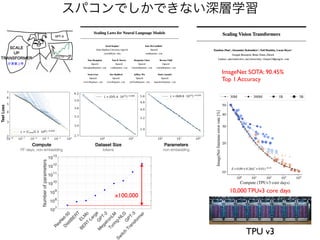
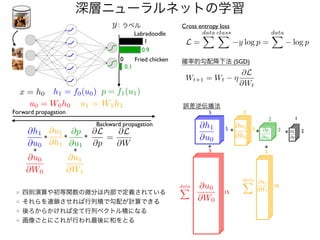
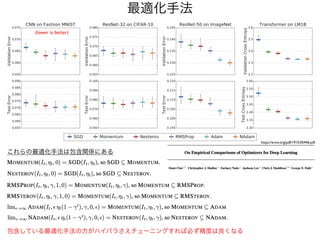
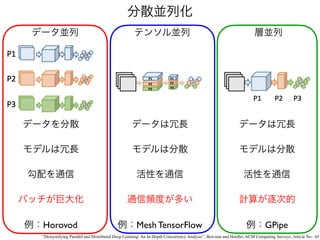
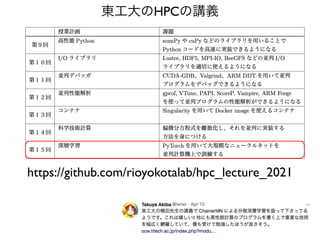
スパコンでしかできない深層学習
TPU v3
ImageNet SOTA:90.45
%
Top 1 Accuracy
10,000 TPUv3 core days
R
e
s
N
e
t
-
5
0
D
i
s
t
i
l
B
E
R
T
E
L
M
o
B
E
R
T
-
L
a
r
g
e
G
P
T
-
2
M
e
g
a
t
r
o
n
L
M
T
u
r
i
n
g
-
N
L
G
G
P
T
-
3
S
w
i
t
c
h
T
r
a
n
s
f
o
r
m
e
r
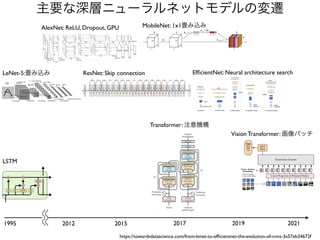
10
7
10
8
10
9
10
10
10
11
10
12
10
13
Number
of
parameters
x100,000
計算量上等
3.
Papers with code
MLPerftarget score: 75.9
https://paperswithcode.com
ImageNet-1k
一番良い結果を出している論文の多くが手元で再現可能
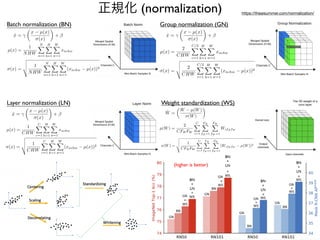
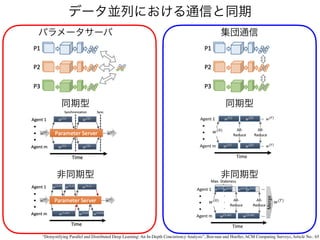
正規化 (normalization)
Batch normalization(BN)
Layer normalization (LN)
Group normalization (GN)
Weight standardization (WS)
https://theaisummer.com/normalization/
<latexit sha1_base64="RqN4YpnAkqmVd2gk3UwpB5hXPg8=">AAACN3icbZDPShxBEMZ7jEZjYlyTYy6DS2BFXGZUYiAEJF48ruCqsL0sNb01s43dM0N3TdhlmIfxMXyCXJNjTjkpXn0De3b34J980PDjqyqq+otyJS0FwV9v4dXi0uvllTerb9+tvV9vbHw4s1lhBHZFpjJzEYFFJVPskiSFF7lB0JHC8+jyqK6f/0RjZZae0iTHvoYklbEUQM4aNL7xEVA5rr7zBLQGrjCmFo8NiHK8w3XRGm9VJbcy0VAjNzIZ0dY2j5Bg0GgG7WAq/yWEc2iyuTqDxg0fZqLQmJJQYG0vDHLql2BICoXVKi8s5iAuIcGewxQ02n45/WTlf3bO0I8z415K/tR9PFGCtnaiI9epgUb2ea02/1frFRR/7ZcyzQvCVMwWxYXyKfPrxPyhNChITRyAMNLd6osRuITI5fpky9DWp1Uul/B5Ci/hbLcdfmnvnew3D3/ME1phn9gma7GQHbBDdsw6rMsEu2K/2G/2x7v2/nm33t2sdcGbz3xkT+TdPwDfNq3S</latexit>
x̂ =
✓
x µ(x)
(x)
◆
+
<latexit sha1_base64="mMlCkP7IjuvtvnbWTjoEnGSHv/w=">AAACUXicbZDLSgMxFIZPx/u96tLNYBHqwjKjom4E0U1XomCt0KlDJs20wSQzJhm1hHkyH8OVSxdu9AncmWkreDsQ+Pj/k5yTP0oZVdrznkvO2PjE5NT0zOzc/MLiUnl55VIlmcSkgROWyKsIKcKoIA1NNSNXqSSIR4w0o5uTwm/eEaloIi50PyVtjrqCxhQjbaWw3AgU7XJUfdg8DNSt1CaIJcLGz81pvZkHKuPXp6ERh/6Q66HpfXEzNPeWqw/Wx737fCvgmX1n83o7D8sVr+YNyv0L/ggqMKqzsPwadBKccSI0Zkiplu+lum2Q1BQzks8GmSIpwjeoS1oWBeJEtc3g+7m7YZWOGyfSHqHdgfr9hkFcqT6PbCdHuqd+e4X4n9fKdHzQNlSkmSYCDwfFGXN14hZZuh0qCdasbwFhSe2uLu4hm5+2if+Y0lHFakUu/u8U/sLlds3fq+2c71aOjkcJTcMarEMVfNiHI6jDGTQAwyO8wBu8l55KHw44zrDVKY3urMKPcuY+AT9ntVY=</latexit>
(x) =
v
u
u
t 1
NHW
N
X
n=1
H
X
h=1
W
X
w=1
(xnchw µ(x))2
<latexit sha1_base64="dpuT1CUY56ArR9bRnSs4Ys0fxb4=">AAACPHicbZDNSgMxFIUz/tb/UZduBotQN2VGRd0IRTddlQrWCp06ZNKMDU0yQ5LRljCv42P4BG4V3OtK3Lo201ZQ64XAxzn3cm9OmFAileu+WFPTM7Nz84WFxaXlldU1e33jUsapQLiBYhqLqxBKTAnHDUUUxVeJwJCFFDfD3lnuN2+xkCTmF2qQ4DaDN5xEBEFlpMCu+Cwt9XdP/EhApL1M16rNzJcpu64Fmp94I64GuvvNzUDfGe4bG3XvssAuumV3WM4keGMognHVA/vN78QoZZgrRKGULc9NVFtDoQiiOFv0U4kTiHrwBrcMcsiwbOvhTzNnxygdJ4qFeVw5Q/XnhIZMygELTSeDqiv/ern4n9dKVXTc1oQnqcIcjRZFKXVU7OSxOR0iMFJ0YAAiQcytDupCk5ky4f7a0pH5aXku3t8UJuFyr+wdlvfPD4qV03FCBbAFtkEJeOAIVEAV1EEDIHAPHsETeLYerFfr3foYtU5Z45lN8Kuszy9NhbAf</latexit>
µ(x) =
1
NHW
N
X
n=1
H
X
h=1
W
X
w=1
xnchw
