Operator Fusion: NNVMの実装
• オペレータは主に4つのグループに分かれている
• グループ間でフューズ可能か決められている
NN op
convolution
conv transpose
pooling
fully connected
Injective
reshape
layout transform
transpose
concatenate
Elementwise
math op
relu
elemwise sum
sigmoid
Broadcast
broadcast_add
broadcast_mul
…
expand_dims
NN op には Elementwise か
Broadcast op をフューズできる
NN op 以外は同じグループの
op 同士で フューズできる, など
44.
Operator Fusion: 例
•Convolution + Bias Add + Batch norm + ReLU
data = sym.Variable(name="data")
data = sym.conv2d(data, kernel_size=(3,3), channels=8, use_bias=True)
data = sym.batch_norm(data)
data = sym.relu(data)
Graph(%data, %conv2d0_weight, %conv2d0_bias,%batch_norm0_gamma_mul_div_expand, %batch_norm0_add_beta_expand) {
%5 = tvm_op(%data, %conv2d0_weight, %conv2d0_bias, %batch_norm0_gamma_mul_div_expand, %batch_norm0_add_beta_expand,
flatten_data='0', func_name='fuse_conv2d_broadcast_mul_broadcast_add_relu', num_inputs='5', num_outputs='1’)
ret %5
}
Links
• TVM: AnAutomated End-to-End Optimizing Compiler for Deep Learning, OSDI 2018
• https://arxiv.org/abs/1802.04799
• Learning to Optimize Tensor Programs, NIPS 2019
• AutoTVM 論文
• https://arxiv.org/abs/1805.08166
• Relay: A New IR for Machine Learning Frameworks
• https://arxiv.org/abs/1810.00952
• VTA: An Open Hardware-Software Stack for Deep Learning
• https://arxiv.org/abs/1807.04188
• Optimizing CNN Model Inference on CPUs
• Amazon のエンジニアによる、Xeon 向けの TVM 最適化に関する論文
• https://arxiv.org/abs/1809.02697
• Discussion forum
• https://discuss.tvm.ai/
• 公式ドキュメント. チュートリアルなども充実.
• https://docs.tvm.ai/
• Automatic Kernel Optimization for Deep Learning on All Hardware Platforms
• https://tvm.ai/2018/10/03/auto-opt-all.html









![Halide の影響
• “アルゴリズムとスケジュールの分離” を踏襲
• Halide と同じ IR を使用している. メモリ上の表現はほぼ同じ
Func sample(Func A, Func B){
Func f;
Var x, y;
f(x, y) = A(x, y) + B(x, y);
// schedule
f.parallel(y).vectorize(x, 8);
return f;
}
def sample(A, B):
f = tvm.compute(A.shape,
lambda y, x: A[y, x] + B[y, x])
# schedule
sch = tvm.create_schedule(f.op)
y, x = sch[f].op.axis
sch[f].parallel(y)
xo, xi = sch[f].split(x, factor=8)
sch[f].vectorize(xi)
return f
TVM による記述 Halide による記述
詳しくは
Halide による画像処理プログラミング入門
Prelude to Halide](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-10-320.jpg)
![核となるアイデア
• cuDNN などの “手で最適化された” コードは使わない. 自分でコード生成する
• 出力されるコードのひな形を登録
• 登録されたひな形から, 各バックエンド向けに Auto Tuning + コード生成
def matmul(A, B):
M, K = A.shape
K, N = B.shape
k = tvm.reduce_axis((0, K), name='k’)
C = tvm.compute((M, N),
lambda i, j:
tvm.sum(A[i, k] * B[k, j], axis=k),
name="C")
return C
def schedule_matmul(C, s):
