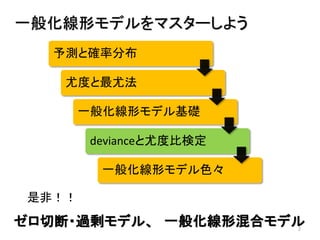
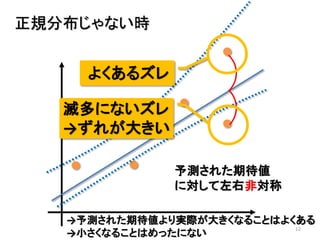
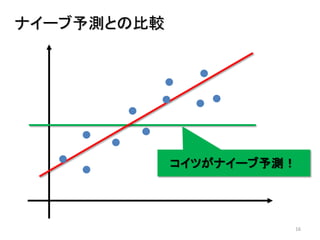
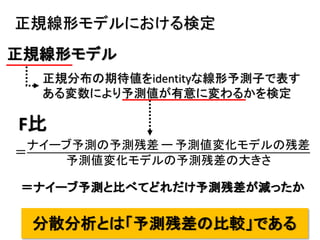
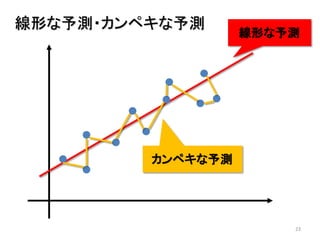
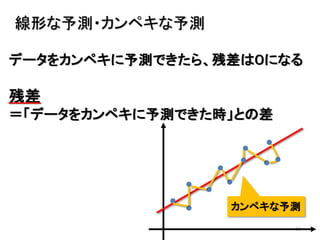
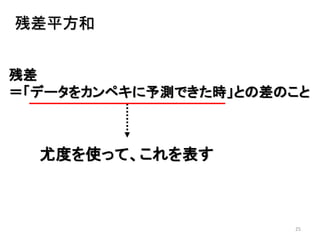
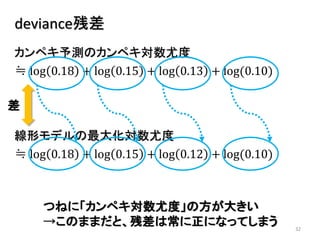
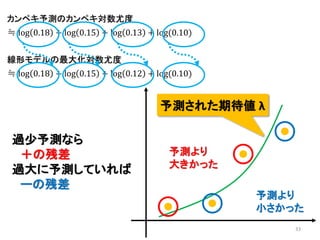
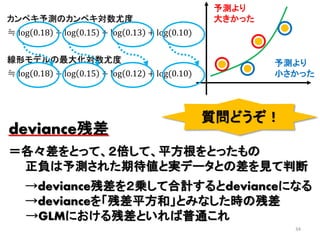
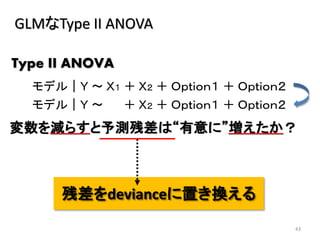
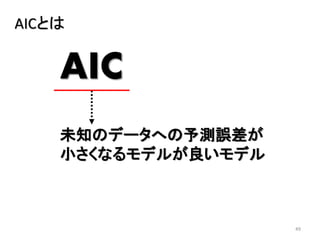
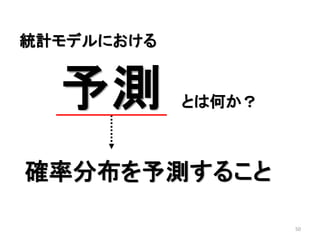
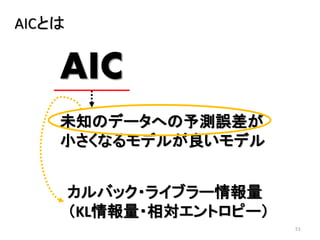
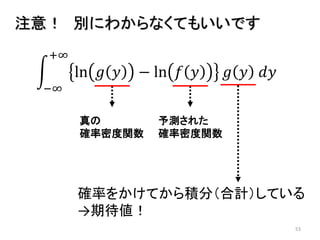
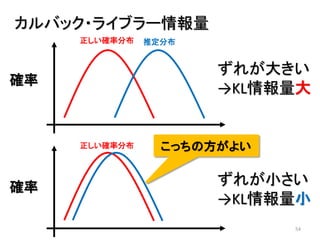
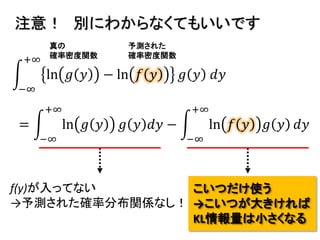
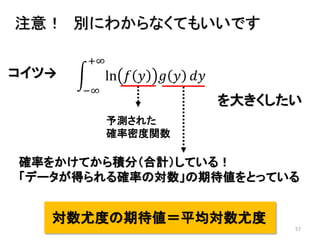
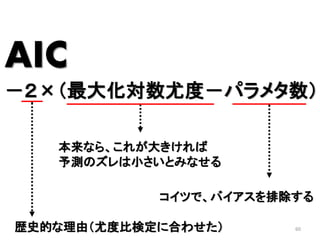
2013年8月10~11日にかけて北大函館キャンパス内で行われた統計勉強会の投影資料です。 2日目 2-4.devianceと尤度比検定 正規分布以外の確率分布では残差の考え方が変わってきます。そこでdevianceという概念を導入したうえで、GLMにおいて分散分析を実行する方法を解説します。 サイト作ってます http://logics-of-blue.com/

































































































![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)


