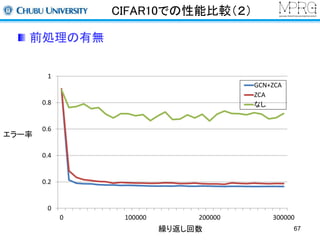
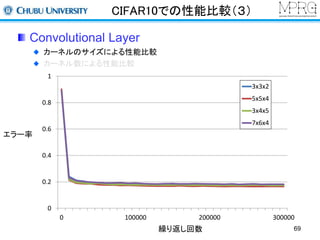
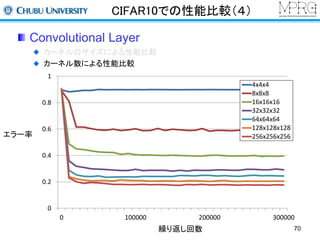
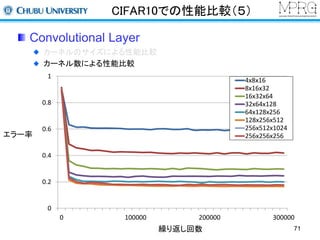
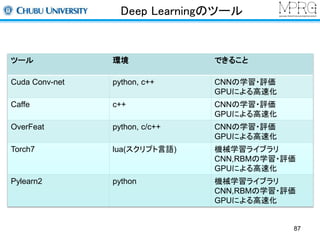
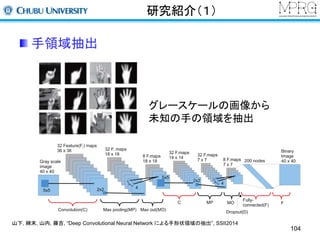
Deep Learningについて
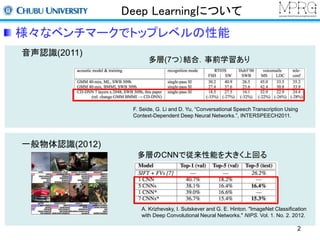
様々なベンチマークでトップレベルの性能
音声認識(2011)
多層(7つ)結合.事前学習あり
F. Seide, G. Li and D. Yu, “Conversational Speech Transcription Using
Context-Dependent Deep Neural Networks.”, INTERSPEECH2011.
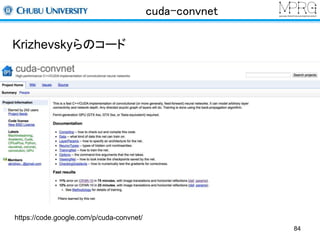
一般物体認識(2012)
多層のCNNで従来性能を大きく上回る
A. Krizhevsky, I. Sutskever and G. E. Hinton. "ImageNet Classification
with Deep Convolutional Neural Networks." NIPS. Vol. 1. No. 2. 2012.
2
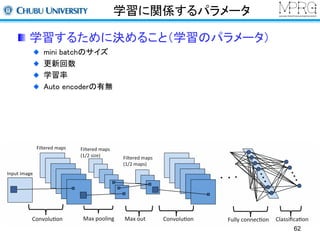
Deep Learningで何ができる?
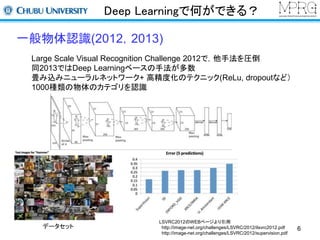
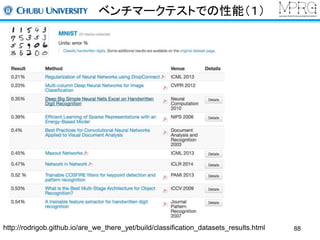
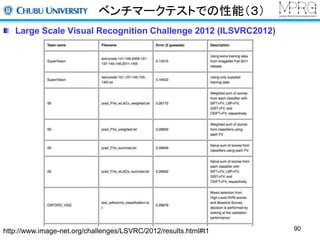
一般物体認識(2012,2013)
Large Scale Visual Recognition Challenge 2012で,他手法を圧倒
同2013ではDeep Learningベースの手法が多数
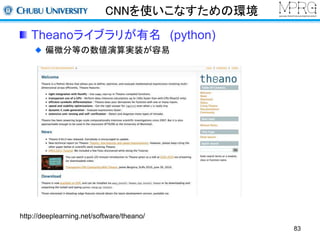
畳み込みニューラルネットワーク+ 高精度化のテクニック(ReLu, dropoutなど)
1000種類の物体のカテゴリを認識
データセット
LSVRC2012のWEBページより引用
http://image-net.org/challenges/LSVRC/2012/ilsvrc2012.pdf
http://image-net.org/challenges/LSVRC/2012/supervision.pdf
6
7.
