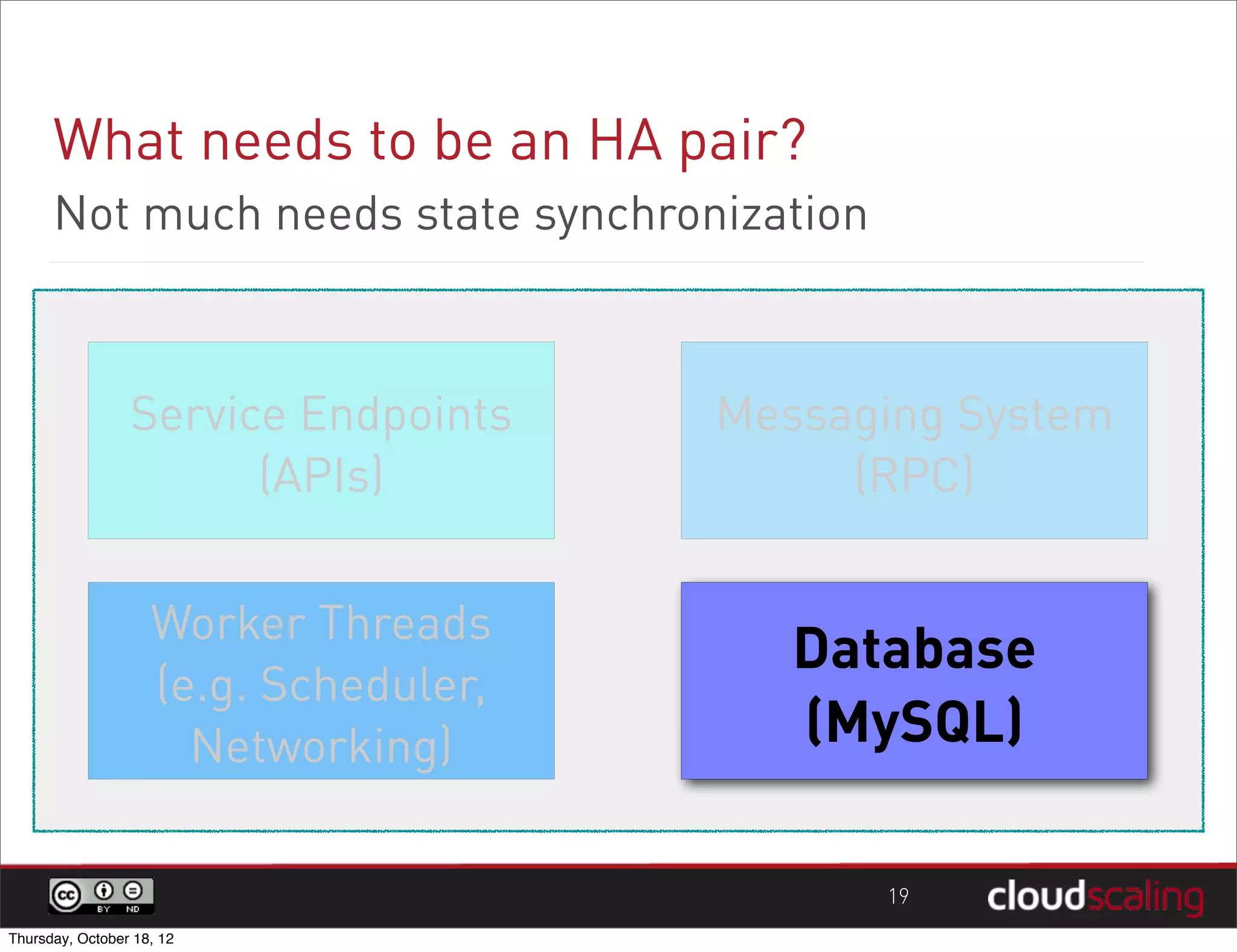




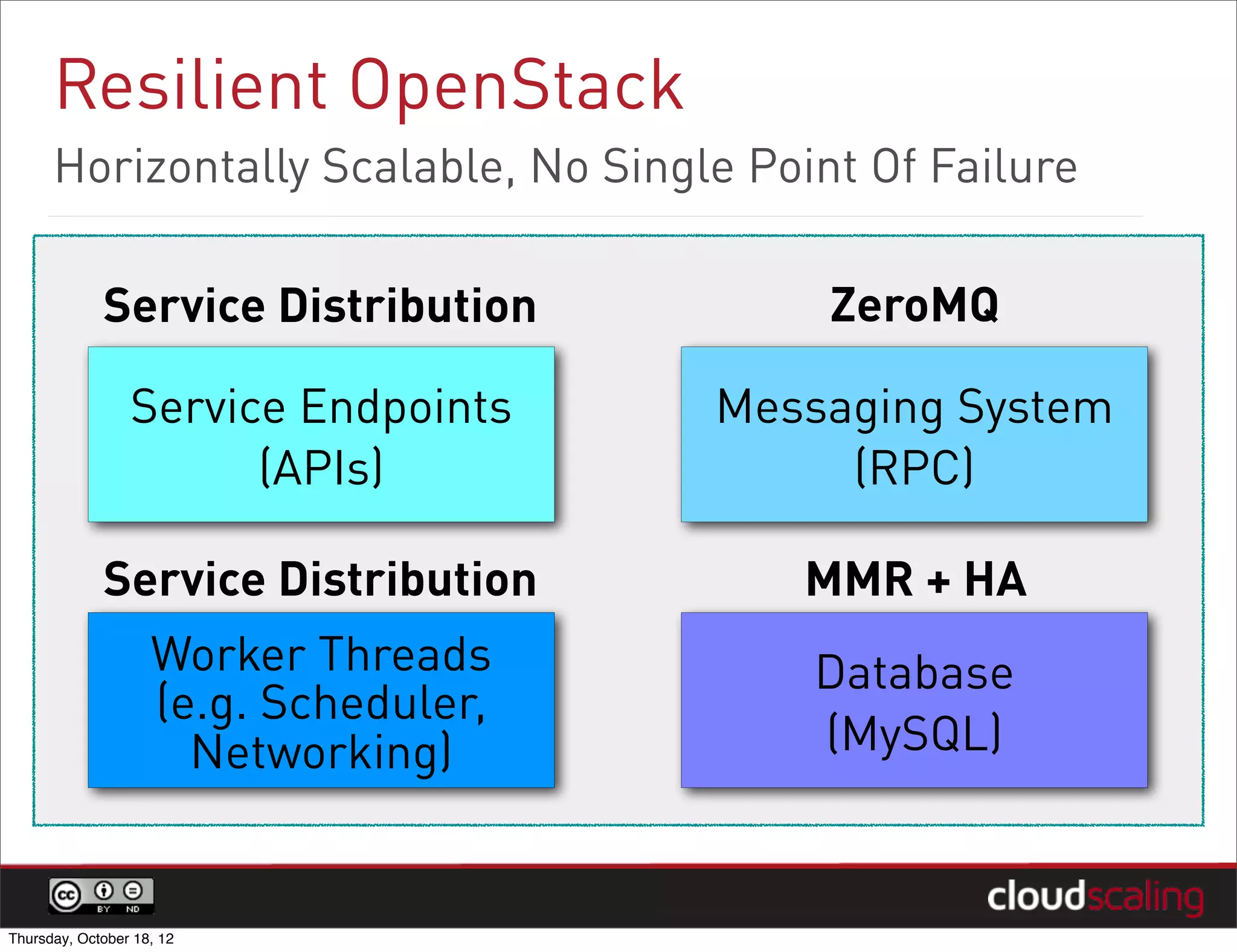

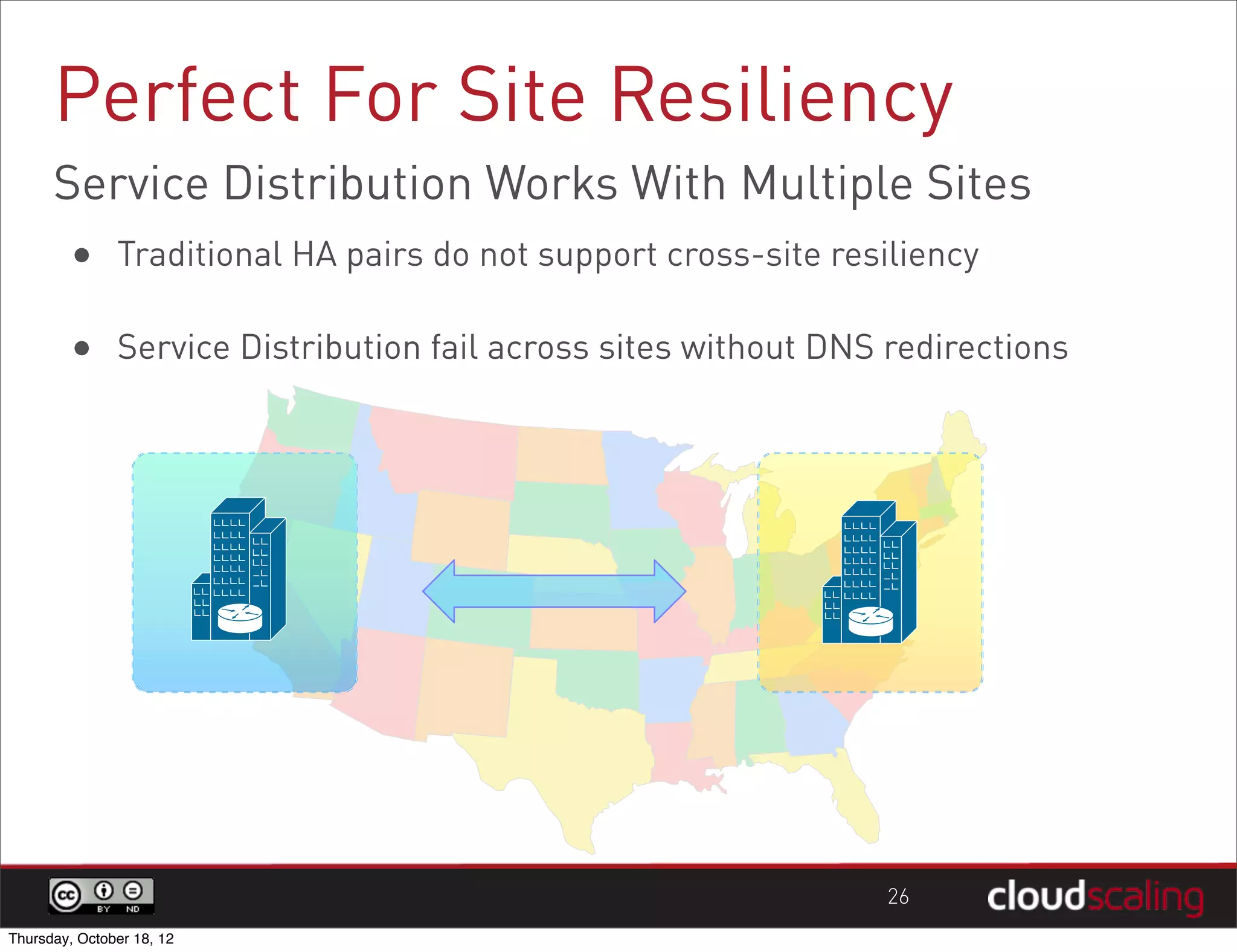
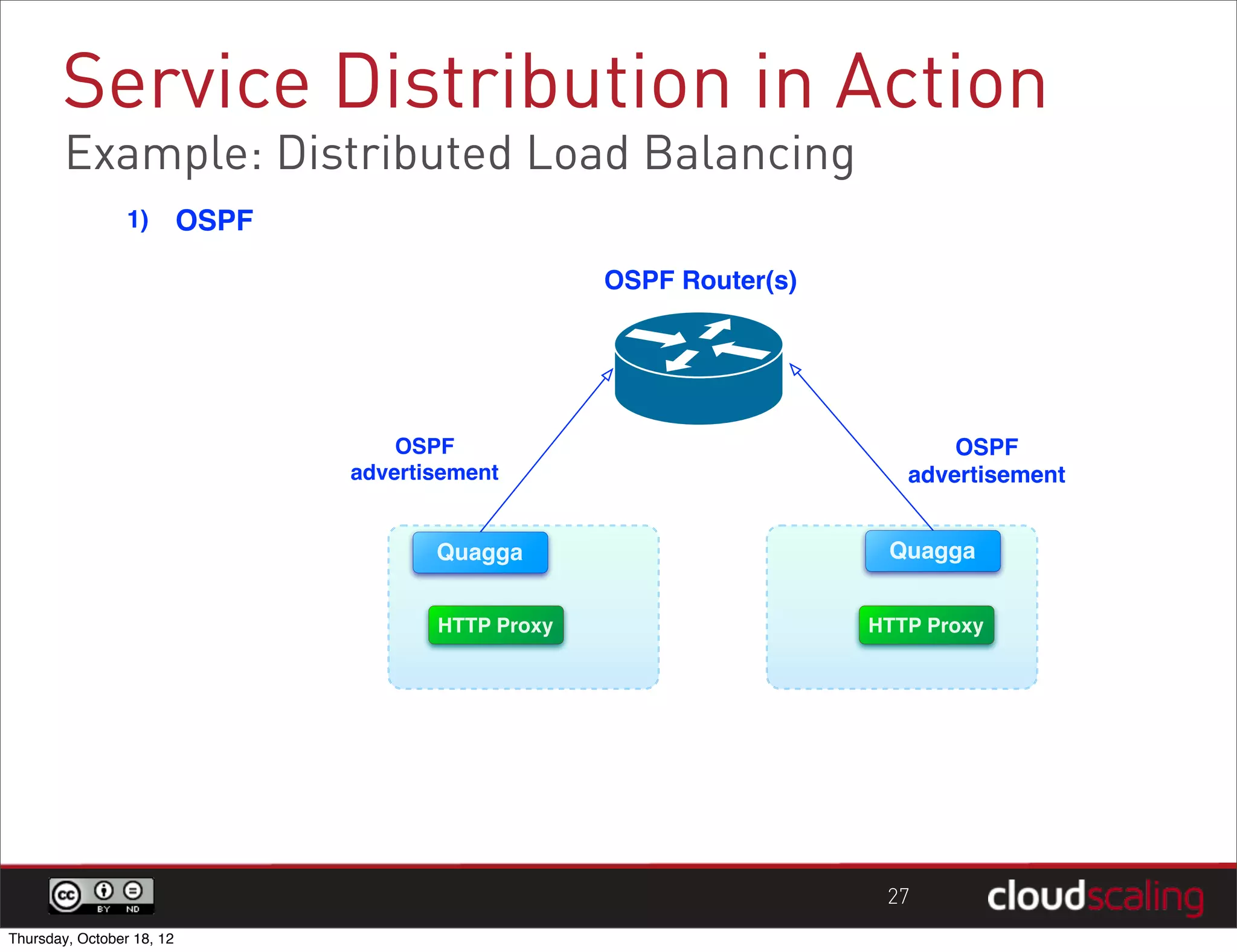