y, x = C.op.axis
k, = s[C].op.reduce_axis
yo, xo, yi, xi = s[C].tile(y, x, 16, 16)
ko, ki = s[C].split(k, factor=8)
s[C].reorder(yo, xo, ko, yi, ki, xi)
fused = s[C].fuse(yo, xo)
s[C].parallel(fused)
s[C].vectorize(xi)
計算の定義 (バックエンド非依存) CPU 向けスケジュール](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-11-320.jpg)


![計算の定義
def matmul(A, B):
M, K = A.shape
K, N = B.shape
k = tvm.reduce_axis((0, K), name='k’)
C = tvm.compute((M, N),
lambda i, j: tvm.sum(A[i, k] * B[k, j], axis=k),
name="C")
return C
• 行列積の TVM による定義
• CPU, GPU バックエンドともに同じ定義を使用
• 記述できるものは, 行列の演算や畳み込みなどに限られる
• DL 用途としてはこれで十分](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-14-320.jpg)
![TVM IR を見てみる
M = N = K = 512
A = tvm.placeholder((M, K), name='A')
B = tvm.placeholder((K, N) , name='B')
C = matmul(A, B)
s = tvm.create_schedule(C.op)
print(tvm.lower(s, [A, B, C], simple_mode=True))
produce C {
for (i, 0, 512) {
for (j, 0, 512) {
C[((i*512) + j)] = 0.000000f
for (k, 0, 512) {
C[((i*512) + j)] = (C[((i*512) + j)] + (A[((i*512) + k)]*B[(j + (k*512))]))
}
}
}
}
デフォルトのスケジュール
計算の定義からループのネスト
構造を自動生成](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-15-320.jpg)
![スケジューリング
• 定義した計算の意味を変えずに, ループ構造・種類を変更
tile_size = 16
y, x = C.op.axis
k, = s[C].op.reduce_axis
yo, xo, yi, xi = s[C].tile(y, x, tile_size, tile_size)
ko, ki = s[C].split(k, factor=8)
s[C].reorder(yo, xo, ko, yi, ki, xi)
fused = s[C].fuse(yo, xo)
s[C].parallel(fused)
s[C].vectorize(xi)
tile, split, reorder, fuse, vectorize,
parallel は Halide 由来
16 x 16 のブロックに分割
内積をとる軸を分割し, ループの順序を変更
外側ブロック数についてのループを並列化
最内ループをベクトル化](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-16-320.jpg)
![スケジューリング適用後
produce C {
parallel (i.outer.j.outer.fused, 0, 1024) {
for (i.inner.init, 0, 16) {
C[ramp(((((i.outer.j.outer.fused/32)*512) + ((i.inner.init*32) + (i.outer.j.outer.fused %
32)))*16), 1, 16)] = x16(0.000000f)
}
for (k.outer, 0, 64) {
for (i.inner, 0, 16) {
for (k.inner, 0, 8) {
C[ramp(((((i.outer.j.outer.fused/32)*512) + ((i.inner*32) + (i.outer.j.outer.fused %
32)))*16), 1, 16)] = (C[ramp(((((i.outer.j.outer.fused/32)*512) + ((i.inner*32) +
(i.outer.j.outer.fused % 32)))*16), 1, 16)] + (x16(A[((((((i.outer.j.outer.fused/32)*1024) +
k.outer) + (i.inner*64))*8) + k.inner)])*B[ramp(((((k.inner*32) + (i.outer.j.outer.fused % 32))
+ (k.outer*256))*16), 1, 16)]))
}
}
}
}
}](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-17-320.jpg)
![GPU へのマッピング
tile_size = 16
yo, xo, yi, xi = s[C].tile(y, x, tile_size, tile_size)
s[C].bind(yo, tvm.thread_axis("blockIdx.y"))
s[C].bind(xo, tvm.thread_axis("blockIdx.x"))
