2020年4月16日 計算科学技術特論B
14
f (x) =
1
2
(x,Ax)−(b,x)
f (x) =
1
2
aij xi xj −
j=1
n
∑
i=1
n
∑ bi xi
i=1
n
∑
∂ f (x)
∂xk
=
1
2
aik xi
i=1
n
∑ +
1
2
akj xj
j=1
n
∑ − bk
∂ f (x)
∂xk
= aki xi
i=1
n
∑ − bk = 0
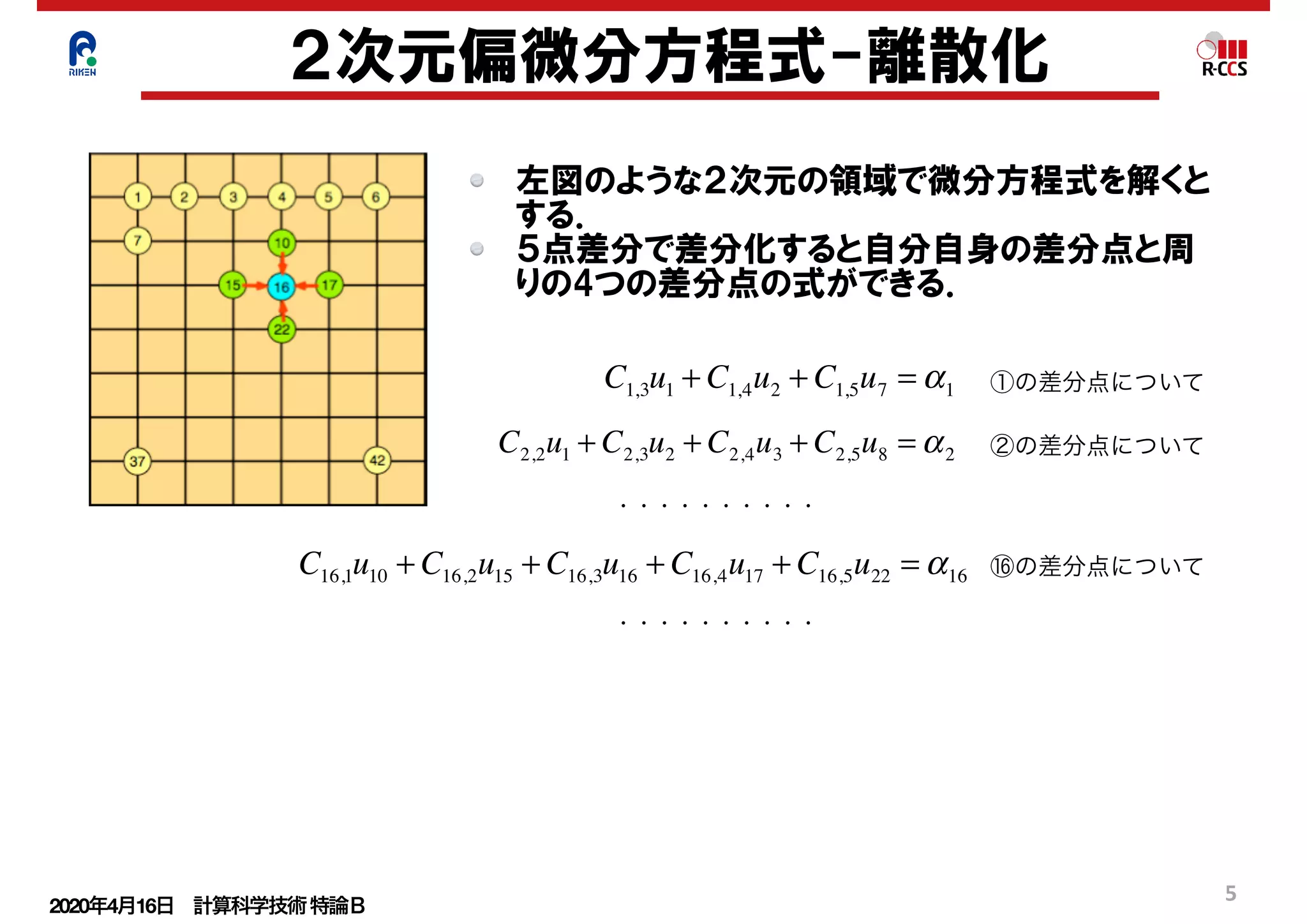
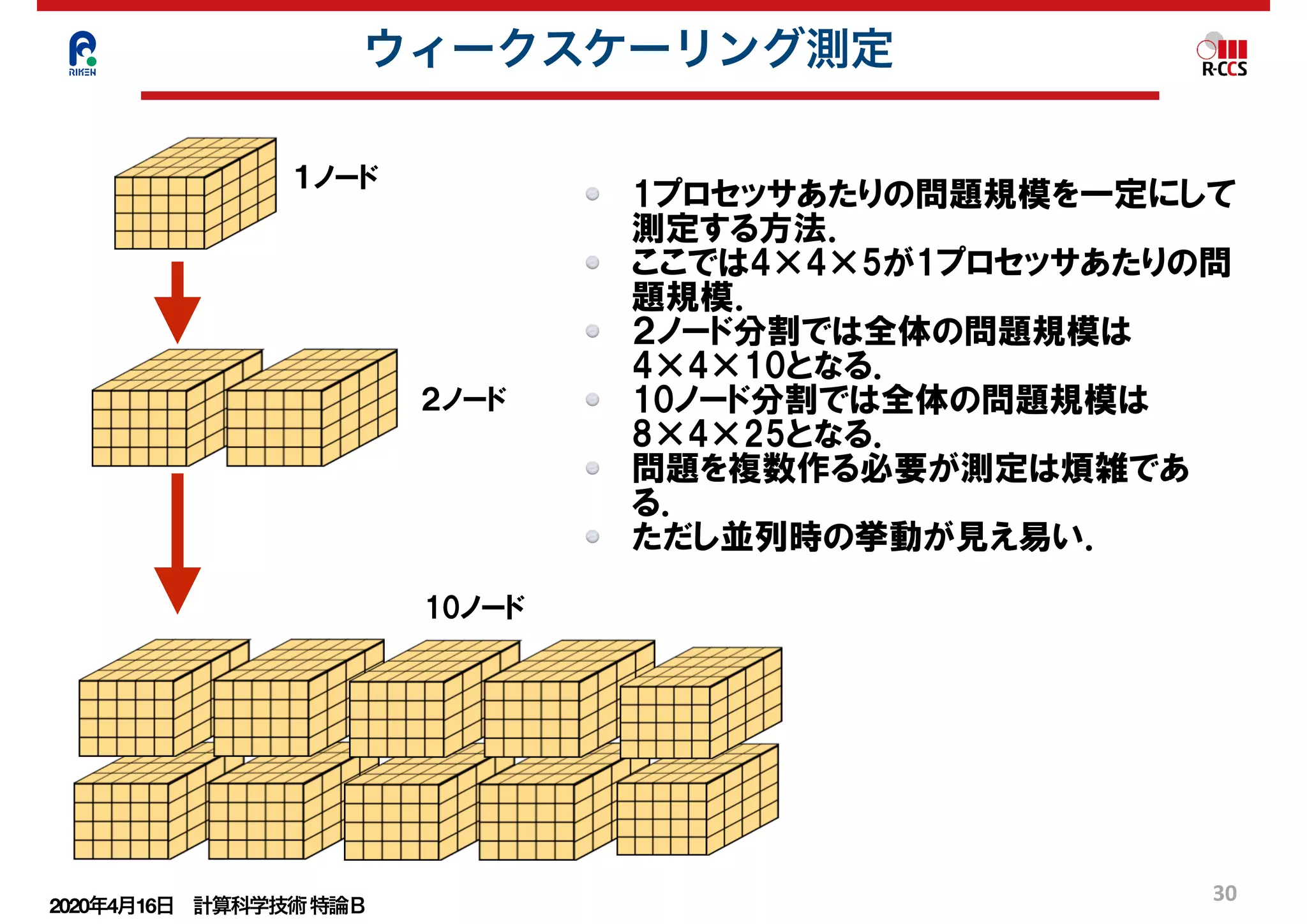
共役勾配法(CG法)
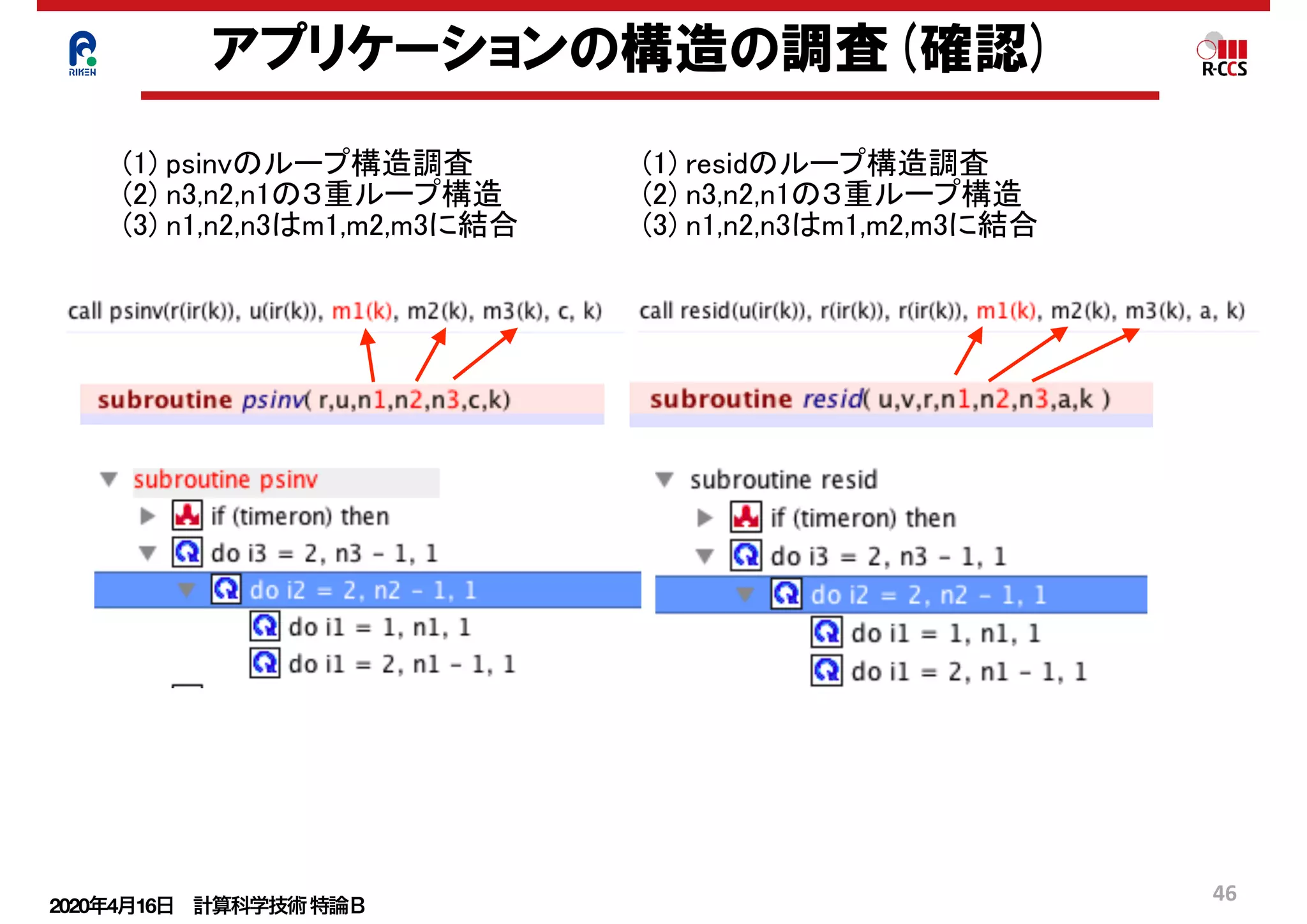
①の2次の関数を考える.
この関数の最小値問題を解くためにf(x)の
微分を取り0とおく.
②より①の最小値問題を解く事がax=bの解
を得る事と同等であることが分かる.
上記と同様な事を多次元のベクトルで行う.
①と同等な関数として③を考える.
③を成分で標記すると④のようになる.
④をxで偏微分すると⑤になる.
行列Aの対称性を使い0とおくことにより⑥
が得られる.
⑥は連立一次方程式⑦の成分表示である.
したがって③の最小値問題を解く事が連立
一次方程式⑦を解くこととなる.
f (x) =
1
2
ax2
− bx ・・・①
・・・②
・・・③
・・④
・・⑤