<latexit sha1_base64="jWwokzwi9lm2DSevW/HMsFrzSug=">AAACPHicbZDNSgMxFIUz/tb6V3XpZrAIdVNmVNSNUOymywq2FTp1yKQZG0wyQ5KxljCv42P4BG4V3OtK3Lo2045g1QOBj3Pv5d6cIKZEKsd5sWZm5+YXFgtLxeWV1bX10sZmW0aJQLiFIhqJywBKTAnHLUUUxZexwJAFFHeCm3pW79xiIUnEL9Qoxj0GrzkJCYLKWH6p5rGkcrd36oUCIu2mut7opJ5M2FXd1+jUnXDD14Nv7vh6aPjO1xwNhqlfKjtVZyz7L7g5lEGupl968/oRShjmClEoZdd1YtXTUCiCKE6LXiJxDNENvMZdgxwyLHt6/NPU3jVO3w4jYR5X9tj9OaEhk3LEAtPJoBrI37XM/K/WTVR40tOEx4nCHE0WhQm1VWRnsdl9IjBSdGQAIkHMrTYaQJOZMuFObenL7LQsF/d3Cn+hvV91j6oH54fl2lmeUAFsgx1QAS44BjXQAE3QAgjcg0fwBJ6tB+vVerc+Jq0zVj6zBaZkfX4BE+av/g==</latexit>
µ(x) =
1
CHW
C
X
c=1
H
X
h=1
W
X
w=1
xnchw
<latexit sha1_base64="RqN4YpnAkqmVd2gk3UwpB5hXPg8=">AAACN3icbZDPShxBEMZ7jEZjYlyTYy6DS2BFXGZUYiAEJF48ruCqsL0sNb01s43dM0N3TdhlmIfxMXyCXJNjTjkpXn0De3b34J980PDjqyqq+otyJS0FwV9v4dXi0uvllTerb9+tvV9vbHw4s1lhBHZFpjJzEYFFJVPskiSFF7lB0JHC8+jyqK6f/0RjZZae0iTHvoYklbEUQM4aNL7xEVA5rr7zBLQGrjCmFo8NiHK8w3XRGm9VJbcy0VAjNzIZ0dY2j5Bg0GgG7WAq/yWEc2iyuTqDxg0fZqLQmJJQYG0vDHLql2BICoXVKi8s5iAuIcGewxQ02n45/WTlf3bO0I8z415K/tR9PFGCtnaiI9epgUb2ea02/1frFRR/7ZcyzQvCVMwWxYXyKfPrxPyhNChITRyAMNLd6osRuITI5fpky9DWp1Uul/B5Ci/hbLcdfmnvnew3D3/ME1phn9gma7GQHbBDdsw6rMsEu2K/2G/2x7v2/nm33t2sdcGbz3xkT+TdPwDfNq3S</latexit>
x̂ =
✓
x µ(x)
(x)
◆
+
<latexit sha1_base64="ih89Pzc2EBidrxV+yRGOgCPpnQE=">AAACUXicbZC7TsMwFIZPw/1eYGSJqJDKQJUAAhYkRJeOIFGK1JTIcZ3WwnaC7QCVlSfjMZgYGVjgCdhw2iJxO5KlT/+5+o9SRpX2vOeSMzE5NT0zOze/sLi0vFJeXbtUSSYxaeKEJfIqQoowKkhTU83IVSoJ4hEjreimXuRbd0QqmogLPUhJh6OeoDHFSFspLDcDRXscVR+2jwN1K7UJYomw8XNTb7TyQGX8uh4afOyPuBGa/he3QnNvufoQGoH79/lOwDM7Z/t6Nw/LFa/mDcP9C/4YKjCOs7D8GnQTnHEiNGZIqbbvpbpjkNQUM5LPB5kiKcI3qEfaFgXiRHXM8Pu5u2WVrhsn0j6h3aH6vcMgrtSAR7aSI91Xv3OF+F+unen4qGOoSDNNBB4tijPm6sQtvHS7VBKs2cACwpLaW13cR9Y/bR3/saWritMKX/zfLvyFy92af1DbO9+vnJyOHZqFDdiEKvhwCCfQgDNoAoZHeIE3eC89lT4ccJxRqVMa96zDj3AWPgEEPLU1</latexit>
(x) =
v
u
u
t 1
CHW
C
X
c=1
H
X
h=1
W
X
w=1
(xnchw µ(x))2
<latexit sha1_base64="RqN4YpnAkqmVd2gk3UwpB5hXPg8=">AAACN3icbZDPShxBEMZ7jEZjYlyTYy6DS2BFXGZUYiAEJF48ruCqsL0sNb01s43dM0N3TdhlmIfxMXyCXJNjTjkpXn0De3b34J980PDjqyqq+otyJS0FwV9v4dXi0uvllTerb9+tvV9vbHw4s1lhBHZFpjJzEYFFJVPskiSFF7lB0JHC8+jyqK6f/0RjZZae0iTHvoYklbEUQM4aNL7xEVA5rr7zBLQGrjCmFo8NiHK8w3XRGm9VJbcy0VAjNzIZ0dY2j5Bg0GgG7WAq/yWEc2iyuTqDxg0fZqLQmJJQYG0vDHLql2BICoXVKi8s5iAuIcGewxQ02n45/WTlf3bO0I8z415K/tR9PFGCtnaiI9epgUb2ea02/1frFRR/7ZcyzQvCVMwWxYXyKfPrxPyhNChITRyAMNLd6osRuITI5fpky9DWp1Uul/B5Ci/hbLcdfmnvnew3D3/ME1phn9gma7GQHbBDdsw6rMsEu2K/2G/2x7v2/nm33t2sdcGbz3xkT+TdPwDfNq3S</latexit>
x̂ =
✓
x µ(x)
(x)
◆
+
<latexit sha1_base64="+mSuVgDmFbFdQz9MORmrfpjKhzI=">AAACQHicbZBNSwMxEIazflu/qh69LBZBL3W3inoRxHrosYL9gG5dsmm2DSbZJclaS9g/5M/wF3jVu+BNvHoy21aw1YHAM+/MMJM3iCmRynFerJnZufmFxaXl3Mrq2vpGfnOrLqNEIFxDEY1EM4ASU8JxTRFFcTMWGLKA4kZwV87qjXssJIn4jRrEuM1gl5OQIKiM5OevPJbsPxyce6GASJdSXa40Uk8m7FaXD0upr9G5O8orvu79cMPXfcMPvuao10/9fMEpOsOw/4I7hgIYR9XPv3mdCCUMc4UolLLlOrFqaygUQRSnOS+ROIboDnZxyyCHDMu2Hv42tfeM0rHDSJjHlT1Uf09oyKQcsMB0Mqh6crqWif/VWokKz9qa8DhRmKPRojChtorszDq7QwRGig4MQCSIudVGPWh8U8bgiS0dmZ2W+eJOu/AX6qWie1I8uj4uXFyOHVoCO2AX7AMXnIILUAFVUAMIPIJn8AJerSfr3fqwPketM9Z4ZhtMhPX1DSxusYA=</latexit>
µ(x) =
2
CHW
C/2
X
c=1
H
X
h=1
W
X
w=1
xnchw
