Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
IT
Uploaded by
Itou Tomokazu
2,642 views
データ解析のための統計モデリング入門第5章
NagoyaStat #3の発表資料です
Data & Analytics
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 17 times
1
/ 24
2
/ 24
3
/ 24
4
/ 24
5
/ 24
6
/ 24
7
/ 24
8
/ 24
9
/ 24
10
/ 24
11
/ 24
12
/ 24
13
/ 24
14
/ 24
15
/ 24
16
/ 24
17
/ 24
18
/ 24
19
/ 24
20
/ 24
21
/ 24
22
/ 24
23
/ 24
24
/ 24
More Related Content
PDF
RでMplusがもっと便利にーmplusAutomationパッケージー #Hiroshimar05
by
Masaru Tokuoka
PDF
因子分析
by
Mitsuo Shimohata
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
データ解析のための統計モデリング入門 1~2章
by
itoyan110
PPTX
最低6回は見よ
by
Toshiyuki Shimono
PPTX
Deep Recurrent Q-Learning(DRQN) for Partially Observable MDPs
by
Hakky St
PDF
みどりぼん3章前半
by
Akifumi Eguchi
PDF
Stanの便利な事後処理関数
by
daiki hojo
RでMplusがもっと便利にーmplusAutomationパッケージー #Hiroshimar05
by
Masaru Tokuoka
因子分析
by
Mitsuo Shimohata
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
データ解析のための統計モデリング入門 1~2章
by
itoyan110
最低6回は見よ
by
Toshiyuki Shimono
Deep Recurrent Q-Learning(DRQN) for Partially Observable MDPs
by
Hakky St
みどりぼん3章前半
by
Akifumi Eguchi
Stanの便利な事後処理関数
by
daiki hojo
What's hot
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PDF
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
PDF
Mplusの使い方 初級編
by
Hiroshi Shimizu
PDF
因果関係を時系列変化で分析
by
DaikiNagamine
PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
PPT
Anova君を使った分散分析
by
Takashi Yamane
PDF
次世代シーケンサが求める機械学習
by
sesejun
PDF
球種予測に関する研究サーベイ
by
raijinshibata
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PDF
PRML輪読#13
by
matsuolab
PDF
ベイズ機械学習(an introduction to bayesian machine learning)
by
医療IT数学同好会 T/T
PPTX
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
PDF
ロジスティック回帰分析の書き方
by
Sayuri Shimizu
PDF
機械学習におけるオンライン確率的最適化の理論
by
Taiji Suzuki
PDF
SEMを用いた縦断データの解析 潜在曲線モデル
by
Masaru Tokuoka
PDF
多重代入法の書き方 公開用
by
Koichiro Gibo
PDF
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
KEY
FDRの使い方 (Kashiwa.R #3)
by
Haruka Ozaki
PDF
Stan超初心者入門
by
Hiroshi Shimizu
一般化線形混合モデル入門の入門
by
Yu Tamura
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
Mplusの使い方 初級編
by
Hiroshi Shimizu
因果関係を時系列変化で分析
by
DaikiNagamine
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
Anova君を使った分散分析
by
Takashi Yamane
次世代シーケンサが求める機械学習
by
sesejun
球種予測に関する研究サーベイ
by
raijinshibata
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PRML輪読#13
by
matsuolab
ベイズ機械学習(an introduction to bayesian machine learning)
by
医療IT数学同好会 T/T
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
ロジスティック回帰分析の書き方
by
Sayuri Shimizu
機械学習におけるオンライン確率的最適化の理論
by
Taiji Suzuki
SEMを用いた縦断データの解析 潜在曲線モデル
by
Masaru Tokuoka
多重代入法の書き方 公開用
by
Koichiro Gibo
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
FDRの使い方 (Kashiwa.R #3)
by
Haruka Ozaki
Stan超初心者入門
by
Hiroshi Shimizu
Viewers also liked
PDF
データ解析のための統計モデリング入門3章後半
by
Shinya Akiba
PDF
データ解析のための統計モデリング入門10章前半
by
Shinya Akiba
PDF
Does Infer dream of design by contract?
