Recommended
PDF
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
PDF
PDF
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ)
PDF
PDF
PDF
PDF
PPTX
PDF
PDF
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能
PDF
汎用性と高速性を目指したペアリング暗号ライブラリ mcl
PDF
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
KEY
PDF
PDF
KEY
PDF
PDF
Wavelet matrix implementation
PDF
PDF
組み込み関数(intrinsic)によるSIMD入門
PPTX
PDF
WASM(WebAssembly)入門 ペアリング演算やってみた
PDF
PDF
Effective Modern C++ 読書会 Item 35
PDF
PDF
ElGamal型暗号文に対する任意関数演算・再暗号化の二者間秘密計算プロトコルとその応用
PDF
PDF
Code iq interpretation_tanaka_publish
PDF
More Related Content
PDF
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
PDF
PDF
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ)
PDF
PDF
PDF
PDF
What's hot
PPTX
PDF
PDF
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能
PDF
汎用性と高速性を目指したペアリング暗号ライブラリ mcl
PDF
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
KEY
PDF
PDF
KEY
PDF
PDF
Wavelet matrix implementation
PDF
PDF
組み込み関数(intrinsic)によるSIMD入門
PPTX
PDF
WASM(WebAssembly)入門 ペアリング演算やってみた
PDF
PDF
Effective Modern C++ 読書会 Item 35
PDF
PDF
ElGamal型暗号文に対する任意関数演算・再暗号化の二者間秘密計算プロトコルとその応用
PDF
Viewers also liked
PDF
Code iq interpretation_tanaka_publish
PDF
PDF
[計算シミュレーション勉強会#1] 粒子法の復習(陽解法と陰解法の比較から)
PDF
Webの未来 〜 PNaClとasm.jsでカワルミライ - いま、モバイルWebの先端で起こっていること
PPTX
PDF
OpenMPSみんな使ってねー[第36回オープンCAE勉強会@関東]
PPTX
TechFeedのつくりかた - Angular2/Webpack/Ionic2/Cordova実践入門
PDF
1075: .NETからCUDAを使うひとつの方法
PDF
C#, C/CLI と CUDAによる画像処理ことはじめ
PDF
Similar to 関東GPGPU勉強会 LLVM meets GPU
PDF
KEY
NVIDIA Japan Seminar 2012
PDF
KEY
PDF
Maxwell と Java CUDAプログラミング
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
PDF
1072: アプリケーション開発を加速するCUDAライブラリ
KEY
DOC
GPGPUによるパーソナルスーパーコンピュータの可能性
PDF
PPTX
もしも… Javaでヘテロジニアスコアが使えたら…
PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
PDF
PDF
PDF
PDF
Intel AVX2を使用したailia sdkの最適化
PDF
【A-1】AIを支えるGPUコンピューティングの今
PDF
PDF
【関東GPGPU勉強会#4】GTX 1080でComputer Vision�アルゴリズムを色々動かしてみる
PPTX
x86-64/Linuxに独自メモリ空間を勝手増設
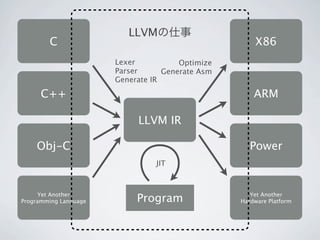
関東GPGPU勉強会 LLVM meets GPU 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. LLVMの仕事
C X86
Lexer Optimize
Parser Generate Asm
Generate IR
C++ ARM
LLVM IR
Obj-C Power
JIT
Yet Another
Programming Language Program Yet Another
Hardware Platform
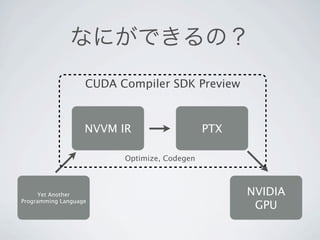
12. 13. 14. 15. 16. 17. 18. なにができるの?
CUDA Compiler SDK Preview
NVVM IR PTX
Optimize, Codegen
Yet Another NVIDIA
Programming Language
GPU
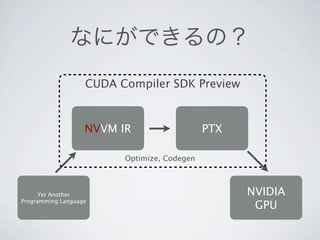
19. 20. なにができるの?
CUDA Compiler SDK Preview
NVVM IR PTX
Optimize, Codegen
Yet Another NVIDIA
Programming Language
GPU
21. 22. 23. 24. 細かい話
• __device__、 __constant__などはLLVMのaddress space
number という概念で表される
• __global__関数、__device__関数などの種別はmetadataという
仕組みで表される
• 追加の組み込み関数が幾つか(nvvm.*)
• 同期、テクスチャ/サーフェス、特殊レジスタ、etc..
25. NVVM Library API
• Start and Shutdown
• Create Compiler Unit
• Verify
• Compile To PTX
• Get Result
26. 28. 29. 31. 32. 1 import pycuda.driver as drv
2 import pycuda.tools
3 import pycuda.autoinit
4 import numpy
5 import numpy.linalg as la
6 from pycuda.compiler import SourceModule
7
8 mod = SourceModule("""
