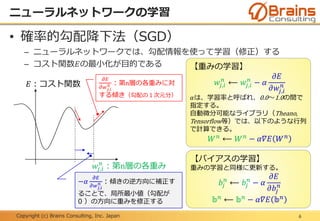
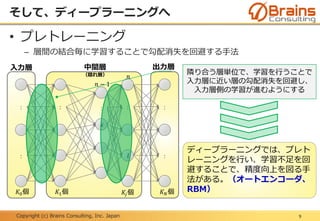
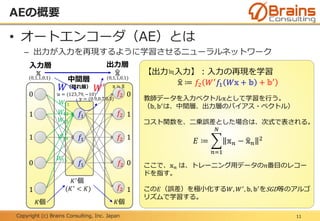
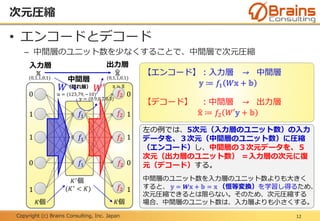
Deep Learningについて、日本情報システム・ユーザー協会(JUAS)のJUAS ビジネスデータ研究会 AI分科会で発表しました。その際に使用した資料です。専門家向けではなく、一般向けの資料です。
なお本資料は、2015年12月の日本情報システム・ユーザー協会(JUAS)での発表資料の改訂版となります。
Copyright (c) BrainsConsulting, Inc. Japan
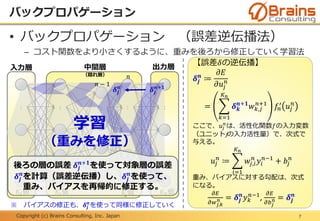
4.再帰的ニューラルネットワーク(RNN)
15
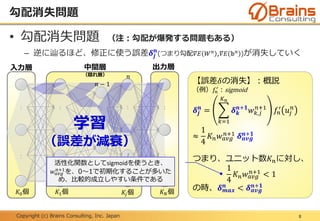
再帰的
ニューラルネットワーク
(RNN)
17.
Copyright (c) BrainsConsulting, Inc. Japan
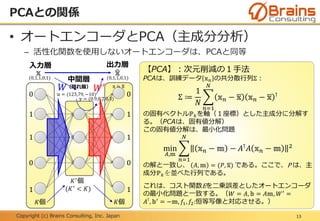
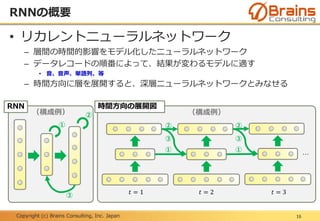
• リカレントニューラルネットワーク
– 層間の時間的影響をモデル化したニューラルネットワーク
– データレコードの順番によって、結果が変わるモデルに適す
• 音、音声、単語列、等
– 時間方向に層を展開すると、深層ニューラルネットワークとみなせる
(構成例)(構成例)
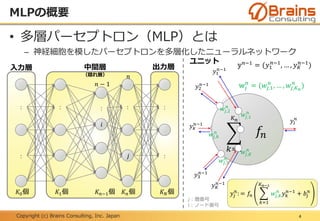
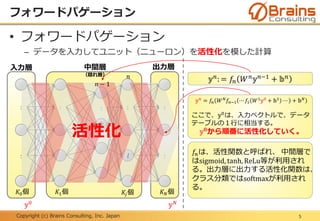
RNNの概要
16
RNN
②
③
𝑡 = 1
① ①
② ②
③ ③
𝑡 = 2 𝑡 = 3
…
時間方向の展開図
①
18.