・・・⑥
f '(x) = ax − b = 0
Ax = b ・・・⑦
2020年4月16日 計算科学技術特論B
36
DGEMM tuned forthe K computer was also used for the
LINPACK benchmark program.
5.2 Scalability
We measured the computation time for the SCF iterations with
communications for the parallel tasks in orbitals, however, was
actually restricted to a relatively small number of compute nodes,
and therefore, the wall clock time for global communications of
the parallel tasks in orbitals was small. This means we succeeded
in decreasing time for global communication by the combination
Figure 6. Computation and communication time of (a) GS, (b) CG, (c) MatE/SD and (d)
RotV/SD for different numbers of cores.
0.0
40.0
80.0
120.0
160.0
0 20000 40000 60000 80000
TimeperCG(sec.)
Number of cores
theoretical computation
computation
adjacent/space
global/space
global/orbital
0.0
100.0
200.0
300.0
400.0
0 20,000 40,000 60,000 80,000
TimeperGS(sec.)
Number of cores
theoretical computation
computation
global/space
global/orbital
wait/orbital
0.0
50.0
100.0
150.0
200.0
0 20,000 40,000 60,000 80,000
TimeperMatE/SD(sec.)
Number of cores
theoretical computation
computation
adjacent/space
global/space
global/orbital
0.0
100.0
200.0
300.0
0 20,000 40,000 60,000 80,000
TimeperRotV/SD(sec.)