9 __global__ void multiply_them(float *dest, float *a, float *b)
10 {
11 const int i = threadIdx.x;
12 dest[i] = a[i] * b[i];
13 }
14 """)
15
16 multiply_them = mod.get_function("multiply_them")
17
18 a = numpy.random.randn(400).astype(numpy.float32)
19 b = numpy.random.randn(400).astype(numpy.float32)
20
21 dest = numpy.zeros_like(a)
22 multiply_them(
23 drv.Out(dest), drv.In(a), drv.In(b),
24 block=(400,1,1))
25
26 print dest-a*b
PythonからGPUプログラミングが簡単にできる!
33. 34. 4 import numpy
5 import numpy.linalg as la
6 from pycuda.compiler import SourceModule
7
8 mod = SourceModule("""
9 __global__ void multiply_them(float *dest, float *a, float *b)
10 {
11 const int i = threadIdx.x;
12 dest[i] = a[i] * b[i];
13 }
14 """)
15
16 multiply_them = mod.get_function("multiply_them")
17
18 a = numpy.random.randn(400).astype(numpy.float32)
19 b = numpy.random.randn(400).astype(numpy.float32)
20
21 dest = numpy.zeros_like(a)
22 multiply_them(
23 drv.Out(dest), drv.In(a), drv.In(b),
24 block=(400,1,1))
35. 8 mod = SourceModule("""
9 __global__ void multiply_them(float *dest, float *a,
float *b)
10 {
11 const int i = threadIdx.x;
12 dest[i] = a[i] * b[i];
13 }
14 """)
36. 38. 1 import pycuda.driver as drv
2 import pycuda.tools
3 import pycuda.autoinit
4 import numpy
5 import numpy.linalg as la
6 from pycuda.compiler import SourceModule
7
8 @kernel
9 def multiply_them(dest, a, b):
10 i = threadIdx.x
11 dest[i] = a[i] * b[i];
12
こんなかんじで書きたい
13 a = numpy.random.randn(400).astype(numpy.float32)
14 b = numpy.random.randn(400).astype(numpy.float32)
15
16 dest = numpy.zeros_like(a)
17 multiply_them(
18 drv.Out(dest), drv.In(a), drv.In(b),
19 block=(400,1,1))
20
21 print dest-a*b
39. 40. @kernelデコレータで
1 import numpy as np
2
3 from pynvvm.kernel import kernel コード生成
4 from pynvvm.nvtype import array, float32, int32
5
6 @kernel(array(float32), array(float32), array(float32), float32(), int32(), int32())
7 def saxpy(z, x, y, a, w, h):
8 xidx = pynvvm_ctaid_x() * pynvvm_ntid_x() + pynvvm_tid_x()
9 yidx = pynvvm_ctaid_y() * pynvvm_ntid_y() + pynvvm_tid_y()
10
11 if yidx < h and xidx < w: 専用のintrinsic
12 i = yidx * w + xidx
13 z[i] = a * x[i] + y[i]
14
15 return
16
17 n = 1024
18
19 x = np.random.randn(n*n).astype(np.float32)
20 y = np.random.randn(n*n).astype(np.float32)
21 a = np.float32(2.71828183)
22
23 z = np.zeros_like(x)
24
25 bsz = (16, 16, 1) In, Outはコード生成時に
26 gsz = ((n+16-1)/16, (n+16-1)/16, 1)
27
28 saxpy(bsz, gsz)(z, x, y, a, np.int32(n), np.int32(n)) 解析して自動転送
29
30 print(z)
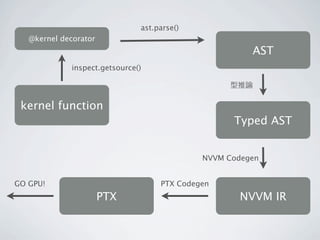
41. ast.parse()
@kernel decorator
AST
inspect.getsource()
型推論
kernel function
Typed AST
NVVM Codegen
GO GPU! PTX Codegen
PTX NVVM IR
42. 43. つくったもの
• LLVM LibraryのPython Binding
• boost::pythonすばらしい
• NVVM LibraryのPython Binding
• CTypesすばらしい
• Python AST -> NVVM IRのトランスレータ
44. 45. 46. 47. 48. 49. 50. まとめ
• NVVM IRはLLVM IR Builderで作れるので
オレオレ言語をGPUで動かすのもカンタン!
• アホなIR作っても色々最適化してくれるのでハッピー
• みんなもCUDA Compiler SDKであそぼう
51. Related Works
• py2llvm
• python -> LLVM IR
• http://code.google.com/p/py2llvm/
• copperhead
• 自動並列化
• http://code.google.com/p/copperhead/
52.





