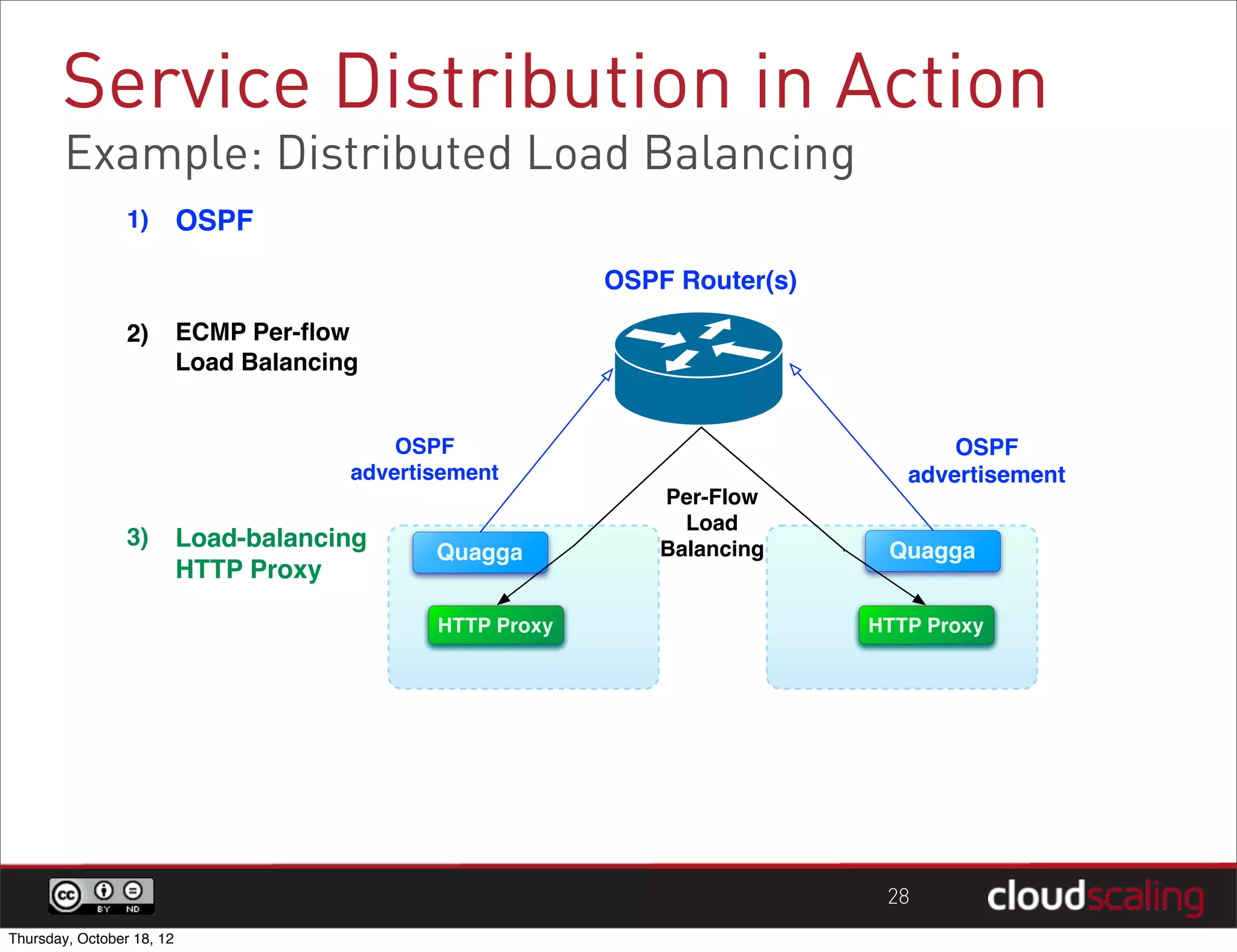
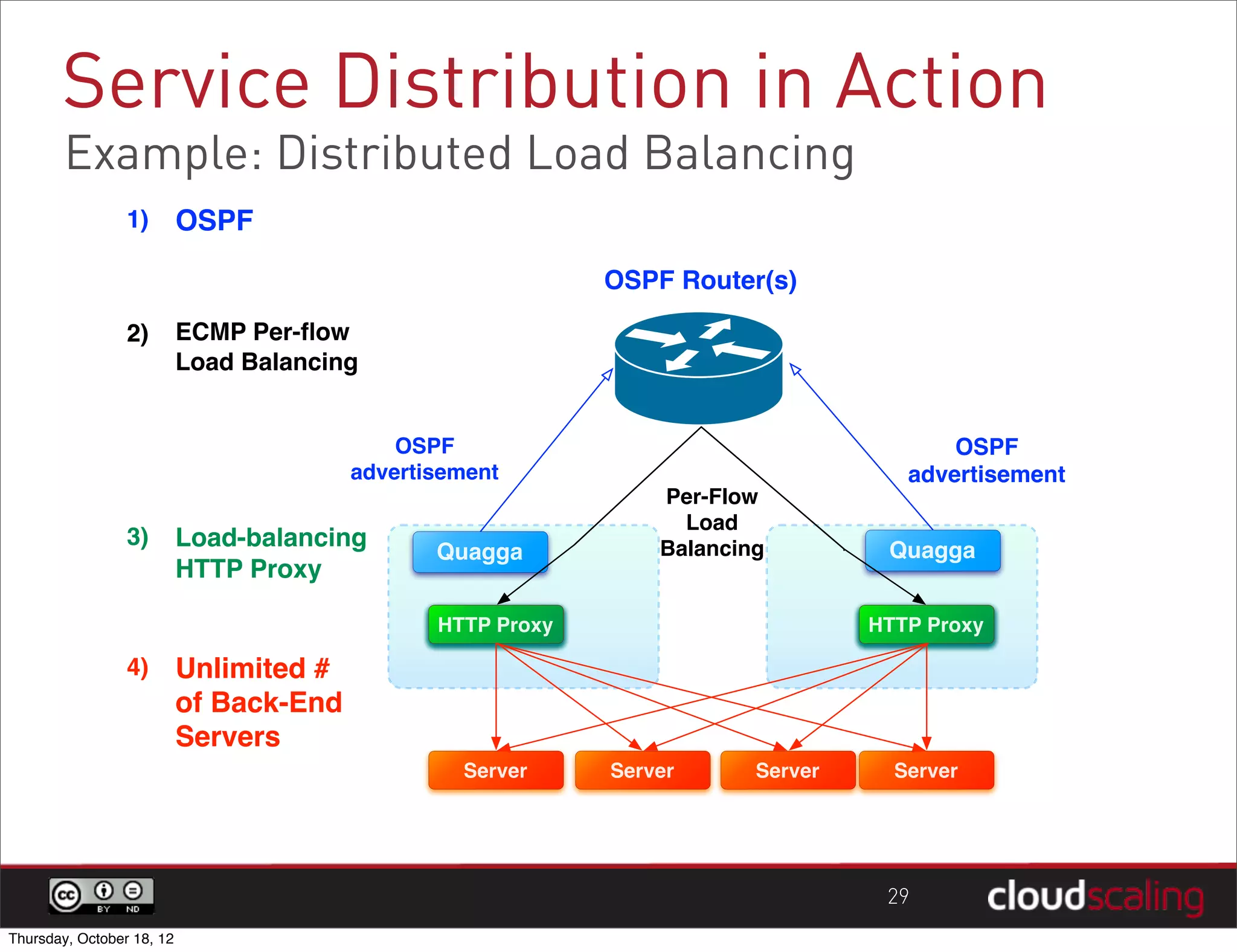
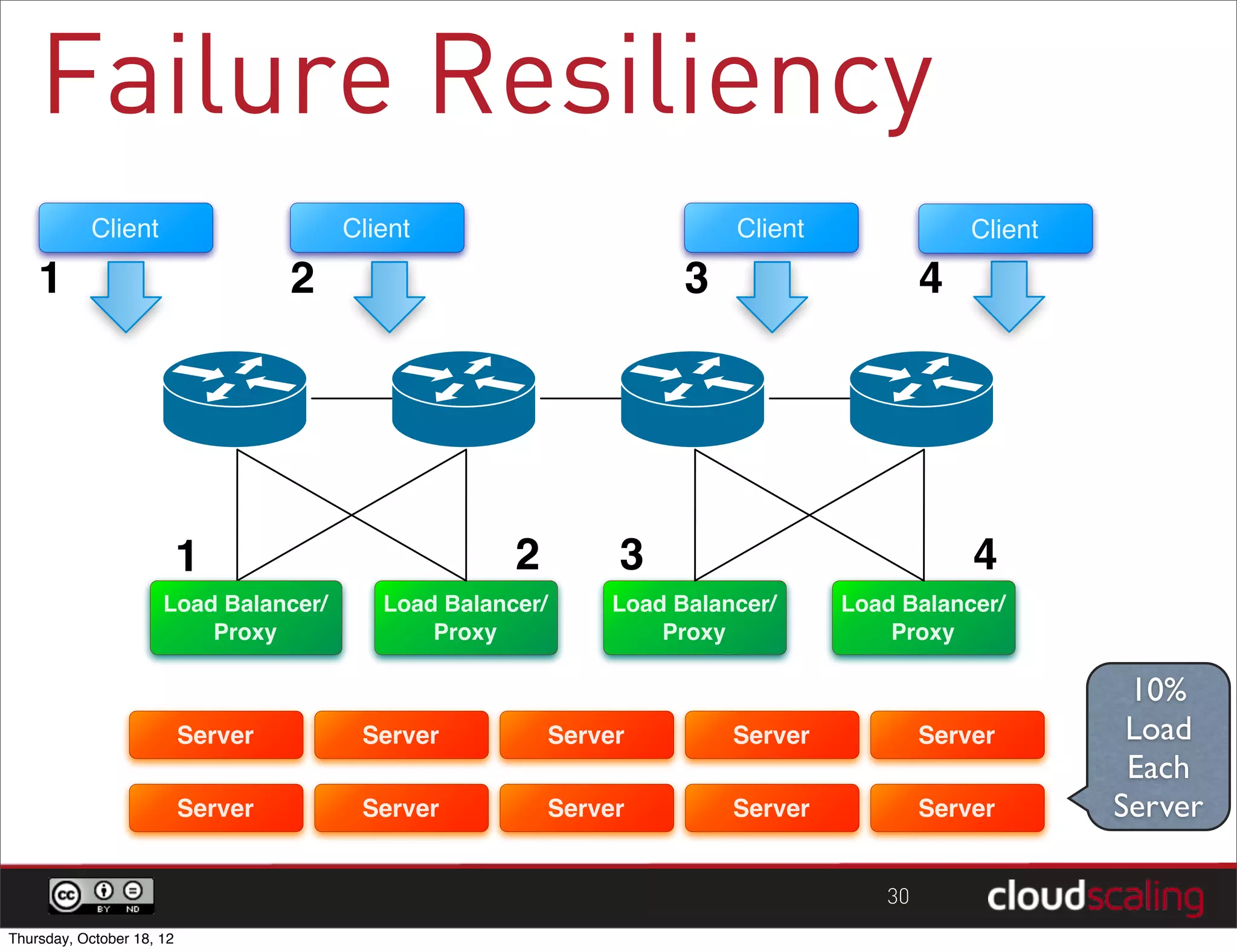
