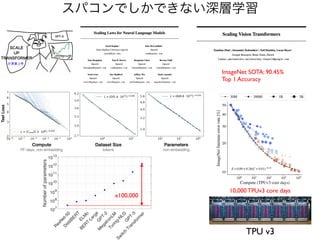
スパコンでしかできない深層学習
TPU v3
ImageNet SOTA:90.45%
Top 1 Accuracy
10,000 TPUv3 core days
R
e
s
N
e
t
-
5
0
D
i
s
t
i
l
B
E
R
T
E
L
M
o
B
E
R
T
-
L
a
r
g
e
G
P
T
-
2
M
e
g
a
t
r
o
n
L
M
T
u
r
i
n
g
-
N
L
G
G
P
T
-
3
S
w
i
t
c
h
T
r
a
n
s
f
o
r
m
e
r
10
7
10
8
10
9
10
10
10
11
10
12
10
13
Number
of
parameters
x100,000
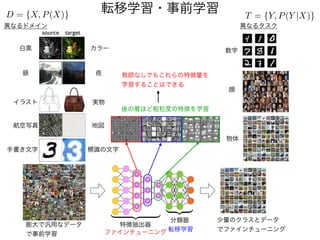
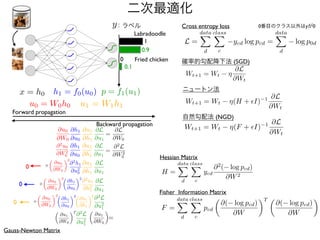
計算量上等
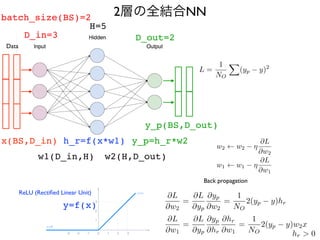
NumPyだけによる実装
import numpy asnp
epochs = 300
batch_size = 32
D_in = 784
H = 100
D_out = 10
learning_rate = 1.0e-06
# create random input and output data
x = np.random.randn(batch_size, D_in)
y = np.random.randn(batch_size, D_out)
# randomly initialize weights
w1 = np.random.randn(D_in, H)
w2 = np.random.randn(H, D_out)
for epoch in range(epochs):
# forward pass
h = x.dot(w1) # h = x * w1
h_r = np.maximum(h, 0) # h_r = ReLU(h)
y_p = h_r.dot(w2) # y_p = h_r * w2
# compute mean squared error and print loss
loss = np.square(y_p - y).sum()
print(epoch, loss)
# backward pass: compute gradients of loss with respect to w2
grad_y_p = 2.0 * (y_p - y)
grad_w2 = h_r.T.dot(grad_y_p)
# backward pass: compute gradients of loss with respect to w1
grad_h_r = grad_y_p.dot(w2.T)
grad_h = grad_h_r.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# update weights
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
w1 w1 ⌘
@L
@w1
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
w2 w2 ⌘
@L
@w2
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
@L
@w2
=
@L
@yp
@yp
@w2
=
1
NO
2 (yp y) hr
@L
@w1
=
@L
@yp
@yp
@hr
@hr
@w1
=
1
NO
2 (yp y) w2x
L =
1
NO
X
(yp y)
2
00_numpy.py
19.
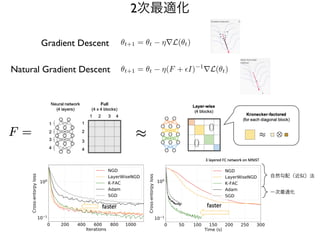
PyTorch の導入
import torch
epochs= 300
batch_size = 32
D_in = 784
H = 100
D_out = 10
learning_rate = 1.0e-06
# create random input and output data
x = torch.randn(batch_size, D_in)
y = torch.randn(batch_size, D_out)
# randomly initialize weights
w1 = torch.randn(D_in, H)
w2 = torch.randn(H, D_out)
for epoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
# compute and print loss
loss = (y_p - y).pow(2).sum().item()
print(t, loss)
# backward pass: compute gradients of loss with respect to w2
grad_y_p = 2.0 * (y_p - y)
grad_w2 = h_r.t().mm(grad_y_p)
# backward pass: compute gradients of loss with respect to w1
grad_h_r = grad_y_p.mm(w2.t())
grad_h = grad_h_r.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# update weights
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
np.random torch
np torch
x.dot(w1) x.mm(w1)
np.maximum(h, 0) h.clamp(min=0)
np.square(y_p-y) (y_p-y).pow(2)
copy() clone()
01_tensors.py
20.