<latexit sha1_base64="VgwH0utETMAfcEv0IoDUtgzOTWk=">AAACVXicbZDdTsIwGIbLxD/8Qz30ZJGY4IG4oVFPSIyccIiJiIbh0pUOGttutp1Cml2bl2G8AE/1CkzsABNRv6TJ2/f7zRPElEjlOK85ay4/v7C4tFxYWV1b3yhubl3LKBEIt1BEI3ETQIkp4biliKL4JhYYsoDidnBfz/LtRywkifiVGsW4y2Cfk5AgqIzlF289SfoMlof7NU8+CKW9UECkq6muN9qpJxN2p+uH1dTXqOZO/g1fD75129dPRpeHvuZo8JQeeCwxs/bvTEex5FSccdh/hTsVJTCNpl9883oRShjmClEoZcd1YtXVUCiCKE4LXiJxDNE97OOOkRwyLLt6jCC194zTs8NImMeVPXZ/dmjIpByxwFQyqAbydy4z/8t1EhWedTXhcaIwR5NFYUJtFdkZT7tHBEaKjoyASBBzq40G0DBUhvrMlp7MTsu4uL8p/BXX1Yp7Ujm6PC6dX0wJLYEdsAvKwAWn4Bw0QBO0AALP4A28g4/cS+7TylsLk1IrN+3ZBjNhbXwBPOS2tw==</latexit>
(x) =
v
u
u
t 2
CHW
C/2
X
c=1
H
X
h=1
W
X
w=1
(xnchw µ(x))2
<latexit sha1_base64="PSqEPc30bQy6FHyPWYe6IWsLh00=">AAACZnicbVFNS8MwGM7q9/dUxIOX4BDmwdFOUS/CcDB2VHBWWGdJs3SLS9qapMII/Y9e/QGCv8CrprMH3Xwh8LzP837xJEgYlcq230rW3PzC4tLyyura+sbmVnl7517GqcCkg2MWi4cAScJoRDqKKkYeEkEQDxhxg1Ez190XIiSNozs1TkiPo0FEQ4qRMpRffvIkHXBUdY+vPPkslPZCgbB2Mt1s+e2W72aeTPmjbma+xldOkRnJ5KHf/sW4E8Y1TNU1tUY0WXbi8dQMP36sZ365YtfsScBZ4BSgAoq48cvvXj/GKSeRwgxJ2XXsRPU0EopiRrJVL5UkQXiEBqRrYIQ4kT098SSDR4bpwzAW5kUKTtjfHRpxKcc8MJUcqaGc1nLyP62bqvCyp2mUpIpE+GdRmDKoYpgbDPtUEKzY2ACEBTW3QjxExlRlvuHPlr7MT8t9caZdmAX39ZpzXju9Pas0rguHlsEBOARV4IAL0ABtcAM6AINX8Am+SqD0YW1ae9b+T6lVKnp2wZ+w4Dc1/7tI</latexit>
(W) =
v
u
u
t 1
CFHFW
C
X
c=1
FH
X
fH =1
FW
X
fW =1
(WcfH fW
µ(W))2
<latexit sha1_base64="kB8kd70X3SXw/F5W+lkWy3s6d8o=">AAACUXicbZDNSsNAFIVv41+tf1WXboJF0E1JVNSNUCyULivYptDUMJlO2sGZJMxMhBLyZD6GK5cu3OgTuHPSZtGqFwbO/c4d5s7xY0alsqy3krGyura+Ud6sbG3v7O5V9w96MkoEJl0csUj0fSQJoyHpKqoY6ceCIO4z4vhPzdx3nomQNAof1DQmQ47GIQ0oRkojr9p1eXLqnN26gUA4Pc/SZstrtzwnc2XCH9Nm5qX41i46bek+8NoLxJkRRxNHj2ovyFG1ZtWtWZl/hV2IGhTV8aof7ijCCSehwgxJObCtWA1TJBTFjGQVN5EkRvgJjclAyxBxIofp7PuZeaLJyAwioU+ozBldvJEiLuWU+3qSIzWRv70c/ucNEhXcDFMaxokiIZ4/FCTMVJGZZ2mOqCBYsakWCAuqdzXxBOkglU586ZWRzFfLc7F/p/BX9M7r9lX94v6y1rgrEirDERzDKdhwDQ1oQwe6gOEF3uETvkqvpW8DDGM+apSKO4ewVMbWD9qTtTQ=</latexit>
µ(W) =
2
CFHFW
C
X
c=1
FH
X
fH =1
FW
X
fW =1
WcfH fW
<latexit sha1_base64="Pt2kdQmIa3vxI/2P4C+R6402oY0=">AAACK3icbZDNTsJAFIWn+If4h7p000hMYCG2atSNCdGNS0yEklBCpsMUJsy0zcytCWn6GD6GT+BWn8CVxi3v4RRYCHiSSb6ce2/uneNFnCmwrC8jt7K6tr6R3yxsbe/s7hX3D5oqjCWhDRLyULY8rChnAW0AA05bkaRYeJw63vA+qzvPVCoWBk8wimhH4H7AfEYwaKtbPHMHGBInvXU59aHs+hKTxDl1RVx2KmniKtYXOENXsv4AKt1iyapaE5nLYM+ghGaqd4tjtxeSWNAACMdKtW0rgk6CJTDCaVpwY0UjTIa4T9saAyyo6iSTj6XmiXZ6ph9K/QIwJ+7fiQQLpUbC050Cw0At1jLzv1o7Bv+mk7AgioEGZLrIj7kJoZmlZPaYpAT4SAMmkulbTTLAOhvQWc5t6anstFTnYi+msAzN86p9Vb14vCzV7mYJ5dEROkZlZKNrVEMPqI4aiKAX9Ibe0Yfxanwa38bPtDVnzGYO0ZyM8S8fuqhU</latexit>
Ŵ =
✓
W µ(W)
(W)
◆
B
N
+
LN
B
N
+
LN
B
N
+
LN
B
N
+
LN
(higher is better)
11.
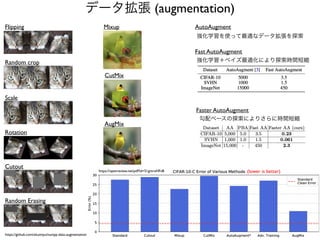
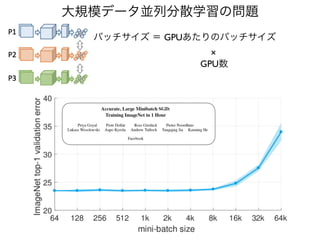
データ拡張 (augmentation)
Flipping
Rotation
Cutout
Random crop
Scale
RandomErasing
Mixup
CutMix
AugMix
AutoAugment
強化学習を使って最適なデータ拡張を探索
Fast AutoAugment
強化学習+ベイズ最適化により探索時間短縮
Faster AutoAugment
勾配ベースの探索によりさらに時間短縮
https://openreview.net/pdf?id=S1gmrxHFvB
https://github.com/xkumiyu/numpy-data-augmentation
(lower is better)
12.
