参考文献
[22] = [Shani+2012] A survey of point-based POMDP solvers
https://pdfs.semanticscholar.org/2027/b108fbefdb8aef1b6db8806
f98fceaa341a9.pdf
[Smallwood and Sondik 1971] The Optinal Control of Partially
Observable Markov Process over a Finite Horizon
http://www.cs.ubc.ca/~nando/550-
2006/handouts/sondikPOMDP.pdf
[Pineau+ 2003]
Point-based value iteration: An anytime algorithm for POMDPs
http://www.cs.mcgill.ca/~jpineau/files/jpineau-ijcai03.pdf
51


![参考文献
2016年10月に左の本が出た。
これを読んでいく。
右下の本が長らくバイブル
だったが2000年(原著1998年)
発行。
3
http://amzn.to/2josIJ1
http://amzn.to/2jCnYQg言及する時 [こ] と呼ぶことにする(著者多いので)](https://image.slidesharecdn.com/4-170203043846/85/4-3-320.jpg)









![修正
[こ]の式1.5.2 (p.59)では
𝑃 𝑜 𝑏, 𝑎 =
𝑠
𝑏 𝑠
𝑠′
𝑃 𝑠′
𝑠, 𝑎 𝑃(𝑎, 𝑜, 𝑠′)
となっているけど[22]の式15(下囲み)を参考にす
ると[こ]の記法ではO(s’, a, o)=P(o | a, s’)だから
𝑃 𝑜 𝑏, 𝑎 =
𝑠
𝑏 𝑠
𝑠′
𝑃 𝑠′
𝑠, 𝑎 𝑃(𝑜|𝑎, 𝑠′)
13
[22] = [Shani+ 2012] A survey of point-based POMDP solvers](https://image.slidesharecdn.com/4-170203043846/85/4-13-320.jpg)
![状態遷移関数
信念bの空間B上の状態遷移関数を求める
𝜏 𝑏, 𝑎, 𝑏′
= 𝑃 𝑏′
𝑎, 𝑏
=
𝑃 𝑏, 𝑎, 𝑏′
𝑃 𝑏, 𝑎
=
σ 𝑜 𝑃 𝑏, 𝑎, 𝑜, 𝑏′
𝑃(𝑏, 𝑎)
𝑏 𝑎,𝑜
𝑠′
= 𝑃(𝑠′
|𝑏, 𝑎, 𝑜)だから
𝑃 𝑏, 𝑎, 𝑜, 𝑠′ = 𝑏 𝑎,𝑜
𝑠′
𝑃 𝑏, 𝑎, 𝑜
= 𝑏 𝑎,𝑜 𝑠′ 𝑃 𝑜 𝑏, 𝑎 𝑃(𝑏, 𝑎)
𝑃 𝑏, 𝑎, 𝑜, 𝑏′ は𝑃 𝑏, 𝑎, 𝑜, 𝑠′ のs’がb’に一致した場合だけを取
り出したものだから
σ 𝑜 𝑃 𝑏, 𝑎, 𝑜, 𝑏′
𝑃(𝑏, 𝑎)
=
𝑜
𝕀[𝑏 𝑎,𝑜
𝑠′
= 𝑏′(𝑠)]𝑃 𝑜 𝑏, 𝑎
14](https://image.slidesharecdn.com/4-170203043846/85/4-14-320.jpg)