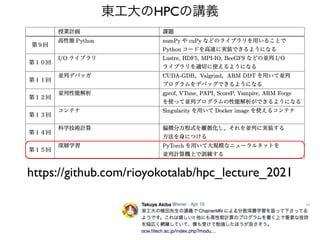
自動微分の導入
# randomly initializeweights
w1 = torch.randn(D_in, H)
w2 = torch.randn(H, D_out)
for epoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
# compute and print loss
loss = (y_p - y).pow(2).sum().item()
print(t, loss)
# backward pass: compute gradients of loss
with respect to w2
grad_y_p = 2.0 * (y_p - y)
grad_w2 = h_r.t().mm(grad_y_p)
# backward pass: compute gradients of loss
with respect to w1
grad_h_r = grad_y_p.mm(w2.t())
grad_h = grad_h_r.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# update weights
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
01_tensor.py 02_autograd.py
# randomly initialize weights
w1 = torch.randn(D_in, H, requires_grad=True)
w2 = torch.randn(H, D_out, requires_grad=True)
for epoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
# compute and print loss
loss = (y_p - y).pow(2).sum()
print(t, loss.item())
# backward pass
loss.backward()
with torch.no_grad():
# update weights
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# initialize weights
w1.grad.zero_()
w2.grad.zero_()
@L
@w1
=
@L
@yp
@yp
@hr
@hr
@w1
=
1
NO
2(yp y)w2x
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
微分を自動的に計算してくれる
21.
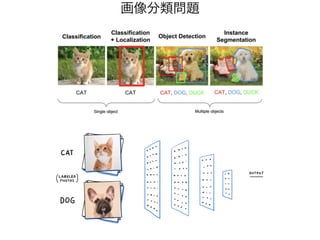
活性化関数の自作 03_function.py
import torch
forepoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
02_autograd.py
import torch
class ReLU(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return input.clamp(min=0)
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
grad_input[input<0] = 0
return grad_input
for epoch in range(epochs):
# forward pass: compute predicted y
relu = ReLU.apply
h = x.mm(w1)
h_r = relu(h)
y_p = h_r.mm(w2)
.
.
.
.
.
.
y=f(x)
ReLU (Rectified Linear Unit)
22.
torch.nnの利用 04_nn_module.py
# createrandom input and output data
x = torch.randn(batch_size, D_in)
y = torch.randn(batch_size, D_out)
# randomly initialize weights
w1 = torch.randn(D_in, H, requires_grad=True)
w2 = torch.randn(H, D_out, requires_grad=True)
for epoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
# compute and print loss
loss = (y_p - y).pow(2).sum()
print(t, loss.item())
# backward pass
loss.backward()
with torch.no_grad():
# update weights
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# initialize weights
w1.grad.zero_()
w2.grad.zero_()
02_autograd.py
# create random input and output data
x = torch.randn(batch_size, D_in)
y = torch.randn(batch_size, D_out)
# define model
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
# define loss function
criterion = torch.nn.MSELoss(reduction='sum')
for epoch in range(epochs):
# forward pass: compute predicted y
y_p = model(x)
# compute and print loss
loss = criterion(y_p, y)
print(t, loss.item())
# backward pass
model.zero_grad()
loss.backward()
with torch.no_grad():
# update weights
for param in model.parameters():
param -= learning_rate * param.grad
23.
最適化関数の呼び出し 05_optimizer.py
04_nn_module.py
# defineloss function
criterion = torch.nn.MSELoss(reduction='sum')
for t in range(epochs):
# forward pass: compute predicted y
y_p = model(x)
# compute and print loss
loss = criterion(y_p, y)
print(t, loss.item())
# backward pass
model.zero_grad()
loss.backward()
with torch.no_grad():
# update weights
for param in model.parameters():
param -= learning_rate * param.grad
# define loss function
criterion = torch.nn.MSELoss(reduction='sum')
# define optimizer
optimizer = torch.optim.SGD(model.parameters(),
lr=learning_rate)
for epoch in range(epochs):
# forward pass: compute predicted y
y_p = model(x)
# compute and print loss
loss = criterion(y_p, y)
print(t, loss.item())
# backward pass
optimizer.zero_grad()
loss.backward()
# update weights
optimizer.step()
24.
