Recommended
PDF
Overcoming Catastrophic Forgetting in Neural Networks読んだ
PDF
PDF
PDF
PDF
SSII2014 詳細画像識別 (FGVC) @OS2
PDF
PDF
PDF
第14回 配信講義 計算科学技術特論B(2022)
PDF
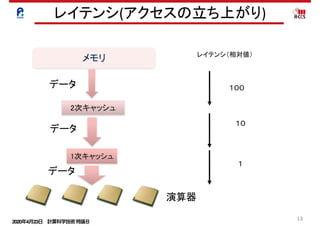
PDF
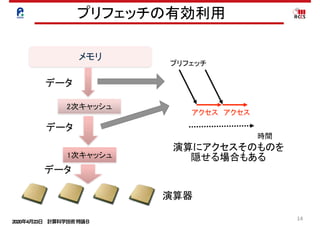
Retty recommendation project
PDF
PPTX
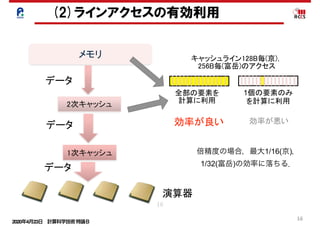
クラシックな機械学習の入門 5. サポートベクターマシン
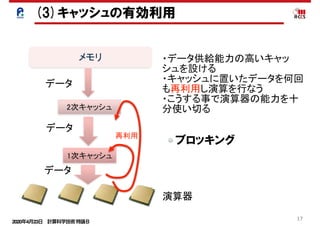
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
PDF
PDF
東京都市大学 データ解析入門 5 スパース性と圧縮センシング 2
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
PDF
ICLR2020読み会 Stable Rank Normalization
PDF
PDF
第11回 配信講義 計算科学技術特論B(2022)
PPTX
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
PDF
PDF
東京都市大学 データ解析入門 8 クラスタリングと分類分析 1
PDF
IPAB2017 深層学習を使った新薬の探索から創造へ
PPTX
[DL Hacks] Learning Transferable Features with Deep Adaptation Networks
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
PDF
PDF
【CVPR 2019】Do Better ImageNet Models Transfer Better?
PDF
PDF
PDF
CMSI計算科学技術特論B(3) アプリケーションの性能最適化2
More Related Content
PDF
Overcoming Catastrophic Forgetting in Neural Networks読んだ
PDF
PDF
PDF
PDF
SSII2014 詳細画像識別 (FGVC) @OS2
PDF
PDF
PDF
第14回 配信講義 計算科学技術特論B(2022)
What's hot
PDF
PDF
Retty recommendation project
PDF
PPTX
クラシックな機械学習の入門 5. サポートベクターマシン
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
PDF
PDF
東京都市大学 データ解析入門 5 スパース性と圧縮センシング 2
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
PDF
ICLR2020読み会 Stable Rank Normalization
PDF
PDF
第11回 配信講義 計算科学技術特論B(2022)
PPTX
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
PDF
PDF
東京都市大学 データ解析入門 8 クラスタリングと分類分析 1
PDF
IPAB2017 深層学習を使った新薬の探索から創造へ
PPTX
[DL Hacks] Learning Transferable Features with Deep Adaptation Networks
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
PDF
PDF
【CVPR 2019】Do Better ImageNet Models Transfer Better?
PDF
Similar to アプリケーションの性能最適化2(CPU単体性能最適化)
PDF
PDF
CMSI計算科学技術特論B(3) アプリケーションの性能最適化2
PDF
第1回 配信講義 計算科学技術特論A (2021)
PDF
PDF
El text.tokuron a(2019).katagiri
PDF
PDF
PDF
PDF
PPTX
20200709 fjt7tdmi-blog-appendix
PDF
第4回 配信講義 計算科学技術特論A (2021)
PDF
CMSI計算科学技術特論A(9) 高速化チューニングとその関連技術2
PDF
ACRi_webinar_20220118_miyo
PDF
計算機アーキテクチャを考慮した高能率画像処理プログラミング
PDF
非静力学海洋モデルkinacoのGPUによる高速化
PDF
2015年度先端GPGPUシミュレーション工学特論 第6回 プログラムの性能評価指針�(Flop/Byte,計算律速,メモリ律速)
PDF
Intel TSX HLE を触ってみた x86opti
PDF
PPTX
PDF
El text.tokuron a(2019).katagiri190509
More from RCCSRENKEI
PDF
第15回 配信講義 計算科学技術特論B(2022)
PDF
第12回 配信講義 計算科学技術特論B(2022)
PDF
第13回 配信講義 計算科学技術特論B(2022)
PDF
第10回 配信講義 計算科学技術特論B(2022)
PDF
PPT
PPT
PPTX
Realization of Innovative Light Energy Conversion Materials utilizing the Sup...
PDF
Current status of the project "Toward a unified view of the universe: from la...
PPTX
Fugaku, the Successes and the Lessons Learned
PDF
PDF
PDF
PDF
第15回 配信講義 計算科学技術特論A(2021)
PDF
第14回 配信講義 計算科学技術特論A(2021)
PDF
第12回 配信講義 計算科学技術特論A(2021)
PDF
第13回 配信講義 計算科学技術特論A(2021)
PDF
第11回 配信講義 計算科学技術特論A(2021)
PDF
第10回 配信講義 計算科学技術特論A(2021)
PDF
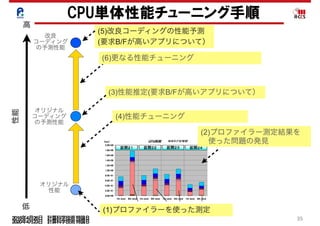
アプリケーションの性能最適化2(CPU単体性能最適化) 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 2020年4月23日 計算科学技術特論B
22
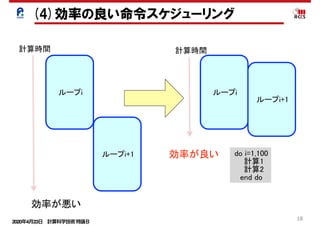
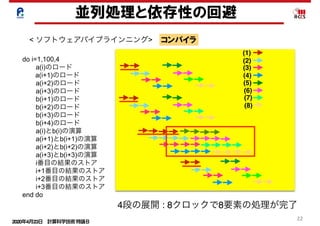
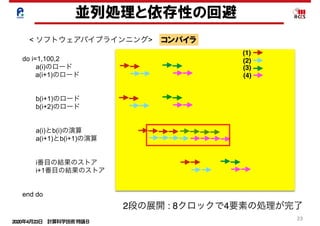
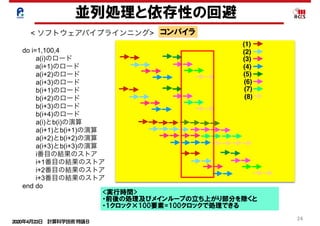
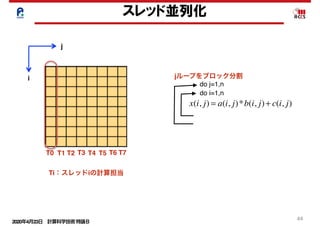
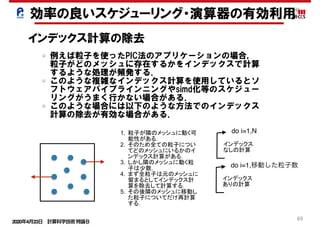
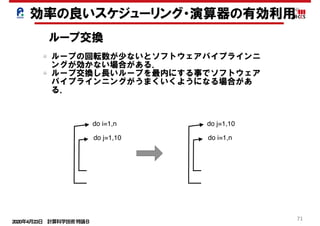
並列処理と依存性の回避
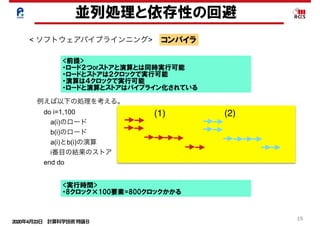
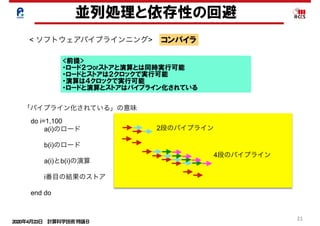
< ソフトウェアパイプラインニング> コンパイラ
do i=1,100,4
a(i)のロード
a(i+1)のロード
a(i+2)のロード
a(i+3)のロード
b(i+1)のロード
b(i+2)のロード
b(i+3)のロード
b(i+4)のロード
a(i)とb(i)の演算
a(i+1)とb(i+1)の演算
a(i+2)とb(i+2)の演算
a(i+3)とb(i+3)の演算
i番目の結果のストア
i+1番目の結果のストア
i+2番目の結果のストア
i+3番目の結果のストア
end do
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
4段の展開 : 8クロックで8要素の処理が完了
23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 2020年4月23日 計算科学技術特論B
36
ルーフラインモデル
mine sustainable DRAM bandwidth.