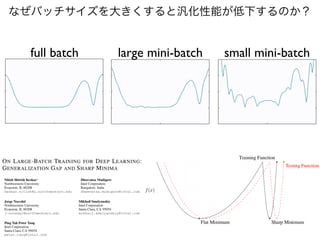
正則化 (regularization)
<latexit sha1_base64="PTOETKQJ9sDV108G8utVEdMYksY=">AAACGnicbVDLSsNAFJ34rPUVdSnIYBHcWJIi6kYounHhooJ9QBPLzWTaDp08mJkIJWTnZ/gFbvUL3IlbN36A/+Gk7cK2Hhg4nHMv98zxYs6ksqxvY2FxaXlltbBWXN/Y3No2d3YbMkoEoXUS8Ui0PJCUs5DWFVOctmJBIfA4bXqD69xvPlIhWRTeq2FM3QB6IesyAkpLHfPACUD1CfD0Nrt0ZBI8pD4oyE4cHvVw3DFLVtkaAc8Te0JKaIJax/xx/IgkAQ0V4SBl27Zi5aYgFCOcZkUnkTQGMoAebWsaQkClm47+keEjrfi4Gwn9QoVH6t+NFAIph4GnJ/PUctbLxf+8dqK6F27KwjhRNCTjQ92EYxXhvBTsM0GJ4kNNgAims2LSBwFE6eqmrvgyj5bpXuzZFuZJo1K2z8qVu9NS9WrSUAHto0N0jGx0jqroBtVQHRH0hF7QK3ozno1348P4HI8uGJOdPTQF4+sXt5uh/g==</latexit>
L=
data
X
log p
損失関数
https://arxiv.org/abs/2002.08709
L2正則化
<latexit sha1_base64="Yy8xPfnTLiqjWpL4JDjdct97CAw=">AAACJ3icbVDLSgMxFM34rPU16tJNsAhCscxUUTdC0Y0LFxXsAzq13MmkNTTzIMkIZTof4Wf4BW71C9yJLl34H2baLmz1QOBwzr259x434kwqy/o05uYXFpeWcyv51bX1jU1za7suw1gQWiMhD0XTBUk5C2hNMcVpMxIUfJfThtu/zPzGAxWShcGtGkS07UMvYF1GQGmpYxYdH9Q9AZ5cp+eOjP27xAMF6aHDwx6Oig7Xf3kwbAzvyh2zYJWsEfBfYk9IAU1Q7ZjfjheS2KeBIhykbNlWpNoJCMUIp2neiSWNgPShR1uaBuBT2U5GR6V4Xyse7oZCv0Dhkfq7IwFfyoHv6srsBDnrZeJ/XitW3bN2woIoVjQg40HdmGMV4iwh7DFBieIDTYAIpnfF5B4EEKVznJriyWy1VOdiz6bwl9TLJfukdHRzXKhcTBLKoV20hw6QjU5RBV2hKqohgh7RM3pBr8aT8Wa8Gx/j0jlj0rODpmB8/QDq3qdI</latexit>
L =
data
X
log p + |W|2
L1正則化
<latexit sha1_base64="qqFUGj5bRbXJTuGZgDLorSbuXL0=">AAACJXicbVDLSgMxFM3UV62vqks3wSIoYplRUTdC0Y0LFxXsAzq13MmkbWjmQZIRynS+wc/wC9zqF7gTwZUr/8NM24VtPRA4nHNv7r3HCTmTyjS/jMzc/MLiUnY5t7K6tr6R39yqyiAShFZIwANRd0BSznxaUUxxWg8FBc/htOb0rlO/9kiFZIF/r/ohbXrQ8VmbEVBaauUPbA9UlwCPb5NLW0beQ+yCguTI5kEHh4c213+5MKgNWvmCWTSHwLPEGpMCGqPcyv/YbkAij/qKcJCyYZmhasYgFCOcJjk7kjQE0oMObWjqg0dlMx6elOA9rbi4HQj9fIWH6t+OGDwp+56jK9MD5LSXiv95jUi1L5ox88NIUZ+MBrUjjlWA03ywywQlivc1ASKY3hWTLgggSqc4McWV6WqJzsWaTmGWVI+L1lnx5O60ULoaJ5RFO2gX7SMLnaMSukFlVEEEPaEX9IrejGfj3fgwPkelGWPcs40mYHz/AprfpqQ=</latexit>
L =
data
X
log p + |W|
Sharpness Aware Minimization (SAM)
Flooding
<latexit sha1_base64="+29JRp4dO+SSQAn2+lrjhc+5WsE=">AAACIHicbVDLSgMxFM34rPVVdekmWAVBWmZU1I1QdOPCRQX7gE4tdzJpG5p5kGSEMp0f8DP8Arf6Be7Epe79DzNtF7b1QOBwzr3ck+OEnEllml/G3PzC4tJyZiW7ura+sZnb2q7KIBKEVkjAA1F3QFLOfFpRTHFaDwUFz+G05vSuU7/2SIVkgX+v+iFtetDxWZsRUFpq5fZtD1SXAI9vk0tbRt5D7IKCZFCwedDBYcEZHDmtXN4smkPgWWKNSR6NUW7lfmw3IJFHfUU4SNmwzFA1YxCKEU6TrB1JGgLpQYc2NPXBo7IZD3+T4AOtuLgdCP18hYfq340YPCn7nqMn0+xy2kvF/7xGpNoXzZj5YaSoT0aH2hHHKsBpNdhlghLF+5oAEUxnxaQLAojSBU5ccWUaLdG9WNMtzJLqcdE6K57cneZLV+OGMmgX7aFDZKFzVEI3qIwqiKAn9IJe0ZvxbLwbH8bnaHTOGO/soAkY378ypqRP</latexit>
L =
data
X
| log p b| + b
<latexit sha1_base64="9vmQ2Pyai29yDGuUrPziv2Rg5HE=">AAACPnicbVBNSxxBEO0xfn+uydFL4yIo4jKjol6EZb3kkIOBrCvsjEtNT+1uY0/30N0jLsP8n/yM/IJcE39AvEmuOaZnXcGvBwWP96qoqhdnghvr+3fe1Ifpmdm5+YXFpeWV1bXa+scLo3LNsM2UUPoyBoOCS2xbbgVeZhohjQV24uuzyu/coDZcyW92lGGUwkDyPmdgndSrtcIU7JCBKL6Up6HJ06siAQulk297RYiZ4ULJUGCoh6rs7oVCDWi23dl9snaiXq3uN/wx6FsSTEidTHDeq/0JE8XyFKVlAozpBn5mowK05UxguRjmBjNg1zDArqMSUjRRMf61pFtOSWhfaVfS0rH6fKKA1JhRGrvO6jPz2qvE97xubvsnUcFllluU7HFRPxfUKloFRxOukVkxcgSY5u5WyoaggVkX74stialOK10uwesU3pKL/UZw1Dj4elhvtiYJzZMNskm2SUCOSZN8JuekTRj5Tn6SX+S398O79x68v4+tU95k5hN5Ae/ff/ElsWk=</latexit>
L =
data
X
max
✏⇢
[ log p(W + ✏)]
https://arxiv.org/abs/2010.01412
Dropout
https://arxiv.org/abs/1603.09382
Stochastic depth
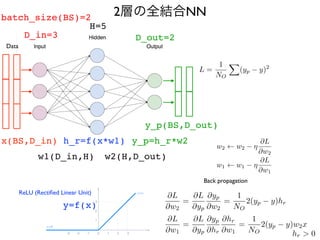
NumPyだけによる実装
import numpy asn
p
epochs = 30
0
batch_size = 3
2
D_in = 78
4
H = 10
0
D_out = 1
0
learning_rate = 1.0e-0
6
# create random input and output dat
a
x = np.random.randn(batch_size, D_in
)
y = np.random.randn(batch_size, D_out
)
# randomly initialize weight
s
w1 = np.random.randn(D_in, H
)
w2 = np.random.randn(H, D_out
)
for epoch in range(epochs)
:
# forward pas
s
h = x.dot(w1) # h = x * w
1
h_r = np.maximum(h, 0) # h_r = ReLU(h
)
y_p = h_r.dot(w2) # y_p = h_r * w
2
# compute mean squared error and print los
s
loss = np.square(y_p - y).sum()
print(epoch, loss
)
# backward pass: compute gradients of loss with respect to w
2
grad_y_p = 2.0 * (y_p - y)
grad_w2 = h_r.T.dot(grad_y_p)
# backward pass: compute gradients of loss with respect to w
1
grad_h_r = grad_y_p.dot(w2.T)
grad_h = grad_h_r.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# update weight
s
w1 -= learning_rate * grad_w
1
w2 -= learning_rate * grad_w2
w1 w1 ⌘
@L
@w1
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
w2 w2 ⌘
@L
@w2
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
@L
@w2
=
@L
@yp
@yp
@w2
=
1
NO
2 (yp y) hr
@L
@w1
=
@L
@yp
@yp
@hr
@hr
@w1
=
1
NO
2 (yp y) w2x
L =
1
NO
X
(yp y)
2
00_numpy.py
24.
PyTorch の導入
import torc
h
epochs = 30
0
batch_size = 3
2
D_in = 78
4
H = 10
0
D_out = 1
0
learning_rate = 1.0e-0
6
# create random input and output dat
a
x = torch.randn(batch_size, D_in
)
y = torch.randn(batch_size, D_out
)
# randomly initialize weight
s
w1 = torch.randn(D_in, H
)
w2 = torch.randn(H, D_out
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2
)
# compute and print los
s
loss = (y_p - y).pow(2).sum().item(
)
print(t, loss
)
# backward pass: compute gradients of loss with respect to w
2
grad_y_p = 2.0 * (y_p - y
)
grad_w2 = h_r.t().mm(grad_y_p
)
# backward pass: compute gradients of loss with respect to w
1
grad_h_r = grad_y_p.mm(w2.t()
)
grad_h = grad_h_r.clone(
)
grad_h[h < 0] =
0
grad_w1 = x.t().mm(grad_h
)
# update weight
s
w1 -= learning_rate * grad_w
1
w2 -= learning_rate * grad_w2
np.random torch
np torch
x.dot(w1) x.mm(w1)
np.maximum(h, 0) h.clamp(min=0)
np.square(y_p-y) (y_p-y).pow(2)
copy() clone()
01_tensors.py
25.