Number of cores
theoretical computation
computation
adjacent/space
global/space
global/orbital
(d)(c)
(a) (b)
ストロングスケーリングだけどスケールをモデル化した例


























![2020年4月16日 計算科学技術特論B
34
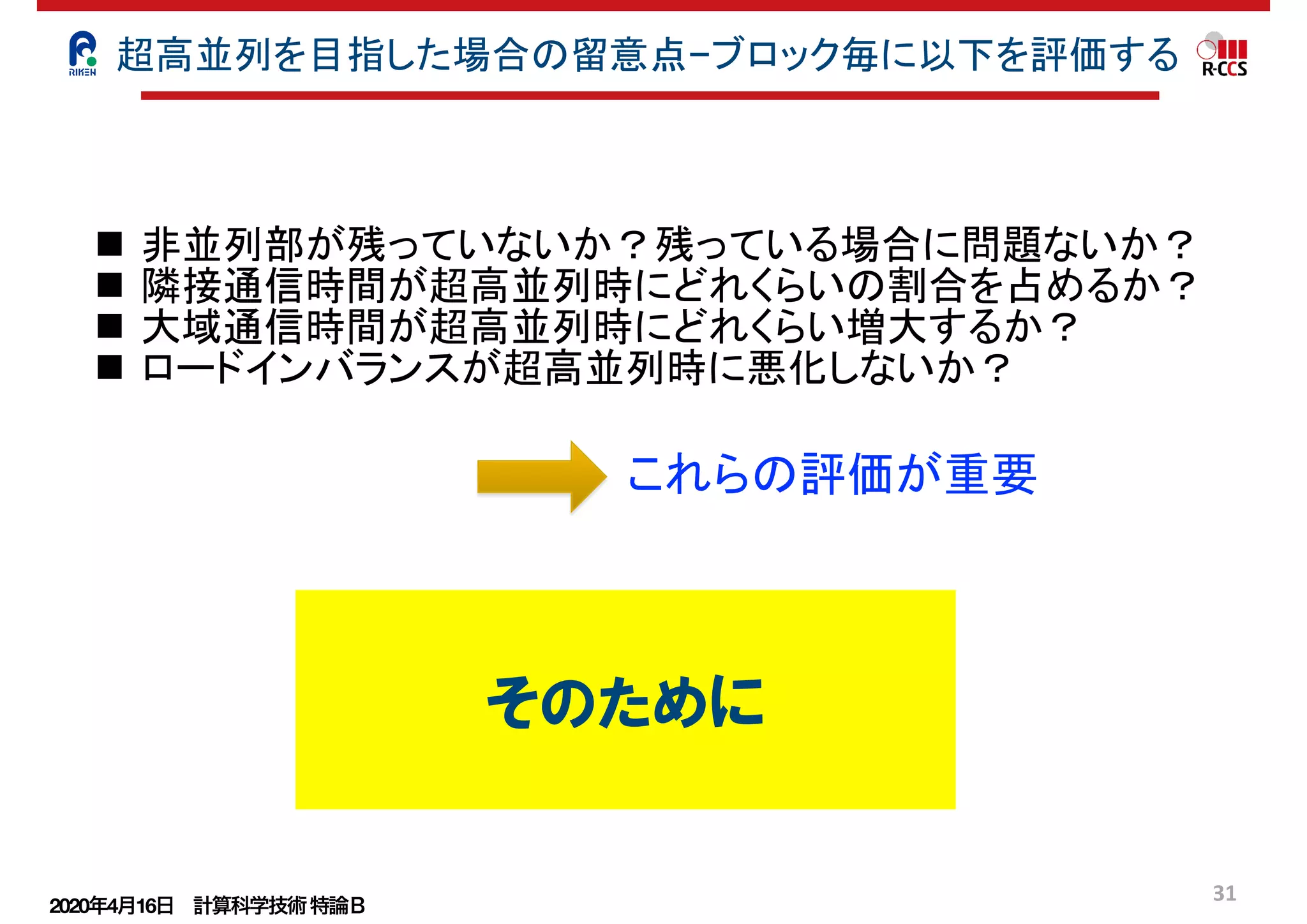
場合が出てくる。これが、アプリケーションとハードウェアの並列度のミスマッ
アプリケーションの並列度の限界に近づいてくると、演算時間が著しく小さくな
し通信時間の割合が増大する状態となり、並列効率の悪化を招く。
2 点目は、非並列部の残存である。本節の冒頭に述べたように、演算部分に非
残っているとアムダールの法則により、並列性能の悪化を招く。ここで、あるア
ションの逐次実行時の実行時間を Ts であるとし、そのアプリケーションの並列
であるとすると、アプリケーションの非並列化率は 1 − α となる。このアプリケ
を並列度 n で実行すると、n 並列での実行時間 Tn は、Tn = Ts(α
n + (1 − α)
る。仮に n = 10000 の時に並列化効率 50%を達成するための α を求めると、並
は 99.99%を要求されることになる。非並列部の残存を発見しやすいのは、前述
ウィークスケーリング測定による、演算部の実行時間の増大である。
3 点目は、大域通信における大きな通信サイズ、通信回数の発生である。通信
に大域通信は、並列性能に大きな影響を与える。n ノード間で m[Byte] の allr