モデルを自作 06_mm_module.py
05_optimizer.py
# createrandom input and output data
x = torch.randn(batch_size, D_in)
y = torch.randn(batch_size, D_out)
# define model
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
# define loss function
criterion = torch.nn.MSELoss(reduction='sum')
import torch.nn as nn
import torch.nn.functional as F
class TwoLayerNet(nn.Module):
def __init__(self, D_in, H, D_out):
super(TwoLayerNet, self).__init__()
self.fc1 = nn.Linear(D_in, H)
self.fc2 = nn.Linear(H, D_out)
def forward(self, x):
h = self.fc1(x)
h_r = F.relu(h)
y_p = self.fc2(h_r)
return y_p
# create random input and output data
x = torch.randn(batch_size, D_in)
y = torch.randn(batch_size, D_out)
# define model
model = TwoLayerNet(D_in, H, D_out)
# define loss function
criterion = nn.MSELoss(reduction='sum')
.
.
.
学習時に不変
25.
MNIST Datasetのロード 07_mnist.py
06_mm_module.py
importtorch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
# read input data and labels
train_dataset = datasets.MNIST('./data',
train=True,
download=True,
transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
for epoch in range(epochs):
# Set model to training mode
model.train()
# Loop over each batch from the training set
for batch_idx, (x, y) in enumerate(train_loader):
# forward pass: compute predicted y
y_p = model(x)
.
.
.
import torch.nn as nn
import torch.nn.functional as F
# create random input and output data
x = torch.randn(batch_size, D_in)
y = torch.randn(batch_size, D_out)
for t in range(epochs):
# forward pass: compute predicted y
y_p = model(x)
.
.
.
.
.
.
Models
19_regularization.py
model = VGG('VGG19').to(device)
#model = ResNet18().to(device)
# model = PreActResNet18().to(device)
# model = GoogLeNet().to(device)
# model = DenseNet121().to(device)
# model = ResNeXt29_2x64d().to(device)
# model = MobileNet().to(device)
# model = MobileNetV2().to(device)
# model = DPN92().to(device)
# model = ShuffleNetG2().to(device)
# model = SENet18().to(device)
# model = ShuffleNetV2(1).to(device)
# model = EfficientNetB0().to(device)
# model = RegNetX_200MF().to(device)
今はこれを使っている
他のモデルも試して見ましょう





![NumPyだけによる実装
import numpy as np
epochs = 300
batch_size = 32
D_in = 784
H = 100
D_out = 10
learning_rate = 1.0e-06
# create random input and output data
x = np.random.randn(batch_size, D_in)
y = np.random.randn(batch_size, D_out)
# randomly initialize weights
w1 = np.random.randn(D_in, H)
w2 = np.random.randn(H, D_out)
for epoch in range(epochs):
# forward pass
h = x.dot(w1) # h = x * w1
h_r = np.maximum(h, 0) # h_r = ReLU(h)
y_p = h_r.dot(w2) # y_p = h_r * w2
# compute mean squared error and print loss
loss = np.square(y_p - y).sum()
print(epoch, loss)
# backward pass: compute gradients of loss with respect to w2
grad_y_p = 2.0 * (y_p - y)
grad_w2 = h_r.T.dot(grad_y_p)
# backward pass: compute gradients of loss with respect to w1
grad_h_r = grad_y_p.dot(w2.T)
grad_h = grad_h_r.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# update weights
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
w1 w1 ⌘
@L
@w1
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
w2 w2 ⌘
@L
@w2
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
@L
@w2
=
@L
@yp
@yp
@w2
=
1
NO
2 (yp y) hr
@L
@w1
=
@L
@yp
@yp
@hr
@hr
@w1
=
1
NO
2 (yp y) w2x
L =
1
NO
X
(yp y)
2
00_numpy.py](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-18-320.jpg)
![PyTorch の導入
import torch
epochs = 300
batch_size = 32
D_in = 784
H = 100
D_out = 10
learning_rate = 1.0e-06
# create random input and output data
x = torch.randn(batch_size, D_in)
y = torch.randn(batch_size, D_out)
# randomly initialize weights
w1 = torch.randn(D_in, H)
w2 = torch.randn(H, D_out)
for epoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
# compute and print loss
loss = (y_p - y).pow(2).sum().item()
print(t, loss)
# backward pass: compute gradients of loss with respect to w2
grad_y_p = 2.0 * (y_p - y)
grad_w2 = h_r.t().mm(grad_y_p)
# backward pass: compute gradients of loss with respect to w1
grad_h_r = grad_y_p.mm(w2.t())
grad_h = grad_h_r.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# update weights
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
np.random torch
np torch
x.dot(w1) x.mm(w1)
np.maximum(h, 0) h.clamp(min=0)
np.square(y_p-y) (y_p-y).pow(2)
copy() clone()
01_tensors.py](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-19-320.jpg)
![自動微分の導入
# randomly initialize weights
w1 = torch.randn(D_in, H)
w2 = torch.randn(H, D_out)
for epoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
# compute and print loss
loss = (y_p - y).pow(2).sum().item()
print(t, loss)
# backward pass: compute gradients of loss
with respect to w2
