Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Fixstars Corporation
PPTX, PDF
2,173 views
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
2022年1月28日開催の「CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編」セミナー資料です。
Technology
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 77 times
1
/ 57
2
/ 57
3
/ 57
4
/ 57
5
/ 57
6
/ 57
7
/ 57
8
/ 57
9
/ 57
10
/ 57
11
/ 57
12
/ 57
13
/ 57
14
/ 57
15
/ 57
16
/ 57
17
/ 57
18
/ 57
19
/ 57
20
/ 57
21
/ 57
22
/ 57
23
/ 57
24
/ 57
25
/ 57
Most read
26
/ 57
Most read
27
/ 57
28
/ 57
29
/ 57
30
/ 57
31
/ 57
32
/ 57
33
/ 57
34
/ 57
35
/ 57
36
/ 57
37
/ 57
Most read
38
/ 57
39
/ 57
40
/ 57
41
/ 57
42
/ 57
43
/ 57
44
/ 57
45
/ 57
46
/ 57
47
/ 57
48
/ 57
49
/ 57
50
/ 57
51
/ 57
52
/ 57
53
/ 57
54
/ 57
55
/ 57
56
/ 57
57
/ 57
More Related Content
PDF
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
PDF
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
PDF
マルチコアを用いた画像処理
by
Norishige Fukushima
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
PDF
ARM CPUにおけるSIMDを用いた高速計算入門
by
Fixstars Corporation
PDF
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
PDF
プログラムを高速化する話
by
京大 マイコンクラブ
PDF
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
マルチコアを用いた画像処理
by
Norishige Fukushima
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
ARM CPUにおけるSIMDを用いた高速計算入門
by
Fixstars Corporation
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
プログラムを高速化する話
by
京大 マイコンクラブ
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
What's hot
PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
by
Takateru Yamagishi
PDF
Intro to SVE 富岳のA64FXを触ってみた
by
MITSUNARI Shigeo
PDF
1076: CUDAデバッグ・プロファイリング入門
by
NVIDIA Japan
PDF
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
PDF
直交領域探索
by
okuraofvegetable
PDF
明日使えないすごいビット演算
by
京大 マイコンクラブ
PPTX
AVX-512(フォーマット)詳解
by
MITSUNARI Shigeo
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
強化学習その2
by
nishio
PDF
20分くらいでわかった気分になれるC++20コルーチン
by
yohhoy
PPTX
Slurmのジョブスケジューリングと実装
by
Ryuichi Sakamoto
PDF
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
PDF
GoogleのSHA-1のはなし
by
MITSUNARI Shigeo
PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
by
MITSUNARI Shigeo
PPTX
backbone としての timm 入門
by
Takuji Tahara
PDF
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
PDF
llvm入門
by
MITSUNARI Shigeo
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PDF
最適化超入門
by
Takami Sato
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
by
Takateru Yamagishi
Intro to SVE 富岳のA64FXを触ってみた
by
MITSUNARI Shigeo
1076: CUDAデバッグ・プロファイリング入門
by
NVIDIA Japan
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
直交領域探索
by
okuraofvegetable
明日使えないすごいビット演算
by
京大 マイコンクラブ
AVX-512(フォーマット)詳解
by
MITSUNARI Shigeo
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
強化学習その2
by
nishio
20分くらいでわかった気分になれるC++20コルーチン
by
yohhoy
Slurmのジョブスケジューリングと実装
by
Ryuichi Sakamoto
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
GoogleのSHA-1のはなし
by
MITSUNARI Shigeo
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
by
MITSUNARI Shigeo
backbone としての timm 入門
by
Takuji Tahara
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
llvm入門
by
MITSUNARI Shigeo
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
最適化超入門
by
Takami Sato
Similar to CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
PDF
2015年度先端GPGPUシミュレーション工学特論 第6回 プログラムの性能評価指針 (Flop/Byte,計算律速,メモリ律速)
by
智啓 出川
PDF
計算機アーキテクチャを考慮した高能率画像処理プログラミング
by
Norishige Fukushima
PDF
R-hpc-1 TokyoR#11
by
Shintaro Fukushima
PPTX
Prelude to Halide
by
Akira Maruoka
PDF
第64回情報科学談話会(滝沢 寛之 准教授)
by
gsis gsis
PPTX
Java でつくる 低レイテンシ実装の技巧
by
Ryosuke Yamazaki
PDF
性能測定道 事始め編
by
Yuto Hayamizu
PDF
アプリケーションの性能最適化2(CPU単体性能最適化)
by
RCCSRENKEI
PDF
ソフト高速化の専門家が教える!AI・IoTエッジデバイスの選び方
by
Fixstars Corporation
PPTX
DIC-PCGソルバーのpimpleFoamに対する時間計測と高速化
by
Fixstars Corporation
PDF
金融業界向けセミナー 量子コンピュータ時代を見据えた組合せ最適化
by
Fixstars Corporation
PDF
アドテク×Scala×パフォーマンスチューニング
by
Yosuke Mizutani
PDF
情報システムの性能マネジメントについて
by
Takashi Natsume
PDF
第4回 配信講義 計算科学技術特論A (2021)
by
RCCSRENKEI
PDF
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
PDF
第5回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
PDF
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
PDF
Ac ri lt_fixstars_20210720
by
直久 住川
PDF
CMSI計算科学技術特論A(9) 高速化チューニングとその関連技術2
by
Computational Materials Science Initiative
PDF
プロファイラGuiを用いたコード分析 20160610
by
HIDEOMI SUZUKI
2015年度先端GPGPUシミュレーション工学特論 第6回 プログラムの性能評価指針 (Flop/Byte,計算律速,メモリ律速)
by
智啓 出川
計算機アーキテクチャを考慮した高能率画像処理プログラミング
by
Norishige Fukushima
R-hpc-1 TokyoR#11
by
Shintaro Fukushima
Prelude to Halide
by
Akira Maruoka
第64回情報科学談話会(滝沢 寛之 准教授)
by
gsis gsis
Java でつくる 低レイテンシ実装の技巧
by
Ryosuke Yamazaki
性能測定道 事始め編
by
Yuto Hayamizu
アプリケーションの性能最適化2(CPU単体性能最適化)
by
RCCSRENKEI