They include all techniques to get the
best memory performance, including
them to include memory optimiza-
tions of a computer into our bound-
and-bottleneck model. Second, we
l
n
-
d
n
-
y
e
-
-
h
”
-
t
e
n
e
d
-
s
n
e
m
-
p
e
-
Figure 1: Roofline model for (a) AMD Opteron X2 and (b) Opteron X2 vs. Opteron X4.
(a)
peak memory bandwidth (stream) peak floating-point performance
Operational Intensity (Flops/Byte)
OperationalIntensity1
(memory-bound)
OperationalIntensity2
(compute-bound)
AttainableGFlops/sec
128
64
32
16
8
4
2
1
1/2
1/4 1/2 1 2 4 8 16
(b)
Opteron X4
Opteron X2
AttainableGFlops/s
128
64
32
16
8
4
2
1
1/2
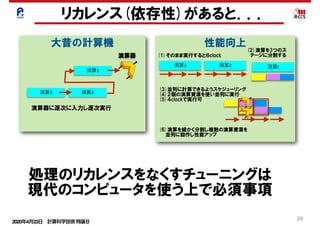
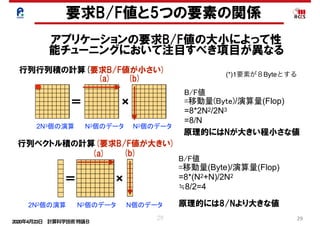
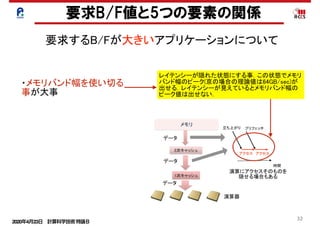
• ハードウェアの実効的なメモリバンド幅:B
• ハードウェアのピーク性能:F
• アプリケーションの演算強度:X=f/b
• アプリケーションの要求フロップス値:f
• アプリケーションの要求バイト値:b
B*X=B*(f/b)=B*F*f/(b*F)=(B/F)/(b/f)*F
アプリケーションのピーク性能比 :min(1.0 , (B/F)/(b/f) )
S. Williams, A. Waterman, and D. Patterson: Roofline: an
insightful visual performance model for multicore architectures.
Commun. ACM, 52:65–76, 2009.
アプリケーションの性能:
min(F,B*X)
ハードウェアのB/F値をアプリ
ケーションのb/f値で割る.
37. 2020年4月23日 計算科学技術特論B
37
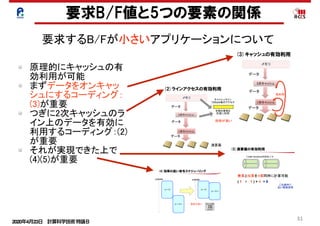
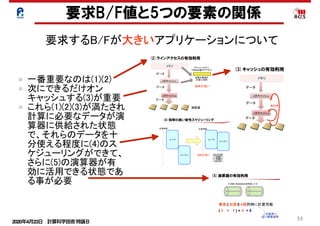
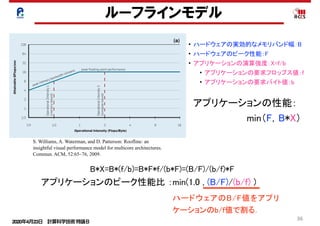
ルーフラインモデルの別の見方
(1)メモリ
• メモリデータ転送量:Mdata
• 実効メモリバンド幅:Mband,
• メモリデータ移動時間:Mtime
(2)演算
• プログラム演算量:Ca
• 演算ピーク性能:Ppeak
• 最小演算時間:Ctime
Mdata
Mband
演算器の処理とメモリのデータ
の処理が同時に終わるモデル
Mtime=Mdata/Mband
Ctime=Ca/Ppeak
A+
BSPbP% B P]SO_TP % A+SPbP A+ P]SO_TP 9P
E_TP y s
ww BbX T A+ s
ww A+bX T 9bX T t
y
Mtime=Mdata/Mband_peak
L2time=L2data/L2band_peak
Ctime=Ca/Ppeak
× * × + × ,
BbX T A+bX T 9bX T
fObX T 9_
Ex_time=max(Mtime,L2time,Ctime)
Cp= Ca/(max(Mtime,L2time,Ctime)*Ppeak)
(3)実行時間 : Ex_time
38. 39. 2020年4月23日 計算科学技術特論B
39
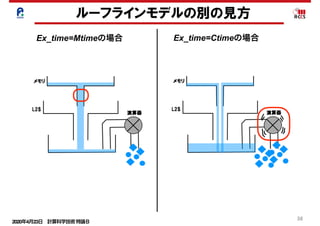
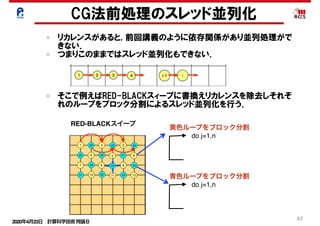
メモリとキャッシュ混合状態での性能予測モデル
s s
A+
A+
A+
BSPbP% B P]SO_TP % A+SPbP A+ P]SO_TP 9P
E_TP y s
ww BbX T A+ s
ww A+bX T 9bX T t
y
Mtime=Mdata/Mband_peak
L2time=L2data/L2band_peak
Ctime=Ca/Ppeak
× * × + × ,
BbX T A+bX T 9bX T
fObX T 9_
Ex_time=max(Mtime,L2time,Ctime)
Cp= Ca/(max(Mtime,L2time,Ctime)*Ppeak)
BbX T6A+bX T r x A+ x u z r
Ex_time=L2timeの場合
L2dataMband
L2band
(1)メモリ
• メモリデータ転送量:Mdata
• 実効メモリバンド幅:Mband
• メモリデータ移動時間:Mtime
(2)L2キャッシュ
• L2データ転送量:L2data
• 実効L2バンド幅:L2band
• L2データ移動時間:L2time
(3)演算
• プログラム演算量:Ca
• 演算ピーク性能:Ppeak
• 最小演算時間:Ctime
「キャッシュの効果を考慮したルーフラインモデルの
拡張によるプログラムの性能予測」南一生他,情報処理学会論文誌
コンピューティングシステム,第9巻,第2号,1-14(2016年6月)
Mtime=Mdata/Mband
Ctime=Ca/Ppeak
L2time=L2data/L2band
(4)実行時間 : Ex_time
40. 41. 2020年4月23日 計算科学技術特論B
41
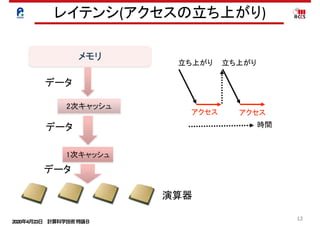
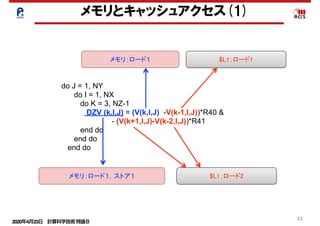
メモリとキャッシュアクセス(1)
do J = 1, NY
do I = 1, NX
do K = 3, NZ-1