grad_y_p = 2.0 * (y_p - y)
grad_w2 = h_r.t().mm(grad_y_p)
# backward pass: compute gradients of loss
with respect to w1
grad_h_r = grad_y_p.mm(w2.t())
grad_h = grad_h_r.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# update weights
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
01_tensor.py 02_autograd.py
# randomly initialize weights
w1 = torch.randn(D_in, H, requires_grad=True)
w2 = torch.randn(H, D_out, requires_grad=True)
for epoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
# compute and print loss
loss = (y_p - y).pow(2).sum()
print(t, loss.item())
# backward pass
loss.backward()
with torch.no_grad():
# update weights
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# initialize weights
w1.grad.zero_()
w2.grad.zero_()
@L
@w1
=
@L
@yp
@yp
@hr
@hr
@w1
=
1
NO
2(yp y)w2x
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
微分を自動的に計算してくれる](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-20-320.jpg)
![活性化関数の自作 03_function.py
import torch
for epoch in range(epochs):
# forward pass: compute predicted y
h = x.mm(w1)
h_r = h.clamp(min=0)
y_p = h_r.mm(w2)
02_autograd.py
import torch
class ReLU(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return input.clamp(min=0)
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
grad_input[input<0] = 0
return grad_input
for epoch in range(epochs):
# forward pass: compute predicted y
relu = ReLU.apply
h = x.mm(w1)
h_r = relu(h)
y_p = h_r.mm(w2)
.
.
.
.
.
.
y=f(x)
ReLU (Rectified Linear Unit)](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-21-320.jpg)




![Validationデータによる検証
08_validate.py
def validate():
model.eval()
val_loss, val_acc = 0, 0
for data, target in val_loader:
output = model(data)
loss = criterion(output, target)
val_loss += loss.item()
pred = output.data.max(1)[1]
val_acc += 100. * pred.eq(target.data).cpu().sum() / target.size(0)
val_loss /= len(val_loader)
val_acc /= len(val_loader)
print('nValidation set: Average loss: {:.4f}, Accuracy: {:.1f}%n'.format(
val_loss, val_acc))
学習時に使うデータ
ハイパラやモデル
を変えて試すとき
に使うデータ
最終的な精度の評価
に使うデータ
Validation dataのloss
予測クラスがラベルと一致しているか?
パーセンテージに変換
sum()はGPUでやると遅いのでCPUで](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-26-320.jpg)
![train(), main()関数の形で書く
09_train.py
def train(train_loader,model,criterion,optimizer,epoch):
model.train()
t = time.perf_counter()
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 200 == 0:
print('Train Epoch: {} [{:>5}/{} ({:.0%})]tLoss: {:.6f}t Time:{:.4f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
batch_idx / len(train_loader), loss.data.item(),
time.perf_counter() - t))
t = time.perf_counter()
def main():
epochs = 10
batch_size = 32
learning_rate = 1.0e-02
train_dataset = datasets.MNIST('./data',
train=True,
download=True,
transform=transforms.ToTensor())
val_dataset = datasets.MNIST('./data',
train=False,
transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=validation_dataset,
batch_size=batch_size,
shuffle=False)
model = TwoLayerNet(D_in, H, D_out)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
model.train()
train(train_loader,model,criterion,optimizer,epoch)
validate(val_loader,model,criterion)](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-27-320.jpg)
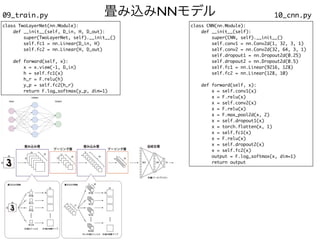

![分散並列
12_distributed.py
import os
import torch
import torch.distributed as dist
master_addr = os.getenv("MASTER_ADDR", default="localhost")
master_port = os.getenv('MASTER_PORT', default='8888')
method = "tcp://{}:{}".format(master_addr, master_port)
rank = int(os.getenv('OMPI_COMM_WORLD_RANK', '0'))
world_size = int(os.getenv('OMPI_COMM_WORLD_SIZE', '1'))
dist.init_process_group("nccl", init_method=method, rank=rank, world_size=world_size)
print('Rank: {}, Size: {}'.format(dist.get_rank(),dist.get_world_size()))
ngpus = 4
device = rank % ngpus
x = torch.randn(1).to(device)
print('rank {}: {}'.format(rank, x))
dist.broadcast(x, src=0)
print('rank {}: {}'.format(rank, x))
通信に用いるホストアドレスとポート番号を指定
OpenMPI環境変数からrankとsizeを取得
PyTorchにこれらを設定
PyTorchによる集団通信
.bashrcに以下を記入
if [ -f "$SGE_JOB_SPOOL_DIR/pe_hostfile" ]; then
export MASTER_ADDR=`head -n 1 $SGE_JOB_SPOOL_DIR/pe_hostfile | cut -d " " -f 1`
fi
mpirun -np 4 python 12_distributed.py](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-30-320.jpg)
![分散並列MNIST
13_ddp.py
def print0(message):
if torch.distributed.is_initialized():
if torch.distributed.get_rank() == 0:
print(message, flush=True)
else:
print(message, flush=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=torch.distributed.get_world_size(),
rank=torch.distributed.get_rank())
model = DDP(model, device_ids=[rank])
.