Copyright (c) BrainsConsulting, Inc. Japan
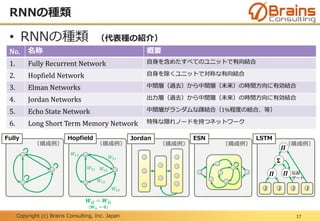
• RNNの種類 (代表種の紹介)
(構成例)
Fully
RNNの種類
17
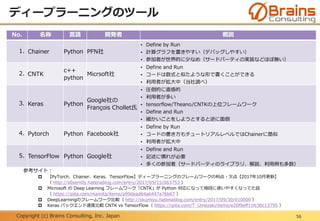
No. 名称 概要
1. Fully Recurrent Network 自身を含めたすべてのユニットで有向結合
2. Hopfield Network 自身を除くユニットで対称な有向結合
3. Elman Networks 中間層(過去)から中間層(未来)の時間方向に有効結合
4. Jordan Networks 出力層(過去)から中間層(未来)の時間方向に有効結合
5. Echo State Network 中間層がランダムな疎結合(1%程度の結合、等)
6. Long Short Term Memory Network 特殊な隠れノードを持つネットワーク
(構成例)
Hopfield
𝑊12
𝑊21
𝑊23
𝑊32
𝑊13
𝑊31
𝑾𝒊𝒋 = 𝑾𝒋𝒊
(𝑾𝒊𝒊 = 𝟎)
(構成例)
Jordan
(構成例)
ESN
(構成例)
LSTM
∫ ∫ ∫ ∫
𝜫 𝜫
𝜫
𝚺
忘却
ゲート
Copyright (c) BrainsConsulting, Inc. Japan
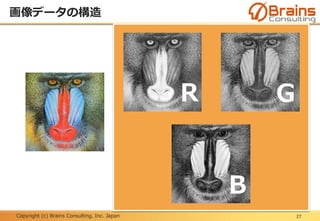
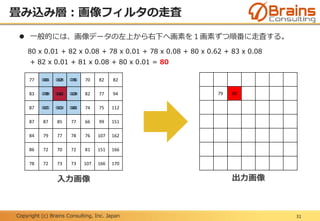
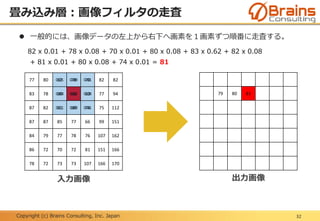
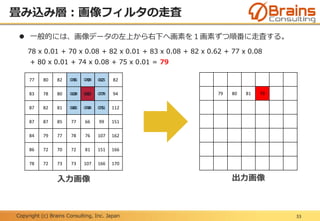
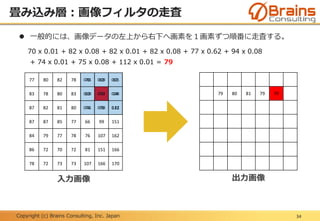
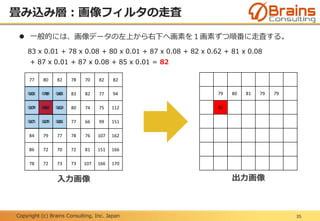
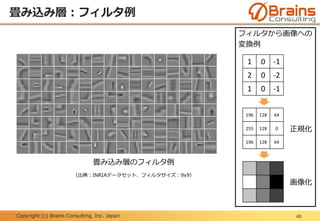
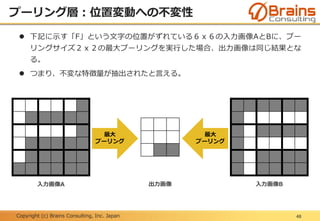
プーリング層:位置変動への不変性
48
下記に示す「F」という文字の位置がずれている6x6の入力画像AとBに、プー
リングサイズ2x2の最大プーリングを実行した場合、出力画像は同じ結果とな
る。
つまり、不変な特徴量が抽出されたと言える。
入力画像A 入力画像B出力画像
最大
プーリング
最大
プーリング
50.
Copyright (c) BrainsConsulting, Inc. Japan
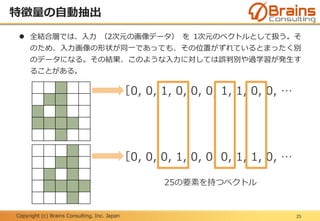
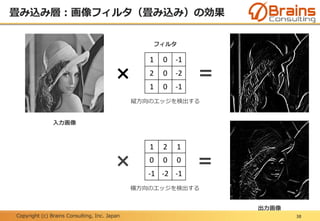
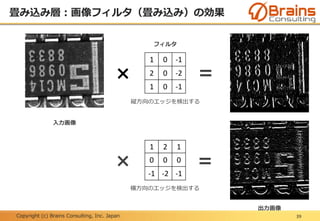
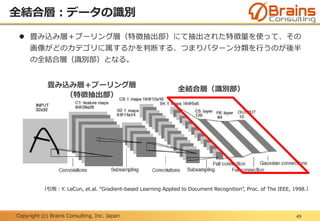
全結合層:データの識別
49
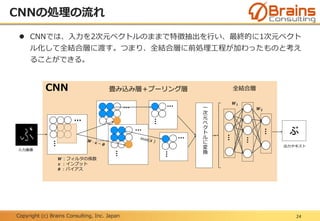
畳み込み層+プーリング層(特徴抽出部)にて抽出された特徴量を使って、その
画像がどのカテゴリに属するかを判断する、つまりパターン分類を行うのが後半
の全結合層(識別部)となる。
(引用:Y. LeCun, et.al. “Gradient-based Learning Applied to Document Recognition”, Proc. of The IEEE, 1998.)
