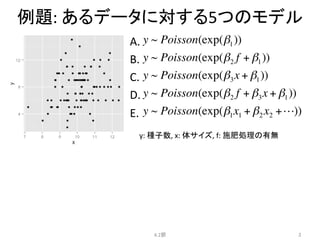
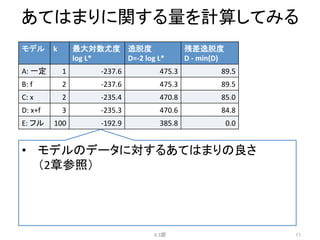
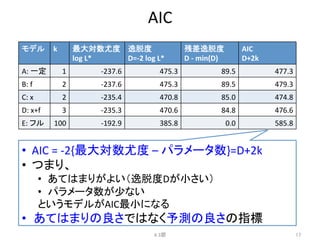
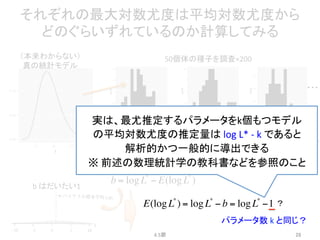
例題:
あるデータに対する5つのモデル
4.2節
3
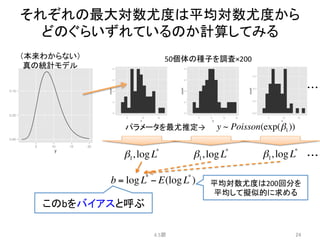
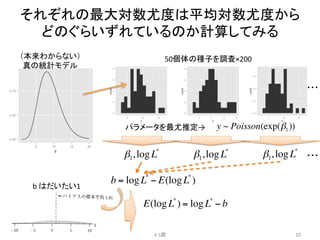
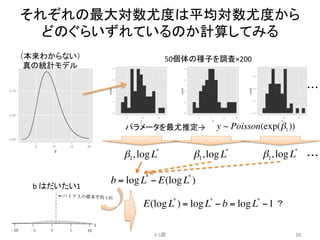
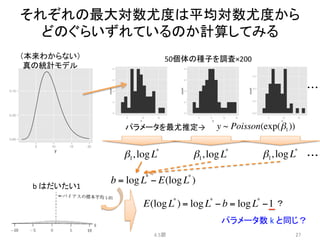
y~ Poisson(exp(β1))
y ~ Poisson(exp(β2 f + β1))
y ~ Poisson(exp(β3x + β1))
y ~ Poisson(exp(β2 f + β3x + β1))
y ~ Poisson(exp(β1x1 + β2 x2 +!))
A.
B.
C.
D.
E.
y:
種子数,
x:
体サイズ,
f:
施肥処理の有無
4.
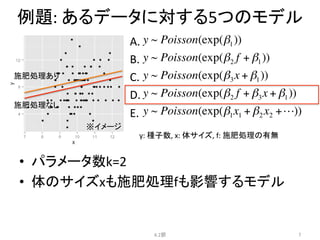
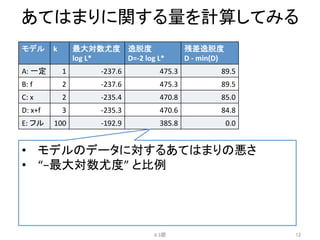
例題:
あるデータに対する5つのモデル
• パラメータ数k=1切片のみ
• 体のサイズxも施肥処理fも影響しないモデル
• 一定モデル
/
Nullモデルと呼ぶ
• 多分、一番あてはまりが悪い
4.2節
4
y:
種子数,
x:
体サイズ,
f:
施肥処理の有無
A.
B.
C.
D.
E.
※イメージ
y ~ Poisson(exp(β1))
y ~ Poisson(exp(β2 f + β1))
y ~ Poisson(exp(β3x + β1))
y ~ Poisson(exp(β2 f + β3x + β1))
y ~ Poisson(exp(β1x1 + β2 x2 +!))
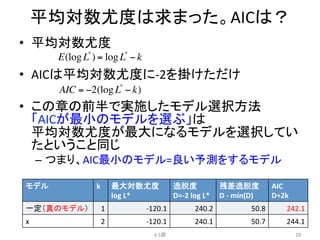
5.
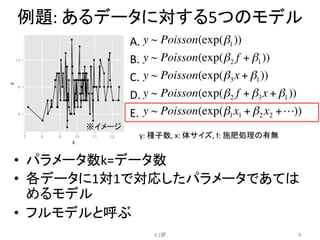
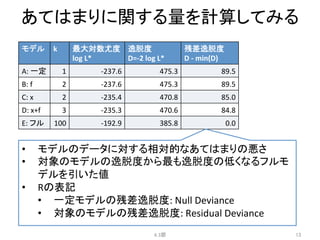
例題:
あるデータに対する5つのモデル
• パラメータ数k=2
• 施肥処理fが影響するモデル
4.2節
5
y:
種子数,
x:
体サイズ,
f:
施肥処理の有無
施肥処理あり
施肥処理なし
A.
B.
C.
D.
E.
※イメージ
y ~ Poisson(exp(β1))
y ~ Poisson(exp(β2 f + β1))
y ~ Poisson(exp(β3x + β1))
y ~ Poisson(exp(β2 f + β3x + β1))
y ~ Poisson(exp(β1x1 + β2 x2 +!))
6.
例題:
あるデータに対する5つのモデル
• パラメータ数k=2
• 体のサイズxが影響するモデル
4.2節
6