ソフト高速化の専門家が教える!AI・IoTエッジデバイスの選び方
by
Fixstars Corporation
DIC-PCGソルバーのpimpleFoamに対する時間計測と高速化
by
Fixstars Corporation
金融業界向けセミナー 量子コンピュータ時代を見据えた組合せ最適化
by
Fixstars Corporation
アドテク×Scala×パフォーマンスチューニング
by
Yosuke Mizutani
情報システムの性能マネジメントについて
by
Takashi Natsume
第4回 配信講義 計算科学技術特論A (2021)
by
RCCSRENKEI
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
第5回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
Ac ri lt_fixstars_20210720
by
直久 住川
CMSI計算科学技術特論A(9) 高速化チューニングとその関連技術2
by
Computational Materials Science Initiative
プロファイラGuiを用いたコード分析 20160610
by
HIDEOMI SUZUKI
More from Fixstars Corporation
PPTX
製造業向け量子コンピュータ時代のDXセミナー_生産計画最適化_20220323.pptx
by
Fixstars Corporation
PDF
製造業向け量子コンピュータ時代のDXセミナー~ 最適化の中身を覗いてみよう~
by
Fixstars Corporation
PPTX
製造業向け量子コンピュータ時代のDXセミナー ~見える化、分析、予測、その先の最適化へ~
by
Fixstars Corporation
PDF
株式会社フィックスターズの会社説明資料(抜粋)
by
Fixstars Corporation
PDF
Fpga online seminar by fixstars (1st)
by
Fixstars Corporation
PDF
Jetson活用セミナー ROS2自律走行実現に向けて
by
Fixstars Corporation
PDF
量子コンピュータ時代の製造業におけるDXセミナー~生産工程効率化に向けた新たなご提案~
by
Fixstars Corporation
PDF
株式会社フィックスターズ 会社説明資料(抜粋)
by
Fixstars Corporation
PDF
株式会社フィックスターズ 会社説明資料(抜粋)
by
Fixstars Corporation
PDF
AIチップ戦国時代における深層学習モデルの推論の最適化と実用的な運用を可能にするソフトウェア技術について
by
Fixstars Corporation
PDF
株式会社フィックスターズ 会社説明資料(抜粋)
by
Fixstars Corporation
PPTX
第8回 社内プログラミングコンテスト 結果発表会
by
Fixstars Corporation
PPTX
第8回 社内プログラミングコンテスト 第1位 taiyo
by
Fixstars Corporation
PPTX
第8回 社内プログラミングコンテスト 第2位 fy999
by
Fixstars Corporation
PPTX
第8回 社内プログラミングコンテスト 第3位 logicmachine
by
Fixstars Corporation
PPTX
株式会社フィックスターズ 会社説明資料(抜粋)
by
Fixstars Corporation
PPTX
A challenge for thread parallelism on OpenFOAM
by
Fixstars Corporation
PDF
マルチレイヤコンパイラ基盤による、エッジ向けディープラーニングの実装と最適化について
by
Fixstars Corporation
PDF
自動運転におけるCNNの信頼性
by
Fixstars Corporation
PDF
NVMCT #1 3D NANDフラッシュメモリの動向 (Trend of 3D NAND Flash Memory)
by
Fixstars Corporation
製造業向け量子コンピュータ時代のDXセミナー_生産計画最適化_20220323.pptx
by
Fixstars Corporation
製造業向け量子コンピュータ時代のDXセミナー~ 最適化の中身を覗いてみよう~
by
Fixstars Corporation
製造業向け量子コンピュータ時代のDXセミナー ~見える化、分析、予測、その先の最適化へ~
by
Fixstars Corporation
株式会社フィックスターズの会社説明資料(抜粋)
by
Fixstars Corporation
Fpga online seminar by fixstars (1st)
by
Fixstars Corporation
Jetson活用セミナー ROS2自律走行実現に向けて
by
Fixstars Corporation
量子コンピュータ時代の製造業におけるDXセミナー~生産工程効率化に向けた新たなご提案~
by
Fixstars Corporation
株式会社フィックスターズ 会社説明資料(抜粋)
by
Fixstars Corporation
株式会社フィックスターズ 会社説明資料(抜粋)
by
Fixstars Corporation
AIチップ戦国時代における深層学習モデルの推論の最適化と実用的な運用を可能にするソフトウェア技術について
by
Fixstars Corporation
株式会社フィックスターズ 会社説明資料(抜粋)
by
Fixstars Corporation
第8回 社内プログラミングコンテスト 結果発表会
by
Fixstars Corporation
第8回 社内プログラミングコンテスト 第1位 taiyo
by
Fixstars Corporation
第8回 社内プログラミングコンテスト 第2位 fy999
by
Fixstars Corporation
第8回 社内プログラミングコンテスト 第3位 logicmachine
by
Fixstars Corporation
株式会社フィックスターズ 会社説明資料(抜粋)
by
Fixstars Corporation
A challenge for thread parallelism on OpenFOAM
by
Fixstars Corporation
マルチレイヤコンパイラ基盤による、エッジ向けディープラーニングの実装と最適化について
by
Fixstars Corporation
自動運転におけるCNNの信頼性
by
Fixstars Corporation
NVMCT #1 3D NANDフラッシュメモリの動向 (Trend of 3D NAND Flash Memory)
by
Fixstars Corporation
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
1.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Copyright © Fixstars Group CPU / GPU 高速化セミナー 性能モデルの理論と実践:理論編
2.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 本ウェビナーは 2部構成 2 • 理論編(本日) • 実践編(近日開催予定!)
3.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 発表者紹介 3 • 冨田 明彦(とみた あきひこ) ソリューションカンパニー 営業企画執行役 2008年に入社。金融、医療業界において、 ソフトウェア高速化業務に携わる。その 後、新規事業企画、半導体業界の事業を 担当し、現職。 • 秋山 茂樹(あきやま しげき) ソリューション第一事業部 リードエンジニア 2016年に入社。主に画像処理・機械学習 ソフトウェアについて x86-64 CPU や NVIDIA/AMD GPU, InfiniBand を用い た高速化業務を担当。
4.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 本日のAgenda はじめに (15分) • 性能に関する課題 • 高速化サービスと開発の流れ 性能モデルの理論と検証 (60分) • 性能モデルが必要となる背景 • 性能モデルとは • ルーフラインモデル • ベンチマークによるルーフラインモデルの検証 Q&A / 告知 4
5.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Copyright © Fixstars Group はじめに
6.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 性能に関する課題 6 生産効率の向上 • より短時間で欠陥検出 • より安価なハードで 安全性の向上 • より精度の高い物体検出 • より低消費電力なハードで
7.
Fixstars Group www.fixstars.com Copyright
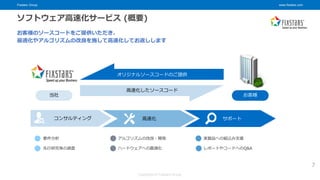
© Fixstars Group ソフトウェア高速化サービス (概要) お客様のソースコードをご提供いただき、 最適化やアルゴリズムの改良を施して高速化してお返しします 当社 お客様 オリジナルソースコードのご提供 高速化したソースコード コンサルティング 高速化 サポート 要件分析 先行研究等の調査 アルゴリズムの改良・開発 ハードウェアへの最適化 実製品への組込み支援 レポートやコードへのQ&A 7
8.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group ソフトウェア高速化サービス 様々な領域でソフトウェア高速化サービスを提供しています 大量データの高速処理は、お客様の製品競争力の源泉となっています ・NAND型フラッシュメモリ向けファー ムウェア開発 ・次世代AIチップ向け開発環境基盤開発 Semiconductor ・デリバティブシステムの高速化 ・HFT(アルゴリズムトレード)の高速化 Finance ・自動運転の高性能化、実用化 ・次世代パーソナルモビリティの研究開発 Mobility ・ゲノム解析の高速化 ・医用画像処理の高速化 ・AI画像診断システムの研究開発 Life Science ・Smart Factory化支援 ・マシンビジョンシステムの高速化 Industrial 8
9.