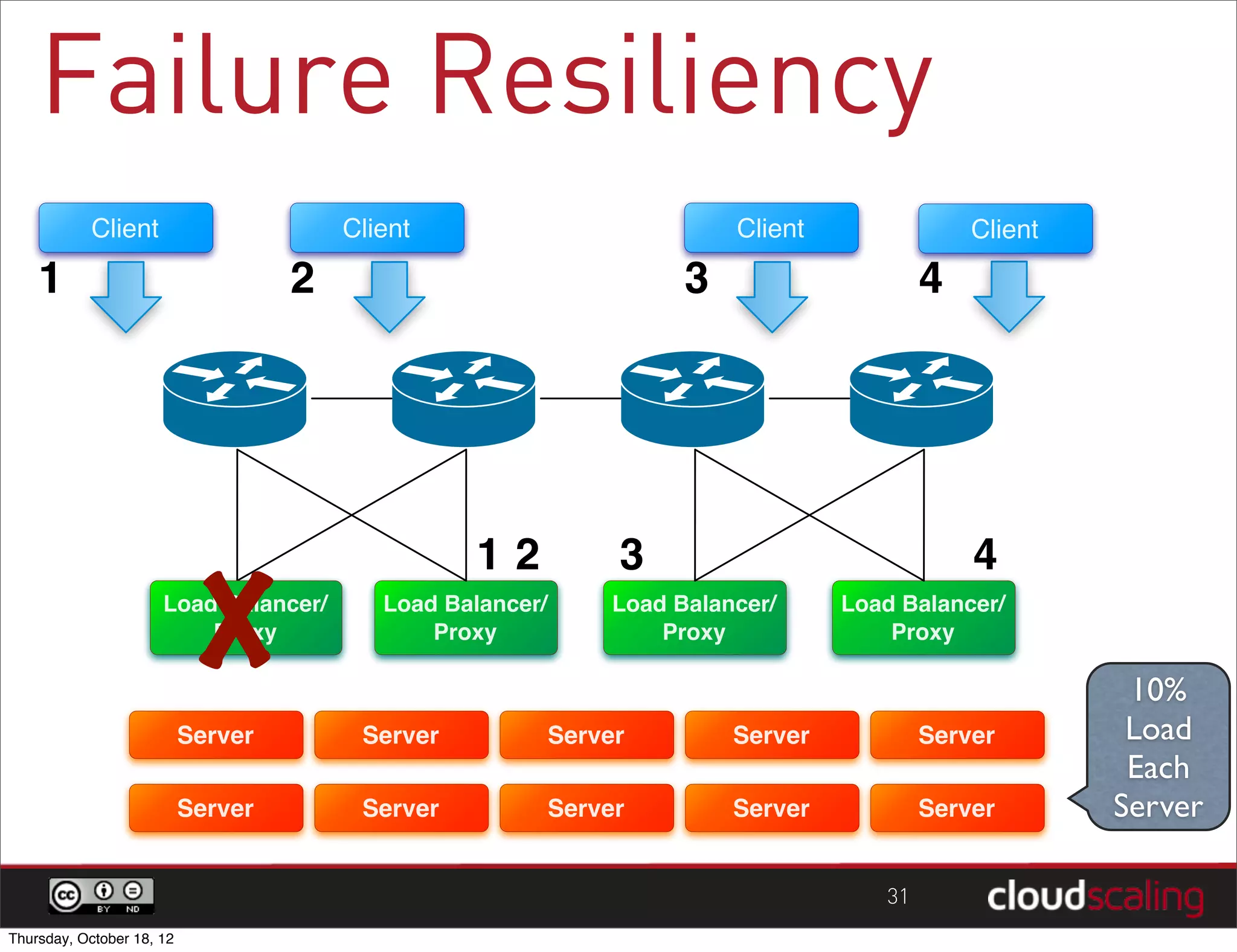
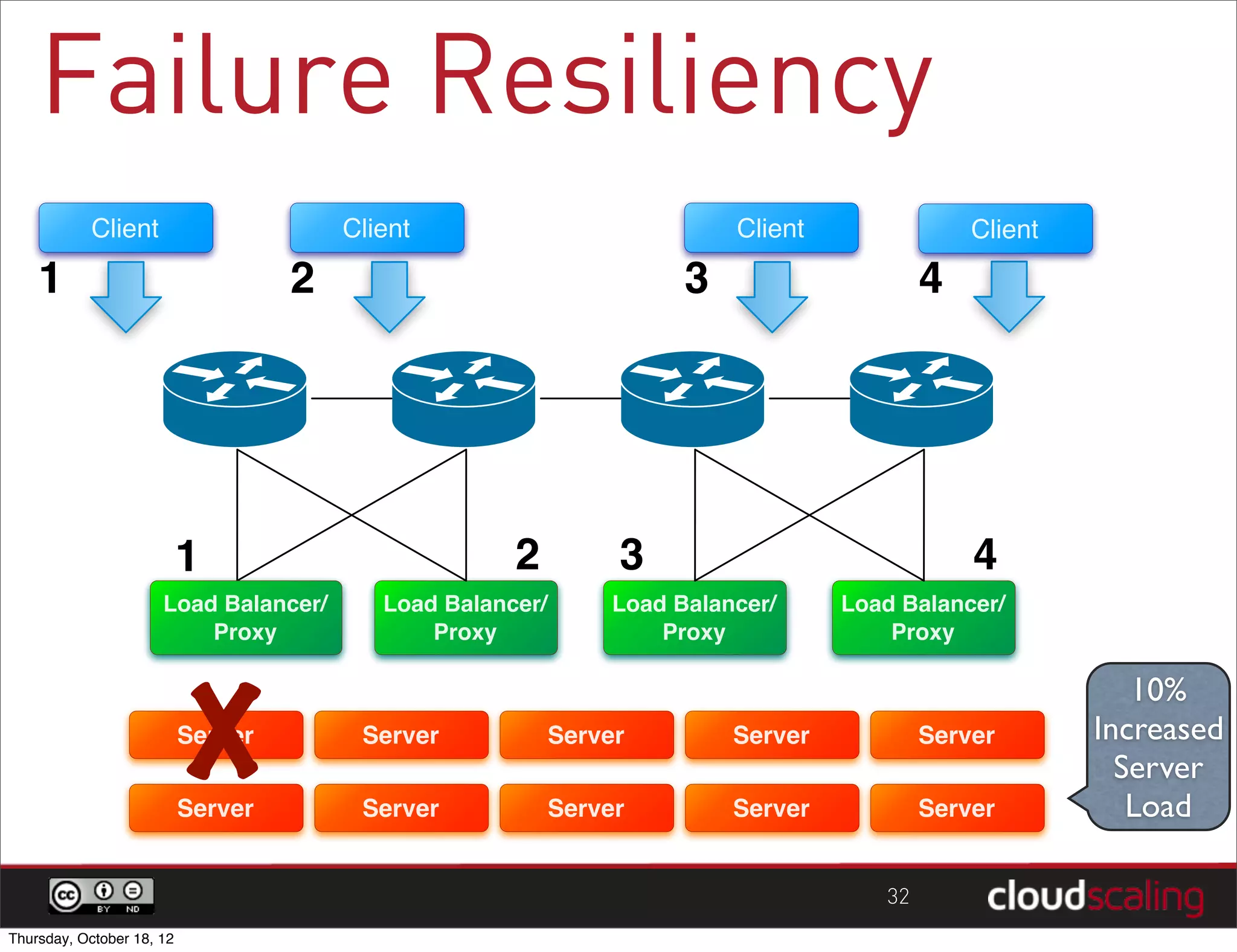
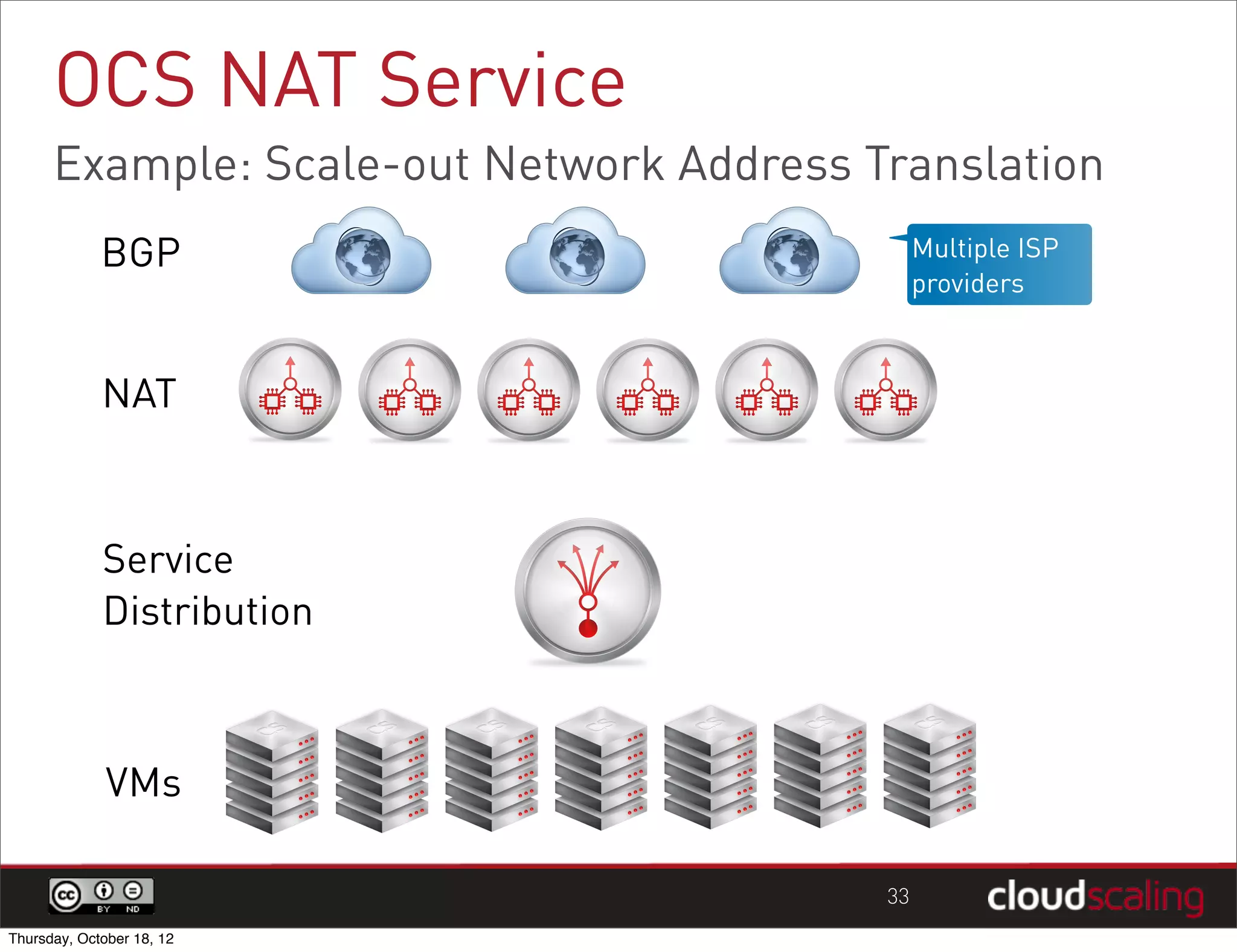
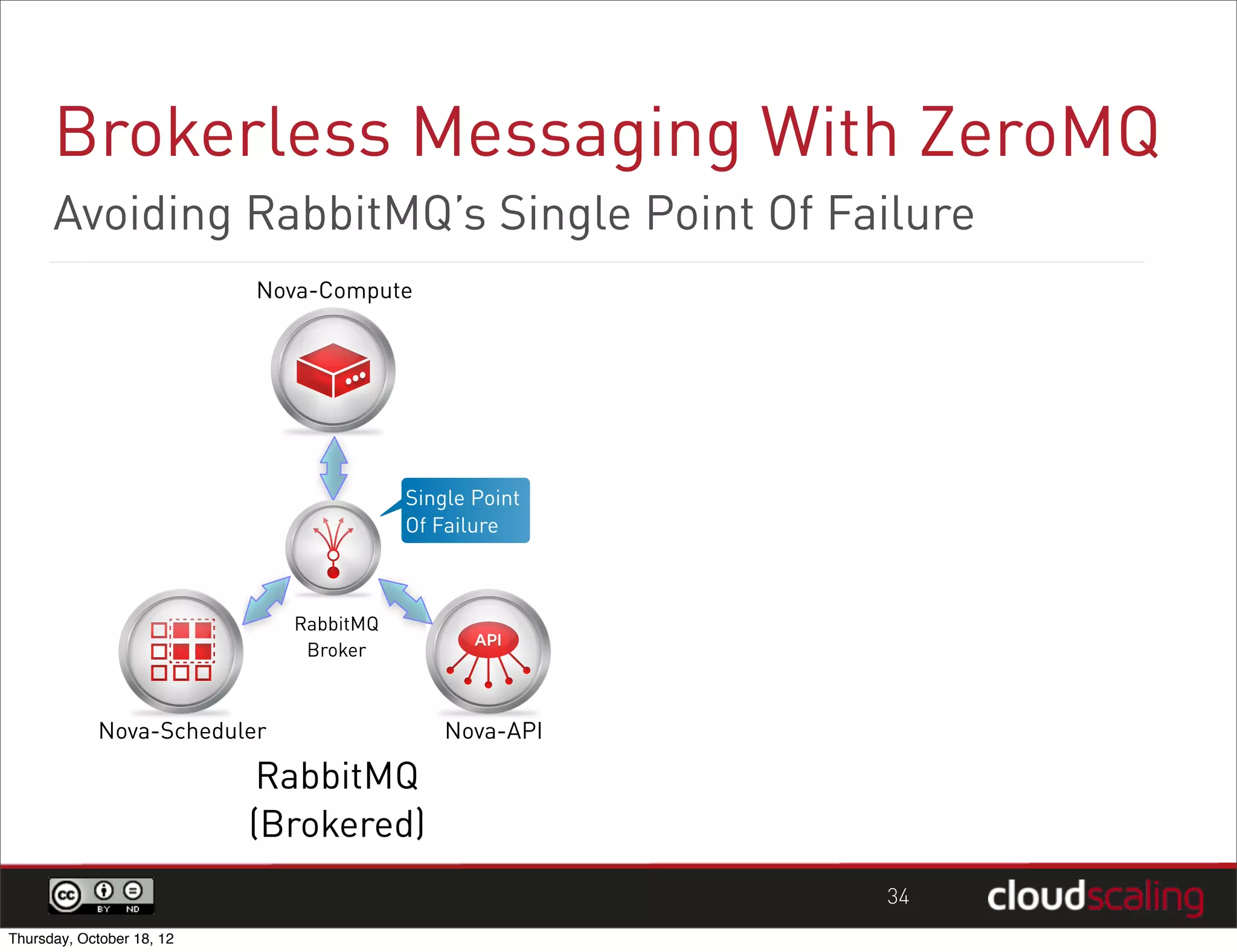