s[C].bind(yi, tvm.thread_axis("threadIdx.y"))
s[C].bind(xi, tvm.thread_axis("threadIdx.x"))
produce C {
// attr [iter_var(blockIdx.y, , blockIdx.y)] thread_extent = 32
// attr [iter_var(blockIdx.x, , blockIdx.x)] thread_extent = 32
// attr [iter_var(threadIdx.y, , threadIdx.y)] thread_extent = 16
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 16
C[(((((blockIdx.y*512) + blockIdx.x) + (threadIdx.y*32))*16) + threadIdx.x)] = 0.000000f
for (k, 0, 512) {
C[(((((blockIdx.y*512) + blockIdx.x) + (threadIdx.y*32))*16) + threadIdx.x)] =
(C[(((((blockIdx.y*512) + blockIdx.x) + (threadIdx.y*32))*16) + threadIdx.x)] +
(A[((((blockIdx.y*16) + threadIdx.y)*512) + k)]*B[(((blockIdx.x*16) + threadIdx.x) + (k*512))]))
}
}](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-18-320.jpg)
![共有メモリの利用
num_thread = 16
k, = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=num_thread)
A, B = s[C].op.input_tensors
AA = s.cache_read(A, "shared", [C])
BB = s.cache_read(B, "shared", [C])
s[AA].compute_at(s[C], ko)
s[BB].compute_at(s[C], ko)
# load one value into shared mem per thread
y, x = s[AA].op.axis
_, _, ty, tx = s[AA].tile(y, x, num_thread, num_thread)
s[AA].bind(ty, tvm.thread_axis("threadIdx.y"))
s[AA].bind(tx, tvm.thread_axis("threadIdx.x"))
y, x = s[BB].op.axis
_, _, ty, tx = s[BB].tile(y, x, num_thread, num_thread)
s[BB].bind(ty, tvm.thread_axis("threadIdx.y"))
s[BB].bind(tx, tvm.thread_axis("threadIdx.x"))
http://www.es.ele.tue.nl/~mwijtvliet/5KK73/?page=mmcuda)](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-19-320.jpg)
![共有メモリの利用
produce C {
// attr [iter_var(blockIdx.y, , blockIdx.y)] thread_extent = 64
// attr [A.shared] storage_scope = "shared"
allocate A.shared[float32 * 16 * 16]
// attr [B.shared] storage_scope = “shared”
allocate B.shared[float32 * 16 * 16]
// attr [iter_var(blockIdx.x, , blockIdx.x)] thread_extent = 64
// attr [iter_var(threadIdx.y, , threadIdx.y)] thread_extent = 16
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 16
C[(((((blockIdx.y*1024) + blockIdx.x) + (threadIdx.y*64))*16) + threadIdx.x)] = 0.000000f
for (k.outer, 0, 64) {
produce A.shared {
// attr [iter_var(threadIdx.y, , threadIdx.y)] thread_extent = 16
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 16
A.shared[((threadIdx.y*16) + threadIdx.x)] = A[(((((blockIdx.y*1024) + k.outer) + (threadIdx.y*64))*16) + threadIdx.x)]
}
produce B.shared {
// attr [iter_var(threadIdx.y, , threadIdx.y)] thread_extent = 16
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 16
B.shared[((threadIdx.y*16) + threadIdx.x)] = B[((((blockIdx.x + (k.outer*1024)) + (threadIdx.y*64))*16) + threadIdx.x)]