Fixstars Group www.fixstars.com Copyright
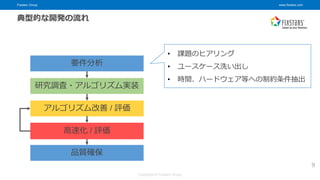
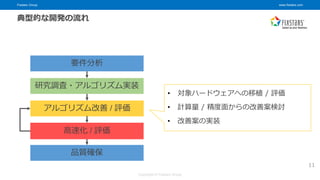
© Fixstars Group 9 要件分析 研究調査・アルゴリズム実装 高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • 課題のヒアリング • ユースケース洗い出し • 時間、ハードウェア等への制約条件抽出
10.
Fixstars Group www.fixstars.com Copyright
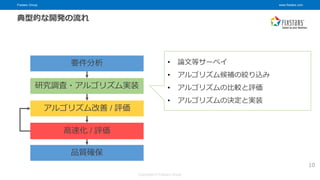
© Fixstars Group 10 要件分析 研究調査・アルゴリズム実装 高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • 論文等サーベイ • アルゴリズム候補の絞り込み • アルゴリズムの比較と評価 • アルゴリズムの決定と実装
11.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 11 要件分析 研究調査・アルゴリズム実装 高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • 対象ハードウェアへの移植 / 評価 • 計算量 / 精度面からの改善案検討 • 改善案の実装
12.
Fixstars Group www.fixstars.com Copyright
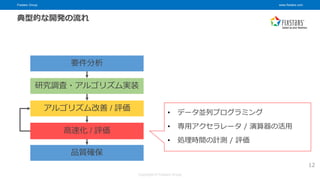
© Fixstars Group 12 要件分析 研究調査・アルゴリズム実装 高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • データ並列プログラミング • 専用アクセラレータ / 演算器の活用 • 処理時間の計測 / 評価
13.
Fixstars Group www.fixstars.com Copyright
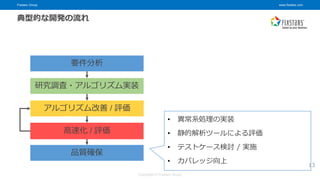
© Fixstars Group 13 要件分析 研究調査・アルゴリズム実装 高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • 異常系処理の実装 • 静的解析ツールによる評価 • テストケース検討 / 実施 • カバレッジ向上
14.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 本ウェビナーの対象プロセス 14 ココ 要件分析 研究調査・アルゴリズム実装 高速化 / 評価 アルゴリズム改善 / 評価 品質確保
15.
Fixstars Group www.fixstars.com Copyright
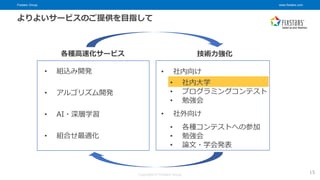
© Fixstars Group • 社内大学 • プログラミングコンテスト • 勉強会 • 各種コンテストへの参加 • 勉強会 • 論文・学会発表 • 社内向け • 社外向け よりよいサービスのご提供を目指して 15 • 組込み開発 • アルゴリズム開発 • AI・深層学習 • 組合せ最適化 各種高速化サービス 技術力強化
16.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Copyright © Fixstars Group 性能モデルの理論と検証
17.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 今回の話題 • CPU/GPU 高速化にあたって重要な「性能モデル」について紹介 • 場当たり的な高速化ではなく 理論的な分析を通した高速化のための枠組み • 「性能モデル」を用いると... • プログラムの性能の上限を見積ることができる • 高速化余地がどれくらいあるかわかる • 高速なシステムの設計に役立つ • 性能ボトルネックが何かあらかじめわかる 17
18.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 目次 • 性能モデルが必要となる背景 • 性能モデルとは • ルーフラインモデル • ベンチマークによるルーフラインモデルの検証 18
19.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Copyright © Fixstars Group 性能モデルが必要となる背景
20.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 典型的な高速化の流れ 1. 性能分析 • プロファイラを用いて以下を調査する • どの関数で時間がかかっているか • 関数のどの部分で時間がかかっているか • なぜ時間がかかっているか 2. 各種高速化テクニックを適用 • アルゴリズム変更 • 命令レベルの改善 (命令数削減, 近似命令の活用, SIMD化, etc.) • メモリアクセスの改善 (キャッシュの活用, アクセスパターン改善, etc.) • etc. 3. 以上を繰り返す 20
21.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 典型的な高速化の問題点 • 反復的な作業であるため、ゴールが見えない • 作業を始めるにあたって以下を明らかにしたい • 目標 • 高速化余地がどの程度あるか • 作業内容 • どういった高速化手法を適用すべきか、どの程度有効か • 工数 • 高速化作業にどの程度時間がかかるか • これらの疑問に答えるために性能モデルを活用できる 特に受託開発では これらをうまく説明できることが 顧客満足につながる 21
22.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Copyright © Fixstars Group 性能モデルとは
23.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 性能モデルとは • 性能モデル • 対象とするコンピュータを簡略化して プログラムの性能 (実行時間等) を定式化したもの • 目的 • あるプログラムがどの程度の性能を達成しうるか、 どのようにすればそれを達成できるかについて知見を得る • 厳密な性能予測を目的としたものではない 23
24.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 性能モデルの原始的な例 (1/3) • シンプルな性能モデル • 命令の種類ごとに実行回数を数えて重み付け • 命令数 • 浮動小数点演算: 2N • メモリアクセス数: 3N • 実行時間: T = F * 2N + M * 3N • F: 浮動小数点演算1命令あたり実行時間 • M: メモリアクセス1命令あたり実行時間 void SAXPY(int N, float a, const float *x, float *y) { for (int i = 0; i < N; ++i) y[i] = a * x[i] + y[i]; } F, M は理論演算性能, メモリ帯域から計算 24
25.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 性能モデルの原始的な例 (2/3) • N = 109 として計算してみる • プロセッサ: Core i7-4790 • クロック周波数: 3.6GHz • メモリ帯域: 25.6GB/s • 1コア1スレッドのみ使用 • 浮動小数点命令1回あたり実行時間 • F = 1 / (3.6*1e9) [sec] • メモリアクセス命令1回あたり実行時間 • M = 1 / (25.6*1e9 / 4) [sec] • プログラムの実行時間 • T = 2FN + 3MN = 1.02 [sec] • 実測した結果: 0.81 sec 25
26.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 性能モデルの原始的な例 (3/3) • 当然ながら、性能モデルによる予測と実測が合わない • 実行モデルと現実のプロセッサが乖離しているため • 性能モデルにより完璧に性能を予測できるわけではない • コンピュータのもつ多数の性質をモデル化するのは困難 • 「知見を得る」という目的に応じて考慮する性質を選択する 26
27.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group よく知られている性能モデル (のようなもの) • Computational complexity • アルゴリズムのリソース使用量 (演算量, メモリ使用量等) を解析 • キャッシュミス回数に対する cache complexity などもある • アムダールの法則 • プログラムの並列化効率を「並列化可能な処理の割合」から定式化 • DAG Execution Model • タスク並列プログラムにおける並列化効率の定式化 • ルーフラインモデル • プロセッサの演算性能・メモリ帯域および プログラムの演算数・メモリアクセス量を用いて 得られる演算性能を定式化 27