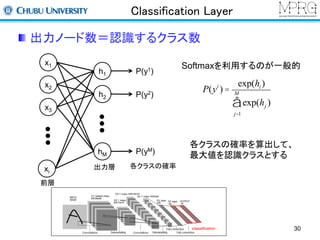
Deep Learningで何ができる?
シーン認識(2012)
畳み込みニューラルネットワークを利用して,各ピクセルのシーンラベルを付与
画素情報をそのまま入力して,特徴を自動的に学習
Superpixelによるセグメンテーションも併用
C.Farabet, C.Couprie, L.Najman, Y.LeCun, “Learning Hierarchical Features for Scene Labeling.”, PAMI2012. 7
8.
Deep Learningで何ができる?
デノイジング(2012)
階層的に学習するニューラルネットワーク
スパースコーディングをネットワークの学習に利用
⇒デノイジングオートエンコーダ
従来手法に比べて,見た目で勝る(数値上は同等)
ノイズなし画像Deep learningでの復元
J.Xie, L.Xu, E.Chen, “Image Denoising and Inpainting with Deep Neural Networks”, NIPS2012.
8
従来手法での復元
9.
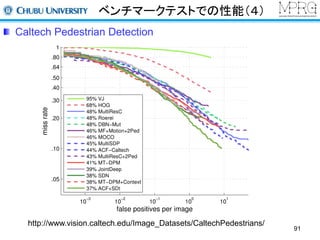
Deep Learningで何ができる?
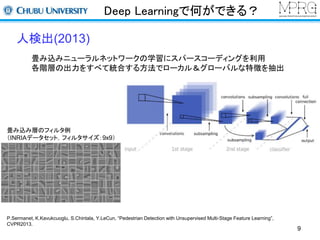
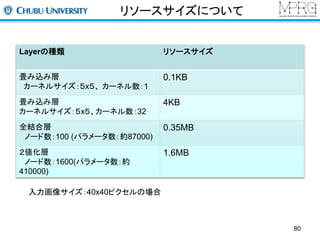
人検出(2013)
畳み込みニューラルネットワークの学習にスパースコーディングを利用
各階層の出力をすべて統合する方法でローカル&グローバルな特徴を抽出
畳み込み層のフィルタ例
(INRIAデータセット,フィルタサイズ:9x9)
P.Sermanet, K.Kavukcuoglu, S.Chintala, Y.LeCun, “Pedestrian Detection with Unsupervised Multi-Stage Feature Learning”,
CVPR2013.
9
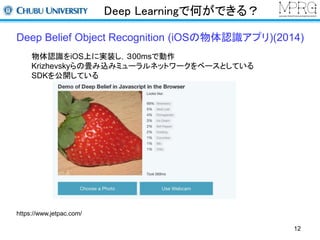
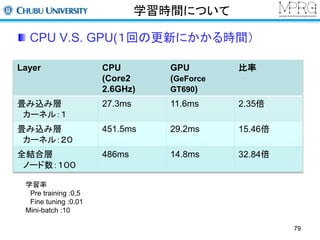
Deep Learningの著名な研究者(1)
Hinton(トロント大学): 教祖的存在
https://www.cs.toronto.edu/~hinton/
ニューラルネットワークの暗黒時代でも根気強く研究
Auto encoder、drop outなどのアプローチを提案
Deep Learningの使い方をレシピとしてまとめている
LeCun(ニューヨーク大学):CNNの第一人者
http://yann.lecun.com
Deep Learningを画像応用
畳み込みネットワーク(CNN)で手書き文字認識を実現
数多くの学生を輩出:Ranzato(Facebook)、Kavukcuoglu(DeepMind)
*FacebookのAI Labの所長を兼任
14
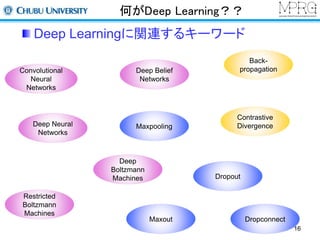
何がDeep Learning??