}
for (k.inner, 0, 16) {
C[(((((blockIdx.y*1024) + blockIdx.x) + (threadIdx.y*64))*16) + threadIdx.x)] = (C[(((((blockIdx.y*1024) + blockIdx.x) +
(threadIdx.y*64))*16) + threadIdx.x)] + (A.shared[((threadIdx.y*16) + k.inner)]*B.shared[(threadIdx.x + (k.inner*16))]))
}
}
}](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-20-320.jpg)

![コード生成: AVX 2
M = N = K = 1024
A = tvm.placeholder((M, K), name='A')
B = tvm.placeholder((K, N) , name='B')
C = matmul(A, B)
s = schedule(C)
target = "llvm -mcpu=core-avx2"
func = tvm.build(s, [A, B, C], target=target)
print(func.get_source("asm"))
.LBB2_4:
leal (%rdx,%rsi), %edi
movslq %edi, %rdi
vbroadcastss -28(%rbx), %ymm4
vmovaps 32(%rcx,%rdi,4), %ymm5
vfmadd231ps 64(%rsp), %ymm4, %ymm5
vmovups 32(%rsp), %ymm6
vfmadd213ps (%rcx,%rdi,4), %ymm6, %ymm4
vbroadcastss -24(%rbx), %ymm6
vfmadd231ps %ymm7, %ymm6, %ymm4
vfmadd132ps (%rsp), %ymm5, %ymm6
vbroadcastss -20(%rbx), %ymm5
vfmadd231ps %ymm8, %ymm5, %ymm6
vfmadd213ps %ymm4, %ymm9, %ymm5
vbroadcastss -16(%rbx), %ymm4
vfmadd231ps %ymm11, %ymm4, %ymm5
vfmadd213ps %ymm6, %ymm10, %ymm4
vbroadcastss -12(%rbx), %ymm6
vfmadd231ps %ymm12, %ymm6, %ymm4
vfmadd213ps %ymm5, %ymm13, %ymm6
vbroadcastss -8(%rbx), %ymm5
vfmadd231ps %ymm15, %ymm5, %ymm6
vfmadd213ps %ymm4, %ymm14, %ymm5
vbroadcastss -4(%rbx), %ymm4
vfmadd231ps %ymm1, %ymm4, %ymm5
vfmadd213ps %ymm6, %ymm2, %ymm4
vbroadcastss (%rbx), %ymm6
vfmadd231ps %ymm3, %ymm6, %ymm4
vfmadd213ps %ymm5, %ymm0, %ymm6
vmovaps %ymm6, 32(%rcx,%rdi,4)
vmovaps %ymm4, (%rcx,%rdi,4)
addq $1024, %rsi
addq $4096, %rbx
cmpq $16384, %rsi
jne .LBB2_4](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-22-320.jpg)
![コード生成: NEON
target = tvm.target.arm_cpu(model="rasp3b")
func = tvm.build(s, [A, B, C], target=target)
print(func.get_source("asm"))
vld1.32 {d18, d19}, [r3:128]!
vld1.32 {d26[], d27[]}, [r2:32]!
vld1.64 {d22, d23}, [r0:128]
vld1.64 {d24, d25}, [r6:128]
vmla.f32 q9, q13, q15
vldmia r4, {d30, d31}
vld1.64 {d20, d21}, [r3:128]
vld1.32 {d28[], d29[]}, [r2:32]
vmla.f32 q11, q13, q7
vmla.f32 q12, q13, q8
add r2, r1, #8
add r4, sp, #32
vmla.f32 q10, q13, q15
vld1.32 {d26[], d27[]}, [r2:32]
vmla.f32 q12, q14, q4
vmla.f32 q9, q14, q6
vmla.f32 q11, q14, q3
add r2, r1, #12
vmla.f32 q12, q13, q0
vmla.f32 q10, q14, q5
vldmia r4, {d28, d29}
add r4, sp, #96
vmla.f32 q9, q13, q2
vmla.f32 q10, q13, q1
vmla.f32 q11, q13, q14
vld1.32 {d28[], d29[]}, [r2:32]
vldmia r4, {d26, d27}
add r4, sp, #80
add r2, r1, #16
vmla.f32 q11, q14, q13
vldmia r4, {d26, d27}
.....