by
Kiwamu Okabe
PDF
五軒家スプリント10月度 タイムスケジュール
by
龍一郎 北野
PDF
OthloEvent #9 Xamarinハンズオン
by
Hidetsugu Tamaki
PDF
WebサービスにおけるWebデザイナーの働き方
by
Yuta Suzuki
PDF
名古屋アジャイル勉強会「コンピテンシーを活用した人財育成」
by
hiroyuki Yamamoto
PDF
第8回 Web 動画 サイト講座 〜 Webサイトを完成させ、来シーズンのトピックを考えよう - NAMO (NAgoya Movie Obenkyokai)
by
Katz Ueno
PDF
サーバー構築ハンズオンマニュアル サンプル
by
Takeshi Kabu
PDF
Hands-on VeriFast with STM32 microcontroller
by
Kiwamu Okabe
PDF
第5章glmの尤度比検定と検定の非対称性 前編
by
T T
PDF
データ解析のための勉強会第7章
by
TokorosawaYoshio
PDF
伝える・見せる技術
by
You&I
PDF
120901fp key
by
ksknac
PDF
鹿児島に引っ越しました
by
Kenichiro MATOHARA
PDF
サーバー構築ハンズオンマニュアル セキュアなプロトコルを使ってみようサンプル
by
Takeshi Kabu
PPTX
スパース性に基づく機械学習(機械学習プロフェッショナルシリーズ) 1章
by
Hakky St
PPTX
スパース性に基づく機械学習 2章 データからの学習
by
hagino 3000
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
PDF
強化学習その4
by
nishio
データ解析のための統計モデリング入門3章後半
by
Shinya Akiba
データ解析のための統計モデリング入門10章前半
by
Shinya Akiba
Does Infer dream of design by contract?
by
Kiwamu Okabe
五軒家スプリント10月度 タイムスケジュール
by
龍一郎 北野
OthloEvent #9 Xamarinハンズオン
by
Hidetsugu Tamaki
WebサービスにおけるWebデザイナーの働き方
by
Yuta Suzuki
名古屋アジャイル勉強会「コンピテンシーを活用した人財育成」
by
hiroyuki Yamamoto
第8回 Web 動画 サイト講座 〜 Webサイトを完成させ、来シーズンのトピックを考えよう - NAMO (NAgoya Movie Obenkyokai)
by
Katz Ueno
サーバー構築ハンズオンマニュアル サンプル
by
Takeshi Kabu
Hands-on VeriFast with STM32 microcontroller
by
Kiwamu Okabe
第5章glmの尤度比検定と検定の非対称性 前編
by
T T
データ解析のための勉強会第7章
by
TokorosawaYoshio
伝える・見せる技術
by
You&I
120901fp key
by
ksknac
鹿児島に引っ越しました
by
Kenichiro MATOHARA
サーバー構築ハンズオンマニュアル セキュアなプロトコルを使ってみようサンプル
by
Takeshi Kabu
スパース性に基づく機械学習(機械学習プロフェッショナルシリーズ) 1章
by
Hakky St
スパース性に基づく機械学習 2章 データからの学習
by
hagino 3000
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
強化学習その4
by
nishio
Similar to データ解析のための統計モデリング入門第5章
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
PPTX
第四回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
データ解析のための統計モデリング入門 6.5章 後半
by
Yurie Oka
PDF
2 2.尤度と最尤法
by
logics-of-blue
PDF
みどりぼん読書会 第4章
by
Masanori Takano
PDF
2 5 3.一般化線形モデル色々_Gamma回帰と対数線形モデル
by
logics-of-blue
PDF
Draftall
by
Toshiyuki Shimono
PDF
Introduction to statistics
by
Kohta Ishikawa
PPTX
データ解析のための統計モデリング入門4章
by
Hirofumi Tsuruta
PPTX
第一回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