y:
種子数,
x:
体サイズ,
f:
施肥処理の有無
A.
B.
C.
D.
E.
※イメージ
y ~ Poisson(exp(β1))
y ~ Poisson(exp(β2 f + β1))
y ~ Poisson(exp(β3x + β1))
y ~ Poisson(exp(β2 f + β3x + β1))
y ~ Poisson(exp(β1x1 + β2 x2 +!))
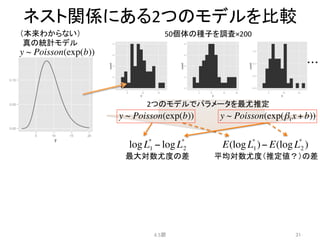
7.
例題:
あるデータに対する5つのモデル
• パラメータ数k=2
• 体のサイズxも施肥処理fも影響するモデル
4.2節
7
y:
種子数,
x:
体サイズ,
f:
施肥処理の有無
施肥処理あり
施肥処理なし
A.
B.
C.
D.
E.
※イメージ
y ~ Poisson(exp(β1))
y ~ Poisson(exp(β2 f + β1))
y ~ Poisson(exp(β3x + β1))
y ~ Poisson(exp(β2 f + β3x + β1))
y ~ Poisson(exp(β1x1 + β2 x2 +!))
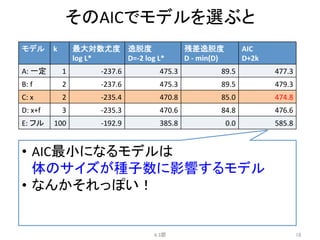
8.
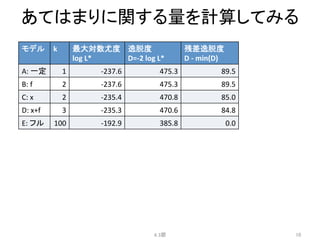
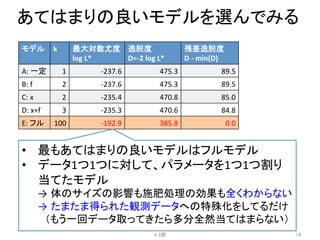
例題:
あるデータに対する5つのモデル
• パラメータ数k=データ数
• 各データに1対1で対応したパラメータであては
めるモデル
• フルモデルと呼ぶ
4.2節
8
y:
種子数,
x:
体サイズ,
f:
施肥処理の有無
A.
B.
C.
D.
E.
※イメージ
y ~ Poisson(exp(β1))
y ~ Poisson(exp(β2 f + β1))
y ~ Poisson(exp(β3x + β1))
y ~ Poisson(exp(β2 f + β3x + β1))
y ~ Poisson(exp(β1x1 + β2 x2 +!))











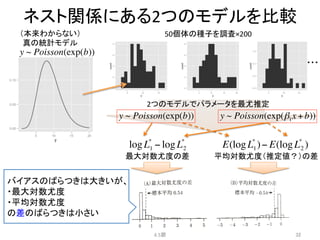
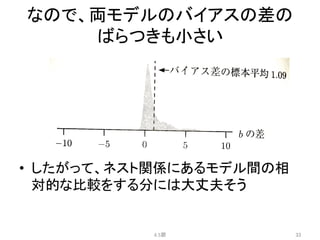

















![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)





![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)



![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DSO]勉強会_データサイエンス講義_Chapter7](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter7-191122112044-thumbnail.jpg?width=640&height=640&fit=bounds)


