DZV (k,I,J) = (V(k,I,J) -V(k-1,I,J))*R40 &
- (V(k+1,I,J)-V(k-2,I,J))*R41
end do
end do
end do
メモリ:ロード1,ストア1
メモリ:ロード1
$L1:ロード2
$L1:ロード1
42. 2020年4月23日 計算科学技術特論B
42
do J = 1, NY
do I = 1, NX
do K = 3, NZ-1
DZV (k,I,J) = (V(k,I,J) -V(k-1,I,J))*R40 &
- (V(k+1,I,J)-V(k-2,I,J))*R41
end do
end do
end do
ルーフラインモデルによる性能見積り
n 最内軸(K軸)が差分
n 1ストリームでその他の3配列は$L1に載っ
ており再利⽤できる。
要求flop:
add : 3 mult : 2 = 5
要求B/F 12/5 = 2.4
性能予測 0.36/2.4 = 0.15
実測値 0.153
要求Byteの算出:
1store,2loadと考える
4x3 = 12byte
アプリケーションのピーク性能比の予測値
: ハードウェアのBF値(実効値)/アプリの要求BF値
43. 44. 45. 46. 47. 48. 2020年4月23日 計算科学技術特論B
48
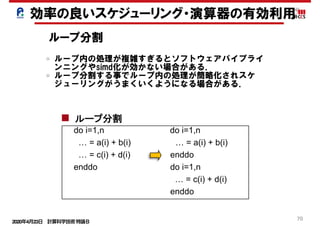
ロード・ストアの効率化
演算とロード・ストア比の改善 < 内側ループアンローリング>
• 以下の様な2 つのコーディングを比較する。
do j=1,m
do i=1,n
x(i)=x(i)+a(i)*b+a(i+1)*d
end do
end do
do j=1,m
do i=1,n,2
x(i)=x(i)+a(i)*b+a(i+1)*d
x(i+1)=x(i+1)+a(i+1)*b+a(i+2)*d
end do
end do
• 最初のコーディングの演算量は4 ,ロード/ストア回数は4 である.2 つ目のコ ーディン
グの演算量は8 ,ロード/ストア回数は7 である.
• 最初のコーディングの演算とロード/ ストアの比は4/4,2つ目のコーディングの演算と
ロード/ストアの比は8/7となり良くなる.
本例は教科書的なもので、キャッシュ
の考慮、コンパイラの処理の考慮、レ
ジスタ数の考慮により一概に効果があ
るものではない。
同じもの
49. 50. 2020年4月23日 計算科学技術特論B
50
ロード・ストアの効率化
演算とロード・ストア比の改善
• この場合a(j,is)・・a(j,is+9)とx(j)の
11個をロードする.さらにy(is)等は
レジスタに保持する.
• その間を20個の演算を実施する.
• したがって演算とロード/ストアの比
は20/11となり改善する.
本例は教科書的なものであり、キャッ
シュの考慮、コンパイラの処理の考
慮、レジスタ数の考慮により最適な
コーディングが必要になる。
• 以下のようなコーディングを外側ループストリップマインニングという.
do is=1,m,10
do j=1,n
do i=is,min(is+9,m)
y(i)=y(i)+a(j,i)*x(j)
end do
end do
end do
do is=1,m,10
do j=1,m
y(is)=y(is)+a(j,is)*x(j)
y(is+1)=y(is+1)+a(j,is+1)*x(j)
・・・・
y(is+9)=y(is+9)+a(j,is+9)*x(j)
end do
end do
• このコーディングの最内ループをアンローリングする.
51. 52. 2020年4月23日 計算科学技術特論B
52
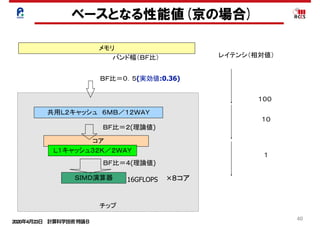
Cache
改善前 0.01% 42.62% 2.13E+08 97.24% 2.76% 0.00% 6.67% 3.34E+07
改善後 0.01% 24.37% 2.19E+08 37.55% 5.69% 56.76% 5.82% 5.24E+07
L1D ミス数
L1D ミス dm率
(/L1D ミス数)
L1D ミス hwpf 率
(/L1D ミス数)
L1D ミス率
(/ロード・ストア命令数)
L1I ミス率
(/有効総命令数)
L1D ミス swpf 率
(/L1D ミス数)
L2 ミス数
L2 ミス率
(/ロード・ストア命令数)
改善後ソース(最適化制御行チューニング)
51 !ocl prefetch
<<< Loop-information Start >>>
<<< [PARALLELIZATION]
<<< Standard iteration count: 616
<<< [OPTIMIZATION]
<<< SIMD
<<< SOFTWARE PIPELINING
<<< PREFETCH : 32
<<< c: 16, b: 16
<<< Loop-information End >>>
52 1 pp 2v do i = 1 , n
53 1 p 2v a(i) = b(d(i)) + scalar * c(e(i))
54 1 p 2v enddo
prefetch指示子を指定することでインダイレクトアクセス(リストアクセス)
します。その結果、データアクセス待ちコストが改善されました。
インダイレクトアクセスプリフェッチの効果
(最適化制御行チューニング)
浮動小
数点ロー
ドキャッ
シュアク
セス待ち
0.0E+00
5.0E-02
1.0E-01
1.5E-01
2.0E-01
2.5E-01
3.0E-01
3.5E-01
4.0E-01
改善前
[秒]
インダイレクトアクセス(配列
b, c)に対するプリフェッチが
生成された
ロード・ストアの効率化
プリフェッチの有効利用
ユーザーがコンパイラオプションやディレクティブで挿入する事もできる.
以下ディレクティブによるソフトウェアプリフェッチ生成の例.
R-CCSチューニングチュートリアルより
53. 2020年4月23日 計算科学技術特論B
53
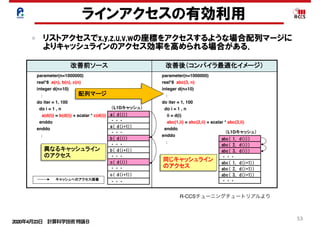
ラインアクセスの有効利用
リストアクセスでx,y,z,u,v,wの座標をアクセスするような場合配列マージに
よりキャッシュラインのアクセス効率を高められる場合がある.