.
.
.
.
.
全プロセスがprintすると見づらいので1プロセスだけprintするようなprint関数を定義
train dataの読み込みで異なるプロセスが異なるデータを読むようにする
モデルをDDP()に通すことで分散並列計算を行う](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-31-320.jpg)


![ProgressMeter
15_meter.py
def train(train_loader,model,criterion,optimizer,epoch,device):
batch_time = AverageMeter('Time', ':.4f')
train_loss = AverageMeter('Loss', ‘:.6f')
progress = ProgressMeter(
len(train_loader),
[train_loss, batch_time],
prefix="Epoch: [{}]".format(epoch))
class ProgressMeter(object):
def __init__(self, num_batches, meters, prefix="", postfix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
self.postfix = postfix
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
entries += self.postfix
print0('t'.join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = '{:' + str(num_digits) + 'd}'
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
前にprintするもの
後にprintするもの
printしたい変数
printしたいものを連結
[ 今のbatch / 全batch数 ] のような表示をしたい](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-34-320.jpg)
![Weights and Biases
pip install wandb
wandb login
import wandb
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '8888'
rank = int(os.getenv('OMPI_COMM_WORLD_RANK', '0'))
world_size = int(os.getenv('OMPI_COMM_WORLD_SIZE', '1'))
dist.init_process_group("nccl", rank=rank, world_size=world_size)
device = torch.device('cuda',rank)
if torch.distributed.get_rank() == 0:
wandb.init(project="example-project")
wandb.config.update(args)
epochs = args.epochs
batch_size = args.batch_size
learning_rate = args.lr * world_size
for epoch in range(epochs):
model.train()
train_loss, train_acc = train(train_loader,model,criterion,optimizer,epoch,device)
val_loss, val_acc = validate(val_loader,model,criterion,device)
if torch.distributed.get_rank() == 0:
wandb.log({
'train_loss': train_loss,
'train_acc': train_acc,
'val_loss': val_loss,
'val_acc': val_acc
})
wandbで記録したい変数
trainとvalidateがlossとaccuracyを返すようにする
wandbの初期化
argsを渡すと実験条件を勝手に記録してくれる
16_wandb.py](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-35-320.jpg)
![train_dataset = datasets.CIFAR10('./data',
train=True,
download=True,
transform=transforms.ToTensor())
val_dataset = datasets.CIFAR10('./data',
train=False,
download=True,
transform=transforms.ToTensor())
CIFAR10
17_cifar10.py
model = VGG('VGG19').to(device)
model = DDP(model, device_ids=[rank % 4])
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
データセットの変更
モデルの変更](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-36-320.jpg)
![transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_val = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
データ拡張
18_augmentation.py
輝度値の正規化](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-37-320.jpg)
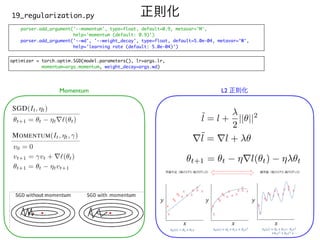
![Sweep
sweep.yaml
program: wrapper.py
method: grid
metric:
goal: minimize
name: val_loss
parameters:
epochs:
values: [100]
batch_size:
values: [32]
learning_rate:
values: [0.005, 0.01, 0.02, 0.05, 0.1]
momentum:
values: [0.85, 0.9, 0.95]
weight_decay:
values: [1.0e-4, 2.0e-4, 5.0e-4, 1.0e-3, 2.0e-3]
wandb sweep sweep.yaml](https://image.slidesharecdn.com/0729yokota-210727025128/85/15-A-2021-39-320.jpg)







![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)

















