ターゲットを変えるだけで, 全く違った
アーキテクチャ用のコード生成が可能](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-23-320.jpg)
![コード生成: CUDA
s = schedule_shared_mem(C)
target = "cuda"
func = tvm.build(s, [A, B, C], target=target)
print(func.imported_modules[0].get_source())
extern "C" __global__ void default_function_kernel0( float* __restrict__ C, float* __restrict__ A, float* __restrict__ B) {
__shared__ float A_shared[256];
__shared__ float B_shared[256];
C[((((((int)blockIdx.y) * 16384) + (((int)blockIdx.x) * 16)) + (((int)threadIdx.y) * 1024)) + ((int)threadIdx.x))] =
0.000000e+00f;
for (int k_outer = 0; k_outer < 64; ++k_outer) {
__syncthreads();
A_shared[((((int)threadIdx.y) * 16) + ((int)threadIdx.x))] = A[((((((int)blockIdx.y) * 16384) + (k_outer * 16)) +
(((int)threadIdx.y) * 1024)) + ((int)threadIdx.x))];
B_shared[((((int)threadIdx.y) * 16) + ((int)threadIdx.x))] = B[((((((int)blockIdx.x) * 16) + (k_outer * 16384)) +
(((int)threadIdx.y) * 1024)) + ((int)threadIdx.x))];
__syncthreads();
for (int k_inner = 0; k_inner < 16; ++k_inner) {
C[((((((int)blockIdx.y) * 16384) + (((int)blockIdx.x) * 16)) + (((int)threadIdx.y) * 1024)) + ((int)threadIdx.x))] =
(C[((((((int)blockIdx.y) * 16384) + (((int)blockIdx.x) * 16)) + (((int)threadIdx.y) * 1024)) + ((int)threadIdx.x))] +
(A_shared[((((int)threadIdx.y) * 16) + k_inner)] * B_shared[(((int)threadIdx.x) + (k_inner * 16))]));
}
}
}](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-24-320.jpg)
![コード生成: AMDGPU
for_body: ; preds = %for_body, %entry
%.promoted = phi float [ 0.000000e+00, %entry ], [ %147, %for_body ]
%indvars.iv = phi i64 [ 0, %entry ], [ %indvars.iv.next, %for_body ]
tail call void @llvm.amdgcn.s.barrier()
%84 = trunc i64 %indvars.iv to i32
%85 = add i32 %9, %84
%86 = shl i32 %85, 4
%87 = add nsw i32 %86, %6
%88 = sext i32 %87 to i64
%89 = getelementptr inbounds float, float addrspace(1)* %1, i64 %88
%90 = bitcast float addrspace(1)* %89 to i32 addrspace(1)*
%91 = load i32, i32 addrspace(1)* %90, align 4, !tbaa !8
store i32 %91, i32 addrspace(3)* %18, align 4, !tbaa !11
%indvars.iv.tr = trunc i64 %indvars.iv to i32
%92 = shl i32 %indvars.iv.tr, 10
%93 = add i32 %19, %92
%94 = shl i32 %93, 4
%95 = add nsw i32 %94, %6
%96 = sext i32 %95 to i64
%97 = getelementptr inbounds float, float addrspace(1)* %2, i64 %96
%98 = bitcast float addrspace(1)* %97 to i32 addrspace(1)*
%99 = load i32, i32 addrspace(1)* %98, align 4, !tbaa !14
store i32 %99, i32 addrspace(3)* %21, align 4, !tbaa !17
tail call void @llvm.amdgcn.s.barrier()
%100 = load float, float addrspace(3)* %22, align 16, !tbaa !11
%101 = load float, float addrspace(3)* %23, align 4, !tbaa !17
%102 = tail call float @llvm.fmuladd.f32(float %100, float %101, float %.promoted)
%103 = load float, float addrspace(3)* %25, align 4, !tbaa !11
%104 = load float, float addrspace(3)* %27, align 4, !tbaa !17
%105 = tail call float @llvm.fmuladd.f32(float %103, float %104, float %102)
%106 = load float, float addrspace(3)* %29, align 8, !tbaa !11
%107 = load float, float addrspace(3)* %31, align 4, !tbaa !17
%108 = tail call float @llvm.fmuladd.f32(float %106, float %107, float %105)
.....
