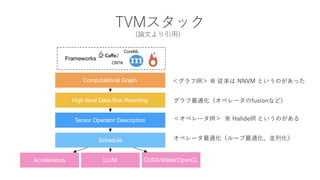
TVMスタック
(論文より引用)MAPL’18, June 18,2018, Philadelphia, PA, USA
Frameworks
Computational Graph
High level Data-flow Rewriting
Tensor Operator Description
Schedule
LLVMAccelerators CUDA/Metal/OpenCL
CNTK
CoreML These graphs areeasy to optimize
struct programs in a deeply-embe
guage (eDSL) without high-level a
A moreexpressivestyle popular
workslikeChainer, PyTorch, and G
tion of graphs with dynamic topo
runtime data and support di ere
tive computations. This expressiv
user but has limited the ability fo
optimize user-de ned graphs. Mo
requires a Python interpreter, ma
accelerators and FPGAsextremely
In summary, static graphs are
the expressivity found in higher-
<グラフIR> ※ 従来は NNVM というのがあった
グラフ最適化(オペレータのfusionなど)
オペレータ最適化(ループ最適化、並列化)
<オペレータIR> ※ HalideIR というのがある
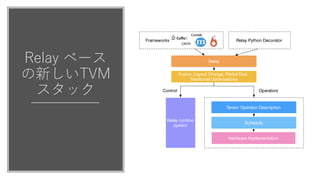
Relay ベース
の新しいTVM
スタック
programs’ computationalexpressivity. FrameworkslikeTen-
sorFlow represent di erentiable computation using static
graphs, which are data ow graphs with a xed topology.
Relay
Fusion, Layout Change, Partial Eval,
Traditional Optimizations
Tensor Operator Description
Schedule
Hardware Implementation
Frameworks
CNTK
CoreML
Relay Python Decorator
Operators
Relay runtime
system
Control
Figure 2. The new TVM stack integrated with Relay.
w
w
9.
Relay ベース
の新しいTVM
スタック
programs’ computationalexpressivity. FrameworkslikeTen-
sorFlow represent di erentiable computation using static
graphs, which are data ow graphs with a xed topology.
Relay
Fusion, Layout Change, Partial Eval,
Traditional Optimizations
Tensor Operator Description
Schedule
Hardware Implementation
Frameworks
CNTK
CoreML
Relay Python Decorator
Operators
Relay runtime
system
Control
Figure 2. The new TVM stack integrated with Relay.
w
w
TVMの一部というより、
新しい汎用グラフIR
or 深層学習用DSLであり、
TVMはそのバックエンドに
なるというイメージ
(紹介者の主観)
#4 Title: Toward new definitions of equivalence in verifying deep learning compilers
Author name: Takeo Imai
Author affiliation: LeapMind Inc.
(Currently, he is a freelance engineer and also at National Institute of Informatics)
Abstract (word count: 373/500):
A deep learning compiler is a compiler that takes a deep neural network (or DNN) as an input, optimizes it for efficient computation, and outputs code that runs on hardware or a platform. Optimizations applied during the compilation include graph optimizations like operator fusion and tensor optimizations like loop optimizations for matrix multiplication and accumulation. In addition to those classical optimizations, a deep learning compiler often applies optimizations specific to deep learning accelerators. One common example is quantization, which reduces the bit length of parameters and its computations in a DNN. A compiler may quantize 32bit float values into n-bit integer, where n = 8 is most common and n = 1 or 2 for some specific hardware devices.
In this talk, we shed light to the difficulties in defining what is equivalence for deep learning compilers. For compilers of ordinary programming languages, the behavior of a program before/after compilation must be equivalent, regardless of optimization passes applied in the compilation process. It is commonly understood that having the “same” behavior is not to have exactly the same output values from the same input, and an output value including some tiny errors like rounding errors in floating point operations are generally accepted, according to the ordinary equivalence criteria. A deep learning compiler, however, sometimes produces a code that does not keep the equivalence in a classical sense; for example, a tiny rounding error caused at a hidden layer may change the value from 0 to 1 after a 1-bit quantization, which may bring a completely different final classification result compared with the original DNN’s behavior. This is because the final output of a DNN is discrete-valued .The classical equivalence criteria do not take into consideration such tiny-error, big-difference cases.
This is a fundamental issue in the equivalence verification of deep learning compilers. We consider that we need to start from redefining the equivalence of DNN computation, or “relaxing” the equivalence criteria in order that some difference of individual discrete-valued results can be acceptable. And then, we need to propose new testing or verification methods according to the new equivalence criteria.
We present issues around the correctness of deep learning compilers described above, and offer a direction for our future work about DNN compilation.












![PythonでのRelay記述例(1) ネットワークの記述
@relay_model
def lenet(x: Tensor[Float, (1, 28, 28)]) -> Tensor[Float, 10]:
conv1 = relay.conv2d(x, num_filter=20, ksize=[1, 5, 5, 1],
no_bias=False)
tanh1 = relay.tanh(conv1)
pool1 = relay.max_pool(tanh1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1])
conv2 = relay.conv2d(pool1, num_filter=50, ksize=[1, 5, 5, 1],
no_bias=False)
tanh2 = relay.tanh(conv2)
pool2 = relay.max_pool(tanh2, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1])
flatten = relay.flatten_layer(pool2)
fc1 = relay.linear(flatten, num_hidden=500)
tanh3 = relay.tanh(fc1)
return relay.linear(tanh3, num_hidden=10)](https://image.slidesharecdn.com/20181110compilerstudy-181110130617/85/TVM-IR-Relay-13-320.jpg)
![PythonでのRelay記述例(2) 実際の学習
@relay
def loss(x: Tensor[Float, (1, 28, 28)], y: Tensor[Float, 10]) -> Float:
return relay.softmax_cross_entropy(lenet(x), y)
@relay
def train_lenet(training_data: Tensor[Float, (60000, 1, 28, 28)]) -> Model:
model = relay.create_model(lenet)
for x, y in data:
model_grad = relay.grad(model, loss, (x, y))
relay.update_model_params(model, model_grad)
return relay.export_model(model)
training_data, test_data = relay.datasets.mnist()
model = train_lenet(training_data)
print(relay.argmax(model(test_data[0])))](https://image.slidesharecdn.com/20181110compilerstudy-181110130617/85/TVM-IR-Relay-14-320.jpg)

















![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)




![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)












![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)



