Downloaded 257 times



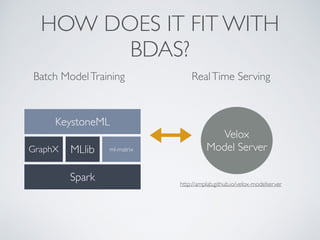






![TRANSFORMERS
TransformerInput Output
abstract classTransformer[In, Out] {
def apply(in: In): Out
def apply(in: RDD[In]): RDD[Out] = in.map(apply)
…
}
TYPE SAFETY HELPS ENSURE ROBUSTNESS](https://image.slidesharecdn.com/04evansparks-150624015344-lva1-app6891/85/Building-Large-Scale-Machine-Learning-Applications-with-Pipelines-Evan-Sparks-and-Shivaram-Venkataraman-UC-Berkeley-AMPLAB-12-320.jpg)
![ESTIMATORS
EstimatorRDD[Input]
abstract class Estimator[In, Out] {
def fit(in: RDD[In]):Transformer[In,Out]
…
}
Transformer
.fit()](https://image.slidesharecdn.com/04evansparks-150624015344-lva1-app6891/85/Building-Large-Scale-Machine-Learning-Applications-with-Pipelines-Evan-Sparks-and-Shivaram-Venkataraman-UC-Berkeley-AMPLAB-13-320.jpg)
![CHAINING
NGrams(2)String Vectorizer VectorBigrams
val featurizer:Transformer[String,Vector] = NGrams(2) thenVectorizer
featurizerString Vector
=](https://image.slidesharecdn.com/04evansparks-150624015344-lva1-app6891/85/Building-Large-Scale-Machine-Learning-Applications-with-Pipelines-Evan-Sparks-and-Shivaram-Venkataraman-UC-Berkeley-AMPLAB-14-320.jpg)
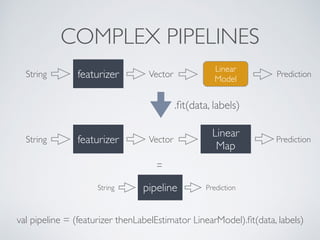



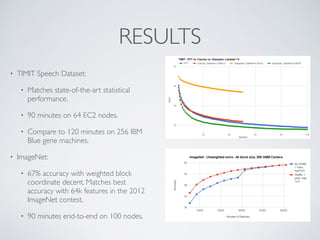







KeystoneML is a software framework for building scalable machine learning pipelines. It provides tools for data loading, feature extraction, model training, and evaluation that work across multiple domains like computer vision, NLP, and speech. Pipelines built with KeystoneML can achieve state-of-the-art results on large datasets using modest computing resources. The framework is open source and available on GitHub.











































































