BB0_1:
v_add_u32_e32 v11, vcc, s6, v0
v_ashrrev_i32_e32 v12, 31, v11
v_ashrrev_i32_e32 v10, 31, v9
v_lshlrev_b64 v[11:12], 2, v[11:12]
v_lshlrev_b64 v[13:14], 2, v[9:10]
v_mov_b32_e32 v1, s1
v_add_u32_e32 v10, vcc, s0, v11
v_addc_u32_e32 v11, vcc, v1, v12, vcc
v_mov_b32_e32 v15, s3
v_add_u32_e32 v12, vcc, s2, v13
v_addc_u32_e32 v13, vcc, v15, v14, vcc
flat_load_dword v1, v[10:11]
flat_load_dword v10, v[12:13]
s_waitcnt vmcnt(0) lgkmcnt(0)
s_barrier
s_add_u32 s6, s6, 16
s_addc_u32 s7, s7, 0
v_add_u32_e32 v9, vcc, 0x4000, v9
s_cmp_lg_u64 s[6:7], s[4:5]
ds_write_b32 v6, v1
ds_write_b32 v5, v10
s_waitcnt lgkmcnt(0)
s_barrier
ds_read2_b32 v[18:19], v8 offset1:16
ds_read2_b64 v[10:13], v7 offset1:1
ds_read2_b64 v[14:17], v7 offset0:2 offset1:3
s_waitcnt lgkmcnt(1)
v_mac_f32_e32 v4, v10, v18
v_mac_f32_e32 v4, v11, v19
ds_read2_b32 v[10:11], v8 offset0:32 offset1:48
s_waitcnt lgkmcnt(0)
v_mac_f32_e32 v4, v12, v10
v_mac_f32_e32 v4, v13, v11
ds_read2_b32 v[10:11], v8 offset0:64 offset1:80
ds_read2_b32 v[12:13], v8 offset0:96 offset1:112
ds_read2_b32 v[18:19], v8 offset0:128 offset1:144
s_waitcnt lgkmcnt(2)
v_mac_f32_e32 v4, v14, v10
v_mac_f32_e32 v4, v15, v11
s_waitcnt lgkmcnt(1)
.....](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-25-320.jpg)
![AutoTVM – 学習ベースの Auto Tuning フレームワーク
• 以前の TVM
• 特定のネットワーク向けに手でパラメータチューニング
• チューニング対象外のネットワークでは遅かった
• AutoTVM によって, 高速なスケジュールを自動で生成できるようになった
ブロック行列積のタイルの大きさをチューニング可能にする例
from tvm import autotvm
cfg = autotvm.get_config()
cfg.define_knob("tile_size", [4, 8, 16, 32])
yo, xo, yi, xi = s[C].tile(y, x, cfg['tile_size'].val, cfg['tile_size'].val)
tile_size = 16
yo, xo, yi, xi = s[C].tile(y, x, tile_size, tile_size)](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-26-320.jpg)
![def schedule_direct_cuda(cfg, s, conv):
n, f, y, x = s[conv].op.axis
rc, ry, rx = s[conv].op.reduce_axis
cfg.define_split("tile_f", f, num_outputs=4)
cfg.define_split("tile_y", y, num_outputs=4)
cfg.define_split("tile_x", x, num_outputs=4)
cfg.define_split("tile_rc", rc, num_outputs=2)
cfg.define_split("tile_ry", ry, num_outputs=2)
cfg.define_split("tile_rx", rx, num_outputs=2)
cfg.define_knob("auto_unroll_max_step", [0, 512, 1500])
cfg.define_knob("unroll_explicit", [0, 1])
pad_data, kernel = s[conv].op.input_tensors
s[pad_data].compute_inline()
output = conv
OL = s.cache_write(conv, 'local’)
AA = s.cache_read(pad_data, 'shared', [OL])
WW = s.cache_read(kernel, 'shared', [OL])
n, f, y, x = s[output].op.axis
kernel_scope, n = s[output].split(n, nparts=1)
bf, vf, tf, fi = cfg["tile_f"].apply(s, output, f)
by, vy, ty, yi = cfg["tile_y"].apply(s, output, y)
bx, vx, tx, xi = cfg["tile_x"].apply(s, output, x)
bf = s[output].fuse(n, bf)
s[output].bind(bf, tvm.thread_axis("blockIdx.z"))
s[output].bind(by, tvm.thread_axis("blockIdx.y"))