DeepLearningに関連するキーワード
Restricted
Boltzmann
Machines
Deep Belief
Networks
Maxpooling
Deep
Boltzmann
Machines
Convolutional
Neural
Networks
Deep Neural
Networks
Back-propagation
Contrastive
Divergence
Dropout
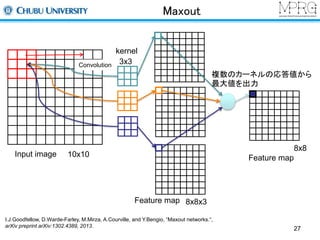
Maxout
Dropconnect
16
17.
何がDeep Learning??
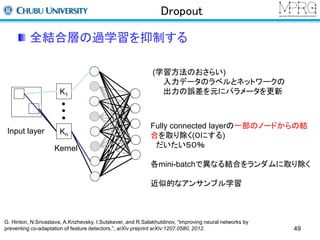
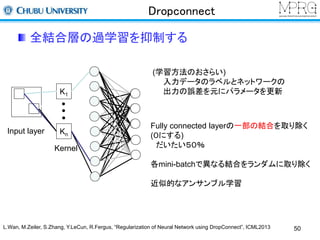
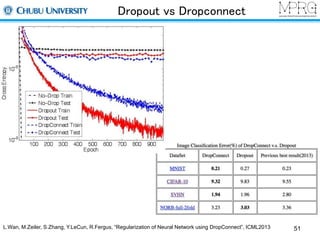
ネットワークの構成ネットワークの学習方法汎化性向上の方法
Restricted
Boltzmann
Machines
Deep Belief
Networks
Maxpooling
Deep
Boltzmann
Machines
Convolutional
Neural
Networks
Deep Neural
Networks
Back-propagation
Contrastive
Divergence
Dropout
Maxout
Dropconnect
17
18.
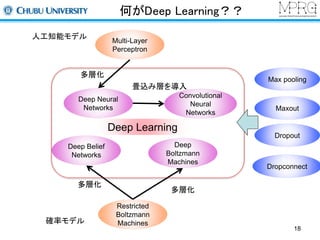
何がDeep Learning??
Multi-Layer
Perceptron
Deep Learning
Restricted
Boltzmann
Machines
人工知能モデル
多層化
Deep Belief
Networks
Convolutional
Neural
Networks
Deep
Boltzmann
Machines
Deep Neural
Networks
確率モデル
畳込み層を導入
多層化
多層化
Max pooling
Maxout
Dropout
Dropconnect
18
19.
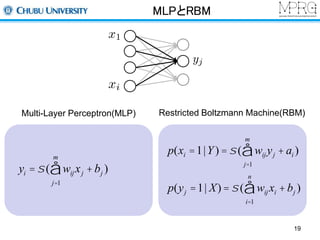
MLPとRBM
Multi-Layer Perceptron(MLP)Restricted Boltzmann Machine(RBM)
m
å )
p(xi =1|Y ) =s ( wijyj + ai