自動微分の導入
# randomly initializeweight
s
w1 = torch.randn(D_in, H
)
w2 = torch.randn(H, D_out
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2
)
# compute and print los
s
loss = (y_p - y).pow(2).sum().item(
)
print(t, loss
)
# backward pass: compute gradients of loss
with respect to w
2
grad_y_p = 2.0 * (y_p - y
)
grad_w2 = h_r.t().mm(grad_y_p
)
# backward pass: compute gradients of loss
with respect to w
1
grad_h_r = grad_y_p.mm(w2.t()
)
grad_h = grad_h_r.clone(
)
grad_h[h < 0] =
0
grad_w1 = x.t().mm(grad_h
)
# update weight
s
w1 -= learning_rate * grad_w
1
w2 -= learning_rate * grad_w2
01_tensor.py 02_autograd.py
# randomly initialize weight
s
w1 = torch.randn(D_in, H, requires_grad=True
)
w2 = torch.randn(H, D_out, requires_grad=True
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2
)
# compute and print los
s
loss = (y_p - y).pow(2).sum(
)
print(t, loss.item()
)
# backward pas
s
loss.backward(
)
with torch.no_grad()
:
# update weight
s
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# initialize weight
s
w1.grad.zero_(
)
w2.grad.zero_()
@L
@w1
=
@L
@yp
@yp
@hr
@hr
@w1
=
1
NO
2(yp y)w2x
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
微分を自動的に計算してくれる
26.
活性化関数の自作 03_function.py
import torc
h
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2)
02_autograd.py
import torc
h
class ReLU(torch.autograd.Function)
:
@staticmetho
d
def forward(ctx, input)
:
ctx.save_for_backward(input
)
return input.clamp(min=0
)
@staticmetho
d
def backward(ctx, grad_output)
:
input, = ctx.saved_tensor
s
grad_input = grad_output.clone(
)
grad_input[input<0] =
0
return grad_inpu
t
for epoch in range(epochs)
:
# forward pass: compute predicted
y
relu = ReLU.appl
y
h = x.mm(w1
)
h_r = relu(h
)
y_p = h_r.mm(w2)
.
.
.
.
.
.
y=f(x)
ReLU (Recti
fi
ed Linear Unit)
27.
torch.nnの利用 04_nn_module.py
# createrandom input and output dat
a
x = torch.randn(batch_size, D_in
)
y = torch.randn(batch_size, D_out
)
# randomly initialize weight
s
w1 = torch.randn(D_in, H, requires_grad=True
)
w2 = torch.randn(H, D_out, requires_grad=True
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2
)
# compute and print los
s
loss = (y_p - y).pow(2).sum()
print(t, loss.item()
)
# backward pas
s
loss.backward(
)
with torch.no_grad()
:
# update weight
s
w1 -= learning_rate * w1.gra
d
w2 -= learning_rate * w2.gra
d
# initialize weight
s
w1.grad.zero_(
)
w2.grad.zero_()
02_autograd.py
# create random input and output dat
a
x = torch.randn(batch_size, D_in
)
y = torch.randn(batch_size, D_out
)
# define mode
l
model = torch.nn.Sequential
(
torch.nn.Linear(D_in, H)
,
torch.nn.ReLU()
,
torch.nn.Linear(H, D_out)
,
)
# define loss functio
n
criterion = torch.nn.MSELoss(reduction='sum'
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
y_p = model(x)
# compute and print los
s
loss = criterion(y_p, y)
print(t, loss.item()
)
# backward pas
s
model.zero_grad()
loss.backward(
)
with torch.no_grad()
:
# update weight
s
for param in model.parameters()
:
param -= learning_rate * param.grad
28.
最適化関数の呼び出し 05_optimizer.py
04_nn_module.py
# defineloss functio
n
criterion = torch.nn.MSELoss(reduction='sum'
)
for t in range(epochs)
:
# forward pass: compute predicted
y
y_p = model(x
)
# compute and print los
s
loss = criterion(y_p, y
)
print(t, loss.item()
)
# backward pas
s
model.zero_grad()
loss.backward(
)
with torch.no_grad()
:
# update weight
s
for param in model.parameters()
:
param -= learning_rate * param.grad
# define loss functio
n
criterion = torch.nn.MSELoss(reduction='sum'
)
# define optimize
r
optimizer = torch.optim.SGD(model.parameters(),
lr=learning_rate
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
y_p = model(x
)
# compute and print los
s
loss = criterion(y_p, y
)
print(t, loss.item()
)
# backward pas
s
optimizer.zero_grad()
loss.backward(
)
# update weight
s
optimizer.step()
29.
モデルを自作 06_mm_module.py
05_optimizer.py
# createrandom input and output dat
a
x = torch.randn(batch_size, D_in
)
y = torch.randn(batch_size, D_out
)
# define mode
l
model = torch.nn.Sequential
(
torch.nn.Linear(D_in, H)
,
torch.nn.ReLU()
,
torch.nn.Linear(H, D_out)
,
)
# define loss functio
n
criterion = torch.nn.MSELoss(reduction='sum')
import torch.nn as n
n
import torch.nn.functional as
F
class TwoLayerNet(nn.Module)
:
def __init__(self, D_in, H, D_out)
:
super(TwoLayerNet, self).__init__(
)
self.fc1 = nn.Linear(D_in, H
)
self.fc2 = nn.Linear(H, D_out
)
def forward(self, x)
:
h = self.fc1(x
)
h_r = F.relu(h
)
y_p = self.fc2(h_r
)
return y_
p
# create random input and output dat
a
x = torch.randn(batch_size, D_in
)
y = torch.randn(batch_size, D_out
)
# define mode
l
model = TwoLayerNet(D_in, H, D_out
)
# define loss functio
n
criterion = nn.MSELoss(reduction='sum')
.
.
.
学習時に不変
30.
MNIST Datasetのロード 07_mnist.py
06_mm_module.py
importtorch.nn as n
n
import torch.nn.functional as
F
from torchvision import datasets, transform
s
# read input data and label
s
train_dataset = datasets.MNIST('./data'
,
train=True
,
download=True
,
transform=transforms.ToTensor()
)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset
,
batch_size=batch_size
,
shuffle=True
)
for epoch in range(epochs)
:
# Set model to training mod
e
model.train(
)
# Loop over each batch from the training se
t
for batch_idx, (x, y) in enumerate(train_loader):
# forward pass: compute predicted
y
y_p = model(x)
.
.
.
import torch.nn as n
n
import torch.nn.functional as
F
# create random input and output dat
a
x = torch.randn(batch_size, D_in
)
y = torch.randn(batch_size, D_out
)
for t in range(epochs)
:
# forward pass: compute predictedy
y_p = model(x)
.
.
.
.
.
.
Models
19_regularization.py
model = VGG('VGG19').to(device
)
#model = ResNet18().to(device
)
# model = PreActResNet18().to(device
)
# model = GoogLeNet().to(device
)
# model = DenseNet121().to(device
)
# model = ResNeXt29_2x64d().to(device
)
# model = MobileNet().to(device
)
# model = MobileNetV2().to(device
)
# model = DPN92().to(device
)
# model = ShuffleNetG2().to(device
)
# model = SENet18().to(device
)
# model = ShuffleNetV2(1).to(device
)
# model = EfficientNetB0().to(device
)
# model = RegNetX_200MF().to(device)
今はこれを使っている
他のモデルも試して見ましょう
46.