28.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Copyright © Fixstars Group ルーフラインモデル
29.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group ルーフラインモデル*1 • 概要 • プログラムが達成可能な演算性能 [FLOPS] を 見積もるための性能モデル • 考慮する要素 • プログラムにおける演算量・メモリアクセス量 • プロセッサの理論演算性能・メモリ帯域 • 実行モデル 29 プロセッサ メモリ 浮動小数点演算性能: π [GFLOPS] メモリ帯域: β [GB/sec] *1: Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009) キャッシュは考慮しない
30.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 補足1: プロセッサの演算性能とは • 1秒間に実行可能な浮動小数点演算数*1 • 単位: FLOPS (FLoating point number Operations per Seconds) • 例: Intel Core i7-4790 • クロック周波数: 3.6 GHz*2 (= clock/sec) • 1クロックあたり実行可能な浮動小数点演算数 (単精度の場合) • CPUコア数: 4 • CPUコアあたりSIMD演算器数: 2 • SIMDレーン数: 8 (AVX) • SIMDレーンあたり演算数: 2 (Fused Multiply-Add 命令) • 3.6 * 4 * 2 * 8 * 2 = 460.8 [GFLOPS] 30 *1: 整数演算が重要な場合は整数演算数で考える *2: 動的周波数制御 (Intel Turbo Boost 等) も 考慮する必要がある
31.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 補足2: メモリ帯域とは • 1秒間に読み書き可能なメモリアクセス量 • 単位: Byte/sec • 例: Intel Core i7-4790 • メモリ規格: DDR3-1600 (12.8 GB/s) • 最大メモリチャネル数: 2 • 積をとると 25.6 GB/s • あくまでスペック値なので実測した方がよい 31
32.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 演算強度と達成可能な性能 • 演算強度 (Operational Intensity, Arithmetic Intensity) • アプリにおける演算量とメモリアクセス量の比 • 達成可能な性能 (Attainable Performance) • 理論的に達成可能な性能の上限 演算強度 𝐼 [Flop/Byte] = 演算量 𝑊 [Flop] メモリアクセス量 𝑄 [Byte] 達成可能な性能 𝑃 [FLOPS] = min 理論演算性能 𝜋 [FLOPS] メモリ帯域 𝛽[Byte/sec] × 演算強度 𝐼 [Flop/Byte] プロセッサに対して 独立な指標 32 アプリの演算量・メモリアクセス量, プロセッサの演算性能・メモリ帯域から計算
33.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 達成可能な性能の導出 • 演算律速の場合: 性能 𝑃 = 𝜋 [FLOPS] • メモリ律速の場合: • メモリアクセスにかかる時間は メモリアクセス量 𝑄 メモリ帯域 𝛽 [sec] • 実行時間 = データ転送時間 なので 性能 𝑃 = 演算量 𝑊 データ転送時間 𝑄 𝛽 = 𝛽 × 𝐼 [FLOPS] 33 プロセッサ メモリ プロセッサ メモリ 常に演算が行われ メモリアクセスは断続的 常にメモリアクセスが行われ 演算は断続的 時間 処理開始 処理終了 時間 処理開始 処理終了
34.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group ルーフラインモデルが成立する前提条件 1. 演算とデータ転送が常に並行して行われる (or どちらかが支配的である) • 対象プログラムがそのように実装されている必要がある • Out-of-Order プロセッサなら意識しなくてもある程度満たしている 2. メモリ階層が単一である • キャッシュがある場合は以下を考慮して拡張する必要がある • メモリ – キャッシュ間データ転送帯域 • キャッシュ – レジスタ間データ転送帯域 • 演算性能 34
35.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 例: ナイーブな行列積の性能見積り (1/2) • 問題: 以下の行列積コードの得られる性能の上限は? • プロセッサの性能 • 浮動小数点演算性能: 4000 GFLOPS • メモリ帯域: 200 GB/sec • M = N = K = 1000, キャッシュは考慮しないものとする 36 float A[M * K], B[K * N], C[M * N]; for (int i = 0; i < M; ++i) { for (int j = 0; j < N; ++j) { float value = 0.0f; for (int k = 0; k < K; ++k) value += A[i * K + k] * B[k * N + j]; C[i * N + j] = value; } }
36.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 例: ナイーブな行列積の性能見積り (2/2) • 答え • 演算量 W = 2MNK = 2*10^9 [flop] • メモリアクセス量 Q = 8MNK + 4MN = 8*10^9 + 4*10^6 [byte] • 演算強度 I = W / Q ≈ 0.25 [flop/byte] • 達成可能な性能 P ≈ min(4000, 200 * 0.25) = 50 [GFLOPS] 37 どれだけ命令レベル高速化を頑張っても 理論演算性能比 1.25% の性能しか得られない*2 → データ局所性を活用して演算強度を上げる必要がある (実践編へ) 知見: ナイーブな行列積はメモリ律速*1 *1 プロセッサの演算性能を 4000 GFLOPS, メモリ帯域を 200 GB/s とした場合 *2 実際にはキャッシュ等の影響でこれ以上の性能となりうる
37.
Fixstars Group www.fixstars.com Copyright
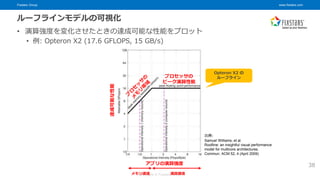
© Fixstars Group ルーフラインモデルの可視化 • 演算強度を変化させたときの達成可能な性能をプロット • 例: Opteron X2 (17.6 GFLOPS, 15 GB/s) 38 アプリの演算強度 達成可能な性能 Opteron X2 の ルーフライン プロセッサの ピーク演算性能 メモリ律速 演算律速 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009)
38.
Fixstars Group www.fixstars.com Copyright
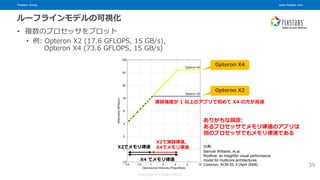
© Fixstars Group ルーフラインモデルの可視化 • 複数のプロセッサをプロット • 例: Opteron X2 (17.6 GFLOPS, 15 GB/s), Opteron X4 (73.6 GFLOPS, 15 GB/s) 39 ありがちな誤謬: あるプロセッサでメモリ律速のアプリは 別のプロセッサでもメモリ律速である X2でメモリ律速 X4 でメモリ律速 演算強度が 1 以上のアプリで初めて X4 の方が高速 X2で演算律速, X4でメモリ律速 Opteron X4 Opteron X2 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009)
39.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Computational Ceilings • ここまで考えてきた演算性能はピーク演算性能 • 実際には命令の並び次第で上限が決まる 40 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009) Fused Multiply-Add 命令を 使用しない場合の性能上限 SIMD命令不使用の場合の性能上限
40.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Bandwidth Ceilings • メモリ帯域についても同様 • 連続アクセス, Memory affininty, Prefetch, etc. 41 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009) プリフェッチを使用しない場合の 性能上限 Memory affinity を考慮しない場合の 性能上限
41.