103
配列マージとは
配列マージとは、同一ループ内でアクセスパターンが共通の配列が複数ある
場合、1個の配列に融合することです。データアクセスを連続化して、キャッ
シュ効率を向上させます。
改善前ソース 改善後(コンパイラ最適化イメージ)
parameter(n=1000000)
real*8 a(n), b(n), c(n)
integer d(n+10)
:
do iter = 1, 100
do i = 1 , n
a(d(i)) = b(d(i)) + scalar * c(d(i))
enddo
enddo
:
parameter(n=1000000)
real*8 abc(3, n)
integer d(n+10)
:
do iter = 1, 100
do i = 1 , n
ii = d(i)
abc(1,ii) = abc(2,ii) + scalar * abc(3,ii)
enddo
enddo
:
abc( 1, d(i))
abc( 2, d(i))
abc( 3, d(i))
・・・
abc( 1, d(i+1))
abc( 2, d(i+1))
abc( 3, d(i+1))
・・・
b( d(i))
・・・
c( d(i+1))
・・・
・・・
a( d(i))
・・・
a( d(i+1))
・・・
b( d(i+1))
・・・
c( d(i))
配列マージ
異なるキャッシュライン
のアクセス
同じキャッシュライン
のアクセス
(L1Dキャッシュ)
(L1Dキャッシュ)
キャッシュへのアクセス順番
Copyright 2012 RIKEN AICS
R-CCSチューニングチュートリアルより
54. 2020年4月23日 計算科学技術特論B
54
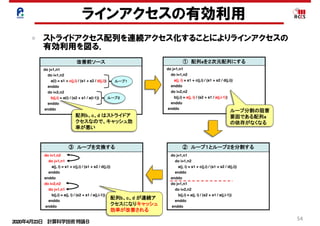
ラインアクセスの有効利用
ストライドアクセス配列を連続アクセス化することによりラインアクセスの
有効利用を図る.
97
ループ交換のチューニング内容
改善前ソース
do j=1,n1
do i=1,n2
a(i) = s1 + c(j,i) / (s1 + s2 / d(j,i))
enddo
do i=2,n2
b(j,i) = a(i) / (s2 + s1 / a(i-1))
enddo
enddo
① 配列aを2次元配列にする
do j=1,n1
do i=1,n2
a(j, i) = s1 + c(j,i) / (s1 + s2 / d(j,i))
enddo
do i=2,n2
b(j,i) = a(j, i) / (s2 + s1 / a(j,i-1))
enddo
enddo
② ループ1とループ2を分割する
do j=1,n1
do i=1,n2
a(j, i) = s1 + c(j,i) / (s1 + s2 / d(j,i))
enddo
enddo
do j=1,n1
do i=2,n2
b(j,i) = a(j, i) / (s2 + s1 / a(j,i-1))
enddo
enddo
ループ1
ループ2
③ ループを交換する
do i=1,n2
do j=1,n1
a(j, i) = s1 + c(j,i) / (s1 + s2 / d(j,i))
enddo
enddo
do i=2,n2
do j=1,n1
b(j,i) = a(j, i) / (s2 + s1 / a(j,i-1))
enddo
enddo
配列b、c、d はストライドア
クセスなので、キャッシュ効
率が悪い
配列b、c、d が連続ア
クセスになりキャッシュ
効率が改善される
ループ分割の阻害
要因である配列a
の依存がなくなる
Copyright 2012 RIKEN AICS
55. 56. 57. 58. 59. 60. 61. 2020年4月23日 計算科学技術特論B
61
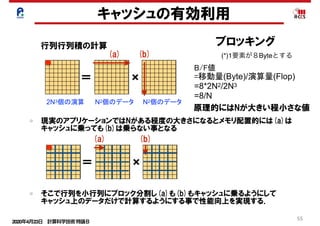
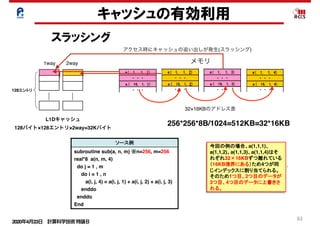
キャッシュの有効利用
スラッシング
キャッシュスラッシングとは
ソース例
subroutine sub(a, n, m) ※n=256, m=256
real*8 a(n, m, 4)
do j = 1 , m
do i = 1 , n
a(i, j, 4) = a(i, j, 1) + a(i, j, 2) + a(i, j, 3)
enddo
enddo
End
キャッシュスラッシングとは、キャッシュ上の特定のインデックス(キャッシュ上の
情報)のデータだけが頻繁に上書きされる現象のことです。この現象は、配列サ
が2のべき乗の場合およびループ内のストリーム数が多い場合に発生しやすく
す。 注:ストリームとは、ループの回転に伴って参照定義される一連のデータの
今回の例の場合、a(1,1,1)、
a(1,1,2)、a(1,1,3)、a(1,1,4)はそ
キャッシュへの格納
キャッシュへの格納(競合)
実行
(L1Dキャッシュ) (メモリ上のデー
a( 1, 1,
・ ・ ・
a ( 16, 1
・ ・ ・
a( 1, 1,
・ ・ ・
a ( 16, 1
・ ・ ・
a( 1, 1,
・ ・ ・
1WAY
128エントリ
2WAY
L1Dキャッシュスラッシングの目安
24
スラッシングとは
※n=256, m=256
(i, j, 2) + a(i, j, 3)
ングとは、キャッシュ上の特定のインデックス(キャッシュ上の位置
が頻繁に上書きされる現象のことです。この現象は、配列サイズ
合およびループ内のストリーム数が多い場合に発生しやすくなりま
注:ストリームとは、ループの回転に伴って参照定義される一連のデータのことです。
今回の例の場合、a(1,1,1)、
a(1,1,2)、a(1,1,3)、a(1,1,4)はそ
れぞれ32×16KBずつ離れている
(16KB境界にある)ため4つが同
じインデックスに割り当てられる。
そのため1つ目、2つ目のデータが
3つ目、4つ目のデータに上書きさ
れる。
キャッシュへの格納
キャッシュへの格納(競合)
実行順序①~④
(L1Dキャッシュ) (メモリ上のデータ配置)
a( 1, 1, 1)
・ ・ ・
a ( 16, 1, 1)
・ ・ ・
a( 1, 1, 2)
・ ・ ・
a ( 16, 1, 2)
・ ・ ・
a( 1, 1, 3)
・ ・ ・
a ( 16, 1, 3)
・ ・ ・
a( 1, 1, 4)
・ ・ ・
a ( 16, 1, 4)
・ ・ ・
実行順序
④
①
②
③
1WAY
128エントリ
2WAY
ッシングの目安
L1D ミス dm率
(/L1D ミス数)
20%以上
2回に1回ミスをする)
6回に1回ミスをする)
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
24
ソース例
broutine sub(a, n, m) ※n=256, m=256
al*8 a(n, m, 4)
o j = 1 , m
do i = 1 , n
a(i, j, 4) = a(i, j, 1) + a(i, j, 2) + a(i, j, 3)
enddo
nddo
nd
情報)のデータだけが頻繁に上書きされる現象のことです。この現象は、配列サイズ
が2のべき乗の場合およびループ内のストリーム数が多い場合に発生しやすくなりま
す。 注:ストリームとは、ループの回転に伴って参照定義される一連のデータのことです。
今回の例の場合、a(1,1,1)、
a(1,1,2)、a(1,1,3)、a(1,1,4)はそ
れぞれ32×16KBずつ離れている
(16KB境界にある)ため4つが同
じインデックスに割り当てられる。
そのため1つ目、2つ目のデータが
3つ目、4つ目のデータに上書きさ
れる。
キャッシュへの格納
キャッシュへの格納(競合)
実行順序①~④
(L1Dキャッシュ) (メモリ上のデータ配置)
a( 1, 1, 1)
・ ・ ・
a ( 16, 1, 1)
・ ・ ・
a( 1, 1, 2)
・ ・ ・
a ( 16, 1, 2)
・ ・ ・
a( 1, 1, 3)
・ ・ ・
a ( 16, 1, 3)
・ ・ ・
a( 1, 1, 4)
・ ・ ・
a ( 16, 1, 4)
・ ・ ・
実行順序
④
①
②
③
1WAY
128エントリ
2WAY
L1Dキャッシュスラッシングの目安
L1D ミス率