![区分線形で下に凸
n>0の時VnはVn-1を用いてこう書ける
𝑉𝑛 𝑏 = max
𝑎
𝑖
𝑏𝑖 𝑞𝑖
𝑎
+
𝑖𝑗𝑜
𝑏𝑖 𝑝𝑖𝑗
𝑎
𝑟𝑗𝑜
𝑎
𝑉𝑛−1(𝑏′
)
ストーリーに影響しないけど一応書いておくと
𝑝𝑖𝑗
𝑎
= 𝑇 𝑠 = 𝑠𝑖, 𝑎, 𝑠′ = 𝑠𝑗 = 𝑃 𝑠′ 𝑠, 𝑎 ,
𝑟𝑗𝑜
𝑎
= 𝑂 𝑠′ = 𝑠𝑗, 𝑎, 𝑜 = 𝑃 𝑜 𝑠′, 𝑎 ,
𝑞𝑖
𝑎
=
𝑗𝑜
𝑝𝑖𝑗
𝑎
𝑟𝑗𝑜
𝑎
𝑤𝑖𝑗𝑜
𝑎
, 𝑏𝑗
′
=
σ𝑖 𝑏𝑖 𝑝𝑖𝑗
𝑎
𝑟𝑗𝑜
𝑎
σ𝑖𝑗 𝑏𝑖 𝑝𝑖𝑗
𝑎
𝑟𝑗𝑜
𝑎
𝑤𝑖𝑗𝑜
𝑎
= 𝑅(𝑠 = 𝑠𝑖, 𝑎, 𝑠′ = 𝑠𝑗, 𝑜)
18
[Smallwood and Sondik 1971]がまあだいぶ前の論文なので記法の差が激しいんですよ](https://image.slidesharecdn.com/4-170203043846/85/4-18-320.jpg)


![Point-Based Value Iteration
αが指数的に増えると困るので数を制限しよう
→Point-Based Value Iteration(PBVI)
個人的には[こ]よりPBVIの提案がされた
[Pineau+ 2003]の方がわかりやすかったのと
[こ]の数式との対応がよくわからなかったので
[Pineau+ 2003]ベースで解説する。
21
[Pineau+ 2003]
Point-based value iteration: An anytime algorithm for POMDPs](https://image.slidesharecdn.com/4-170203043846/85/4-21-320.jpg)






![実装してみよう!
[こ]でも紹介されているTiger問題、元が2状態だ
からbが1次元単体でグラフが描きやすい。
なのでこれを実装して観察してみよう。
28](https://image.slidesharecdn.com/4-170203043846/85/4-28-320.jpg)



![小問の答え
(4)
𝑅 𝑠, 𝑎 = {
𝑠𝑙𝑒𝑓𝑡 ∶ +10, −100, −1 ,
𝑠 𝑟𝑖𝑔ℎ𝑡: [−100, +10, −1]
}
(5)
𝑇 𝑠, 𝑎, 𝑠′
= {
𝑠𝑙𝑒𝑓𝑡 ∶ 0.5, 0.5 , 0.5, 0.5 , [1.0, 0.0] ,
𝑠 𝑟𝑖𝑔ℎ𝑡: 0.5, 0.5 , 0.5, 0.5 , 0.0, 1.0
}
32
見やすさのために連想行列風に書いたけど最終的に行列に落とします](https://image.slidesharecdn.com/4-170203043846/85/4-32-320.jpg)
![小問の答え
(6) 観測(listen)していない時の観測結果を表現す
るために何も聞こえないo_nothingを追加する手
も考えられたが、今回は左右均等に音が聞こえる
ことにした。
𝑂 𝑠′
, 𝑎, 𝑜 = {
𝑠𝑙𝑒𝑓𝑡 ∶ 0.5, 0.5 , 0.5, 0.5 , [0.85, 0.15] ,
𝑠 𝑟𝑖𝑔ℎ𝑡: 0.5, 0.5 , 0.5, 0.5 , 0.15, 0.85
}
33](https://image.slidesharecdn.com/4-170203043846/85/4-33-320.jpg)