Fixstars Group www.fixstars.com Copyright
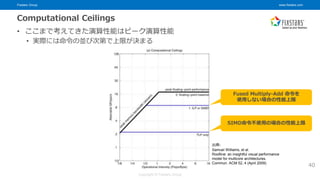
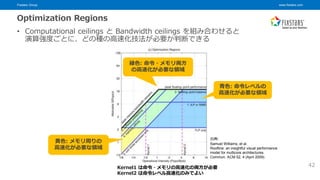
© Fixstars Group Optimization Regions • Computational ceilings と Bandwidth ceilings を組み合わせると 演算強度ごとに、どの種の高速化技法が必要か判断できる 黄色: メモリ周りの 高速化が必要な領域 緑色: 命令・メモリ両方 の高速化が必要な領域 青色: 命令レベルの 高速化が必要な領域 Kernel1 は命令・メモリの高速化の両方が必要 Kernel2 は命令レベル高速化のみでよい 42 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009)
42.
Fixstars Group www.fixstars.com Copyright
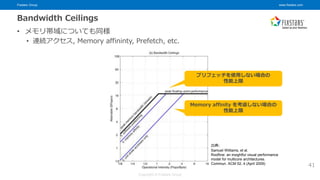
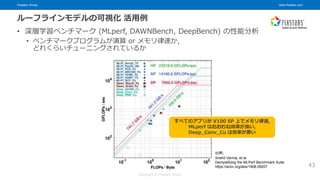
© Fixstars Group ルーフラインモデルの可視化 活用例 • 深層学習ベンチマーク (MLperf, DAWNBench, DeepBench) の性能分析 • ベンチマークプログラムが演算 or メモリ律速か, どれくらいチューニングされているか 43 出典: Snehil Verma, et al. Demystifying the MLPerf Benchmark Suite. https://arxiv.org/abs/1908.09207 すべてのアプリが V100 SP 上でメモリ律速, MLperf はおおむね効率が良い, Deep_Conv_Cu は効率が悪い
43.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group ピーク性能を達成するためには • 命令レベルの高速化 • SIMD, FMA 命令の活用 • 命令レベル並列性 (ILP) の改善 • パイプラインハザードを減らす (命令レイテンシ隠蔽, 分岐予測改善, etc.) • スーパースカラ (複数の実行ユニット) を活用する • スレッドレベル並列性 (TLP) の改善 • 演算器を使い切れるだけの並列性を供給する • 浮動小数点命令の割合を増やす (FP命令とそれ以外の命令が同じ演算器で実行される場合) • メモリアクセスの高速化 • 適切な粒度, 量, alignment でメモリアクセス • メモリアクセスレイテンシの隠蔽 (w/ ILP, TLP, Prefetch) • プロセッサ・メモリトポロジの考慮 • 演算強度の向上 • レジスタ, キャッシュ等のメモリ階層を活用 • その他 (ルーフラインモデルの範疇外) • 負荷分散の改善, 同期の削減, etc. 44
44.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group なぜルーフラインモデルが重要か • プログラムの性能を (ある程度) 見積もることができる • 高速化余地がどれくらいあるか • どのリソースがボトルネックか • 別のプロセッサに移植した場合にどの程度の性能となるか (→ 機種選定に役立つ) • 高速なソフトウェアの設計に役立つ • アルゴリズム選定, cache-aware algorithms で必要なキャッシュサイズ • 数ある高速化手法のうち、不要なものを事前に枝刈りできる • 試行錯誤を減らせるかも 45
45.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Copyright © Fixstars Group ベンチマークによる ルーフラインモデルの検証
46.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group ルーフラインモデルの検証 • ルーフラインモデルがどの程度正確か ベンチマークプログラムを用いて検証する • 演算性能の計測 • メモリ帯域の計測 • 演算・メモリ複合実行性能の計測 • 実験環境 • x86-64 CPU • Intel Core i7-3770 3.40GHz (IvyBridge), Ubuntu 18.04 • Intel Core i7-4790 3.60GHz (Haswell), WSL1 • Intel Core i7-6500U 2.50GHz (Skylake), WSL1 • AMD Ryzen 7 3700X 3.60GHz (Zen 2), Ubuntu 18.04 47
47.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 演算性能の計測 • ベンチマーク内容 • 1命令あたり8加算可能な vaddps 命令を大量に実行し 1秒あたりの演算回数 [FLOPS] を計測する*1 • 1コアのみ使用 48 __m256 vx = ..., vy = ...; auto vz0 = vx, vz1 = vx, vz2 = vx, vz3 = vx; auto vz4 = vx, vz5 = vx, vz6 = vx, vz7 = vx; for (size_t i = 0; i < n_times; ++i) { vz0 = _mm256_add_ps(vz0, vy); vz1 = _mm256_add_ps(vz1, vy); vz2 = _mm256_add_ps(vz2, vy); vz3 = _mm256_add_ps(vz3, vy); vz4 = _mm256_add_ps(vz4, vy); vz5 = _mm256_add_ps(vz5, vy); vz6 = _mm256_add_ps(vz6, vy); vz7 = _mm256_add_ps(vz7, vy); } // Avoid dead-code elimination auto vz = vz0; vz = _mm256_add_ps(vz, vz1); vz = _mm256_add_ps(vz, vz2); vz = _mm256_add_ps(vz, vz3); vz = _mm256_add_ps(vz, vz4); vz = _mm256_add_ps(vz, vz5); vz = _mm256_add_ps(vz, vz6); vz = _mm256_add_ps(vz, vz7); _mm256_store_ps(tmp, vz); 依存関係のない8個の vaddps 命令を繰り返し実行 (パイプラインハザードが発生しないようにする) *1: 理論ピーク演算性能を計測する場合、 FMA 命令 (vfmaddps) を使用する必要があるが、今回は vaddps 命令を用いる。
48.
