




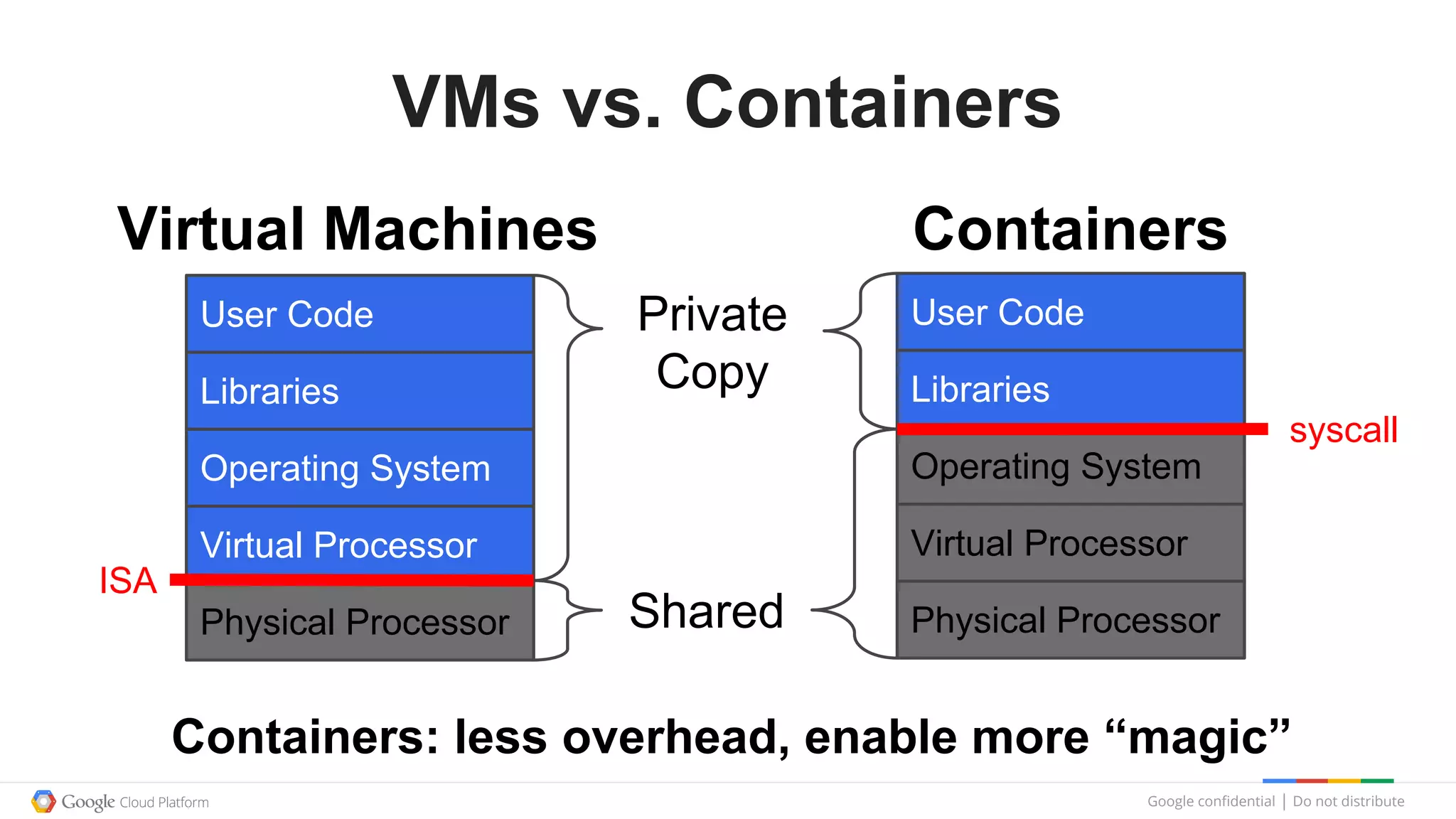

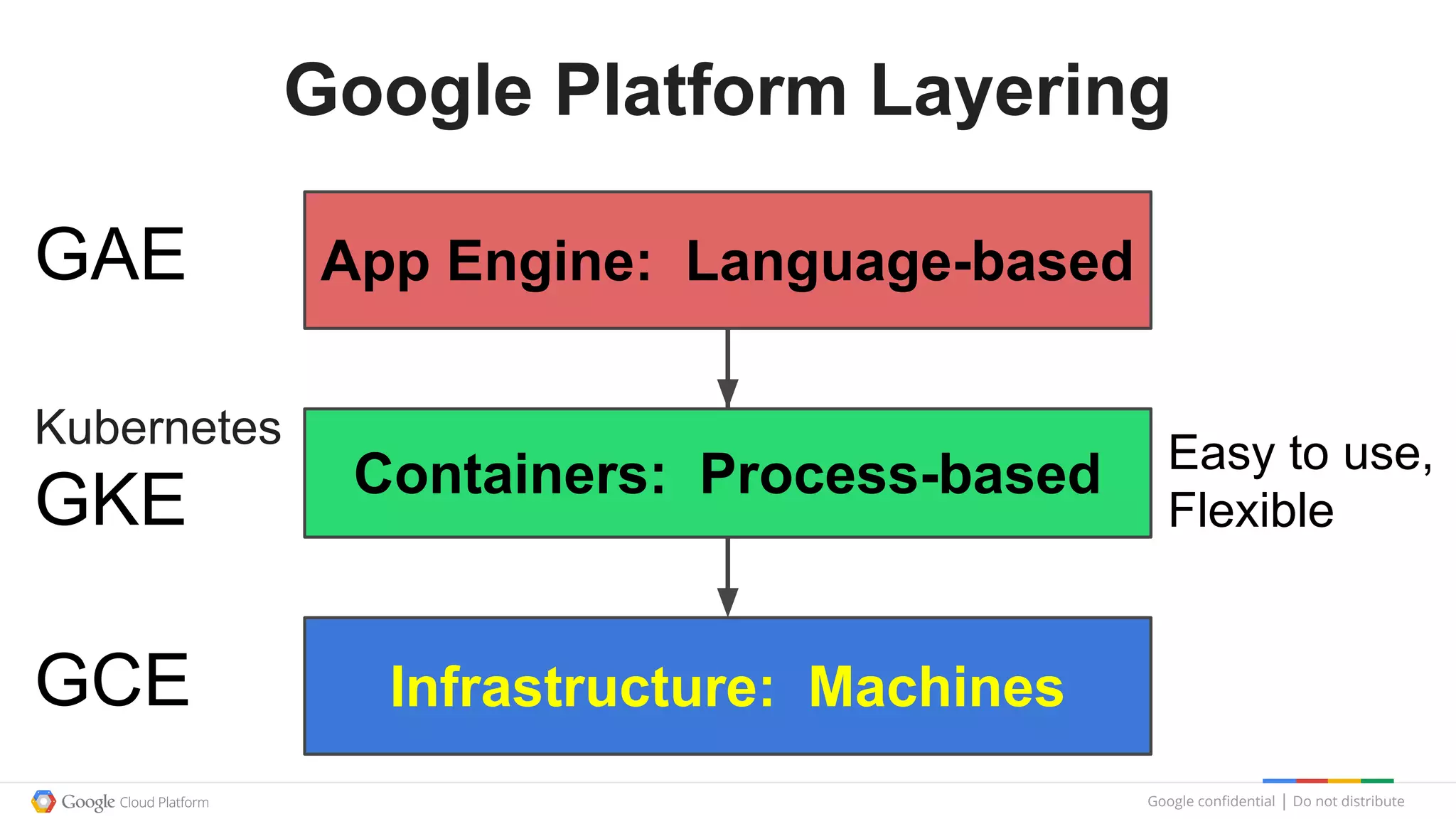









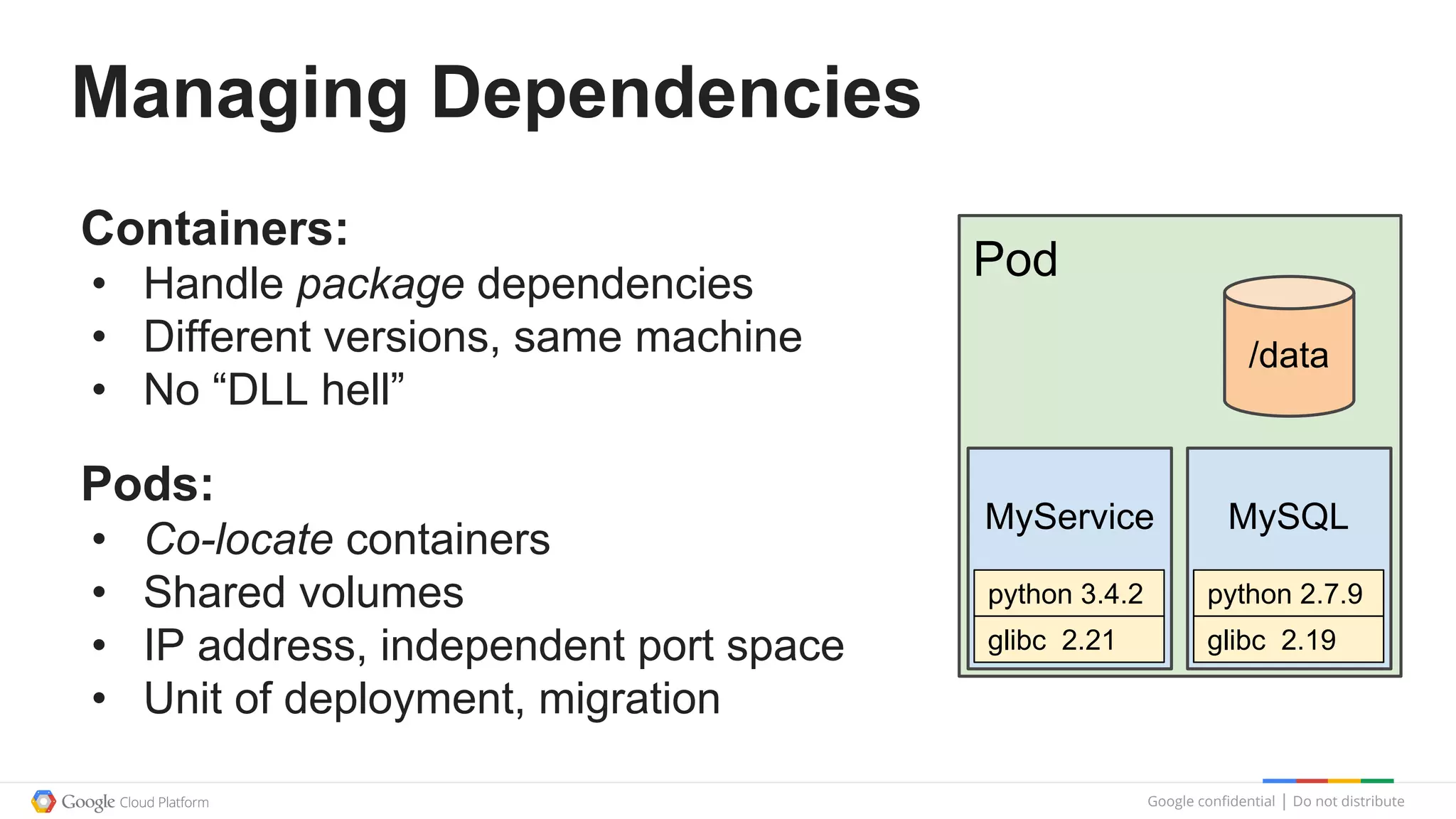
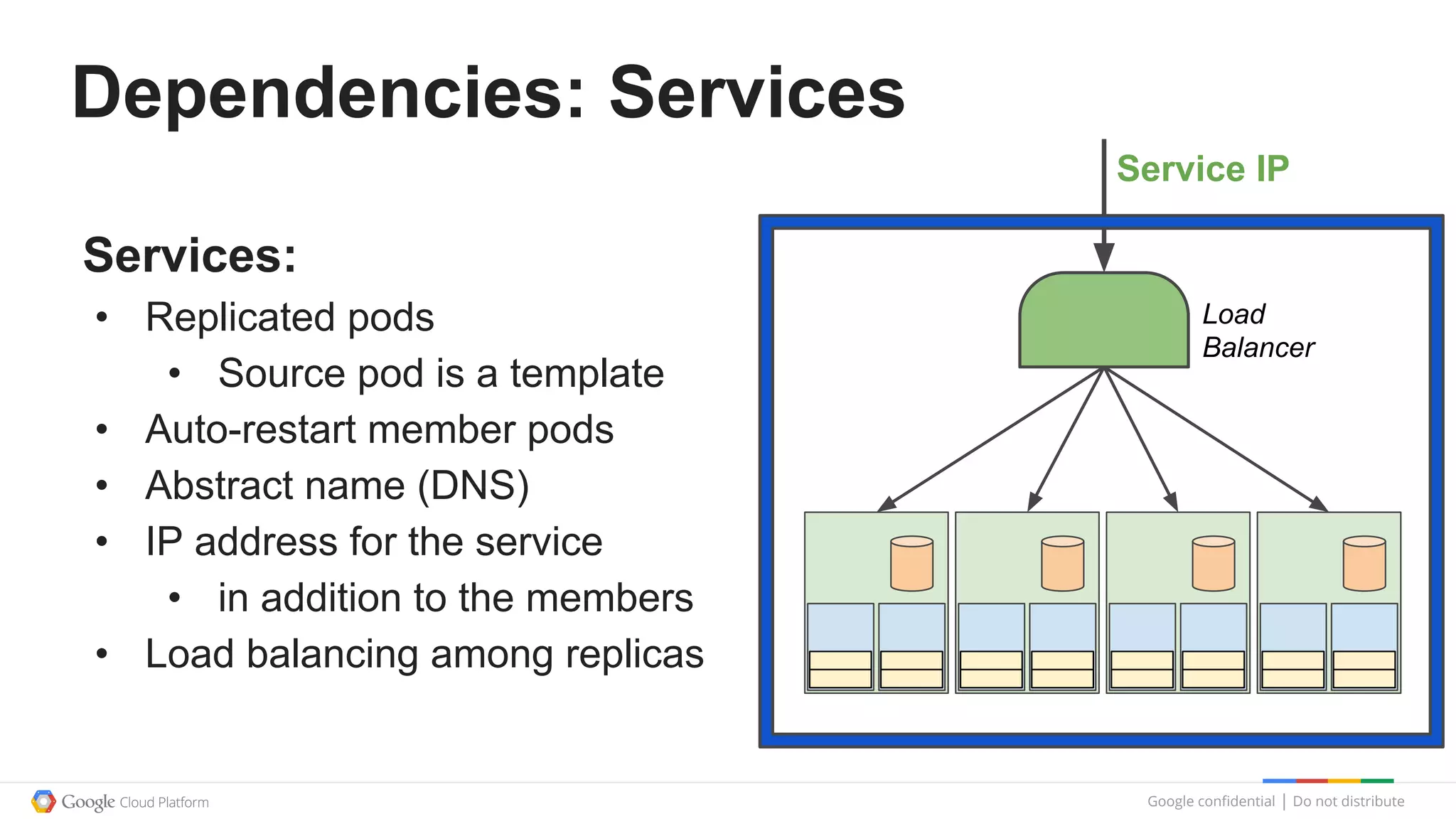
