Download as PDF, PPTX




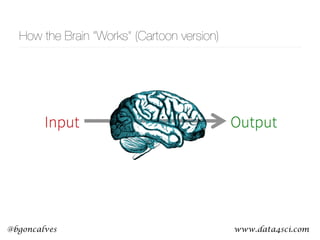
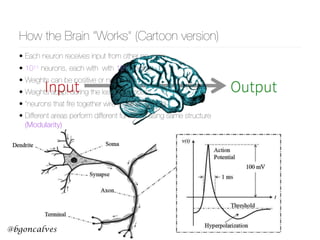
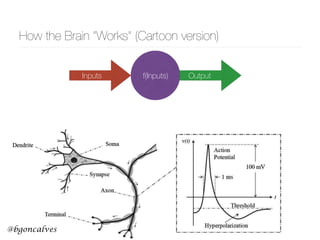

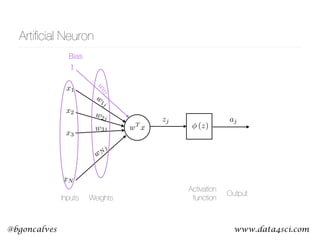
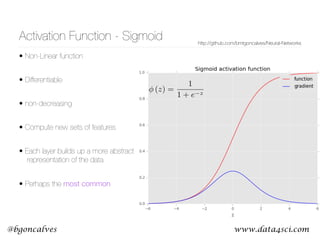
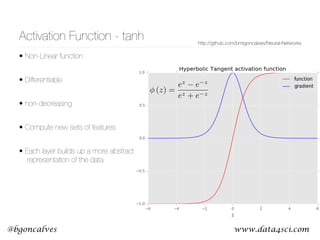



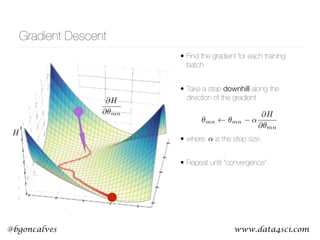
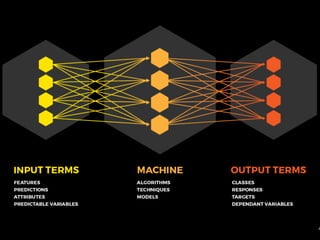
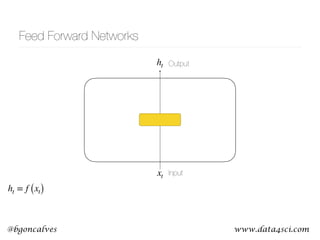
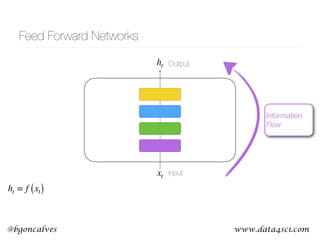
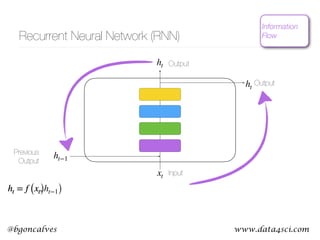
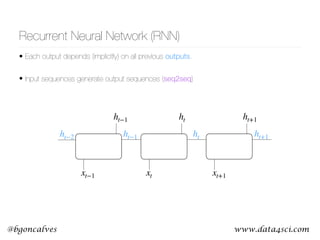
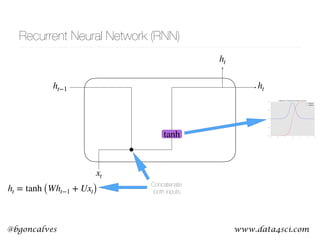
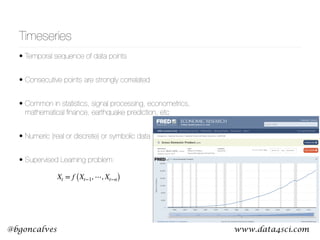

