Downloaded 122 times


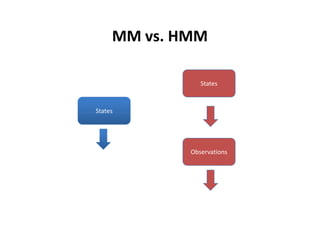


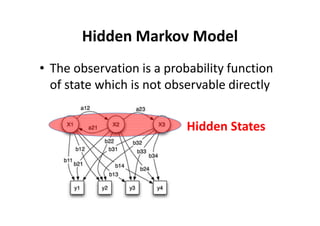




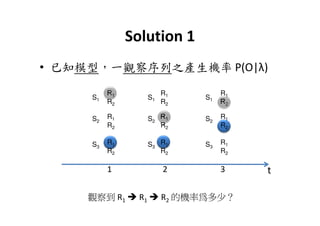



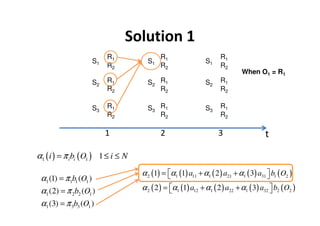
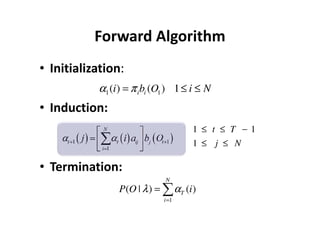
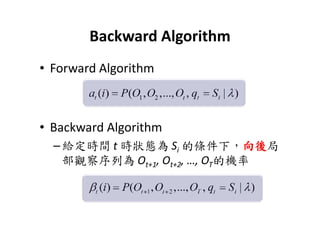











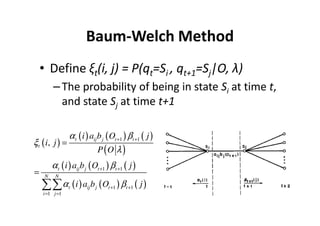





This document provides an introduction to Hidden Markov Models (HMMs). It begins by explaining the key differences between Markov Models and HMMs, noting that in HMMs the states are hidden and can only be indirectly observed through observations. It then outlines the main elements of an HMM - the number of states, observations, state transition probabilities, observation probabilities, and initial state distribution. An example HMM is provided. Finally, it briefly introduces three common problems in HMMs - determining the most likely model given observations, determining the most likely state sequence, and determining the model parameters that are most likely to have generated the observations.

























































![[C++ gui programming with qt4] chap9](https://cdn.slidesharecdn.com/ss_thumbnails/cguiprogrammingwithqt4chap9-110525095646-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[C++ GUI Programming with Qt4] chap7](https://cdn.slidesharecdn.com/ss_thumbnails/qt-chap4-110408012821-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[C++ GUI Programming with Qt4] chap4](https://cdn.slidesharecdn.com/ss_thumbnails/qt-chap4-110408012607-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