NagoyaStat #4 ご挨拶と前回の復習
by
itoyan110
PPTX
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
データ解析のための統計モデリング入門-6章後半
by
yukit_cesc
PDF
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PDF
Analysis of clinical trials using sas 勉強用 isseing333
by
Issei Kurahashi
PDF
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
PRML セミナー
by
sakaguchi050403
PDF
001 z test
by
Ayako Hoshino
2 4.devianceと尤度比検定
by
logics-of-blue
第四回統計学勉強会@東大駒場
by
Daisuke Yoneoka
データ解析のための統計モデリング入門 6.5章 後半
by
Yurie Oka
2 2.尤度と最尤法
by
logics-of-blue
みどりぼん読書会 第4章
by
Masanori Takano
2 5 3.一般化線形モデル色々_Gamma回帰と対数線形モデル
by
logics-of-blue
Draftall
by
Toshiyuki Shimono
Introduction to statistics
by
Kohta Ishikawa
データ解析のための統計モデリング入門4章
by
Hirofumi Tsuruta
第一回統計学勉強会@東大駒場
by
Daisuke Yoneoka
NagoyaStat #4 ご挨拶と前回の復習
by
itoyan110
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
2 3.GLMの基礎
by
logics-of-blue
データ解析のための統計モデリング入門-6章後半
by
yukit_cesc
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
Analysis of clinical trials using sas 勉強用 isseing333
by
Issei Kurahashi
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PRML セミナー
by
sakaguchi050403
001 z test
by
Ayako Hoshino
データ解析のための統計モデリング入門第5章
1.
データ解析のための 統計モデリング⼊⾨ 第5章 〜GLMの尤度⽐検定と検定の⾮対称性〜 2016年11⽉26⽇(⼟) NagoyaStat #3 @restofwaterimp 1
2.
⾃⼰紹介 n 名前 n twitterID
: @restofwaterimp google account : tmkz.it n 統計 : 初学者(NagoyaStatから学習中) n 普段の仕事 業務アプリケーション開発が主業務 要件ヒアリング〜保守運⽤まで メインフレーム開発が⻑かったので、新しい技術等、 時間軸を気にせず取り戻し中です・・・ ■学習の悩み・・・算術記号がすぐに何かわからない mc = x1x2 !xn =n xi i=1 n ∏ " # $ % & ' 1 n ≈ 2
3.
第2章 第3章 第4章 第5章第6章 第7章 第8章 第9章 第10章 第11章 ポアソン分布 GLM ポアソン回帰 良いモデルって? 逸脱度、AIC 検定って何? モデル選択とは 違うの? 最尤推定法 指定推定の 計算⽅法をより 深く知る MCMC 事前分布 複数パラメー タのMCMC 階層事前分布 個体差・場所差の 統計モデリング いろんなGLM ここ 本⽇の内容 3
4.
この章の⽬的 どのようなモデルであっても利⽤可能 な「尤度⽐検定」を⽤いて 検定の枠組みを知る 4
5.
仮説検定の⽬的 ⺟集団について仮定された命題を標本に基づいて、 検証すること 統計学的な検定って? ずれ 理論⽐からのずれ が誤差の範囲内 意味のある差か 統計学⼊⾨ P233より 統計学では、仮説からのずれは有意であるという。 ⽴てた仮説を統計的仮説という。 有意性の検定 5
6.
統計モデルの検定 AICによるモデル選択 解析対象のデータを確定 データを証明できるような統計モデルを設計 ネストした統計モデルたちのパラメーターの最尤推定計算 帰無仮説棄却の危険率を評価 帰無仮説棄却の破棄を判断 モデル選択基準AICの評価 予測の良いモデルを選ぶ (帰無仮説・対⽴仮説) (単純モデル・複雑モデル) 統計モデルの検定とAICモデル選択の流れ 検定もモデル選択も途中までは流れは同じ 6
7.