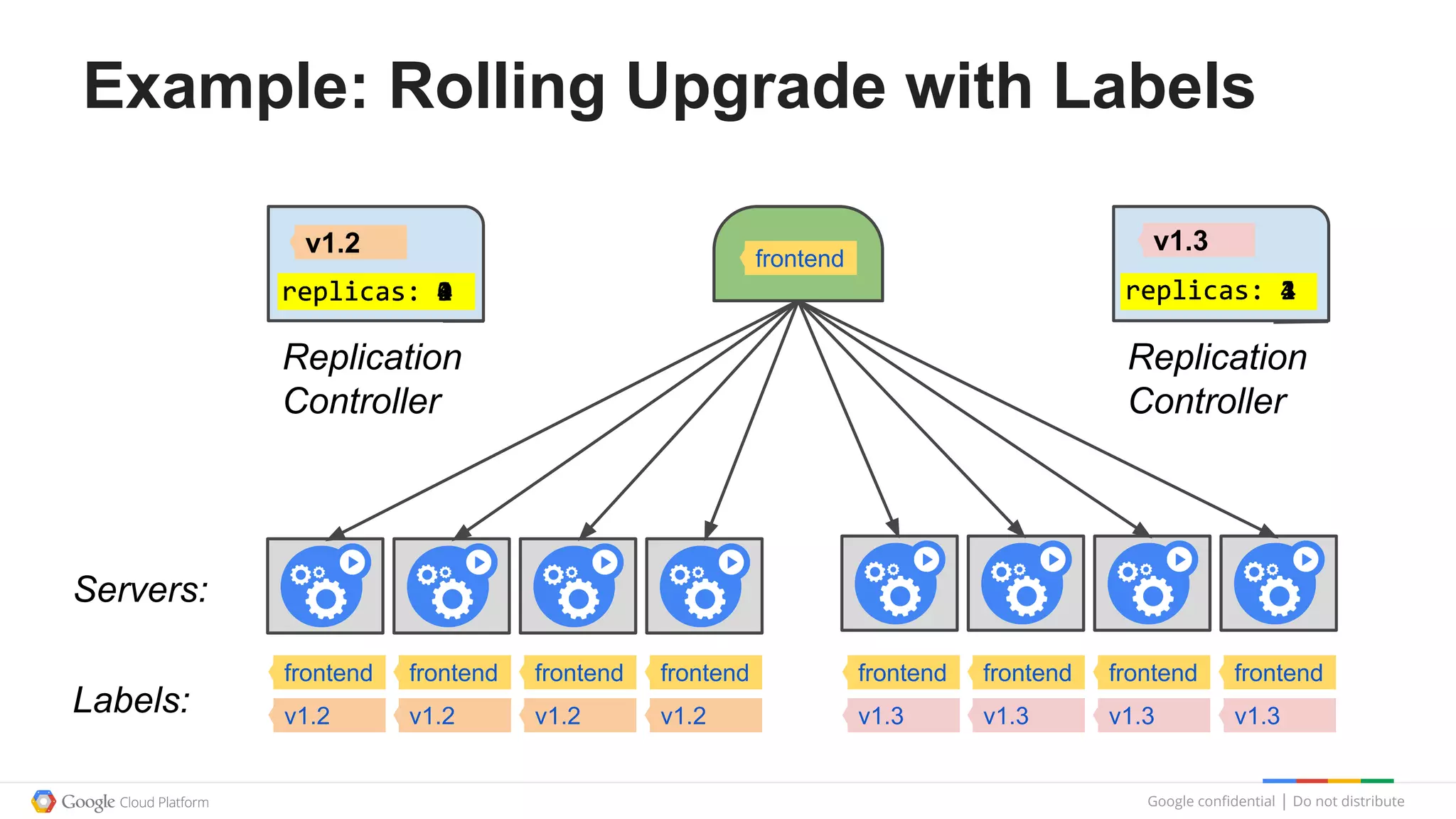


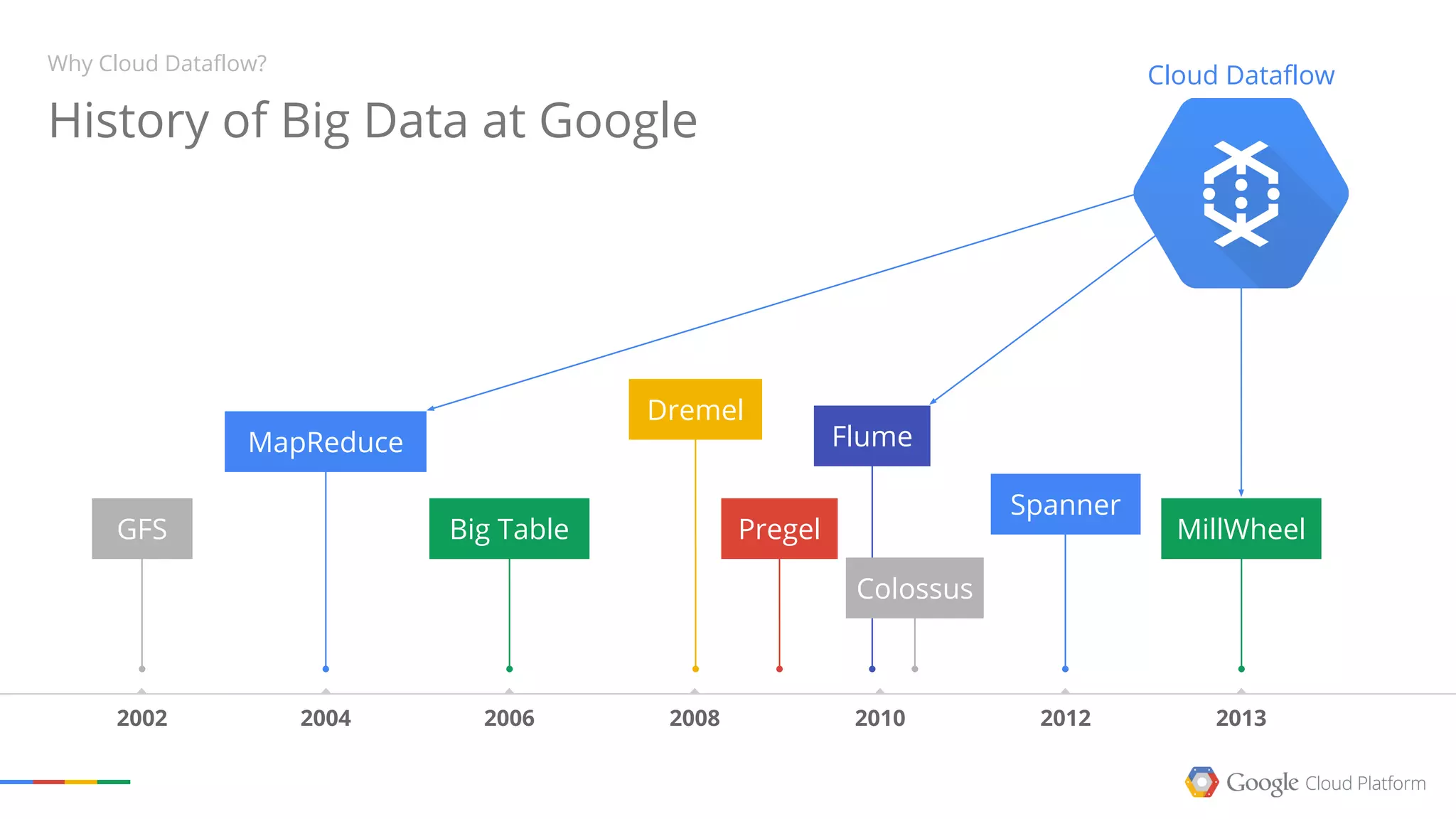


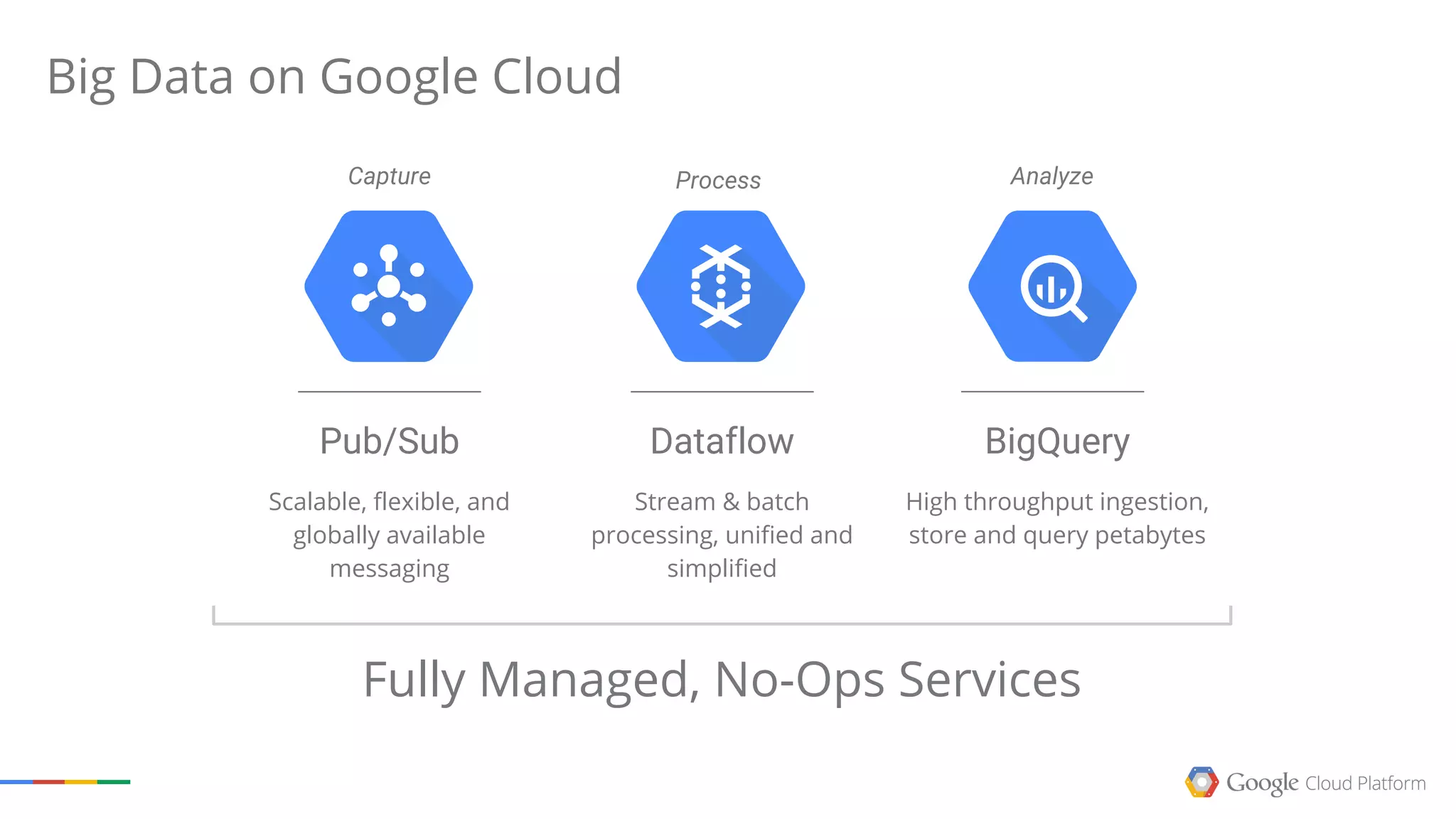