j=1
n
å )
p(yj =1| X) =s ( wijxi + bj
i=1
m
å )
yi =s ( wijxj + bj
j=1
19
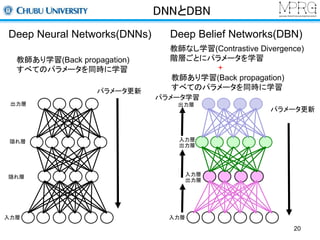
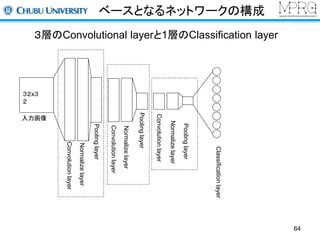
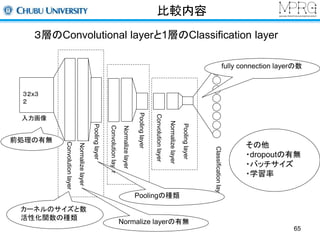
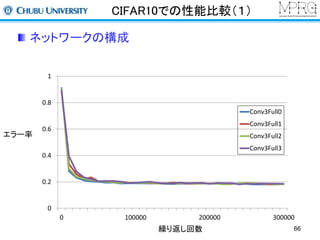
Convolutional Neural Networks
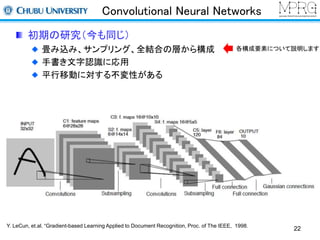
初期の研究(今も同じ)
畳み込み、サンプリング、全結合の層から構成
手書き文字認識に応用
平行移動に対する不変性がある
各構成要素について説明します
Y. LeCun, et.al. “Gradient-based Learning Applied to Document Recognition, Proc. of The IEEE, 1998. 22
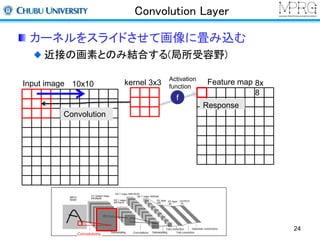
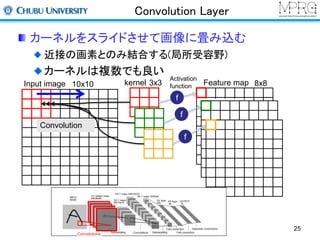
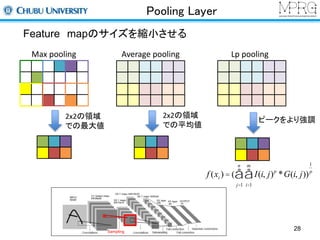
Pooling Layer
Featuremapのサイズを縮小させる
Max pooling
2x2の領域
での最大値
Average pooling
2x2の領域
での平均値
Lp pooling
m
å
n
å
ピークをより強調
f (xi ) = ( I(i, j)p *G(i, j))
1
p
i=1
j=1
28 Sampling
29.
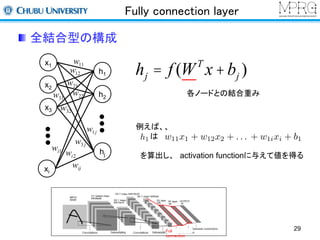
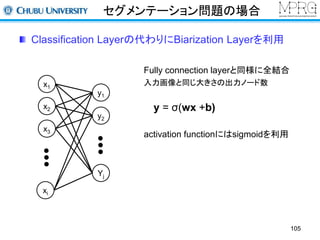
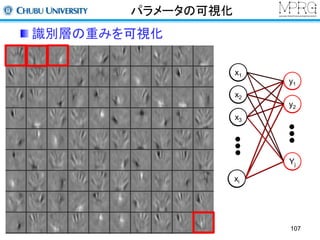
Fully connection layer
x1
x2
x3
xi
h1
h2
hj
各ノードとの結合重み
例えば、、
は
を算出し、activation functionに与えて値を得る
全結合型の構成
hj = f (WT x +bj )
29 Full
connection
w11
w12
w21
w1 j
w22 w31
w32