(/ロード・ストア数)
L1D ミス dm率
(/L1D ミス数)
単精度 3.125%以上
倍精度 6.250%以上
20%以上
単精度:1/32(32回に1回ミスをする)
倍精度:1/16(16回に1回ミスをする)
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
ht 2012 RIKEN AICS
24
ソース例
subroutine sub(a, n, m) ※n=256, m=256
real*8 a(n, m, 4)
do j = 1 , m
do i = 1 , n
a(i, j, 4) = a(i, j, 1) + a(i, j, 2) + a(i, j, 3)
enddo
enddo
End
今回の例の場合、a(1,1,1)、
a(1,1,2)、a(1,1,3)、a(1,1,4)はそ
れぞれ32×16KBずつ離れている
(16KB境界にある)ため4つが同
じインデックスに割り当てられる。
そのため1つ目、2つ目のデータが
3つ目、4つ目のデータに上書きさ
れる。
キャッシュへの格納
キャッシュへの格納(競合)
実行順序①~④
(L1Dキャッシュ) (メモリ上のデータ配置)
a( 1, 1, 1)
・ ・ ・
a ( 16, 1, 1)
・ ・ ・
a( 1, 1, 2)
・ ・ ・
a ( 16, 1, 2)
・ ・ ・
a( 1, 1, 3)
・ ・ ・
a ( 16, 1, 3)
・ ・ ・
a( 1, 1, 4)
・ ・ ・
a ( 16, 1, 4)
・ ・ ・
実行順序
④
①
②
③
1WAY
128エントリ
2WAY
L1Dキャッシュスラッシングの目安
L1D ミス率
(/ロード・ストア数)
L1D ミス dm率
(/L1D ミス数)
単精度 3.125%以上
倍精度 6.250%以上
20%以上
単精度:1/32(32回に1回ミスをする)
倍精度:1/16(16回に1回ミスをする)
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
Copyright 2012 RIKEN AICS
24
subroutine sub(a, n, m) ※n=256, m=256
real*8 a(n, m, 4)
do j = 1 , m
do i = 1 , n
a(i, j, 4) = a(i, j, 1) + a(i, j, 2) + a(i, j, 3)
enddo
enddo
End
今回の例の場合、a(1,1,1)、
a(1,1,2)、a(1,1,3)、a(1,1,4)はそ
れぞれ32×16KBずつ離れている
(16KB境界にある)ため4つが同
じインデックスに割り当てられる。
そのため1つ目、2つ目のデータが
3つ目、4つ目のデータに上書きさ
れる。
a( 1, 1, 1)
・ ・ ・
a ( 16, 1, 1)
・ ・ ・
a( 1, 1, 2)
・ ・ ・
a ( 16, 1, 2)
・ ・ ・
a( 1, 1, 3)
・ ・ ・
a ( 16, 1, 3)
・ ・ ・
a( 1, 1, 4)
・ ・ ・
a ( 16, 1, 4)
・ ・ ・
④
①
②
③
1WAY
128エントリ
2WAY
L1Dキャッシュスラッシングの目安
L1D ミス率
(/ロード・ストア数)
L1D ミス dm率
(/L1D ミス数)
単精度 3.125%以上
倍精度 6.250%以上
20%以上
単精度:1/32(32回に1回ミスをする)
倍精度:1/16(16回に1回ミスをする)
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
Copyright 2012 RIKEN AICS
24
3)
キャッシュ上の特定のインデックス(キャッシュ上の位置
上書きされる現象のことです。この現象は、配列サイズ
ープ内のストリーム数が多い場合に発生しやすくなりま
注:ストリームとは、ループの回転に伴って参照定義される一連のデータのことです。
今回の例の場合、a(1,1,1)、
a(1,1,2)、a(1,1,3)、a(1,1,4)はそ
れぞれ32×16KBずつ離れている
(16KB境界にある)ため4つが同
じインデックスに割り当てられる。
そのため1つ目、2つ目のデータが
3つ目、4つ目のデータに上書きさ
れる。
キャッシュへの格納
キャッシュへの格納(競合)
実行順序①~④
(L1Dキャッシュ) (メモリ上のデータ配置)
a( 1, 1, 1)
・ ・ ・
a ( 16, 1, 1)
・ ・ ・
a( 1, 1, 2)
・ ・ ・
a ( 16, 1, 2)
・ ・ ・
a( 1, 1, 3)
・ ・ ・
a ( 16, 1, 3)
・ ・ ・
a( 1, 1, 4)
・ ・ ・
a ( 16, 1, 4)
・ ・ ・
実行順序
④
①
②
③
1WAY
128エントリ
2WAY
目安
m率
数)
する)
する)
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
24
=256, m=256
j, 2) + a(i, j, 3)
グとは、キャッシュ上の特定のインデックス(キャッシュ上の位置
が頻繁に上書きされる現象のことです。この現象は、配列サイズ
およびループ内のストリーム数が多い場合に発生しやすくなりま
注:ストリームとは、ループの回転に伴って参照定義される一連のデータのことです。
今回の例の場合、a(1,1,1)、
a(1,1,2)、a(1,1,3)、a(1,1,4)はそ
れぞれ32×16KBずつ離れている
(16KB境界にある)ため4つが同
じインデックスに割り当てられる。
そのため1つ目、2つ目のデータが
3つ目、4つ目のデータに上書きさ
れる。
キャッシュへの格納
キャッシュへの格納(競合)
実行順序①~④
(L1Dキャッシュ) (メモリ上のデータ配置)
a( 1, 1, 1)
・ ・ ・
a ( 16, 1, 1)
・ ・ ・
a( 1, 1, 2)
・ ・ ・
a ( 16, 1, 2)
・ ・ ・
a( 1, 1, 3)
・ ・ ・
a ( 16, 1, 3)
・ ・ ・
a( 1, 1, 4)
・ ・ ・
a ( 16, 1, 4)
・ ・ ・
実行順序
④
①
②
③
1WAY
128エントリ
2WAY
シングの目安
L1D ミス dm率
(/L1D ミス数)
20%以上
回に1回ミスをする)
回に1回ミスをする)
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
1way 2way
L1Dキャッシュ
128バイト×128エントリ×2way=32Kバイト
24
キャッシュスラッシングとは
ソース例
subroutine sub(a, n, m) ※n=256, m=256
real*8 a(n, m, 4)
do j = 1 , m
do i = 1 , n
a(i, j, 4) = a(i, j, 1) + a(i, j, 2) + a(i, j, 3)
enddo
enddo
End
キャッシュスラッシングとは、キャッシュ上の特定のインデックス(キャッシ
情報)のデータだけが頻繁に上書きされる現象のことです。この現象は、
が2のべき乗の場合およびループ内のストリーム数が多い場合に発生し
す。 注:ストリームとは、ループの回転に伴って参照定義される一連の
今回の例の場合、a(1,1,1)、
a(1,1,2)、a(1,1,3)、a(1,1,4)はそ
れぞれ32×16KBずつ離れている
(16KB境界にある)ため4つが同
じインデックスに割り当てられる。
そのため1つ目、2つ目のデータが
3つ目、4つ目のデータに上書きさ
れる。
キャッシュへの格納
キャッシュへの格納(競合)
(L1Dキャッシュ) (メモリ
a(
a
a(
a
a(
a
a(
a
1WAY
128エントリ
2WAY
L1Dキャッシュスラッシングの目安
L1D ミス率
(/ロード・ストア数)
L1D ミス dm率
(/L1D ミス数)
単精度 3.125%以上
倍精度 6.250%以上
20%以上
単精度:1/32(32回に1回ミスをする)
倍精度:1/16(16回に1回ミスをする)
Copyright 2012 RIKEN AICS
メモリ
アクセス時にキャッシュの追い出しが発生(スラッシング)
32×16KBのアドレス差