統計モデルの検定 AICによるモデル選択 統計モデルの検定とAICモデル選択の目的 検定もモデル選択は⽬的が違う 「良い予測をするモ デル」を選ぶ 「帰無仮説の安全な 棄却」 7 検定とモデル選択で は⽬的が異なる
8.
仮説の検証⽅法は? 帰無仮説 (null hypothesis) 「棄却されるための仮説」 対立仮説 (alternab5ve hypothesis) 「対立する仮説」 「帰無仮説は正しい」という命題が否定できるかという点のみを調べる モデルの当てはまりの良さなどを検定統 計量に指定する 「帰無仮説」が真と仮定して、統計検定 量の理論的なばらつき(確率分布)を調 べて、「ありがちな範囲」を定める 「ありがちな範囲」の⼤きさが、有意⽔ 準と⽐較、はみ出ているか確認する ここでは5%の有意⽔準を設定する 仮説を 棄却 対⽴仮説を採択する ⼿順 こちらしか検証しない こっちを⽀持したい ここでは以下の方法を「Neyman-Personの検定のわくぐみ」 とよぶ 8
9.
尤度⽐検定の例 帰無仮説 対立仮説 ⼀定モデル:種⼦数の平均λiが定数であり、体サイズXiに依存しな いモデル 傾き(β2=0;パラメータ数k=1) xモデル:種⼦数の平均λiが定数であり、体サイズXiに依存するモデ ル 傾き(β2=0;パラメータ数k=2) 3章と同じ 施肥処理には依存しない 9
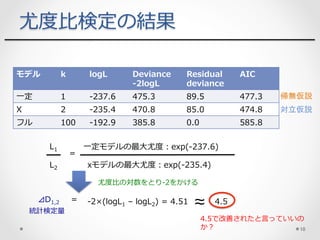
10.
モデル k logL
Deviance -2logL Residual deviance AIC ⼀定 1 -237.6 475.3 89.5 477.3 X 2 -235.4 470.8 85.0 474.8 フル 100 -192.9 385.8 0.0 585.8 尤度⽐検定の結果 帰無仮説 対立仮説 L1 L2 xモデルの最⼤尤度:exp(-235.4) ⼀定モデルの最⼤尤度:exp(-237.6) = =⊿D1,2 -2×(logL1 – logL2) = 4.51 ≈ 4.5 尤度⽐の対数をとり-2をかける 統計検定量 4.5で改善されたと⾔っていいの か? 10
11.
「滅多にない差」 (帰無仮説を棄却) 「よくある差」 (棄却できない) 真のモデルである 第⼀種の過誤 (問題なし) 真のモデルでない
(問題なし) 第⼆種の過誤 観察された逸脱度差⊿D1,2 帰 無 仮 説 の 真 実 仮説による決定 第⼀種の過誤のみ検討をする 第⼀種の過誤・・・正しいのに間違っていると判断する誤り ⽣産者のリスク 第⼆種の過誤・・・不合格なのに合格とする判断の誤り 消費者のリスク 品質管理で⾔うと ⾚本 P236 これを重視:検定の⾮対称性 11
12.
当てはまりの良さ評価⽤のデータ(多数) 尤度⽐検定に必要な⊿D1,2の⽣成 12
13.
パラメトリックブートストラップ法 ⽤語 定義 パラメトリック 事前に⺟集団分布がxx分布という形で与えられており、幾つ かの定数さえわかれば、⺟集団分布についてすべて知ることが できる場合、それをパラメトリックの場合と呼ぶ ノンパラメトリック
幾つかのパラメータで⺟集団分布を決定することが出来ない場 合、ノン・パラメトリックの場合と呼ぶ ブートストラップ・・・ 無作為にn個を抽出し、x1,x2,x3,・・・・xnの標本を作成する これをたくさん繰り返す 参照:統計学⼊⾨P179 13
14.