w3 j
wi2
wij
wi1
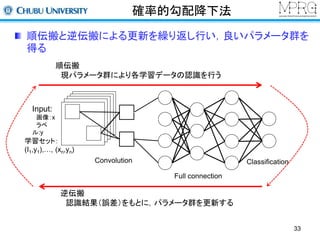
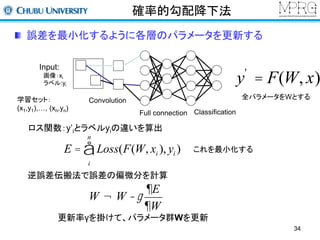
確率的勾配降下法
誤差を最小化するように各層のパラメータを更新する
Input:
画像:xi
ラベル:yi
学習セット:
(x1,y1),…, (xn,yn)
全パラメータをWとする
ロス関数:y’iとラベルyiの違いを算出
これを最小化する
34
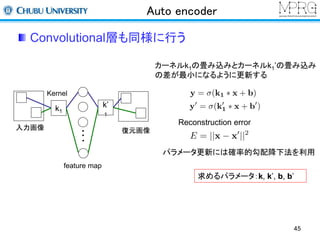
Convolution
Full connection Classification
y' = F(W, x)
n
å
E = Loss(F(W, xi ), yi )
i
逆誤差伝搬法で誤差の偏微分を計算
¶E
¶W
W ¬W -g
更新率γを掛けて、パラメータ群Wを更新
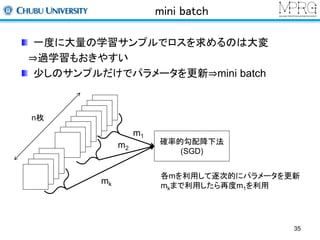
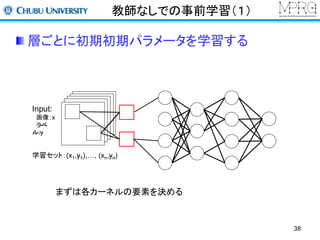
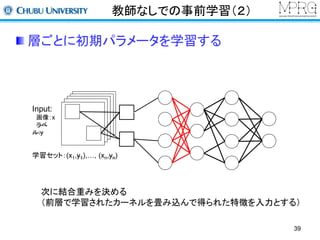
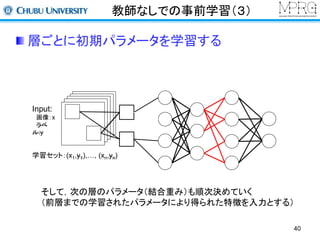
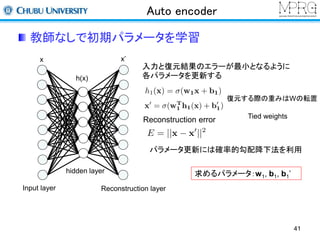
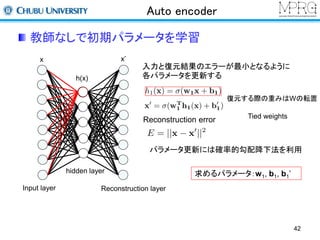
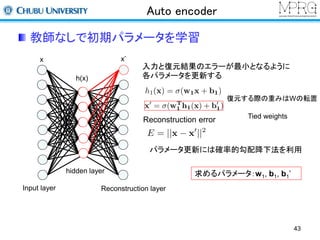
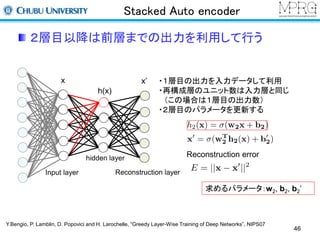
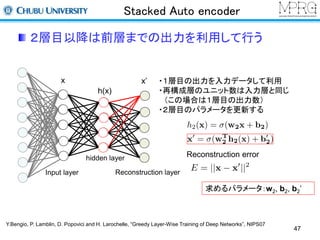
Stacked Auto encoder
2層目以降は前層までの出力を利用して行う
x x’
Input layer
hidden layer
・1層目の出力を入力データして利用
・再構成層のユニット数は入力層と同じ
(この場合は1層目の出力数)
・2層目のパラメータを更新する
Reconstruction layer
Reconstruction error
求めるパラメータ:w2, b2, b2’
Y.Bengio, P. Lamblin, D. Popovici and H. Larochelle, “Greedy Layer-Wise Training of Deep Networks”, NIPS07
46
h(x)
47.