256*256*8B/1024=512KB=32*16KB
62. 2020年4月23日 計算科学技術特論B
62
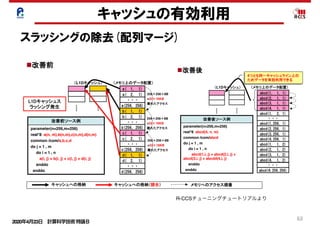
キャッシュの有効利用
スラッシングの除去(配列マージ)
28
改善前ソース例
parameter(n=256,m=256)
real*8 a(n, m),b(n,m),c(n,m),d(n,m)
common /com/a,b,c,d
do j = 1 , m
do i = 1 , n
a(i, j) = b(i, j) + c(i, j) + d(i, j)
enddo
enddo
配列マージとは、複数の配列を1つの配列とするチューニングです。
使用条件
配列の要素数が同じである。
a( 1, 1)
a( 2, 1)
・・・
a(256, 256)
b( 1, 1)
b( 2, 1)
・・・
(L1Dキャッシュ) (メモリ上のデータ配置)
b(256, 256)
c( 1, 1)
c( 2, 1)
・・・
c(256, 256)
d( 1, 1)
d( 2, 1)
・・・
d(256, 256)
改善後ソース例
parameter(n=256,m=256)
real*8 abcd(4, n, m)
common /com/abcd
do j = 1 , m
do i = 1 , n
abcd(1,i, j) = abcd(2,i, j) +
abcd(3,i, j) + abcdd(4,i, j)
enddo
enddo
改善前 改善後
L1Dキャッシュス
ラッシング発生
狙い
ストリーム数削減。
副作用
ロード、ストア命令のSIMD化が難しくなる。
abcd(1, 1, 1)
abcd(2, 1, 1)
・・・
abcd(1,256, 1)
(L1Dキャッシュ) (メモリ上のデータ配置)
・・・
abcd(3, 1, 1)
abcd(4, 1, 1)
abcd(2,256, 1)
abcd(3,256, 1)
abcd(4,256, 1)
abcd(1, 1, 2)
abcd(2, 1, 2)
abcd(3, 1, 2)
abcd(4, 1, 2)
abcd(1, 2, 1)
abcd(4,256,256)
キャッシュへの格納 キャッシュへの格納(競合) メモリへのアクセス順番
4つとも同一キャッシュライン上の
ためデータを有効利用できる
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
Copyright 2012 RIKEN AICS
28
配列マージとは
改善前ソース例
parameter(n=256,m=256)
real*8 a(n, m),b(n,m),c(n,m),d(n,m)
common /com/a,b,c,d
do j = 1 , m
do i = 1 , n
a(i, j) = b(i, j) + c(i, j) + d(i, j)
enddo
enddo
配列マージとは、複数の配列を1つの配列とするチューニングです。
使用条件
配列の要素数が同じである。
a( 1, 1)
a( 2, 1)
・・・
a(256, 256)
b( 1, 1)
b( 2, 1)
・・・
(L1Dキャッシュ) (メモリ上のデータ配置)
b(256, 256)
c( 1, 1)
c( 2, 1)
・・・
c(256, 256)
d( 1, 1)
d( 2, 1)
・・・
d(256, 256)
改善後ソース例
parameter(n=256,m=256)
real*8 abcd(4, n, m)
common /com/abcd
do j = 1 , m
do i = 1 , n
abcd(1,i, j) = abcd(2,i, j) +
abcd(3,i, j) + abcdd(4,i, j)
enddo
enddo
改善前 改善後
L1Dキャッシュス
ラッシング発生
狙い
ストリーム数削減。
副作用
ロード、ストア命令のSIMD化が難しくなる。
abcd(1, 1, 1)
abcd(2, 1, 1)
・・・
abcd(1,256, 1)
(L1Dキャッシュ) (メモリ上のデータ配置)
・・・
abcd(3, 1, 1)
abcd(4, 1, 1)
abcd(2,256, 1)
abcd(3,256, 1)
abcd(4,256, 1)
abcd(1, 1, 2)
abcd(2, 1, 2)
abcd(3, 1, 2)
abcd(4, 1, 2)
abcd(1, 2, 1)
abcd(4,256,256)
キャッシュへの格納 キャッシュへの格納(競合) メモリへのアクセス順番
4つとも同一キャッシュライン上の
ためデータを有効利用できる
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
Copyright 2012 RIKEN AICS
28
改善前ソース例
parameter(n=256,m=256)
real*8 a(n, m),b(n,m),c(n,m),d(n,m)
common /com/a,b,c,d
do j = 1 , m
do i = 1 , n
a(i, j) = b(i, j) + c(i, j) + d(i, j)
enddo
enddo
配列マージとは、複数の配列を1つの配列とするチューニングです。
使用条件
配列の要素数が同じである。
a( 1, 1)
a( 2, 1)
・・・
a(256, 256)
b( 1, 1)
b( 2, 1)
・・・
(L1Dキャッシュ) (メモリ上のデータ配置)
b(256, 256)
c( 1, 1)
c( 2, 1)
・・・
c(256, 256)
d( 1, 1)
d( 2, 1)
・・・
d(256, 256)
改善後ソース例
parameter(n=256,m=256)
real*8 abcd(4, n, m)
common /com/abcd
do j = 1 , m
do i = 1 , n
abcd(1,i, j) = abcd(2,i, j) +
abcd(3,i, j) + abcdd(4,i, j)
enddo
enddo
改善前 改善後
L1Dキャッシュス
ラッシング発生
狙い
ストリーム数削減。
副作用
ロード、ストア命令のSIMD化が難しくなる。
abcd(1, 1, 1)
abcd(2, 1, 1)
・・・
abcd(1,256, 1)
(L1Dキャッシュ) (メモリ上のデータ配置)
・・・
abcd(3, 1, 1)
abcd(4, 1, 1)
abcd(2,256, 1)
abcd(3,256, 1)
abcd(4,256, 1)
abcd(1, 1, 2)
abcd(2, 1, 2)
abcd(3, 1, 2)
abcd(4, 1, 2)
abcd(1, 2, 1)
abcd(4,256,256)
キャッシュへの格納 キャッシュへの格納(競合) メモリへのアクセス順番
4つとも同一キャッシュライン上の
ためデータを有効利用できる
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
Copyright 2012 RIKEN AICS
R-CCSチューニングチュートリアルより
63. 2020年4月23日 計算科学技術特論B
63
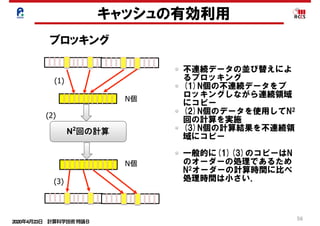
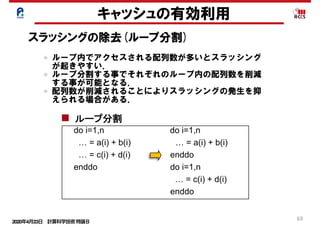
キャッシュの有効利用
スラッシングの除去(ループ分割)
do i=1,n do i=1,n
… = a(i) + b(i) … = z(1,i) + z(2,i)
enddo enddo
ストリ
リスク
do i=1,n do i=1,n
… = a(I,1) + a(I,2) … = a(1,i) + a(2,i)
enddo enddo
do i=1,n do i=1,n
… = a(i) + b(i) … = a(i) + b(i)
… = c(i) + d(i) enddo
enddo do i=1,n
… = c(i) + d(i)
enddo
common //a(n),b(n) common //a(n),p(64),b(n)
配列マージ
配列次元移動
ループ分割
パディング
ループ内でアクセスされる配列数が多いとスラッシング
が起きやすい.