参考文献
Learning PyTorch withExample
s
https://pytorch.org/tutorials/beginner/pytorch_with_examples.html
PyTorch Examples githu
b
https://github.com/pytorch/examples
PyTorch Tutorial githu
b
https://github.com/yunjey/pytorch-tutorial
Understanding PyTorch with an example: a step-by-step tutorial by Daniel Godo
y
https://towardsdatascience.com/understanding-pytorch-with-an-example-a-step-by-step-tutorial-81fc5f8c4e8e
Practical Deep Learning for Coders, v3 by fast.a
i
https://course.fast.ai
PyTorch by Beeren Sah
u
https://beerensahu.wordpress.com/2018/03/21/pytorch-tutorial-lesson-1-tensor/
Writing Distributed Applications with PyTorch by Séb Arnol
d
https://pytorch.org/tutorials/intermediate/dist_tuto.html



![畳み込みニューラルネット
https://cs231n.github.io/convolutional-networks/
[入出力テンソルの次元
]
N: バッチサイズ
C: チャネル数
H: 画像の高さ
W: 画像の幅
[畳み込みのパラメータ
]
F: フィルタの大きさ
P: パディングの幅
S: ストライド
入力チャネル3,出力チャネル2の例
[入力
]
N:
1
Cin:
3
Hin:
5
Win: 5
[出力
]
N:
1
Cout:
2
Hout:
3
Wout: 3
F:
3
P:
1
S: 2
GEMM
Winograd
入力画像
フィルタ
入力画像
フィルタ
出力画像
batched GEMM
FFT
http://cs231n.stanford.edu/reports/2016/pdfs/117_Report.pdf
https://arxiv.org/abs/1410.0759
https://www.slideshare.net/nervanasys/an-analysis-of-convolution-for-inference](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-9-320.jpg)
![正則化 (regularization)
<latexit sha1_base64="PTOETKQJ9sDV108G8utVEdMYksY=">AAACGnicbVDLSsNAFJ34rPUVdSnIYBHcWJIi6kYounHhooJ9QBPLzWTaDp08mJkIJWTnZ/gFbvUL3IlbN36A/+Gk7cK2Hhg4nHMv98zxYs6ksqxvY2FxaXlltbBWXN/Y3No2d3YbMkoEoXUS8Ui0PJCUs5DWFVOctmJBIfA4bXqD69xvPlIhWRTeq2FM3QB6IesyAkpLHfPACUD1CfD0Nrt0ZBI8pD4oyE4cHvVw3DFLVtkaAc8Te0JKaIJax/xx/IgkAQ0V4SBl27Zi5aYgFCOcZkUnkTQGMoAebWsaQkClm47+keEjrfi4Gwn9QoVH6t+NFAIph4GnJ/PUctbLxf+8dqK6F27KwjhRNCTjQ92EYxXhvBTsM0GJ4kNNgAims2LSBwFE6eqmrvgyj5bpXuzZFuZJo1K2z8qVu9NS9WrSUAHto0N0jGx0jqroBtVQHRH0hF7QK3ozno1348P4HI8uGJOdPTQF4+sXt5uh/g==</latexit>
L =
data
X
log p
損失関数
https://arxiv.org/abs/2002.08709
L2正則化
<latexit sha1_base64="Yy8xPfnTLiqjWpL4JDjdct97CAw=">AAACJ3icbVDLSgMxFM34rPU16tJNsAhCscxUUTdC0Y0LFxXsAzq13MmkNTTzIMkIZTof4Wf4BW71C9yJLl34H2baLmz1QOBwzr259x434kwqy/o05uYXFpeWcyv51bX1jU1za7suw1gQWiMhD0XTBUk5C2hNMcVpMxIUfJfThtu/zPzGAxWShcGtGkS07UMvYF1GQGmpYxYdH9Q9AZ5cp+eOjP27xAMF6aHDwx6Oig7Xf3kwbAzvyh2zYJWsEfBfYk9IAU1Q7ZjfjheS2KeBIhykbNlWpNoJCMUIp2neiSWNgPShR1uaBuBT2U5GR6V4Xyse7oZCv0Dhkfq7IwFfyoHv6srsBDnrZeJ/XitW3bN2woIoVjQg40HdmGMV4iwh7DFBieIDTYAIpnfF5B4EEKVznJriyWy1VOdiz6bwl9TLJfukdHRzXKhcTBLKoV20hw6QjU5RBV2hKqohgh7RM3pBr8aT8Wa8Gx/j0jlj0rODpmB8/QDq3qdI</latexit>
L =
data
X
log p + |W|2
L1正則化
<latexit sha1_base64="qqFUGj5bRbXJTuGZgDLorSbuXL0=">AAACJXicbVDLSgMxFM3UV62vqks3wSIoYplRUTdC0Y0LFxXsAzq13MmkbWjmQZIRynS+wc/wC9zqF7gTwZUr/8NM24VtPRA4nHNv7r3HCTmTyjS/jMzc/MLiUnY5t7K6tr6R39yqyiAShFZIwANRd0BSznxaUUxxWg8FBc/htOb0rlO/9kiFZIF/r/ohbXrQ8VmbEVBaauUPbA9UlwCPb5NLW0beQ+yCguTI5kEHh4c213+5MKgNWvmCWTSHwLPEGpMCGqPcyv/YbkAij/qKcJCyYZmhasYgFCOcJjk7kjQE0oMObWjqg0dlMx6elOA9rbi4HQj9fIWH6t+OGDwp+56jK9MD5LSXiv95jUi1L5ox88NIUZ+MBrUjjlWA03ywywQlivc1ASKY3hWTLgggSqc4McWV6WqJzsWaTmGWVI+L1lnx5O60ULoaJ5RFO2gX7SMLnaMSukFlVEEEPaEX9IrejGfj3fgwPkelGWPcs40mYHz/AprfpqQ=</latexit>
L =
data
X
log p + |W|
Sharpness Aware Minimization (SAM)
Flooding
<latexit sha1_base64="+29JRp4dO+SSQAn2+lrjhc+5WsE=">AAACIHicbVDLSgMxFM34rPVVdekmWAVBWmZU1I1QdOPCRQX7gE4tdzJpG5p5kGSEMp0f8DP8Arf6Be7Epe79DzNtF7b1QOBwzr3ck+OEnEllml/G3PzC4tJyZiW7ura+sZnb2q7KIBKEVkjAA1F3QFLOfFpRTHFaDwUFz+G05vSuU7/2SIVkgX+v+iFtetDxWZsRUFpq5fZtD1SXAI9vk0tbRt5D7IKCZFCwedDBYcEZHDmtXN4smkPgWWKNSR6NUW7lfmw3IJFHfUU4SNmwzFA1YxCKEU6TrB1JGgLpQYc2NPXBo7IZD3+T4AOtuLgdCP18hYfq340YPCn7nqMn0+xy2kvF/7xGpNoXzZj5YaSoT0aH2hHHKsBpNdhlghLF+5oAEUxnxaQLAojSBU5ccWUaLdG9WNMtzJLqcdE6K57cneZLV+OGMmgX7aFDZKFzVEI3qIwqiKAn9IJe0ZvxbLwbH8bnaHTOGO/soAkY378ypqRP</latexit>
L =
data
X
| log p b| + b
<latexit sha1_base64="9vmQ2Pyai29yDGuUrPziv2Rg5HE=">AAACPnicbVBNSxxBEO0xfn+uydFL4yIo4jKjol6EZb3kkIOBrCvsjEtNT+1uY0/30N0jLsP8n/yM/IJcE39AvEmuOaZnXcGvBwWP96qoqhdnghvr+3fe1Ifpmdm5+YXFpeWV1bXa+scLo3LNsM2UUPoyBoOCS2xbbgVeZhohjQV24uuzyu/coDZcyW92lGGUwkDyPmdgndSrtcIU7JCBKL6Up6HJ06siAQulk297RYiZ4ULJUGCoh6rs7oVCDWi23dl9snaiXq3uN/wx6FsSTEidTHDeq/0JE8XyFKVlAozpBn5mowK05UxguRjmBjNg1zDArqMSUjRRMf61pFtOSWhfaVfS0rH6fKKA1JhRGrvO6jPz2qvE97xubvsnUcFllluU7HFRPxfUKloFRxOukVkxcgSY5u5WyoaggVkX74stialOK10uwesU3pKL/UZw1Dj4elhvtiYJzZMNskm2SUCOSZN8JuekTRj5Tn6SX+S398O79x68v4+tU95k5hN5Ae/ff/ElsWk=</latexit>
L =
data
X
max
✏⇢
[ log p(W + ✏)]
https://arxiv.org/abs/2010.01412
Dropout
https://arxiv.org/abs/1603.09382
Stochastic depth](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-12-320.jpg)

![NumPyだけによる実装
import numpy as n
p
epochs = 30
0
batch_size = 3
2
D_in = 78
4
H = 10
0
D_out = 1
0
learning_rate = 1.0e-0
6
# create random input and output dat
a
x = np.random.randn(batch_size, D_in
)
y = np.random.randn(batch_size, D_out
)
# randomly initialize weight
s
w1 = np.random.randn(D_in, H
)
w2 = np.random.randn(H, D_out
)
for epoch in range(epochs)
:
# forward pas
s
h = x.dot(w1) # h = x * w
1
h_r = np.maximum(h, 0) # h_r = ReLU(h
)
y_p = h_r.dot(w2) # y_p = h_r * w
2
# compute mean squared error and print los
s
loss = np.square(y_p - y).sum()
print(epoch, loss
)
# backward pass: compute gradients of loss with respect to w
2
grad_y_p = 2.0 * (y_p - y)