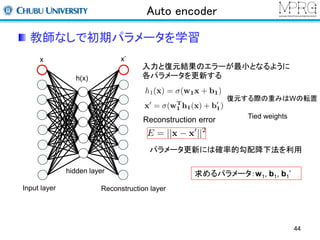
Stacked Auto encoder
2層目以降は前層までの出力を利用して行う
x x’
Input layer
hidden layer
・1層目の出力を入力データして利用
・再構成層のユニット数は入力層と同じ
(この場合は1層目の出力数)
・2層目のパラメータを更新する
Reconstruction layer
Reconstruction error
求めるパラメータ:w2, b2, b2’
47
h(x)
Y.Bengio, P. Lamblin, D. Popovici and H. Larochelle, “Greedy Layer-Wise Training of Deep Networks”, NIPS07
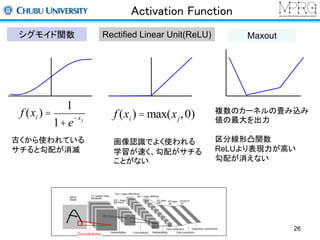
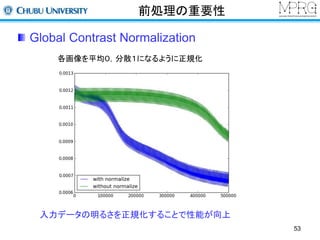
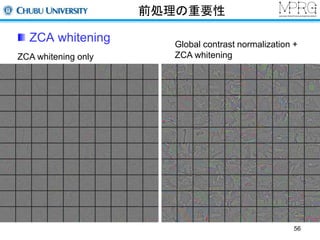
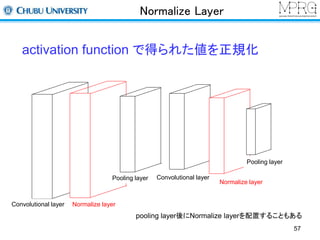
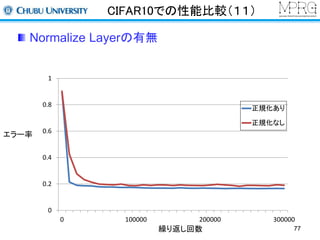
Normalize Layer
Localcontrast normalization
同一特徴マップにおける局所領域内で正規化する
Convolutional layer Normalize layer
vj,k = xj,k - wp,qxj+p,k+q å
åwp,q =1
yj,k =
vj,k
max(C,s jk )
2 å
s jk = wpqvj+p,k+q
K. Jarrett, K. Kavukcuoglu, M. Ranzato and Y.LeCun ,“What is the Best Multi-Stage Architecture for
Object Recognition?”, ICCV2009 58
59.
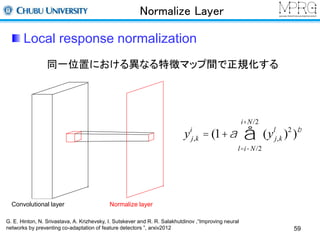
Normalize Layer
Localresponse normalization
同一位置における異なる特徴マップ間で正規化する
Convolutional layer Normalize layer
yi
i+N/2
å
j,k = (1+a (yl
j,k )2 )b
l=i-N/2
59
G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever and R. R. Salakhutdinov ,“Improving neural
networks by preventing co-adaptation of feature detectors ”, arxiv2012
物体検出
最近のトレンド
CNNを特徴量の生成として使用
Image netで学習したネットワークを活用
Caffeをもとに,物体のLocalizationに応用
CNNで抽出した特徴量をSVMでクラス識別
Pascal VOCでトップの物体検出
R. Girshick, J. Donahue, T. Darrell, J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation”
, Conference on Computer Vision and Pattern Recognition, pp. 580–587, 2014.
95
96.
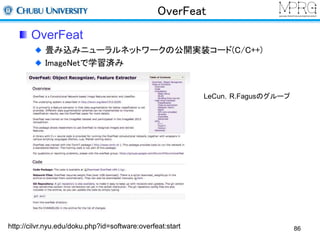
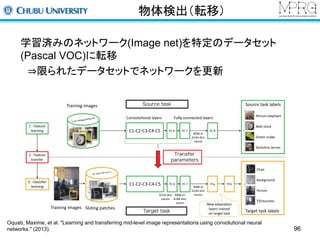
物体検出(転移)
学習済みのネットワーク(Image net)を特定のデータセット
(Pascal VOC)に転移
⇒限られたデータセットでネットワークを更新
Oquab, Maxime, et al. "Learning and transferring mid-level image representations using convolutional neural
networks." (2013). 96
97.
人の属性分類
各poseletのCNNから特徴抽出
SVMにより各属性の判別を行う
Figure3: Poselet Input Patchesfrom Berkeley Attr ibutes
of People Dataset. For each poselet, we use the detected
patches to train aconvolution neural net. Here are someex-amples
of input poselet patches and weareshowing poselet
patcheswith high scores for poselet 1,16 and 79.
sumably requires different features) whilethebottomlayers
are shared to a) reduce the number of parameters and b) to
leverage common low-level structure.