Fixstars Group www.fixstars.com Copyright
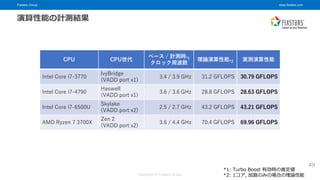
© Fixstars Group 演算性能の計測結果 CPU CPU世代 ベース / 計測時*1 クロック周波数 理論演算性能*2 実測演算性能 Intel Core i7-3770 IvyBridge (VADD port x1) 3.4 / 3.9 GHz 31.2 GFLOPS 30.79 GFLOPS Intel Core i7-4790 Haswell (VADD port x1) 3.6 / 3.6 GHz 28.8 GFLOPS 28.63 GFLOPS Intel Core i7-6500U Skylake (VADD port x2) 2.5 / 2.7 GHz 43.2 GFLOPS 43.21 GFLOPS AMD Ryzen 7 3700X Zen 2 (VADD port x2) 3.6 / 4.4 GHz 70.4 GFLOPS 69.96 GFLOPS *1: Turbo Boost 有効時の推定値 *2: 1コア, 加算のみの場合の理論性能 49
49.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group メモリ帯域の計測 • ベンチマーク内容 • キャッシュに収まらないサイズの配列に対して 4つのパターンでメモリアクセスし、スループットを計測する • read only (read:write=1:0), write only (read:write=0:1), copy (read:write=1:1), triad (read:write=2:1) • 1コアのみ使用 float *sp0 = src0, *sp1 = src1, *dp = dst, *dst_end = dst + size; while (dp < dst_end) { // triad: dst[i] = alpha * src0[i] + src1[i]; auto vx0 = _mm256_load_ps(sp0 + 0 * 8), vx1 = _mm256_load_ps(sp0 + 1 * 8); auto vx2 = _mm256_load_ps(sp0 + 2 * 8), vx3 = _mm256_load_ps(sp0 + 3 * 8); auto vy0 = _mm256_load_ps(sp1 + 0 * 8), vy1 = _mm256_load_ps(sp1 + 1 * 8); auto vy2 = _mm256_load_ps(sp1 + 2 * 8), vy3 = _mm256_load_ps(sp1 + 3 * 8); auto vz0 = _mm256_fmadd_ps(valpha, vx0, vy0); auto vz1 = _mm256_fmadd_ps(valpha, vx1, vy1); auto vz2 = _mm256_fmadd_ps(valpha, vx2, vy2); auto vz3 = _mm256_fmadd_ps(valpha, vx3, vy3); _mm256_store_ps(dp + 0 * 8, vz0); _mm256_store_ps(dp + 1 * 8, vz1); _mm256_store_ps(dp + 2 * 8, vz2); _mm256_store_ps(dp + 3 * 8, vz3); sp0 += 4 * 8, sp1 += 4 * 8, dp += 4 * 8; } 50
50.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group メモリ帯域の計測結果 • 1コアのみ使用する場合には最大でも理論値の60%程度に留まる • メモリアクセスパターンによって得られる帯域が異なる • プロセッサアーキテクチャに依存するが 今回の対象ではおおむね read only > triad > copy > write only CPU CPU世代 メモリ規格 理論メモリ 帯域 [GB/s] 実測メモリ帯域 [GB/s] read / write / copy / triad Intel Core i7-3770 IvyBridge DDR3-1600 x2 25.6 17.3 / 10.4 / 13.3 / 14.3 Intel Core i7-4790 Haswell DDR3-1600 x2 25.6 16.3 / 10.3 / 13.4 / 14.1 Intel Core i7-6500U Skylake LPDDR3-1866 x2 29.9 15.9 / 11.1 / 14.6 / 16.5 AMD Ryzen 7 3700X Zen 2 DDR4-2666 x2 42.6 22.8 / 12.1 / 17.6 / 20.5 51
51.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 演算・メモリ複合実行性能の計測 • ベンチマーク内容 • 配列の各要素に対してロード・N回加算・ストアを行う • read:write:add=1:1:N • 演算強度: N / ((1 + 1) * sizeof(float)) = N/8 • 1コアのみ使用 52 const auto va = ...; const auto *sp0 = src0, *dp = dst, *dst_end = dst + size; while (dp < dst_end) { // dst[i] = src0[i] + (a + a + ... + a); auto vz0 = _mm256_load_ps(sp0 + 0 * 8), vz1 = _mm256_load_ps(sp0 + 1 * 8); auto vz2 = _mm256_load_ps(sp0 + 2 * 8), vz3 = _mm256_load_ps(sp0 + 3 * 8); auto vz4 = _mm256_load_ps(sp0 + 4 * 8), vz5 = _mm256_load_ps(sp0 + 5 * 8); auto vz6 = _mm256_load_ps(sp0 + 6 * 8), vz7 = _mm256_load_ps(sp0 + 7 * 8); UNROLL for (int i = 0; i < N; ++i) { // N: 演算強度を変化させるためのパラメータ vz0 = _mm256_add_ps(vz0, va); vz1 = _mm256_add_ps(vz1, va); vz2 = _mm256_add_ps(vz2, va); vz3 = _mm256_add_ps(vz3, va); vz4 = _mm256_add_ps(vz4, va); vz5 = _mm256_add_ps(vz5, va); vz6 = _mm256_add_ps(vz6, va); vz7 = _mm256_add_ps(vz7, va); } _mm256_store_ps(dp + 0 * 8, vz0); _mm256_store_ps(dp + 1 * 8, vz1); _mm256_store_ps(dp + 2 * 8, vz2); _mm256_store_ps(dp + 3 * 8, vz3); _mm256_store_ps(dp + 4 * 8, vz4); _mm256_store_ps(dp + 5 * 8, vz5); _mm256_store_ps(dp + 6 * 8, vz6); _mm256_store_ps(dp + 7 * 8, vz7); sp0 += 8 * 8, dp += 8 * 8; }
52.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 演算・メモリ複合実行性能の計測結果 • おおむねルーフラインモデルに近い値が得られている 0 20 40 60 80 0 2 4 6 8 性能 [GFLOPS] Core i7-3770 (IvyBridge) Loofline 実測値 0 20 40 60 80 0 2 4 6 8 Core i7-4790 (Haswell) Loofline 実測値 0 20 40 60 80 0 2 4 6 8 性能 [GFLOPS] 演算強度 Core i7-6500U (Skylake) Loofline 実測値 0 20 40 60 80 0 2 4 6 8 演算強度 Ryzen 7 3700X (Zen 2) Loofline 実測値 53
53.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group まとめ • CPU/GPU 高速化において重要な「ルーフラインモデル」について解説 • プログラムの性能上限を見積もることができる • どのリソースがボトルネックか判定できる • 色んなプロセッサに移植した場合の性能を推定できる • 有効な高速化手法を選ぶのに役立つ • ベンチマークによる検証を実施 • ルーフラインモデルによる理論性能と実性能を比較し、 おおむね理論性能に近い結果が得られることを確認 54
54.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Copyright © Fixstars Group 実践編予告: AMD GPU における 行列積の高速化
55.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group 実践編 予告 • AMD GPU における行列積の高速化 • ルーフラインモデルを活用した高速化の例を解説 • 性能の上限を求める • 最適なレジスタ・キャッシュブロッキングサイズを求める 56
56.