s[output].bind(bx, tvm.thread_axis("blockIdx.x"))
s[output].bind(vf, tvm.thread_axis("vthread"))
s[output].bind(vy, tvm.thread_axis("vthread"))
s[output].bind(vx, tvm.thread_axis("vthread"))
s[output].bind(tf, tvm.thread_axis("threadIdx.z"))
s[output].bind(ty, tvm.thread_axis("threadIdx.y"))
s[output].bind(tx, tvm.thread_axis("threadIdx.x"))
s[output].reorder(bf, by, bx, vf, vy, vx, tf, ty, tx, fi, yi, xi)
s[OL].compute_at(s[output], tx)
n, f, y, x = s[OL].op.axis
rc, ry, rx = s[OL].op.reduce_axis
rco, rci = cfg['tile_rc'].apply(s, OL, rc)
ryo, ryi = cfg['tile_rx'].apply(s, OL, ry)
rxo, rxi = cfg['tile_ry'].apply(s, OL, rx)
s[OL].reorder(rco, ryo, rxo, rci, ryi, rxi, n, f, y, x)
s[AA].compute_at(s[OL], rxo)
s[WW].compute_at(s[OL], rxo)
for load in [AA, WW]:
n, f, y, x = s[load].op.axis
fused = s[load].fuse(n, f, y, x)
tz, fused = s[load].split(fused, nparts=cfg["tile_f"].size[2])
ty, fused = s[load].split(fused, nparts=cfg["tile_y"].size[2])
tx, fused = s[load].split(fused, nparts=cfg["tile_x"].size[2])
s[load].bind(tz, tvm.thread_axis("threadIdx.z"))
s[load].bind(ty, tvm.thread_axis("threadIdx.y"))
s[load].bind(tx, tvm.thread_axis("threadIdx.x"))
s[output].pragma(kernel_scope, 'auto_unroll_max_step', cfg['auto_unroll_max_step'].val)
s[output].pragma(kernel_scope, 'unroll_explicit', cfg['unroll_explicit'].val)
AutoTVM 使用例
• CUDA バックエンドの Direct Convolution
スケジュール
• Thread block, 共有メモリの大きさなどが
チューニングされる
tvm/topi/python/topi/cuda/conv2d_direct.py
より抜粋
AutoTVM についての詳細は, チュートリアル
及び 論文を参照](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-27-320.jpg)








![Winograd アルゴリズム を使う
• 入力サイズとフィルター数を, Winograd Convolution に適したものに変更
• Direct Convolution が Winograd Convolution に置き換わる
Graph(%data, %transpose0, %conv2d0_bias, %batch_norm0_gamma_mul_div_expand, %batch_norm0_add_beta_expand,
%dense0_weight,%dense0_bias) {
%5 = tvm_op(%data, %transpose0, %conv2d0_bias, %batch_norm0_gamma_mul_div_expand, %batch_norm0_add_beta_expand,
num_outputs='1', num_inputs='5', flatten_data='0',
func_name='fuse__contrib_conv2d_winograd_without_weight_transform_broadcast_mul_broadcast_add_relu’)
%6 = tvm_op(%5, num_outputs='1', num_inputs='1', flatten_data='0', func_name='fuse_max_pool2d’)
%7 = tvm_op(%6, num_outputs='1', num_inputs='1', flatten_data='0', func_name='fuse_flatten’)
%10 = tvm_op(%7, %dense0_weight, %dense0_bias, num_outputs='1', num_inputs='3', flatten_data='0', func_name='fuse_dense’)
%11 = tvm_op(%10, num_outputs='1', num_inputs='1', flatten_data='0', func_name='fuse_softmax’)
ret %11
}
net = get_net(filters=64)
in_shape = (1, 64, 56, 56)
net, params = utils.create_workload(net, 1, in_shape[1:])
with nnvm.compiler.build_config(opt_level=3):
graph, lib, params = nnvm.compiler.build(net, target, {"data": in_shape}, params=params)](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-36-320.jpg)