grad_w2 = h_r.T.dot(grad_y_p)
# backward pass: compute gradients of loss with respect to w
1
grad_h_r = grad_y_p.dot(w2.T)
grad_h = grad_h_r.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# update weight
s
w1 -= learning_rate * grad_w
1
w2 -= learning_rate * grad_w2
w1 w1 ⌘
@L
@w1
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
<latexit sha1_base64="kN3sQo8OP8glKG68w4PsUtC/f3k=">AAACMXicbVDLSgNBEJyN73fUo5fBIHgx7IqiR9GLBw8RjArZEHonvcmQ2QczvYaw5Ev8DL/Aq35BbiJ48iecjQGfDQM1VdXTPRWkShpy3ZFTmpqemZ2bX1hcWl5ZXSuvb1ybJNMC6yJRib4NwKCSMdZJksLbVCNEgcKboHdW6Dd3qI1M4isapNiMoBPLUAogS7XKh/2W5ysMCbRO+tze9nwk8EMNIvdT0CRB8YvhF7aWYatccavuuPhf4E1AhU2q1iq/+e1EZBHGJBQY0/DclJp58aRQOFz0M4MpiB50sGFhDBGaZj7+3pDvWKbNw0TbExMfs987coiMGUSBdUZAXfNbK8j/tEZG4XEzl3GaEcbic1CYKU4JL7LibalRkBpYAEJLuysXXbDJkE30x5S2KVYrcvF+p/AXXO9XPbfqXR5UTk4nCc2zLbbNdpnHjtgJO2c1VmeC3bNH9sSenQdn5Lw4r5/WkjPp2WQ/ynn/AO/Rq1o=</latexit>
w2 w2 ⌘
@L
@w2
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
<latexit sha1_base64="XDVYNpwB7UZogd7iSX6oklwpHpw=">AAACMXicbVDLSgNBEJz1bXxFPXoZDIIXw64oehS9ePAQwZhANoTeSa8Ozj6Y6TWEJV/iZ/gFXvULchPBkz/hbAz4iA0DNVXV0z0VpEoact2hMzU9Mzs3v7BYWlpeWV0rr29cmyTTAusiUYluBmBQyRjrJElhM9UIUaCwEdydFXrjHrWRSXxF/RTbEdzEMpQCyFKd8mGvs+8rDAm0Tnrc3vZ8JPBDDSL3U9AkQfGLwTe2lkGnXHGr7qj4JPDGoMLGVeuU3/1uIrIIYxIKjGl5bkrtvHhSKByU/MxgCuIObrBlYQwRmnY++t6A71imy8NE2xMTH7E/O3KIjOlHgXVGQLfmr1aQ/2mtjMLjdi7jNCOMxdegMFOcEl5kxbtSoyDVtwCElnZXLm7BJkM20V9TuqZYrcjF+5vCJLjer3pu1bs8qJycjhNaYFtsm+0yjx2xE3bOaqzOBHtgT+yZvTiPztB5dd6+rFPOuGeT/Srn4xP07atd</latexit>
@L
@w2
=
@L
@yp
@yp
@w2
=
1
NO
2 (yp y) hr
@L
@w1
=
@L
@yp
@yp
@hr
@hr
@w1
=
1
NO
2 (yp y) w2x
L =
1
NO
X
(yp y)
2
00_numpy.py](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-23-320.jpg)
![PyTorch の導入
import torc
h
epochs = 30
0
batch_size = 3
2
D_in = 78
4
H = 10
0
D_out = 1
0
learning_rate = 1.0e-0
6
# create random input and output dat
a
x = torch.randn(batch_size, D_in
)
y = torch.randn(batch_size, D_out
)
# randomly initialize weight
s
w1 = torch.randn(D_in, H
)
w2 = torch.randn(H, D_out
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2
)
# compute and print los
s
loss = (y_p - y).pow(2).sum().item(
)
print(t, loss
)
# backward pass: compute gradients of loss with respect to w
2
grad_y_p = 2.0 * (y_p - y
)
grad_w2 = h_r.t().mm(grad_y_p
)
# backward pass: compute gradients of loss with respect to w
1
grad_h_r = grad_y_p.mm(w2.t()
)
grad_h = grad_h_r.clone(
)
grad_h[h < 0] =
0
grad_w1 = x.t().mm(grad_h
)
# update weight
s
w1 -= learning_rate * grad_w
1
w2 -= learning_rate * grad_w2
np.random torch
np torch
x.dot(w1) x.mm(w1)
np.maximum(h, 0) h.clamp(min=0)
np.square(y_p-y) (y_p-y).pow(2)
copy() clone()
01_tensors.py](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-24-320.jpg)
![自動微分の導入
# randomly initialize weight
s
w1 = torch.randn(D_in, H
)
w2 = torch.randn(H, D_out
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2
)
# compute and print los
s
loss = (y_p - y).pow(2).sum().item(
)
print(t, loss
)
# backward pass: compute gradients of loss
with respect to w
2
grad_y_p = 2.0 * (y_p - y
)
grad_w2 = h_r.t().mm(grad_y_p
)
# backward pass: compute gradients of loss
with respect to w
1
grad_h_r = grad_y_p.mm(w2.t()
)
grad_h = grad_h_r.clone(
)
grad_h[h < 0] =
0
grad_w1 = x.t().mm(grad_h
)
# update weight
s
w1 -= learning_rate * grad_w
1
w2 -= learning_rate * grad_w2
01_tensor.py 02_autograd.py
# randomly initialize weight
s
w1 = torch.randn(D_in, H, requires_grad=True
)
w2 = torch.randn(H, D_out, requires_grad=True
)
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2
)
# compute and print los
s
loss = (y_p - y).pow(2).sum(
)
print(t, loss.item()
)
# backward pas
s
loss.backward(
)
with torch.no_grad()
:
# update weight
s
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# initialize weight
s
w1.grad.zero_(
)
w2.grad.zero_()
@L
@w1
=
@L
@yp
@yp
@hr
@hr
@w1
=
1
NO
2(yp y)w2x
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
<latexit sha1_base64="V1OkoDW7pmfxcKKULrjvVELuV8s=">AAACmHicfVHdSsMwGE3r//ybeqc3wSHMC0dTBL0Rhl6oIDrFqbCNkmbpFkx/SFJnKX0TX8wH8D1Mt8JcFT8InJzzfTkfJ27EmVSW9WmYc/MLi0vLK5XVtfWNzerW9pMMY0Fom4Q8FC8ulpSzgLYVU5y+RIJi3+X02X29yPXnNyokC4NHlUS05+NBwDxGsNKUU/3oegKTtBthoRjm8Cab4pGDsrN/9MSJspKcU9Pb0BHlhpyadagUFihLb527zK7rN46Sw5FjvzvVmtWwxgV/A1SAGiiq5VS/uv2QxD4NFOFYyg6yItVLczfCaVbpxpJGmLziAe1oGGCfyl46TjGDB5rpQy8U+gQKjtmfEyn2pUx8V3f6WA1lWcvJv7ROrLzTXsqCKFY0IBMjL+ZQhTD/EthnghLFEw0wEUzvCskQ60yU/rgZl77MV8t0Lqicwm/wZDeQ1UD3x7XmeZHQMtgD+6AOEDgBTXAFWqANiGEadQMZtrlrNs1L83rSahrFzA6YKfPhG92OzlM=</latexit>
微分を自動的に計算してくれる](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-25-320.jpg)
![活性化関数の自作 03_function.py
import torc
h
for epoch in range(epochs)
:
# forward pass: compute predicted
y
h = x.mm(w1
)
h_r = h.clamp(min=0
)
y_p = h_r.mm(w2)
02_autograd.py
import torc
h
class ReLU(torch.autograd.Function)
:
@staticmetho
d
def forward(ctx, input)
:
ctx.save_for_backward(input
)
return input.clamp(min=0
)
@staticmetho
d
def backward(ctx, grad_output)
:
input, = ctx.saved_tensor
s
grad_input = grad_output.clone(
)
grad_input[input<0] =
0
return grad_inpu
t
for epoch in range(epochs)
:
# forward pass: compute predicted
y
relu = ReLU.appl
y
h = x.mm(w1
)
h_r = relu(h
)
y_p = h_r.mm(w2)
.