The whole network is trained jointly by standard back-propagation
of the error [24] and stochastic gradient de-scent
[2] using as a loss function the sum of the log-losses
of each attributefor each training sample. Thedetails of the
layers are given in Figure 2 and further implementation de-tails
can befound in [15]. To deal with noiseand inaccurate
poselet detections, we train on patches with high poselet
detection scores and then wegradually addmore low confi-dence
patches.
Different parts of thebody may havedifferent signals for
each of the attributes and sometimes signals coming from
one part cannot infer certain attributes accurately. For ex-ample,
deep net trained on person leg patches contains little
information about whether the person wears a hat. There-fore,
we first use deep convolutional nets to generate dis-criminative
image representations for each part separately
and then we combine these representations for the final
classification. Specifically, we extract the activations from
! "
# $
Figure 2: Par t-based Convolutional Neural Nets. For each poselet, one convolutional neural net is trained on patches
resized 64x64. The network consists of 4 stages of convolution/pooling/normalization and followed by a fully connected
layer. Then, it branches out one fully connected layer with 128 hidden units for each attribute. Weconcatenate the activation
from fc attr from each poselet network to obtain the pose-normalized representation. The details of filter size, number of
filters weused are depicted above.
some degenerate cases, images may have few poselets de-tected.
To deal with that, we also incorporate a deep net-work
covering thewhole-person bounding box region as in-put
to our final pose-normalized representation.
Based on our experiments, we find amore complex net
is needed for the whole-person region than for the part re-gions.
We extract deep convolutional features from the
model trained on Imagenet [15] using theopen sourcepack-age
provided by [8] as our deep representation of the full
image patch.
As shown in Figure 1, we concatenate the features from
thedeep representations of thefull imagepatch and the150
parts and train a linear SVM for each attribute.
2.5
2
1.5
1
0.5
4
N.Zhang, M.Paluri, M.Ranzato, T.Darrell, L.Bourdev, “PANDA: Pose Aligned Networks for Deep Attribute Modeling”, CVPR2014
4. Datasets
is male long hair hat glasses dress sunglasses short sleeves is baby
0
x 10
Number of Labels
Positives
Negatives
Unspecified
97
Figure 4: Statisitcs of the number of groundtruth labels on
Attribute 25k Dataset. For each attribute, green is the num-ber
of positive labels, red is the number of negative labels
Figure 1: Overview of Pose Aligned Networks for Deep Attr ibute modeling (PANDA). One convolutional neural net trained on semantic part patches for each poselet and then the top-level activations of all nets are concatenated to obtain pose-normalized deep representation. The final attributes are predicted by linear SVM classifier using the pose-normalized
98.
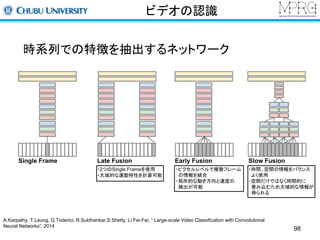
ビデオの認識
時系列での特徴を抽出するネットワーク
SingleFrame Late Fusion Early Fusion Slow Fusion
・ピクセルレベルで複数フレーム
の情報を統合
・局所的な動き方向と速度の
検出が可能
・2つのSingle Frameを使用
・大域的な運動特性を計算可能
・時間、空間の情報をバランス
よく使用
・空間だけではなく時間的に
畳み込むため大域的な情報が
得られる
A.Karpathy, T.Leung, G.Toderici, R.Sukthankar,S.Shetty, Li Fei-Fei, “ Large-scale Video Classification with Convolutional
Neural Networks”, 2014
98
99.
ビデオの認識
Slow Fusionnetwork on the first layer
A.Karpathy, T.Leung, G.Toderici, R.Sukthankar,S.Shetty, Li Fei-Fei, “ Large-scale Video Classification with
Convolutional Neural Networks”, 2014 99
100.