ループ分割する事でそれぞれのループ内の配列数を削減
する事が可能となる.
配列数が削減されることによりスラッシングの発生を抑
えられる場合がある.
64. 2020年4月23日 計算科学技術特論B
64
キャッシュの有効利用
スラッシングの除去(パディング)
26
enddo enddo
リスクそのものを改善する解決型のアプロー
長所:パラメタ変更等、問題規模の変化に
順応できる
do i=1,n do i=1,n
… = a(I,1) + a(I,2) … = a(1,i) + a(2,i)
enddo enddo
do i=1,n do i=1,n
… = a(i) + b(i) … = a(i) + b(i)
… = c(i) + d(i) enddo
enddo do i=1,n
… = c(i) + d(i)
enddo
common //a(n),b(n) common //a(n),p(64),b(n)
do i=1,n do i=1,n
… = a(i) + b(i) … = a(i) + b(i)
enddo enddo
パディングを行うことで、配列のアドレスを
ずらして改善する回避型のアプローチ
短所:修正量が多い。SIMD化が複雑
注意:ループ分割は除
長所:修正量が少ない、SIMD化が容易
短所:パラメタ変更等、問題規模が変化す
度に調整が必要になる
配列次元移動
ループ分割
パディング
Copyright 2012 RIKEN AICS
L1Dキャッシュへの配列の配置の状況を変更する事でス
ラッシングの解消を目指す.
そのためにcommon配列の宣言部にダミーの配列を配置
することでスラッシングが解消する場合がある.
また配列宣言時にダミー領域を設けることでスラッシン
グが解消する場合がある.
42
キャッシュへの格納 キャッシュへの格納(競合) メモリへのアクセス順番
改善前ソース例
ter(n=256,m=256)
a(n,m,4),b(n,m,4),c(n,m,4),d(n,m,4)
n /com/a
, m
= 1 , n
j, 1) = a(i, j, 2) + a(i, j, 3) + a(i, j, 4)
o
前 改善後
ャッシュス
ング発生
a( 1, 1, 1)
a( 2, 1, 1)
・・・
a(256, 256, 1)
a( 1, 1, 2)
a( 2, 1, 2)
・・・
(L1Dキャッシュ) (メモリ上のデータ配置)
a(256, 256, 2)
a( 1, 1, 3)
a( 2, 1, 3)
・・・
a(256, 256, 3)
a( 1, 1, 4)
a( 2, 1, 4)
・・・
a(256, 256, 4)
もしくは
複数の配列が存在している。
副作用
問題規模変更ごとにパディング量の変更が
(L1Dキャッシュ)
a( 1
a( 2
・
a(256,
a( 1
a( 2
・
(メモリ上の
a(257,
改善後ソース例
parameter(n=257,m=256)
real*8 a(n,m,4),b(n,m,4),c(n,m,4),d(n,m,4)
common /com/a
do j = 1 , m
do i = 1 , n
a(i, j, 1) = a(i, j, 2) + a(i, j, 3) + a(i, j, 4)
enddo
enddo
配列で複数のストリームが存在している例
格納場所が
ずれたことで
L1Dキャッ
シュスラッシ
ングは発生
せず
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
256×256×8B
=32×16KB
離れたアクセス
・
a(257,
a(256,
パディン
でキャッ
される場
12 RIKEN AICS
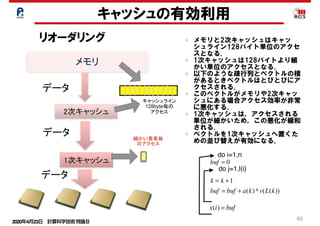
65. 66. 67. 2020年4月23日 計算科学技術特論B
67
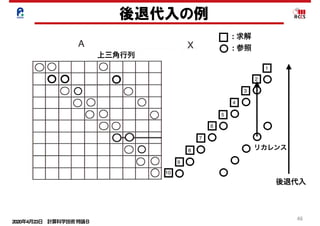
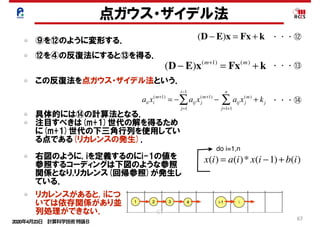
点ガウス・ザイデル法
⑨を⑫のように変形する. (D − E)x = Fx + k
(D − E)x(m+1)
= Fx(m)
+ k
aii xi
(m+1)
= − aij xj
(m+1)
j=1
i−1
∑ − aij xj
(m)
+ kj
j=1+1
n
∑
・・・⑫
⑫を④の反復法にすると⑬を得る.
この反復法を点ガウス・ザイデル法という.
具体的には⑭の計算法となる.
注目すべきは(m+1)世代の解を得るため
に(m+1)世代の下三角行列を使用してい
る点である(リカレンスの発生).
右図のように, iを定義するのにi-1の値を
参照するコーディングは下図のような参照
関係となり,リカレンス(回帰参照)が発生し
ている.
・・・⑬
・・・⑭
x(i) = a(i)* x(i −1)+ b(i)
do i=1,n
リカレンスがあると, iにつ
いては依存関係があり並
列処理ができない. 67
68. 69. 70. 2020年4月23日 計算科学技術特論B
70
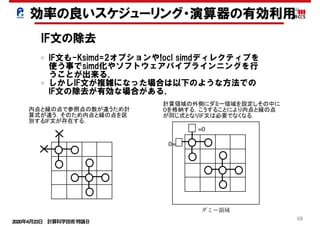
ループ分割
do i=1,n do i=1,n
… = a(i) + b(i) … = z(1,i) + z(2,i)
enddo enddo
ストリ
リスク
do i=1,n do i=1,n
… = a(I,1) + a(I,2) … = a(1,i) + a(2,i)
enddo enddo
do i=1,n do i=1,n
… = a(i) + b(i) … = a(i) + b(i)
… = c(i) + d(i) enddo
enddo do i=1,n
… = c(i) + d(i)
enddo
common //a(n),b(n) common //a(n),p(64),b(n)
配列マージ
配列次元移動
ループ分割
パディング
ループ内の処理が複雑すぎるとソフトウェアパイプライ
ンニングやsimd化が効かない場合がある.
ループ分割する事でループ内の処理が簡略化されスケ
ジューリングがうまくいくようになる場合がある.
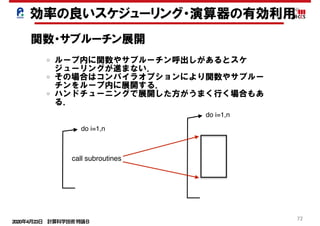
効率の良いスケジューリング・演算器の有効利用
71. 72. 73.