![小問の答え
(6) V0は行動が0回残っている時点での価値なの
で{[0.0, 0.0]}
(7-1) Γ 𝑎,∗
は|A| * |S|で
[[ 10 -100 -1]
[-100 10 -1]]
長さ|S|のベクトルの集合であるVと揃えて考える
と、V0がサイズ1で、Γ 𝑎,∗
がサイズ3
35](https://image.slidesharecdn.com/4-170203043846/85/4-35-320.jpg)
![小問の答え
Γ 𝑎,𝑜
は |A| * |O| * |V0| * |S| で、V0の中身がゼロな
ので計算すると全部ゼロになる。
[[[[ 0. 0.]] [[ 0. 0.]]]
[[[ 0. 0.]] [[ 0. 0.]]]
[[[ 0. 0.]] [[ 0. 0.]]]]
36](https://image.slidesharecdn.com/4-170203043846/85/4-36-320.jpg)
![小問の答え
Γ 𝑎
はクロス和をするので |A| * (|V0| ** |O|) * |S| と
指数的サイズだが、今回 |V0| = 1なのでサイズ3
ゼロのクロス和もゼロなので結局、各行動・状態
ごとの報酬であるところの Γ 𝑎,∗
になる。
[[[ 10. -100.]]
[[-100. 10.]]
[[ -1. -1.]]]
V1はこの3つの|S|次元ベクトルの集合になる。
37](https://image.slidesharecdn.com/4-170203043846/85/4-37-320.jpg)
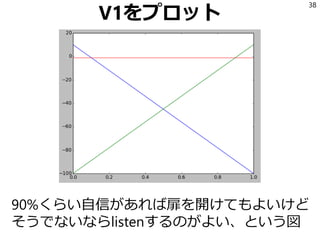

![V2
V2は|A| * (|V1| ** |O|)なので
3 * 3 ** 2の27になる。
40
[[ -35. -145. ]
[ -35. -145. ]
[ -13. -123. ]
[ -35. -145. ]
[ -35. -145. ]
[ -13. -123. ]
[ -13. -123. ]
[ -13. -123. ]
[ 9. -101. ]
[-145. -35. ]
[-145. -35. ]
[-123. -13. ]
[-145. -35. ]
[-145. -35. ]
[-123. -13. ]
[-123. -13. ]
[-123. -13. ]
[-101. 9. ]
[ 9. -101. ]
[ -7.5 -7.5 ]
[ 7.35 -16.85]
[ -84.5 -84.5 ]
[-101. 9. ]
[ -86.15 -0.35]
[ -0.35 -86.15]
[ -16.85 7.35]
[ -2. -2. ]]](https://image.slidesharecdn.com/4-170203043846/85/4-40-320.jpg)
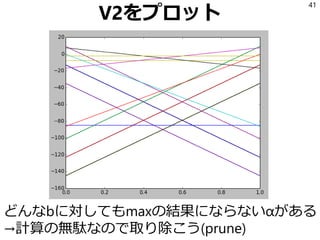
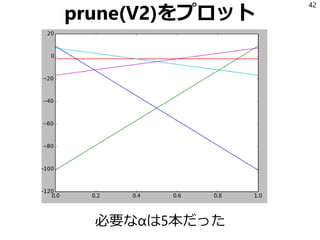

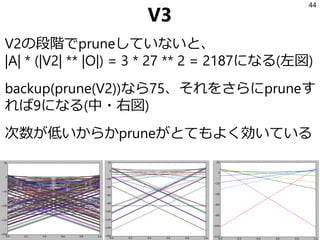


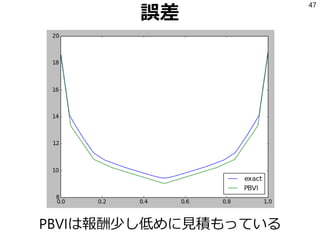

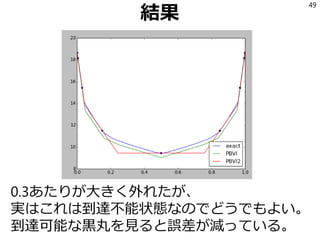

![参考文献
[22] = [Shani+ 2012] A survey of point-based POMDP solvers
https://pdfs.semanticscholar.org/2027/b108fbefdb8aef1b6db8806
f98fceaa341a9.pdf
[Smallwood and Sondik 1971] The Optinal Control of Partially
Observable Markov Process over a Finite Horizon
http://www.cs.ubc.ca/~nando/550-
2006/handouts/sondikPOMDP.pdf
[Pineau+ 2003]
Point-based value iteration: An anytime algorithm for POMDPs
http://www.cs.mcgill.ca/~jpineau/files/jpineau-ijcai03.pdf
51](https://image.slidesharecdn.com/4-170203043846/85/4-51-320.jpg)



![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)


