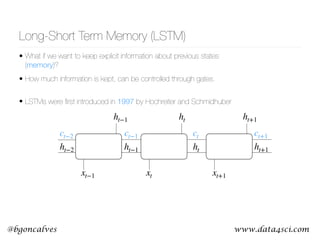
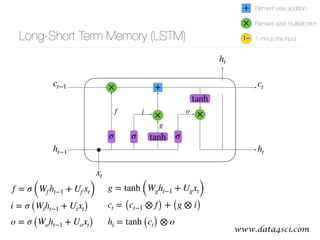
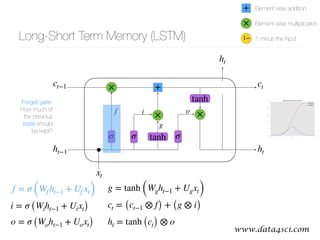
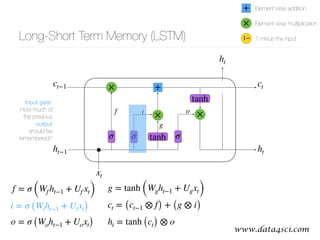
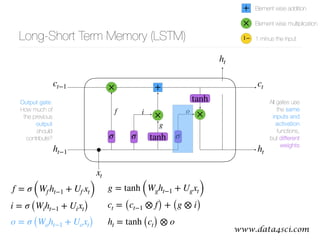
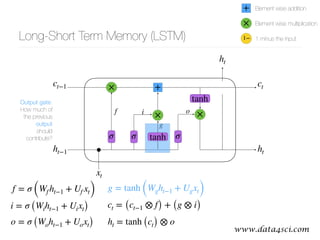
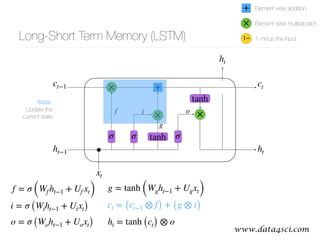
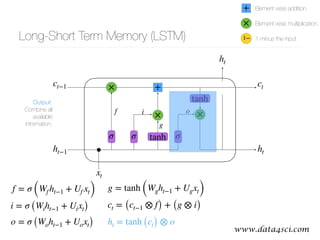

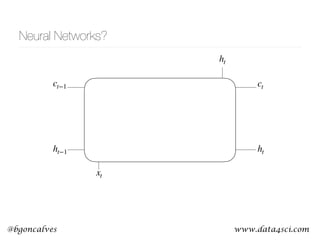


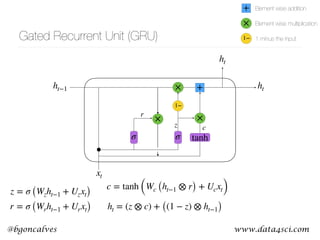
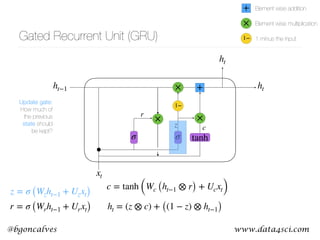
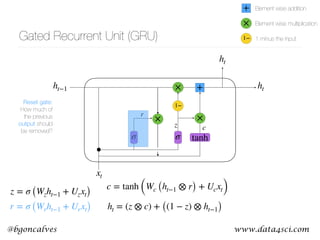
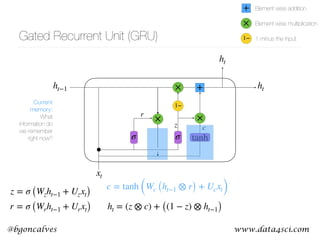
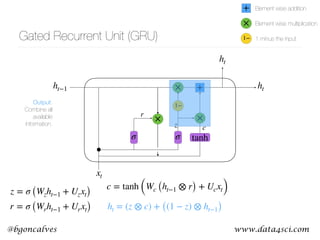

This document presents a comprehensive overview of recurrent neural networks (RNNs) and their applications in time series analysis, including fundamental concepts such as feedforward networks, backpropagation, and long short-term memory (LSTM) architectures. It discusses the optimization problems involved in machine learning, introduces gated recurrent units (GRUs) as a simplified alternative to LSTMs, and highlights the use of Keras for building neural network models. Practical applications of these techniques span various fields, including language modeling, speech recognition, and time series forecasting.
































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)








![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