Fixstars Group www.fixstars.com Copyright
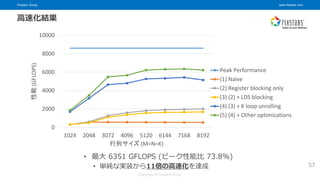
© Fixstars Group 高速化結果 • 最大 6351 GFLOPS (ピーク性能比 73.8%) • 単純な実装から11倍の高速化を達成 0 2000 4000 6000 8000 10000 1024 2048 3072 4096 5120 6144 7168 8192 性能 (GFLOPS) 行列サイズ (M=N=K) Peak Performance (1) Naïve (2) Register blocking only (3) (2) + LDS blocking (4) (3) + K loop unrolling (5) (4) + Other optimizations 57
57.
Fixstars Group www.fixstars.com Copyright
© Fixstars Group Thank You お問い合わせ窓口 : contact@fixstars.com
Editor's Notes
#16
社内大学の様子があるといいのだけど
Download
















![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
性能モデルの原始的な例 (1/3)
• シンプルな性能モデル
• 命令の種類ごとに実行回数を数えて重み付け
• 命令数
• 浮動小数点演算: 2N
• メモリアクセス数: 3N
• 実行時間: T = F * 2N + M * 3N
• F: 浮動小数点演算1命令あたり実行時間
• M: メモリアクセス1命令あたり実行時間
void SAXPY(int N, float a, const float *x, float *y) {
for (int i = 0; i < N; ++i)
y[i] = a * x[i] + y[i];
}
F, M は理論演算性能,
メモリ帯域から計算
24](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-24-320.jpg)
![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
性能モデルの原始的な例 (2/3)
• N = 109 として計算してみる
• プロセッサ: Core i7-4790
• クロック周波数: 3.6GHz
• メモリ帯域: 25.6GB/s
• 1コア1スレッドのみ使用
• 浮動小数点命令1回あたり実行時間
• F = 1 / (3.6*1e9) [sec]
• メモリアクセス命令1回あたり実行時間
• M = 1 / (25.6*1e9 / 4) [sec]
• プログラムの実行時間
• T = 2FN + 3MN = 1.02 [sec]
• 実測した結果: 0.81 sec
25](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-25-320.jpg)



![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
ルーフラインモデル*1
• 概要
• プログラムが達成可能な演算性能 [FLOPS] を
見積もるための性能モデル
• 考慮する要素
• プログラムにおける演算量・メモリアクセス量
• プロセッサの理論演算性能・メモリ帯域
• 実行モデル
29
プロセッサ
メモリ
浮動小数点演算性能:
π [GFLOPS]
メモリ帯域: β [GB/sec]
*1: Samuel Williams, Andrew Waterman, and David Patterson.
Roofline: an insightful visual performance model for multicore architectures.
Commun. ACM 52, 4 (April 2009)
キャッシュは考慮しない](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-29-320.jpg)
![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
補足1: プロセッサの演算性能とは
• 1秒間に実行可能な浮動小数点演算数*1
• 単位: FLOPS (FLoating point number Operations per Seconds)
• 例: Intel Core i7-4790
• クロック周波数: 3.6 GHz*2 (= clock/sec)
• 1クロックあたり実行可能な浮動小数点演算数 (単精度の場合)
• CPUコア数: 4
• CPUコアあたりSIMD演算器数: 2
• SIMDレーン数: 8 (AVX)
• SIMDレーンあたり演算数: 2 (Fused Multiply-Add 命令)
• 3.6 * 4 * 2 * 8 * 2 = 460.8 [GFLOPS]
30
*1: 整数演算が重要な場合は整数演算数で考える
*2: 動的周波数制御 (Intel Turbo Boost 等) も
考慮する必要がある](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-30-320.jpg)

![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
演算強度と達成可能な性能
• 演算強度 (Operational Intensity, Arithmetic Intensity)
• アプリにおける演算量とメモリアクセス量の比
• 達成可能な性能 (Attainable Performance)
• 理論的に達成可能な性能の上限
演算強度 𝐼 [Flop/Byte] =
演算量 𝑊 [Flop]
メモリアクセス量 𝑄 [Byte]
達成可能な性能 𝑃 [FLOPS] = min
理論演算性能 𝜋 [FLOPS]
メモリ帯域 𝛽[Byte/sec] × 演算強度 𝐼 [Flop/Byte]
プロセッサに対して
独立な指標
32
アプリの演算量・メモリアクセス量,
プロセッサの演算性能・メモリ帯域から計算](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-32-320.jpg)
![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
達成可能な性能の導出
• 演算律速の場合:
性能 𝑃 = 𝜋 [FLOPS]
• メモリ律速の場合:
• メモリアクセスにかかる時間は
メモリアクセス量 𝑄
メモリ帯域 𝛽
[sec]
• 実行時間 = データ転送時間 なので
性能 𝑃 =
演算量 𝑊
データ転送時間 𝑄
𝛽
= 𝛽 × 𝐼 [FLOPS]
33
プロセッサ
メモリ
プロセッサ
メモリ
常に演算が行われ
メモリアクセスは断続的
常にメモリアクセスが行われ
演算は断続的
時間
処理開始 処理終了
時間
処理開始 処理終了](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-33-320.jpg)

![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
例: ナイーブな行列積の性能見積り (1/2)
• 問題: 以下の行列積コードの得られる性能の上限は?