を実施する例を考える。2 分木のアルゴリズムにより allreduce 通信を実施し通
Pt[B/sec] と仮定すると、全ノードが通信を終わり m[Byte] の総和量を取得する
信時間 T は、T = m×log 2n
Pt
で計算される。大域通信と隣接通信と比較するため
ドが隣のランクに m[Byte] の隣接通信を実施する例を考える。通信性能を上記の
m
度しか使えない、という
列度のミスマッチである。
著しく小さくなるのに対
。
、演算部分に非並列部が
ここで、あるアプリケー
ーションの並列化率を α
。このアプリケーション
(α
n + (1 − α)) で表され
を求めると、並列化率 α
すいのは、前述した通り
る。
生である。通信時間、特
[Byte] の allreduce 通信
通信を実施し通信性能が
和量を取得するための通
比較するために、n ノー
ョンの並列化の限界から、数千の並列度しか使えない、という
アプリケーションとハードウェアの並列度のミスマッチである。
の限界に近づいてくると、演算時間が著しく小さくなるのに対
る状態となり、並列効率の悪化を招く。
存である。本節の冒頭に述べたように、演算部分に非並列部が
法則により、並列性能の悪化を招く。ここで、あるアプリケー
時間を Ts であるとし、そのアプリケーションの並列化率を α
ーションの非並列化率は 1 − α となる。このアプリケーション
n 並列での実行時間 Tn は、Tn = Ts(α
n + (1 − α)) で表され
並列化効率 50%を達成するための α を求めると、並列化率 α
とになる。非並列部の残存を発見しやすいのは、前述した通り
による、演算部の実行時間の増大である。
ける大きな通信サイズ、通信回数の発生である。通信時間、特