![Operator Fusion: CUDA カーネル
for (int rc_inner = 0; rc_inner < 4; ++rc_inner) {
for (int ry_inner = 0; ry_inner < 3; ++ry_inner) {
for (int rx_inner = 0; rx_inner < 3; ++rx_inner) {
for (int ff = 0; ff < 2; ++ff) {
for (int xx = 0; xx < 2; ++xx) {
compute[((ff * 2) + xx)] = (compute[((ff * 2) + xx)] + (pad_temp_shared[((((((((int)threadIdx.y) * 8) +
(((int)threadIdx.x) * 2)) + (rc_inner * 32)) + (ry_inner * 8)) + rx_inner) + xx)] * input1_shared[(((((((int)threadIdx.z)
* 72) + (rc_inner * 9)) + (ry_inner * 3)) + rx_inner) + (ff * 36))]));
}
}
}
}
}
for (int ax1_inner_inner_inner = 0; ax1_inner_inner_inner < 2; ++ax1_inner_inner_inner) {
for (int ax3_inner_inner_inner = 0; ax3_inner_inner_inner < 2; ++ax3_inner_inner_inner) {
tensor[(((((((((int)blockIdx.y) * 108) + (((int)blockIdx.x) * 6)) + (((int)threadIdx.z) * 5832)) +
(((int)threadIdx.y) * 54)) + (((int)threadIdx.x) * 2)) + (ax1_inner_inner_inner * 2916)) + ax3_inner_inner_inner)] =
max((((compute[(((ax1_inner_inner_inner * 2) + ax3_inner_inner_inner) - (((int)blockIdx.z) * 4))] +
input2[((((int)threadIdx.z) * 2) + ax1_inner_inner_inner)]) * input3[((((int)threadIdx.z) * 2) + ax1_inner_inner_inner)])
+ input4[((((int)threadIdx.z) * 2) + ax1_inner_inner_inner)]), 0.000000e+00f);
}
}
• 生成された CUDA カーネルより一部を抜粋](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-45-320.jpg)


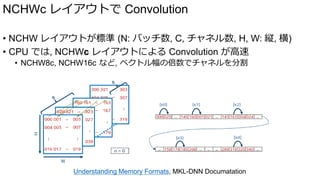
![[WIP] Graph level Auto Tuning
• AutoTVM によって, オペレータ (ノード) 単位のチューニングが可能になった
• だが, 入力のレイアウトは固定 (NCHW, NCHW[8, 16, 32…]c)
• 最適なレイアウトは入力によって変わりうる
→ レイアウト変換のコストを考慮したグラフ全体のチューニングが必要
離散最適化問題を解くことになる
同様の問題を扱った論文
Optimal DNN Primitive Selection with Partitioned
Boolean Quadratic Programming, CGO 2018
Node A
Node B
NCHW8c NCHW16c NCHW32c
NCHW8c 0 0.1 0.25
NCHW16c 0.12 0 0.2
NCHW32c 0.3 0.18 0
レイアウト変換コスト
NCHW8c 3.2
NCHW16c 2.8
NCHW32c 3.0
NCHW8c 2.6
NCHW16c 2.75
NCHW32c 2.5
ノードコスト
ノードコスト](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-48-320.jpg)
![[WIP] Relay – NNVM IR v2
• 詳細は LT にて, または論文を参照
• NNVM IR の言語としての記述力は限られている
→ 正真正銘のプログラミング言語を組み込んでしまえ!
• 純粋関数型言語 + Tensor の各次元数を埋め込んだ型システム
• 各グラフ変換パスの, Relay IR 変換パスへの再実装が進行中
• Operator fusion, 自動微分など](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-49-320.jpg)









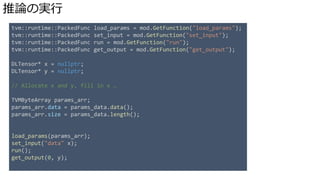

![TVM とコミュニティ
• コントリビュータやユーザーを主体としたコミュニティづくりを重視
より詳しくは, TVM Community Structure, [RFC] Community Guideline Improvements
しばらくコントリビュートしていると,
レビューアになってくれと頼まれる](https://image.slidesharecdn.com/tvmintro-181108053329/85/TVM-64-320.jpg)






















![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[第2版]Python機械学習プログラミング 第14章](https://cdn.slidesharecdn.com/ss_thumbnails/14-190318023253-thumbnail.jpg?width=640&height=640&fit=bounds)