![1 import pycuda.driver as drv
2 import pycuda.tools
3 import pycuda.autoinit
4 import numpy
5 import numpy.linalg as la
6 from pycuda.compiler import SourceModule
7
8 mod = SourceModule("""
9 __global__ void multiply_them(float *dest, float *a, float *b)
10 {
11 const int i = threadIdx.x;
12 dest[i] = a[i] * b[i];
13 }
14 """)
15
16 multiply_them = mod.get_function("multiply_them")
17
18 a = numpy.random.randn(400).astype(numpy.float32)
19 b = numpy.random.randn(400).astype(numpy.float32)
20
21 dest = numpy.zeros_like(a)
22 multiply_them(
23 drv.Out(dest), drv.In(a), drv.In(b),
24 block=(400,1,1))
25
26 print dest-a*b
PythonからGPUプログラミングが簡単にできる!](https://image.slidesharecdn.com/gpgpustudy-120602020510-phpapp01/85/GPGPU-LLVM-meets-GPU-32-320.jpg)

![4 import numpy
5 import numpy.linalg as la
6 from pycuda.compiler import SourceModule
7
8 mod = SourceModule("""
9 __global__ void multiply_them(float *dest, float *a, float *b)
10 {
11 const int i = threadIdx.x;
12 dest[i] = a[i] * b[i];
13 }
14 """)
15
16 multiply_them = mod.get_function("multiply_them")
17
18 a = numpy.random.randn(400).astype(numpy.float32)
19 b = numpy.random.randn(400).astype(numpy.float32)
20
21 dest = numpy.zeros_like(a)
22 multiply_them(
23 drv.Out(dest), drv.In(a), drv.In(b),
24 block=(400,1,1))](https://image.slidesharecdn.com/gpgpustudy-120602020510-phpapp01/85/GPGPU-LLVM-meets-GPU-34-320.jpg)
![8 mod = SourceModule("""
9 __global__ void multiply_them(float *dest, float *a,
float *b)
10 {
11 const int i = threadIdx.x;
12 dest[i] = a[i] * b[i];
13 }
14 """)](https://image.slidesharecdn.com/gpgpustudy-120602020510-phpapp01/85/GPGPU-LLVM-meets-GPU-35-320.jpg)


![1 import pycuda.driver as drv
2 import pycuda.tools
3 import pycuda.autoinit
4 import numpy
5 import numpy.linalg as la
6 from pycuda.compiler import SourceModule
7
8 @kernel
9 def multiply_them(dest, a, b):
10 i = threadIdx.x
11 dest[i] = a[i] * b[i];
12
こんなかんじで書きたい
13 a = numpy.random.randn(400).astype(numpy.float32)
14 b = numpy.random.randn(400).astype(numpy.float32)
15
16 dest = numpy.zeros_like(a)
17 multiply_them(
18 drv.Out(dest), drv.In(a), drv.In(b),
19 block=(400,1,1))
20
21 print dest-a*b](https://image.slidesharecdn.com/gpgpustudy-120602020510-phpapp01/85/GPGPU-LLVM-meets-GPU-38-320.jpg)

![@kernelデコレータで
1 import numpy as np
2
3 from pynvvm.kernel import kernel コード生成
4 from pynvvm.nvtype import array, float32, int32
5
6 @kernel(array(float32), array(float32), array(float32), float32(), int32(), int32())
7 def saxpy(z, x, y, a, w, h):
8 xidx = pynvvm_ctaid_x() * pynvvm_ntid_x() + pynvvm_tid_x()
9 yidx = pynvvm_ctaid_y() * pynvvm_ntid_y() + pynvvm_tid_y()
10
11 if yidx < h and xidx < w: 専用のintrinsic
12 i = yidx * w + xidx
13 z[i] = a * x[i] + y[i]
14
15 return
16
17 n = 1024
18
19 x = np.random.randn(n*n).astype(np.float32)
20 y = np.random.randn(n*n).astype(np.float32)
21 a = np.float32(2.71828183)
22
23 z = np.zeros_like(x)
24
25 bsz = (16, 16, 1) In, Outはコード生成時に
26 gsz = ((n+16-1)/16, (n+16-1)/16, 1)
27
28 saxpy(bsz, gsz)(z, x, y, a, np.int32(n), np.int32(n)) 解析して自動転送
29
30 print(z)](https://image.slidesharecdn.com/gpgpustudy-120602020510-phpapp01/85/GPGPU-LLVM-meets-GPU-40-320.jpg)









































![[計算シミュレーション勉強会#1] 粒子法の復習(陽解法と陰解法の比較から)](https://cdn.slidesharecdn.com/ss_thumbnails/computationalsimulation1-131012213950-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![OpenMPSみんな使ってねー[第36回オープンCAE勉強会@関東]](https://cdn.slidesharecdn.com/ss_thumbnails/opencaekanto36-140222004810-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