大きな影響を与える。n ノード間で m[Byte] の allreduce 通信
分木のアルゴリズムにより allreduce 通信を実施し通信性能が
全ノードが通信を終わり m[Byte] の総和量を取得するための通
で計算される。大域通信と隣接通信と比較するために、n ノー
プリケーションの並列化の限界から、数千の並列度しか使えない、という
。これが、アプリケーションとハードウェアの並列度のミスマッチである。
ンの並列度の限界に近づいてくると、演算時間が著しく小さくなるのに対
合が増大する状態となり、並列効率の悪化を招く。
列部の残存である。本節の冒頭に述べたように、演算部分に非並列部が
ムダールの法則により、並列性能の悪化を招く。ここで、あるアプリケー
行時の実行時間を Ts であるとし、そのアプリケーションの並列化率を α
、アプリケーションの非並列化率は 1 − α となる。このアプリケーション
行すると、n 並列での実行時間 Tn は、Tn = Ts(α
n + (1 − α)) で表され
000 の時に並列化効率 50%を達成するための α を求めると、並列化率 α
されることになる。非並列部の残存を発見しやすいのは、前述した通り
リング測定による、演算部の実行時間の増大である。
通信における大きな通信サイズ、通信回数の発生である。通信時間、特
並列性能に大きな影響を与える。n ノード間で m[Byte] の allreduce 通信
考える。2 分木のアルゴリズムにより allreduce 通信を実施し通信性能が
すると、全ノードが通信を終わり m[Byte] の総和量を取得するための通
ケーションの並列化の限界から、数千の並列度しか使えない、という