パラメトリックブートストラップ法 > d <-
read.csv("data3a.csv") > d$y.rnd <- rpois(100, lambda = mean(d$y)) ポアソン乱数⽣成関数(100個分、パラメータはyの標本平均) > fit1 <- glm(y.rnd ~ 1, data = d , family = poisson) > fit2 <- glm(y.rnd ~ x, data = d , family = poisson) 1.平均mean(d$y)のポアソン乱数をd$y.rndに格納する 2.d$y.rndに対する⼀定モデル、xモデルのglm()の推定結果を求める > fit1$deviance - fit2$deviance 3.逸脱度の差を計算する 1から3をとにかく繰り返す 14
15.
pb <- function(d,
n.bootstrap) { n.sample <- nrow(d) y.mean <- mean(d$y) cat("# ") v.d.dev12 <- sapply( 1:n.bootstrap, function(i) { cat(".") if (i %% 50 == 0) cat("n# ") d$y.rnd <- rpois(n.sample, lambda = y.mean) fit1 <- glm(y.rnd ~ 1, data = d, family = poisson) fit2 <- glm(y.rnd ~ x, data = d, family = poisson) fit1$deviance - fit2$deviance } ) cat("n") v.d.dev12 } > dd12 <- pb(d, n.bootstrap = 1000) Rで実施する(関数化する) 15
16.
⼀定モデルとxモデルの逸脱度の差⊿D1,2 > summary(dd12) Min. 1st
Qu. Median Mean 3rd Qu. Max. 0.000003 0.087490 0.401500 0.949400 1.169000 8.512000 観察された逸脱度差 4.5 逸脱度の差⊿D1,2の確率分布 16 N=1000
17.
観察された逸脱度差 4.5 ⼀定モデルとxモデルの逸脱度の差⊿D1,2 > sum(dd12 >= 4.5) [1] 38 1000個中38個 → P =
0.038 逸脱度の差が4.5より⼤きくなる確率 有意⽔準を0.05に決める P=0.05となる逸脱度の差 > quantile(dd12,0.95) 95% 3.953957(⊿D1,2) 棄却点 棄却点より⼤きな値のため 帰無仮説は棄却される 有意⽔準との⽐較 17
18.
18 > sum(dd12 >=
4.5) [1] 354 N=10000 ⼀定モデルとxモデルの逸脱度の差⊿D1,2 逸脱度の差が4.5より⼤きくなる確率 10000個中354個 → P = 0.0354 P=0.05となる逸脱度の差 > quan5le(dd12,0.95) 95% 3.804167 棄却点 N=10000だと
19.
X2分布を使った近似計算法 ブートストラップ法より楽に尤度比検定できる場合がある > fit11 <-
glm(y ~ 1, data = d , family = poisson) > fit22 <- glm(y ~ x, data = d , family = poisson) > anova(fit11,fit22, test = "Chisq") Analysis of Deviance Table Model 1: y ~ 1 Model 2: y ~ x Resid. Df Resid. Dev Df Deviance Pr(>Chi) 1 99 89.507 2 98 84.993 1 4.5139 0.03362 * 分散分析表を作成 X2検定を指している(Chi-squared test) 逸脱度の差⊿1,2が4.5になるP値が0.034となり、帰無仮説は棄却される ※自由度 「自由に動ける変数の数」という意味 この場合、一定モデルとxモデルでパラメータ1のため、自由度1 19
20.
もし、P > 0.05だったら 「滅多にない差」 (帰無仮説を棄却) 「よくある差」 (棄却できない) 真のモデルである
第⼀種の過誤 (問題なし) 真のモデルでない (問題なし) 第⼆種の過誤 観察された逸脱度差⊿D1,2 帰 無 仮 説 の 真 実 仮説による決定 これを重視:検定の⾮対称性 棄却できない ≠ 帰無仮説が正しい 正しいとも正しくないともいえない、判断保留 優位性検定は、帰無仮説の元で期待する結果が⽣じなかったを根拠として、仮説を棄却、否定 することが主な内容。論理学では、背理法と⾔われているもので、あくまで棄却されることが 中⼼であり、仮説が棄却されなかったからと⾔って、積極的に⽀持されたわけではない。単に、 結果が帰無仮説と「⽭盾はしない」ことがいわれただけで、仮説が真であることを積極的に 「証明」したわけではない。 ⾚本 P237より 20
21.