• プロセッサの性能
• 浮動小数点演算性能: 4000 GFLOPS
• メモリ帯域: 200 GB/sec
• M = N = K = 1000, キャッシュは考慮しないものとする
36
float A[M * K], B[K * N], C[M * N];
for (int i = 0; i < M; ++i) {
for (int j = 0; j < N; ++j) {
float value = 0.0f;
for (int k = 0; k < K; ++k)
value += A[i * K + k] * B[k * N + j];
C[i * N + j] = value;
}
}](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-35-320.jpg)
![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
例: ナイーブな行列積の性能見積り (2/2)
• 答え
• 演算量 W = 2MNK = 2*10^9 [flop]
• メモリアクセス量 Q = 8MNK + 4MN = 8*10^9 + 4*10^6 [byte]
• 演算強度 I = W / Q ≈ 0.25 [flop/byte]
• 達成可能な性能 P ≈ min(4000, 200 * 0.25) = 50 [GFLOPS]
37
どれだけ命令レベル高速化を頑張っても
理論演算性能比 1.25% の性能しか得られない*2
→ データ局所性を活用して演算強度を上げる必要がある (実践編へ)
知見: ナイーブな行列積はメモリ律速*1
*1 プロセッサの演算性能を 4000 GFLOPS, メモリ帯域を 200 GB/s とした場合
*2 実際にはキャッシュ等の影響でこれ以上の性能となりうる](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-36-320.jpg)




![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
演算性能の計測
• ベンチマーク内容
• 1命令あたり8加算可能な vaddps 命令を大量に実行し
1秒あたりの演算回数 [FLOPS] を計測する*1
• 1コアのみ使用
48
__m256 vx = ..., vy = ...;
auto vz0 = vx, vz1 = vx, vz2 = vx, vz3 = vx;
auto vz4 = vx, vz5 = vx, vz6 = vx, vz7 = vx;
for (size_t i = 0; i < n_times; ++i) {
vz0 = _mm256_add_ps(vz0, vy); vz1 = _mm256_add_ps(vz1, vy);
vz2 = _mm256_add_ps(vz2, vy); vz3 = _mm256_add_ps(vz3, vy);
vz4 = _mm256_add_ps(vz4, vy); vz5 = _mm256_add_ps(vz5, vy);
vz6 = _mm256_add_ps(vz6, vy); vz7 = _mm256_add_ps(vz7, vy);
}
// Avoid dead-code elimination
auto vz = vz0;
vz = _mm256_add_ps(vz, vz1); vz = _mm256_add_ps(vz, vz2);
vz = _mm256_add_ps(vz, vz3); vz = _mm256_add_ps(vz, vz4);
vz = _mm256_add_ps(vz, vz5); vz = _mm256_add_ps(vz, vz6);
vz = _mm256_add_ps(vz, vz7);
_mm256_store_ps(tmp, vz);
依存関係のない8個の vaddps 命令を繰り返し実行
(パイプラインハザードが発生しないようにする)
*1: 理論ピーク演算性能を計測する場合、 FMA 命令 (vfmaddps) を使用する必要があるが、今回は vaddps 命令を用いる。](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-47-320.jpg)
![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
メモリ帯域の計測
• ベンチマーク内容
• キャッシュに収まらないサイズの配列に対して
4つのパターンでメモリアクセスし、スループットを計測する
• read only (read:write=1:0), write only (read:write=0:1),
copy (read:write=1:1), triad (read:write=2:1)
• 1コアのみ使用
float *sp0 = src0, *sp1 = src1, *dp = dst, *dst_end = dst + size;
while (dp < dst_end) {
// triad: dst[i] = alpha * src0[i] + src1[i];
auto vx0 = _mm256_load_ps(sp0 + 0 * 8), vx1 = _mm256_load_ps(sp0 + 1 * 8);
auto vx2 = _mm256_load_ps(sp0 + 2 * 8), vx3 = _mm256_load_ps(sp0 + 3 * 8);
auto vy0 = _mm256_load_ps(sp1 + 0 * 8), vy1 = _mm256_load_ps(sp1 + 1 * 8);
auto vy2 = _mm256_load_ps(sp1 + 2 * 8), vy3 = _mm256_load_ps(sp1 + 3 * 8);
auto vz0 = _mm256_fmadd_ps(valpha, vx0, vy0);
auto vz1 = _mm256_fmadd_ps(valpha, vx1, vy1);
auto vz2 = _mm256_fmadd_ps(valpha, vx2, vy2);
auto vz3 = _mm256_fmadd_ps(valpha, vx3, vy3);
_mm256_store_ps(dp + 0 * 8, vz0); _mm256_store_ps(dp + 1 * 8, vz1);
_mm256_store_ps(dp + 2 * 8, vz2); _mm256_store_ps(dp + 3 * 8, vz3);
sp0 += 4 * 8, sp1 += 4 * 8, dp += 4 * 8;
} 50](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-49-320.jpg)
![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
メモリ帯域の計測結果
• 1コアのみ使用する場合には最大でも理論値の60%程度に留まる
• メモリアクセスパターンによって得られる帯域が異なる
• プロセッサアーキテクチャに依存するが
今回の対象ではおおむね read only > triad > copy > write only
CPU CPU世代 メモリ規格
理論メモリ
帯域 [GB/s]
実測メモリ帯域 [GB/s]
read / write / copy / triad
Intel Core i7-3770 IvyBridge DDR3-1600 x2 25.6 17.3 / 10.4 / 13.3 / 14.3
Intel Core i7-4790 Haswell DDR3-1600 x2 25.6 16.3 / 10.3 / 13.4 / 14.1
Intel Core i7-6500U Skylake LPDDR3-1866 x2 29.9 15.9 / 11.1 / 14.6 / 16.5
AMD Ryzen 7 3700X Zen 2 DDR4-2666 x2 42.6 22.8 / 12.1 / 17.6 / 20.5
51](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-50-320.jpg)
![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
演算・メモリ複合実行性能の計測
• ベンチマーク内容
• 配列の各要素に対してロード・N回加算・ストアを行う
• read:write:add=1:1:N
• 演算強度: N / ((1 + 1) * sizeof(float)) = N/8
• 1コアのみ使用
52
const auto va = ...;
const auto *sp0 = src0, *dp = dst, *dst_end = dst + size;
while (dp < dst_end) {
// dst[i] = src0[i] + (a + a + ... + a);
auto vz0 = _mm256_load_ps(sp0 + 0 * 8), vz1 = _mm256_load_ps(sp0 + 1 * 8);
auto vz2 = _mm256_load_ps(sp0 + 2 * 8), vz3 = _mm256_load_ps(sp0 + 3 * 8);
auto vz4 = _mm256_load_ps(sp0 + 4 * 8), vz5 = _mm256_load_ps(sp0 + 5 * 8);
auto vz6 = _mm256_load_ps(sp0 + 6 * 8), vz7 = _mm256_load_ps(sp0 + 7 * 8);
UNROLL for (int i = 0; i < N; ++i) { // N: 演算強度を変化させるためのパラメータ
vz0 = _mm256_add_ps(vz0, va); vz1 = _mm256_add_ps(vz1, va);
vz2 = _mm256_add_ps(vz2, va); vz3 = _mm256_add_ps(vz3, va);
vz4 = _mm256_add_ps(vz4, va); vz5 = _mm256_add_ps(vz5, va);
vz6 = _mm256_add_ps(vz6, va); vz7 = _mm256_add_ps(vz7, va);
}
_mm256_store_ps(dp + 0 * 8, vz0); _mm256_store_ps(dp + 1 * 8, vz1);
_mm256_store_ps(dp + 2 * 8, vz2); _mm256_store_ps(dp + 3 * 8, vz3);
_mm256_store_ps(dp + 4 * 8, vz4); _mm256_store_ps(dp + 5 * 8, vz5);
_mm256_store_ps(dp + 6 * 8, vz6); _mm256_store_ps(dp + 7 * 8, vz7);
sp0 += 8 * 8, dp += 8 * 8;
}](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-51-320.jpg)
![Fixstars Group www.fixstars.com
Copyright © Fixstars Group
演算・メモリ複合実行性能の計測結果
• おおむねルーフラインモデルに近い値が得られている
0
20
40
60
80
0 2 4 6 8
性能
[GFLOPS]
Core i7-3770 (IvyBridge)
Loofline
実測値
0
20
40
60
80
0 2 4 6 8
Core i7-4790 (Haswell)
Loofline
実測値
0
20
40
60
80
0 2 4 6 8
性能
[GFLOPS]
演算強度
Core i7-6500U (Skylake)
Loofline
実測値
0
20
40
60
80
0 2 4 6 8
演算強度
Ryzen 7 3700X (Zen 2)
Loofline
実測値
53](https://image.slidesharecdn.com/20220128-webinar-perf-modelsubmit-220131043341/85/CPU-GPU-52-320.jpg)