れが、アプリケーションとハードウェアの並列度のミスマッチである。
並列度の限界に近づいてくると、演算時間が著しく小さくなるのに対
が増大する状態となり、並列効率の悪化を招く。
部の残存である。本節の冒頭に述べたように、演算部分に非並列部が
ダールの法則により、並列性能の悪化を招く。ここで、あるアプリケー
時の実行時間を Ts であるとし、そのアプリケーションの並列化率を α
アプリケーションの非並列化率は 1 − α となる。このアプリケーション
すると、n 並列での実行時間 Tn は、Tn = Ts(α
n + (1 − α)) で表され
0 の時に並列化効率 50%を達成するための α を求めると、並列化率 α
れることになる。非並列部の残存を発見しやすいのは、前述した通り
ング測定による、演算部の実行時間の増大である。
信における大きな通信サイズ、通信回数の発生である。通信時間、特
列性能に大きな影響を与える。n ノード間で m[Byte] の allreduce 通信
える。2 分木のアルゴリズムにより allreduce 通信を実施し通信性能が
ると、全ノードが通信を終わり m[Byte] の総和量を取得するための通
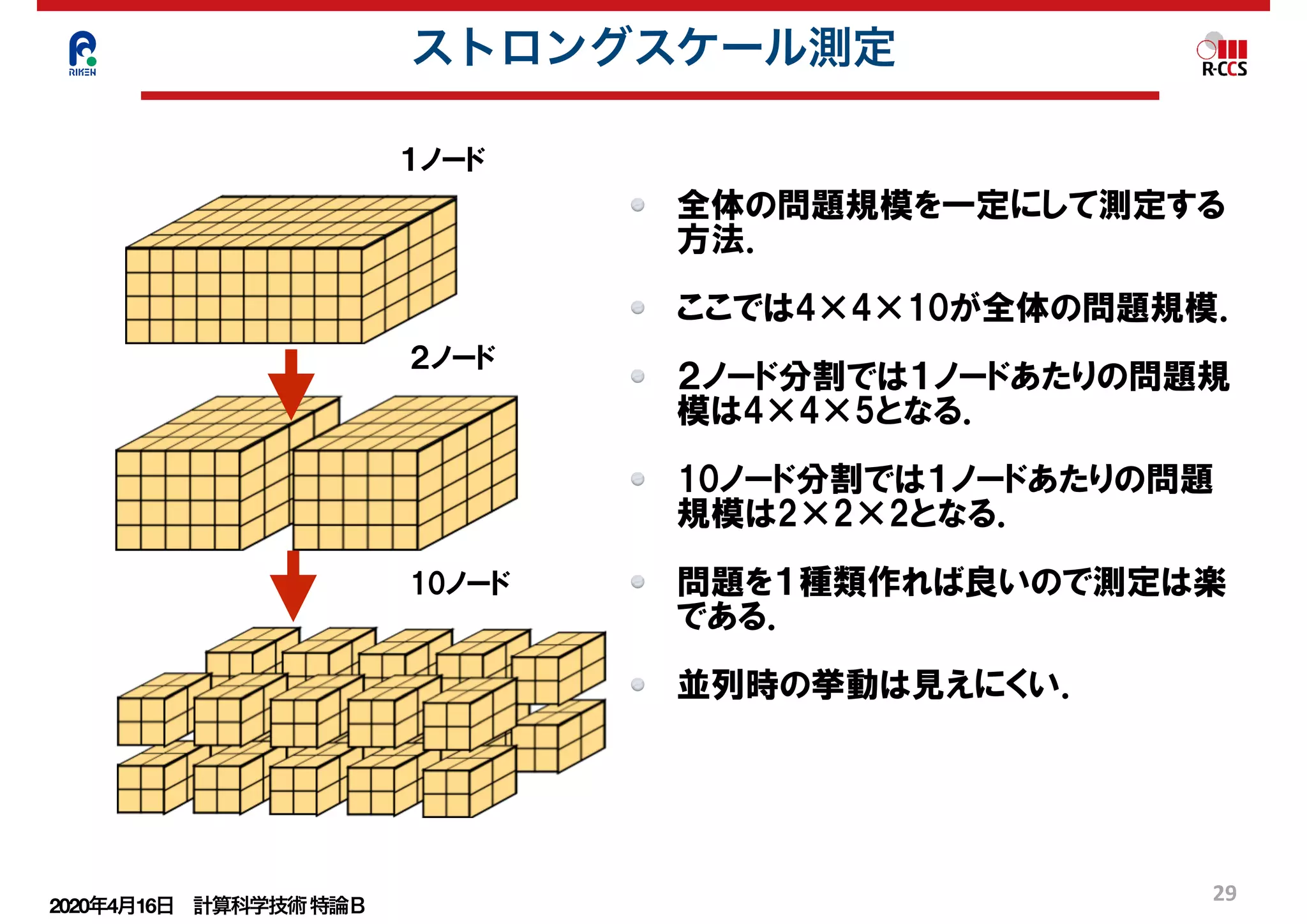
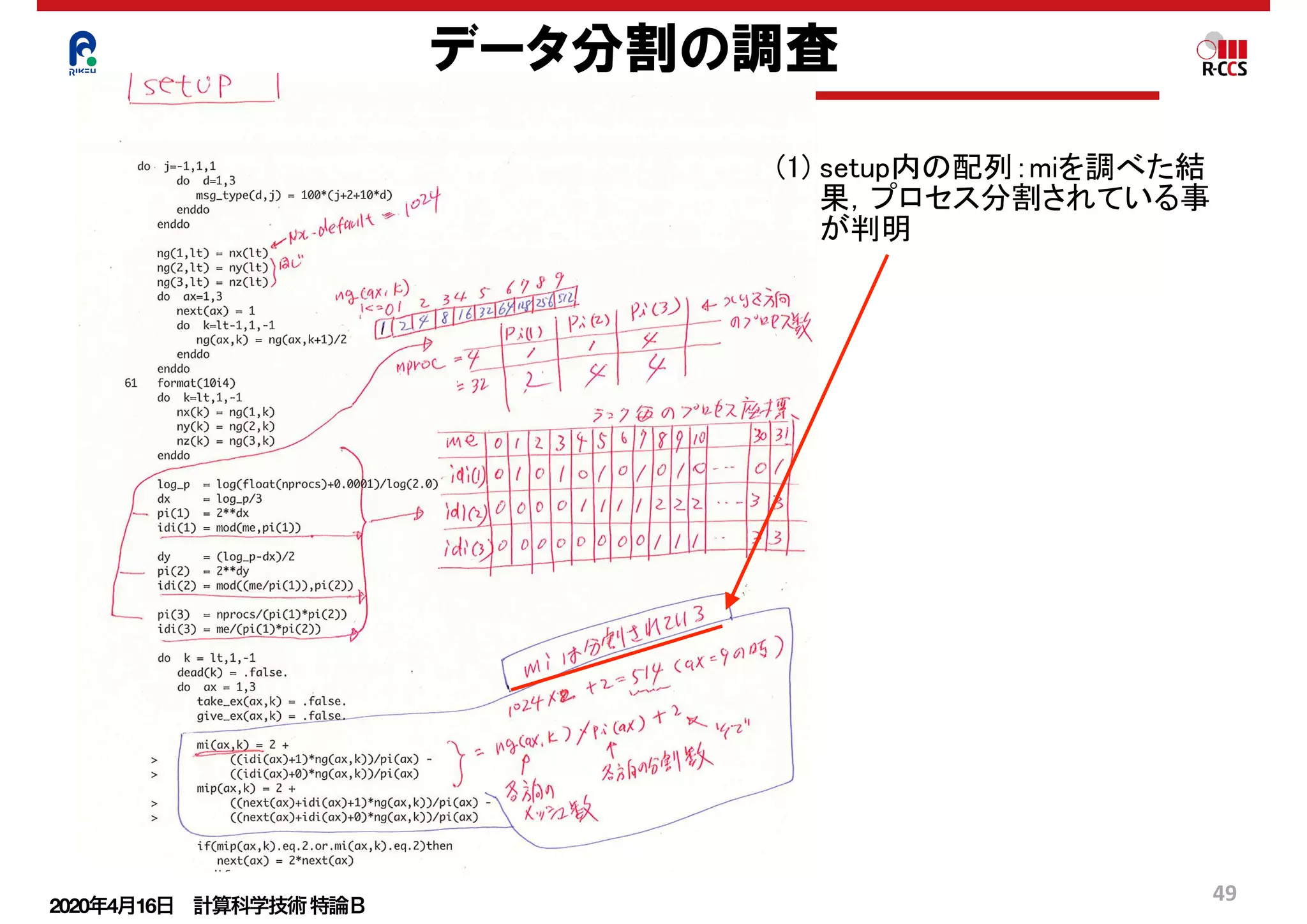
大規模並列のウィークスケーリング評価
非並列部の評価
Tn = Ts
α
n
+Ts (1−α)
T2n = 2Ts
α
2n
+ 2Ts (1−α) = Ts
α
n
+ 2Ts (1−α)
並列度を上げると,ここが