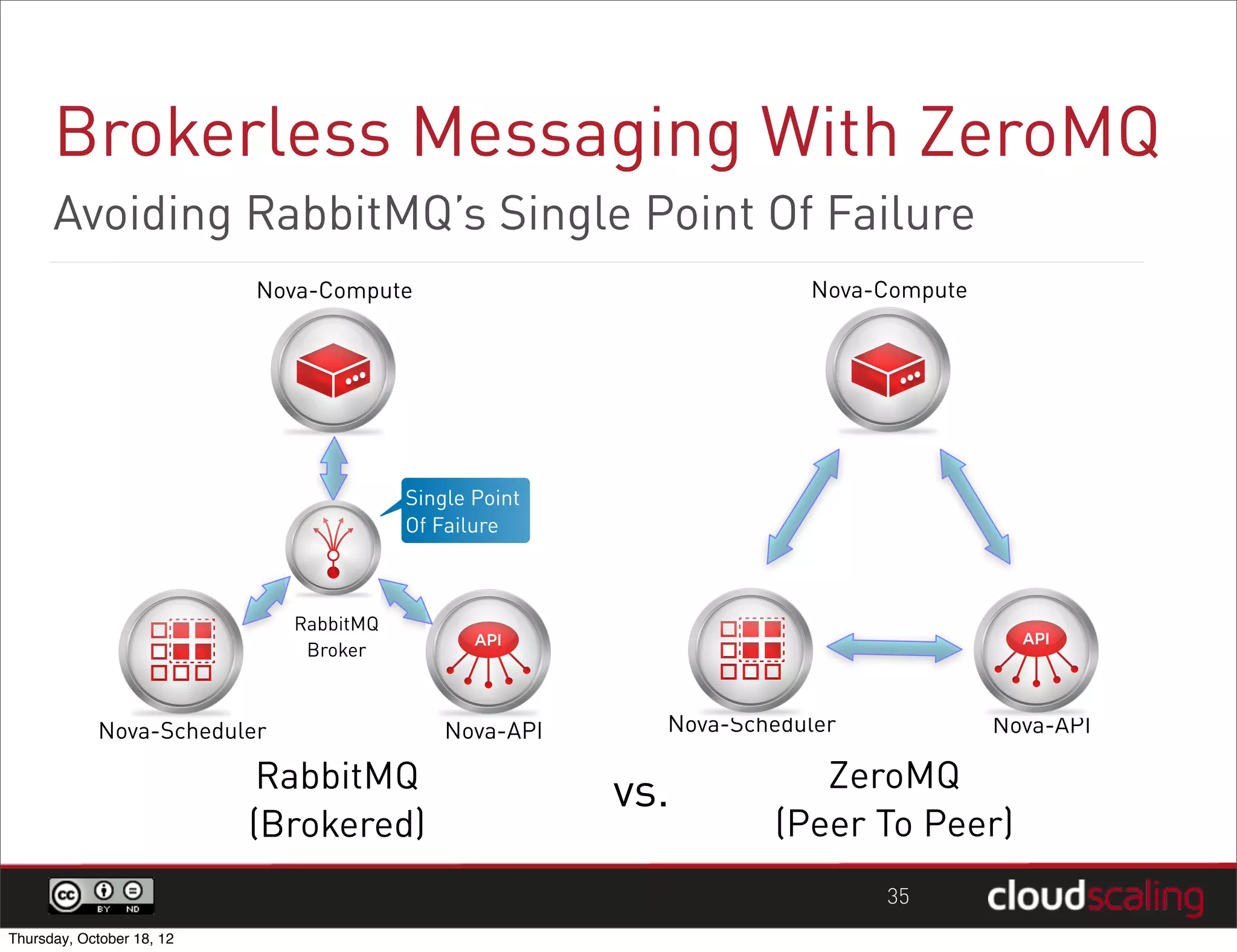



1) "HA" pairs are commonly used but are not the only way to achieve redundancy. They have limitations around catastrophic failures and lack of scale out. 2) Alternative patterns like distributed load balancing and brokerless messaging can provide redundancy without single points of failure and allow for scale out. 3) Service distribution is presented as a superior approach that combines standard networking technologies to provide resilient, stateless and scale out services for OpenStack.













![[ML15]Class Cat佐々木さん「いち早く人工知能テクノロジーを取り入れた製品・サービスを市場に展開するには?」](https://cdn.slidesharecdn.com/ss_thumbnails/classcatml15-20170226-170306025120-thumbnail.jpg?width=640&height=640&fit=bounds)











































