


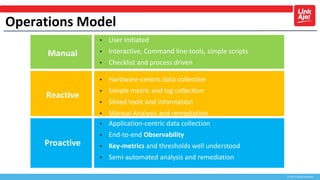













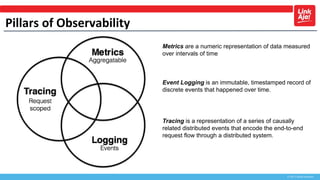



This document discusses operations, monitoring, and observability. It provides an overview of each topic. For operations, it describes different models from manual to proactive. For monitoring, it explains that the goal is to understand what is broken and why by looking at symptoms and causes. It also discusses monitoring methodologies like using key metrics and thresholds. For observability, it defines it as understanding a system more fully by capturing metrics, events, and traces. It explains the three pillars of observability - metrics, logging, and tracing - and how they provide visibility into reliability, bottlenecks, and request flows.



































