どんどん大きくなる](https://image.slidesharecdn.com/200416materialminami-200415004023/75/slide-34-2048.jpg)



















![2020年4月16日 計算科学技術特論B
59
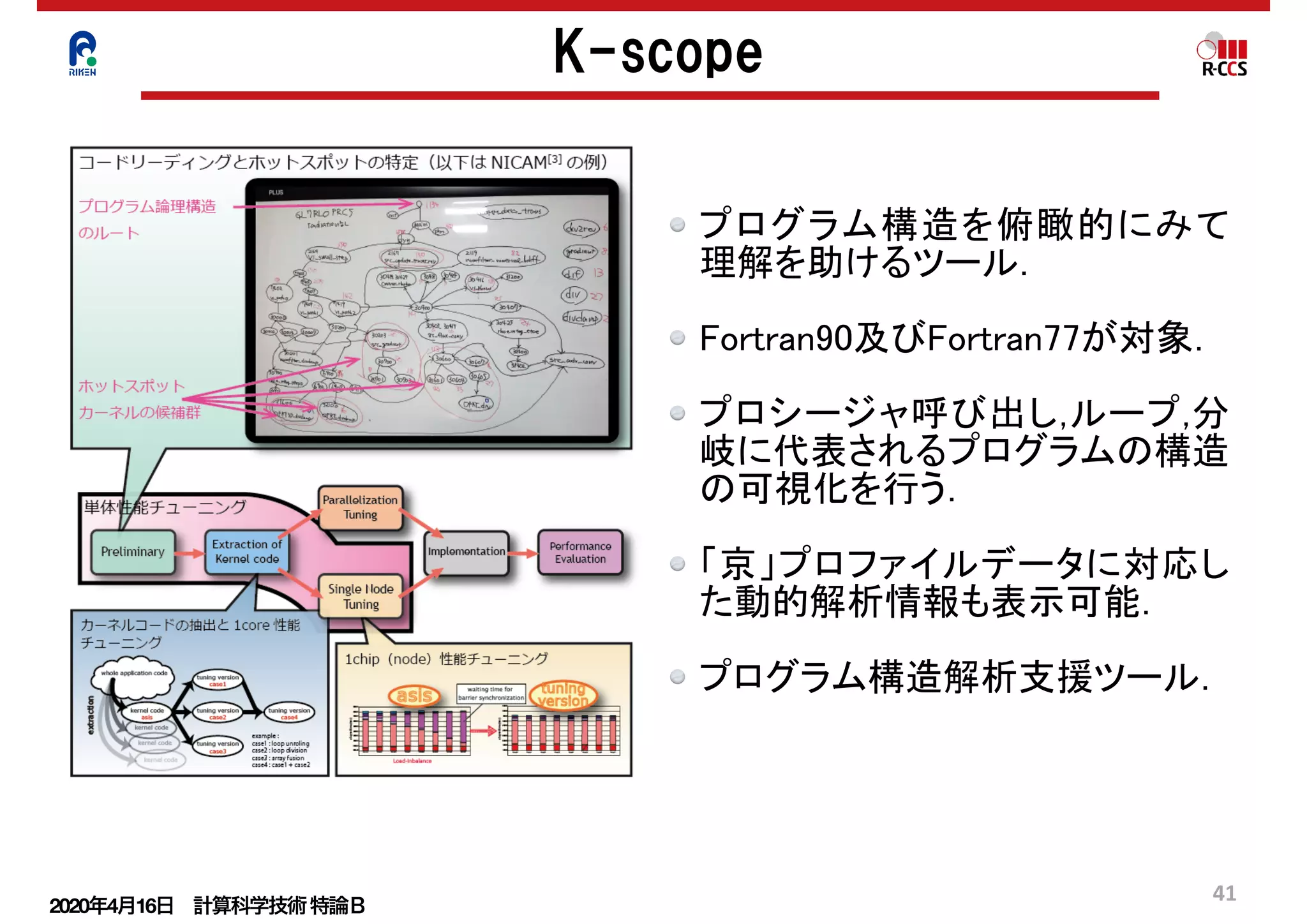
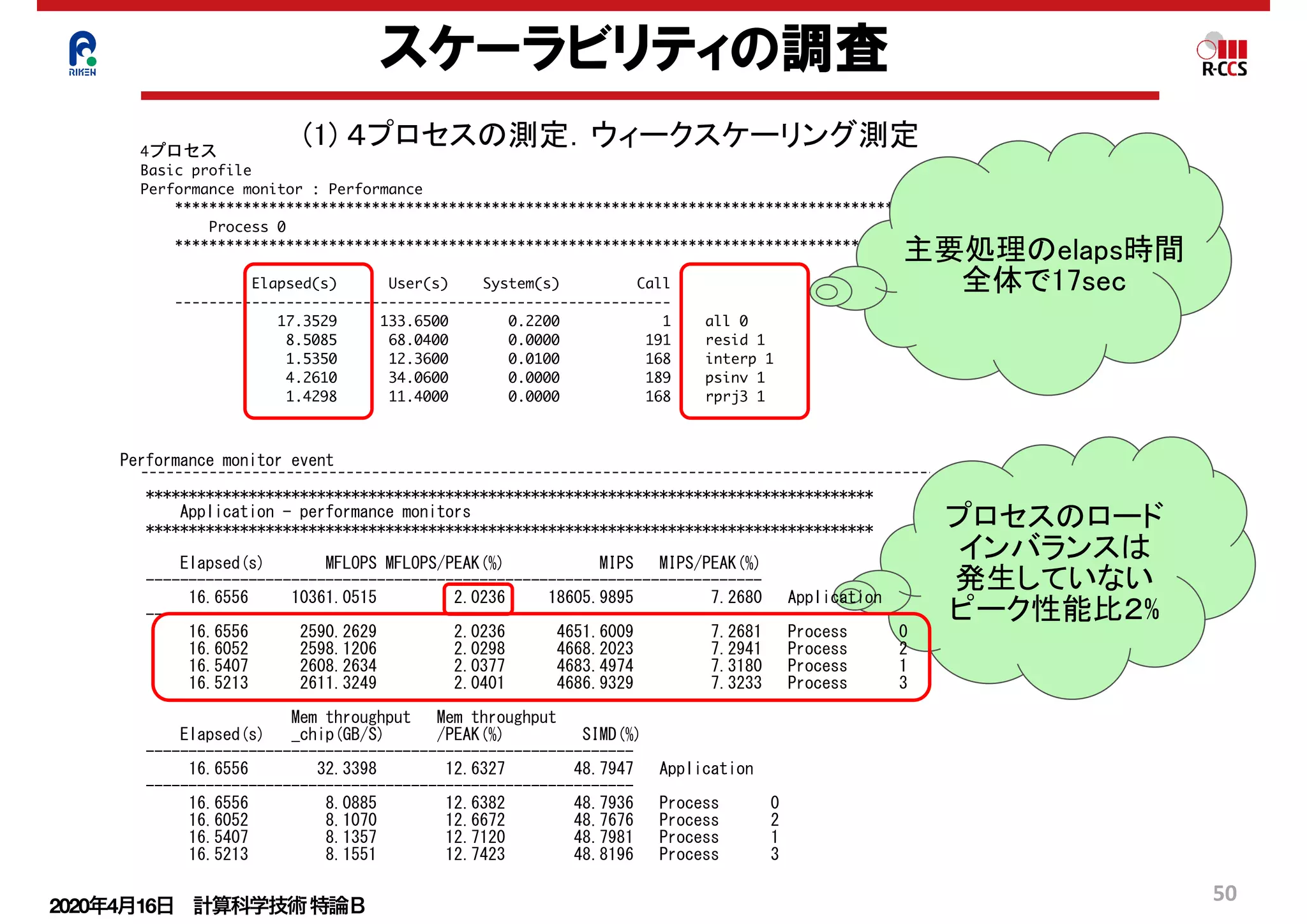
非並列部の残存
第一原理アプリケーションの処理ブロック:ノンローカル項の計算部分を例に示す.
低並列でストロングスケールで測定.
すでにこの並列度でスケールしていない.原因は次ページに示す.
!
BLAS Level3 ( 2)
(
!
BLAS Level3 ( 2)
(
0
2
4
6
8
10
12
14
16
[s]](https://image.slidesharecdn.com/200416materialminami-200415004023/75/slide-59-2048.jpg)








![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)





![[MIRU2018] Global Average Poolingの特性を用いたAttention Branch Network](https://cdn.slidesharecdn.com/ss_thumbnails/miru2018longorl-v3-180810062528-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)






















