![2020年4月23日 計算科学技術特論B
37
ルーフラインモデルの別の見方
(1)メモリ
• メモリデータ転送量:Mdata
• 実効メモリバンド幅:Mband,
• メモリデータ移動時間:Mtime
(2)演算
• プログラム演算量:Ca
• 演算ピーク性能:Ppeak
• 最小演算時間:Ctime
Mdata
Mband
演算器の処理とメモリのデータ
の処理が同時に終わるモデル
Mtime=Mdata/Mband
Ctime=Ca/Ppeak
A+
BSPbP% B P]SO_TP % A+SPbP A+ P]SO_TP 9P
E_TP y s
ww BbX T A+ s
ww A+bX T 9bX T t
y
Mtime=Mdata/Mband_peak
L2time=L2data/L2band_peak
Ctime=Ca/Ppeak
× * × + × ,
BbX T A+bX T 9bX T
fObX T 9_
Ex_time=max(Mtime,L2time,Ctime)
Cp= Ca/(max(Mtime,L2time,Ctime)*Ppeak)
(3)実行時間 : Ex_time](https://image.slidesharecdn.com/200423materialminami-200421005734/85/CPU-37-320.jpg)
![2020年4月23日 計算科学技術特論B
39
メモリとキャッシュ混合状態での性能予測モデル
s s
A+
A+
A+
BSPbP% B P]SO_TP % A+SPbP A+ P]SO_TP 9P
E_TP y s
ww BbX T A+ s
ww A+bX T 9bX T t
y
Mtime=Mdata/Mband_peak
L2time=L2data/L2band_peak
Ctime=Ca/Ppeak
× * × + × ,
BbX T A+bX T 9bX T
fObX T 9_
Ex_time=max(Mtime,L2time,Ctime)
Cp= Ca/(max(Mtime,L2time,Ctime)*Ppeak)
BbX T6A+bX T r x A+ x u z r
Ex_time=L2timeの場合
L2dataMband
L2band
(1)メモリ
• メモリデータ転送量:Mdata
• 実効メモリバンド幅:Mband
• メモリデータ移動時間:Mtime
(2)L2キャッシュ
• L2データ転送量:L2data
• 実効L2バンド幅:L2band
• L2データ移動時間:L2time
(3)演算
• プログラム演算量:Ca
• 演算ピーク性能:Ppeak
• 最小演算時間:Ctime
「キャッシュの効果を考慮したルーフラインモデルの
拡張によるプログラムの性能予測」南一生他,情報処理学会論文誌
コンピューティングシステム,第9巻,第2号,1-14(2016年6月)
Mtime=Mdata/Mband
Ctime=Ca/Ppeak
L2time=L2data/L2band
(4)実行時間 : Ex_time](https://image.slidesharecdn.com/200423materialminami-200421005734/85/CPU-39-320.jpg)







![2020年4月23日 計算科学技術特論B
52
Cache
改善前 0.01% 42.62% 2.13E+08 97.24% 2.76% 0.00% 6.67% 3.34E+07
改善後 0.01% 24.37% 2.19E+08 37.55% 5.69% 56.76% 5.82% 5.24E+07
L1D ミス数
L1D ミス dm率
(/L1D ミス数)
L1D ミス hwpf 率
(/L1D ミス数)
L1D ミス率
(/ロード・ストア命令数)
L1I ミス率
(/有効総命令数)
L1D ミス swpf 率
(/L1D ミス数)
L2 ミス数
L2 ミス率
(/ロード・ストア命令数)
改善後ソース(最適化制御行チューニング)
51 !ocl prefetch
<<< Loop-information Start >>>
<<< [PARALLELIZATION]
<<< Standard iteration count: 616
<<< [OPTIMIZATION]
<<< SIMD
<<< SOFTWARE PIPELINING
<<< PREFETCH : 32
<<< c: 16, b: 16
<<< Loop-information End >>>
52 1 pp 2v do i = 1 , n
53 1 p 2v a(i) = b(d(i)) + scalar * c(e(i))
54 1 p 2v enddo
prefetch指示子を指定することでインダイレクトアクセス(リストアクセス)
します。その結果、データアクセス待ちコストが改善されました。
インダイレクトアクセスプリフェッチの効果
(最適化制御行チューニング)
浮動小
数点ロー
ドキャッ
シュアク
セス待ち
0.0E+00
5.0E-02
1.0E-01
1.5E-01
2.0E-01
2.5E-01
3.0E-01
3.5E-01
4.0E-01
改善前
[秒]
インダイレクトアクセス(配列
b, c)に対するプリフェッチが
生成された
ロード・ストアの効率化
プリフェッチの有効利用
ユーザーがコンパイラオプションやディレクティブで挿入する事もできる.
以下ディレクティブによるソフトウェアプリフェッチ生成の例.
R-CCSチューニングチュートリアルより](https://image.slidesharecdn.com/200423materialminami-200421005734/85/CPU-52-320.jpg)
![2020年4月23日 計算科学技術特論B
57
L1キャッシュの動作Overview
キャッシュの有効利用
・・・・・・・・・・
LineNo
0
1
2
3
4
5
6
7
8
9
10
124
125
126
127
・・・
128
byte
メモリ空間の
物理アドレス
メモリ空間の物理アドレスには
各々LineNoが割り当てられる.
そのLineNoがキャッシュのアドレ
スに使用される.
INDEX=[ADDR/128]
LineNo=MOD[INDEX/128]](https://image.slidesharecdn.com/200423materialminami-200421005734/85/CPU-57-320.jpg)
![2020年4月23日 計算科学技術特論B
58
L1キャッシュの動作Overview [Hitの場合]
キャッシュの有効利用
0 1
Line0
Line1
Line2
Line127
Way
・・・ ・・・ ・・・
L1キャッシュ容量32KB,
1ライン128Byte, 2Wayの例
1. アドレス49500の値を要求
2. 要求アドレスをラインの
インデックスに変換
ADDR=49500
↓
INDEX=[ADDR/128]=386
3. インデックスをライン番号に変
換LINE=MOD(INDEX,128)=2
4. Line2のWay0かWay1に要求アドレ
ス(index)のデータが入っていたら
Hit
386
・・・
・
・
・
・・・
13186
・・・
・・・
・・・
Hit](https://image.slidesharecdn.com/200423materialminami-200421005734/85/CPU-58-320.jpg)
![2020年4月23日 計算科学技術特論B
59
L1キャッシュの動作Overview [Missの場合(1)]
キャッシュの有効利用
0 1
Line0
Line1
Line2
Line127
Way
・・・ ・・・ ・・・
1. アドレス49500の値を要求
2. 要求アドレスをラインの
インデックスに変換
ADDR=49500
↓
INDEX=[ADDR/128]=386
3. インデックスをライン番号に変
換LINE=MOD(INDEX,128)=2
4. 入っていなければ次のレベル(L2
やメモリ)からデータを持ってく
る
・・・
・
・
・
・・・
13186
・・・
・・・
・・・
Wayに空きがあればそこに入れる
386
L1キャッシュ容量32KB,
1ライン128Byte, 2Wayの例](https://image.slidesharecdn.com/200423materialminami-200421005734/85/CPU-59-320.jpg)
![2020年4月23日 計算科学技術特論B
60
L1キャッシュの動作Overview [Missの場合(2)] キャッシュ競合
キャッシュスラッシング
キャッシュの有効利用
0 1
Line0
Line1
Line2
Line127
Way
・・・ ・・・ ・・・
1. アドレス49500の値を要求
2. 要求アドレスをラインの
インデックスに変換
ADDR=49500
↓
INDEX=[ADDR/128]=386
3. インデックスをライン番号に変
換LINE=MOD(INDEX,128)=2
4. 入っていなければ次のレベル(L2や
メモリ)からデータを持ってくる
・・・
・
・
・
・・・
13186
・・・
・・・
・・・
Wayに空きがなければ一番使
われてないものをどかして,
そこに入れる
642 386
※ここには書かれていないが,どちらの
Wayがより古いか?を表すフラグがある
L1キャッシュ容量32KB,
1ライン128Byte, 2Wayの例](https://image.slidesharecdn.com/200423materialminami-200421005734/85/CPU-60-320.jpg)


























![[DL Hacks] Learning Transferable Features with Deep Adaptation Networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-20151105-iwasawa-160204020204-thumbnail.jpg?width=640&height=640&fit=bounds)











