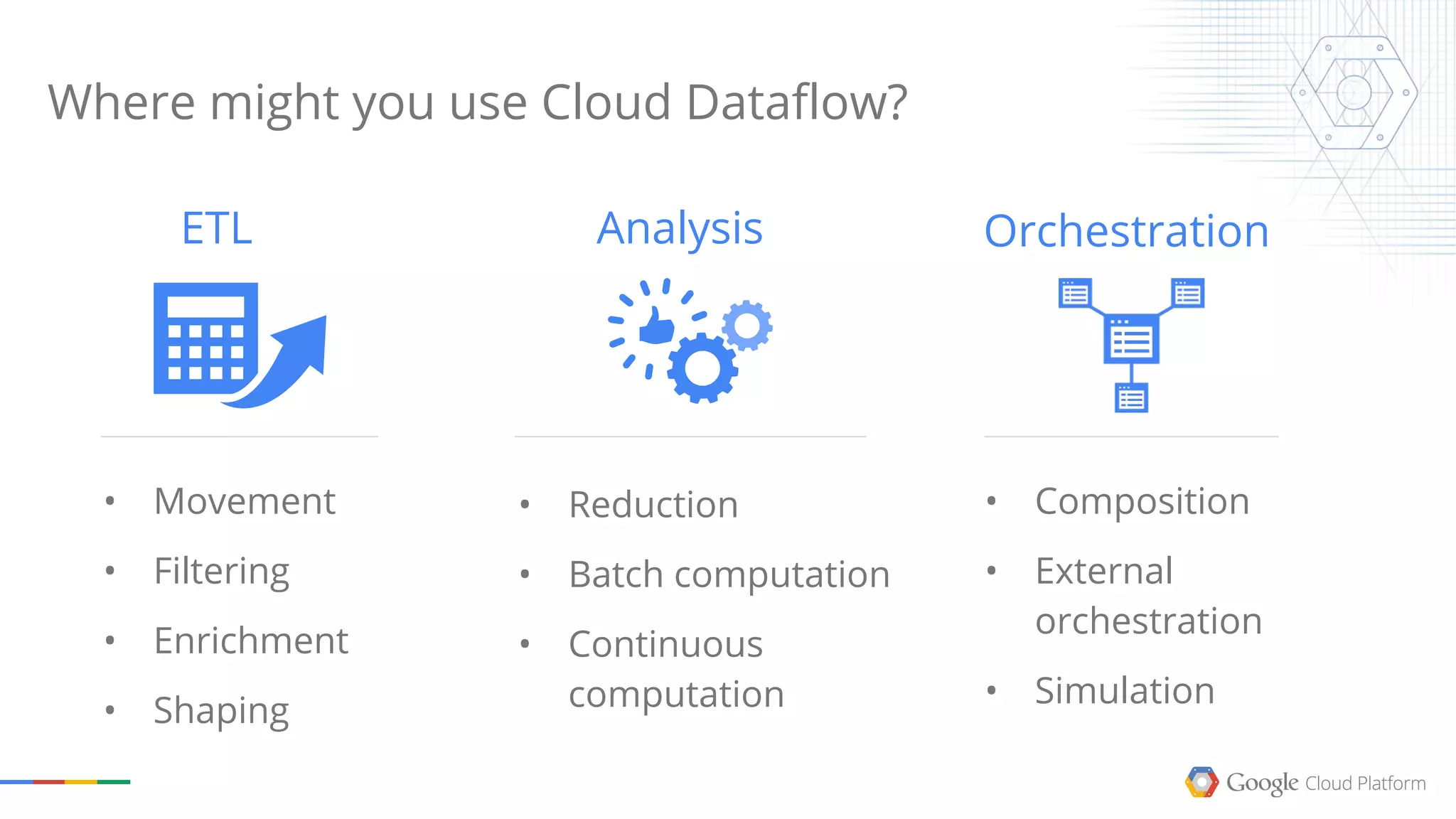






This document summarizes a Google Tech Talk given by Dr. Eric Brewer on containers. The talk discussed how Google has been using containers for over 10 years to manage applications, with over 2 billion containers launched per week. Containers were described as providing simplification of management, performance isolation, and efficiency. Docker and Linux containers were discussed as merging the packaging benefits of Docker with the isolation capabilities of Linux containers. Kubernetes, an open source container orchestration system inspired by Google's internal systems, was also summarized.
![[English] Create Mobile LBS Application Using Maps API](https://cdn.slidesharecdn.com/ss_thumbnails/createmobilelbsapplicationusingmapsapi-googleonemobileeventen-150422202736-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






















































