ビデオの認識
Sports-1M Datasetを公開
100
A.Karpathy, T.Leung, G.Toderici, R.Sukthankar,S.Shetty, Li Fei-Fei, “ Large-scale Video Classification with
Convolutional Neural Networks”, 2014
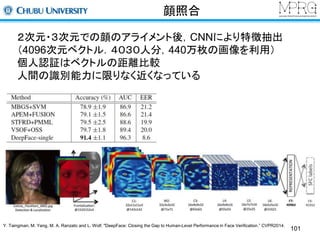
顔照合
切り出し位置を変えた複数のネットワークから特徴を抽出
DeepFaceを超える照合精度
Method Accuracy(%) No. of points No. of images Feature dimensions
DeepFace 97.25 6+67 4,400,000+3,000,000 4096×4
DeepID on CelebFaces 96.05 5 87,628 150
DeepID on CelebFaces+ 97.20 5 202,599 150
DeepID on CelebFaces+ & TL 97.45 5 202,599 150
Y. Taingman, M. Yang, M. A. Ranzato and L. Wolf. "DeepFace: Closing the Gap to Human-Level Performance in Face Verification.” CVPR2014.
102































![人の属性分類
各poseletのCNNから特徴抽出
SVMにより各属性の判別を行う
Figure3: Poselet Input Patchesfrom Berkeley Attr ibutes
of People Dataset. For each poselet, we use the detected
patches to train aconvolution neural net. Here are someex-amples
of input poselet patches and weareshowing poselet
patcheswith high scores for poselet 1,16 and 79.
sumably requires different features) whilethebottomlayers
are shared to a) reduce the number of parameters and b) to
leverage common low-level structure.
The whole network is trained jointly by standard back-propagation
of the error [24] and stochastic gradient de-scent
[2] using as a loss function the sum of the log-losses
of each attributefor each training sample. Thedetails of the
layers are given in Figure 2 and further implementation de-tails
can befound in [15]. To deal with noiseand inaccurate
poselet detections, we train on patches with high poselet
detection scores and then wegradually addmore low confi-dence
patches.
Different parts of thebody may havedifferent signals for
each of the attributes and sometimes signals coming from
one part cannot infer certain attributes accurately. For ex-ample,
deep net trained on person leg patches contains little
information about whether the person wears a hat. There-fore,
we first use deep convolutional nets to generate dis-criminative
image representations for each part separately
and then we combine these representations for the final
classification. Specifically, we extract the activations from
! "
# $
Figure 2: Par t-based Convolutional Neural Nets. For each poselet, one convolutional neural net is trained on patches
resized 64x64. The network consists of 4 stages of convolution/pooling/normalization and followed by a fully connected
layer. Then, it branches out one fully connected layer with 128 hidden units for each attribute. Weconcatenate the activation
from fc attr from each poselet network to obtain the pose-normalized representation. The details of filter size, number of
filters weused are depicted above.
some degenerate cases, images may have few poselets de-tected.
To deal with that, we also incorporate a deep net-work
covering thewhole-person bounding box region as in-put
to our final pose-normalized representation.
Based on our experiments, we find amore complex net
is needed for the whole-person region than for the part re-gions.
We extract deep convolutional features from the
model trained on Imagenet [15] using theopen sourcepack-age
provided by [8] as our deep representation of the full
image patch.
As shown in Figure 1, we concatenate the features from
thedeep representations of thefull imagepatch and the150
parts and train a linear SVM for each attribute.
2.5
2
1.5
1
0.5
4
N.Zhang, M.Paluri, M.Ranzato, T.Darrell, L.Bourdev, “PANDA: Pose Aligned Networks for Deep Attribute Modeling”, CVPR2014
4. Datasets
is male long hair hat glasses dress sunglasses short sleeves is baby
0
x 10
Number of Labels
Positives
Negatives
Unspecified
97
Figure 4: Statisitcs of the number of groundtruth labels on
Attribute 25k Dataset. For each attribute, green is the num-ber
of positive labels, red is the number of negative labels
Figure 1: Overview of Pose Aligned Networks for Deep Attr ibute modeling (PANDA). One convolutional neural net trained on semantic part patches for each poselet and then the top-level activations of all nets are concatenated to obtain pose-normalized deep representation. The final attributes are predicted by linear SVM classifier using the pose-normalized](https://image.slidesharecdn.com/miru2014tutorialdeeplearningslideshare-140721201916-phpapp02/85/MIRU2014-tutorial-deeplearning-97-320.jpg)










![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Estimating Predictive Uncertainty via Prior Networks](https://cdn.slidesharecdn.com/ss_thumbnails/estimatingpredictiveuncertaintyviapriornetworks-190628002736-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)
