統計モデルの検定 AICによるモデル選択 統計モデルの検定とAICモデル選択の目的 「良い予測をする モデル」を選ぶ 「帰無仮説の安全 な棄却」 「予測の良さは平均対数尤 度」と明⽰した上で、平均 対数尤度を最⼤対数尤度と パラメーター数から推定 帰無仮説を棄却した後に残 された対⽴仮説が、「どの ような意味で良いモデル」 なのかは明確ではない 検定とモデル選択の解釈 有意な結果が出ただけで、主張が正し いというわけではない。対象テーマに よって変化するので、推定誤差や⾊々 と組み合わせたときの統計モデルの挙 動がどうなるかの予想も⽰すべき 21
22.
まとめ ü NeyMan-Personの統計学検定のわくぐみでは、パラメーター数の少ないモデル を帰無仮説と位置づけ、帰無仮説が棄却できるかどうかの確率評価に専念 ü 尤度比検定の検定統計量は2つの統計モデルの逸脱度差 ü
検定の過誤には2種類あるが、Neyman-Person検定のわくぐみでは帰無仮説の 誤棄却を重視 ü 帰無仮説を棄却する有意水準αの大きさは解析者が任意に決めるもの。 ü よくα=0.05が使われるが、これに特別な根拠はない ü Neyman-Personの検定のわくぐみでは、第一種の過誤の大きさを正確に評価で きるが、一方で帰無仮説が棄却できない場合の結論は何も言えない。 ü 検定やモデル選択の結果だけに注目するのではなく、推定された統計モデル が対象となる現象の挙動を、どのように予測しているのかも確認すべき 22
23.
おわり 23
24.
http://www.biwako.shiga-u.ac.jp/sensei/mnaka/ut/statdist.html 検定について 参考にした資料 http://hosho.ees.hokudai.ac.jp/~kubo/stat/2016/ngt/d/ngt2016d.pdf 24 ⽣態学のデータ解析 新潟⼤講義 http://hosho.ees.hokudai.ac.jp/~kubo/ce/FrontPage.html ⽣態学のデータ解析 https://www.amazon.co.jp/統計学⼊⾨-基礎統計学-東京⼤学教養学部統計学教室/dp/4130420658 Rで学ぶ ブートストラップ⼊⾨ https://www.amazon.co.jp/ブートストラップ⼊⾨-Rで学ぶデータサイエンス-4-汪-⾦芳/dp/4320110137 統計学⼊⾨
Download















![観察された逸脱度差
4.5
⼀定モデルとxモデルの逸脱度の差⊿D1,2
> sum(dd12 >= 4.5)
[1] 38 1000個中38個 → P = 0.038
逸脱度の差が4.5より⼤きくなる確率
有意⽔準を0.05に決める
P=0.05となる逸脱度の差
> quantile(dd12,0.95)
95%
3.953957(⊿D1,2)
棄却点
棄却点より⼤きな値のため
帰無仮説は棄却される
有意⽔準との⽐較
17](https://image.slidesharecdn.com/chapter5-161127211853/85/slide-17-320.jpg)
![18
> sum(dd12 >= 4.5)
[1] 354
N=10000
⼀定モデルとxモデルの逸脱度の差⊿D1,2
逸脱度の差が4.5より⼤きくなる確率
10000個中354個 → P = 0.0354
P=0.05となる逸脱度の差
> quan5le(dd12,0.95)
95%
3.804167
棄却点
N=10000だと](https://image.slidesharecdn.com/chapter5-161127211853/85/slide-18-320.jpg)























![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)














































![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)