畳み込み層+プーリング層
(特徴抽出部)
全結合層(識別部)
51.
Copyright (c) BrainsConsulting, Inc. Japan
活用事例:ABEJA「ABEJA PLATFORM」
50
人工知能を活用した店舗解析プラットフォームである。実店舗にカメラ設置し、
取得したデータの解析部分に、ディープラーニングを応用した技術を利用してい
る。実際に店舗でも運用事例もあり、目玉賞品の売上比率が上昇するなどの成果
がでている。
(引用:ABEJA、「売れない理由」をAIで解析、繁盛店に、動画でわかるABEJA Platform for Retail)
52.
Copyright (c) BrainsConsulting, Inc. Japan
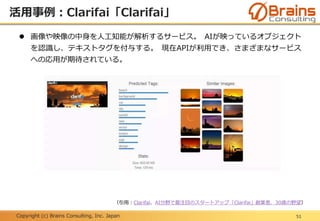
活用事例:Clarifai「Clarifai」
51
画像や映像の中身を人工知能が解析するサービス。 AIが映っているオブジェクト
を認識し、テキストタグを付与する。 現在APIが利用でき、さまざまなサービス
への応用が期待されている。
(引用:Clarifai、AI分野で最注目のスタートアップ「Clarifai」創業者、30歳の野望)
53.
Copyright (c) BrainsConsulting, Inc. Japan
活用事例:Google DeepMind「AlphaGo」
52
人類最強棋士を打ち破ったアルファ碁は、直感に優れたAI(深層学習)、経験に
学ぶAI(強化学習)、先読みするAI(探索)の3つのAI技術で支えられている。
上記の中でCNNは、「次の一手」を決定するタスクで使われている。囲碁の
19x19路の盤面を入力とし、次の手を盤面のどこに打つかを決定している。
(引用:囲碁AI “AlphaGo” はなぜ強いのか?)






![Copyright (c) Brains Consulting, Inc. Japan
• Elman Networks
– 音声認識では、主にElman Networks タイプのRNNが広く利用される
– 1つ前の時刻の隠れ層の出力を現在時刻の隠れ層への入力とする
– 一般に、RNNと言えば、Elman Networks タイプを指すことも多い
(構成例)
時間方向の展開図
音声認識におけるRNN
18
(構成例)
Elman
𝑡 = 1 𝑡 = 2 𝑡 = 3 𝑡 = T
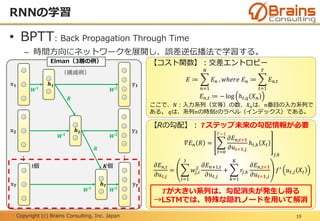
【定式化】 𝑇:入力系列の長さ(1文の音声特徴ベクトル列、等), 𝑡 = 1, ⋯ , 𝑇 に対して、
𝑋𝑡 = [𝕩1, ⋯ , 𝕩 𝑡]:入力系列の時刻𝑡までの部分列とすると、以下のように式で表せる。
ℎ 𝑡 𝑋𝑡 ≔ 𝑓 𝑢 𝑡 𝑋𝑡
𝑢 𝑡 𝑋𝑡 ≔ 𝕓 + 𝑊1
𝕩 𝑡 + 𝑅ℎ 𝑡−1 𝑋𝑡−1
𝕪 𝑡:1-of-N 方式(正解ラベルの次元/ユニットのみ1, その他は0を出力)
𝑾 𝟏
𝑾 𝟐
𝑾 𝟏
𝑾 𝟐
𝑾 𝟏
𝑾 𝟐
𝑾 𝟏
𝑾 𝟐
𝑾 𝟏
𝑾 𝟐
𝑹
𝑹 𝑹 𝑹𝒉 𝟏 𝒉 𝟐 𝒉 𝟑
𝒉 𝑻
𝕩 𝟏 𝕩 𝟐 𝕩 𝟑
𝕩 𝑻
𝕪 𝟏 𝕪 𝟐 𝕪 𝟑
𝕪 𝑻](https://image.slidesharecdn.com/bci20171201-171203171506/85/Deep-Learning-19-320.jpg)

















![[DL輪読会]High-Quality Self-Supervised Deep Image Denoising](https://cdn.slidesharecdn.com/ss_thumbnails/high-qualityself-superviseddeepimagedenoising-200501014639-thumbnail.jpg?width=640&height=640&fit=bounds)



![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)




