.
.
.
.
.
y=f(x)
ReLU (Recti
fi
ed Linear Unit)](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-26-320.jpg)




![Validationデータによる検証
08_validate.py
def validate()
:
model.eval(
)
val_loss, val_acc = 0,
0
for data, target in val_loader
:
output = model(data
)
loss = criterion(output, target
)
val_loss += loss.item()
pred = output.data.max(1)[1
]
val_acc += 100. * pred.eq(target.data).cpu().sum() / target.size(0)
val_loss /= len(val_loader
)
val_acc /= len(val_loader
)
print('nValidation set: Average loss: {:.4f}, Accuracy: {:.1f}%n'.format
(
val_loss, val_acc))
学習時に使うデータ
ハイパラやモデル
を変えて試すとき
に使うデータ
最終的な精度の評価
に使うデータ
Validation dataのloss
予測クラスがラベルと一致しているか?
パーセンテージに変換
sum()はGPUでやると遅いのでCPUで](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-31-320.jpg)
![train(), main()関数の形で書く
09_train.py
def train(train_loader,model,criterion,optimizer,epoch)
:
model.train(
)
t = time.perf_counter(
)
for batch_idx, (data, target) in enumerate(train_loader)
:
output = model(data
)
loss = criterion(output, target
)
optimizer.zero_grad(
)
loss.backward(
)
optimizer.step(
)
if batch_idx % 200 == 0
:
print('Train Epoch: {} [{:>5}/{} ({:.0%})]tLoss: {:.6f}t Time:{:.4f}'.format
(
epoch, batch_idx * len(data), len(train_loader.dataset)
,
batch_idx / len(train_loader), loss.data.item()
,
time.perf_counter() - t)
)
t = time.perf_counter()
def main()
:
epochs = 1
0
batch_size = 3
2
learning_rate = 1.0e-0
2
train_dataset = datasets.MNIST('./data'
,
train=True
,
download=True
,
transform=transforms.ToTensor()
)
val_dataset = datasets.MNIST('./data'
,
train=False
,
transform=transforms.ToTensor()
)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset
,
batch_size=batch_size
,
shuffle=True
)
val_loader = torch.utils.data.DataLoader(dataset=validation_dataset
,
batch_size=batch_size
,
shuffle=False
)
model = TwoLayerNet(D_in, H, D_out
)
criterion = nn.CrossEntropyLoss(
)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate
)
for epoch in range(epochs)
:
model.train(
)
train(train_loader,model,criterion,optimizer,epoch
)
validate(val_loader,model,criterion
)](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-32-320.jpg)
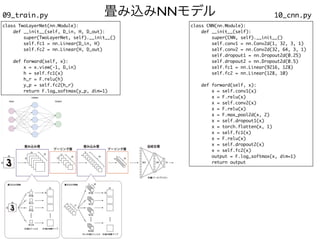

![分散並列
12_distributed.py
import o
s
import torc
h
import torch.distributed as dis
t
master_addr = os.getenv("MASTER_ADDR", default="localhost"
)
master_port = os.getenv('MASTER_PORT', default='8888'
)
method = "tcp://{}:{}".format(master_addr, master_port
)
rank = int(os.getenv('OMPI_COMM_WORLD_RANK', '0')
)
world_size = int(os.getenv('OMPI_COMM_WORLD_SIZE', '1')
)
dist.init_process_group("nccl", init_method=method, rank=rank, world_size=world_size
)
print('Rank: {}, Size: {}'.format(dist.get_rank(),dist.get_world_size())
)
ngpus =
4
device = rank % ngpu
s
x = torch.randn(1).to(device
)
print('rank {}: {}'.format(rank, x)
)
dist.broadcast(x, src=0
)
print('rank {}: {}'.format(rank, x))
通信に用いるホストアドレスとポート番号を指定
OpenMPI環境変数からrankとsizeを取得
PyTorchにこれらを設定
PyTorchによる集団通信
.bashrcに以下を記入
if [ -f "$SGE_JOB_SPOOL_DIR/pe_hostfile" ]; the
n
export MASTER_ADDR=`head -n 1 $SGE_JOB_SPOOL_DIR/pe_hostfile | cut -d " " -f 1
`
f
i
mpirun -np 4 python 12_distributed.py](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-35-320.jpg)
![分散並列MNIST
13_ddp.py
def print0(message)
:
if torch.distributed.is_initialized()
:
if torch.distributed.get_rank() == 0
:
print(message, flush=True
)
else
:
print(message, flush=True
)
train_sampler = torch.utils.data.distributed.DistributedSampler
(
train_dataset
,
num_replicas=torch.distributed.get_world_size()
,
rank=torch.distributed.get_rank()
)
model = DDP(model, device_ids=[rank])
.
.
.
.
.
.
全プロセスがprintすると見づらいので1プロセスだけprintするようなprint関数を定義
train dataの読み込みで異なるプロセスが異なるデータを読むようにする
モデルをDDP()に通すことで分散並列計算を行う](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-36-320.jpg)


![ProgressMeter
15_meter.py
def train(train_loader,model,criterion,optimizer,epoch,device)
:
batch_time = AverageMeter('Time', ':.4f'
)
train_loss = AverageMeter('Loss', ‘:.6f'
)
progress = ProgressMeter
(
len(train_loader)
,
[train_loss, batch_time]
,
prefix="Epoch: [{}]".format(epoch))
class ProgressMeter(object)
:
def __init__(self, num_batches, meters, prefix="", postfix="")
:
self.batch_fmtstr = self._get_batch_fmtstr(num_batches
)
self.meters = meters
self.prefix = prefix
self.postfix = postfix
def display(self, batch)
:
entries = [self.prefix + self.batch_fmtstr.format(batch)
]
entries += [str(meter) for meter in self.meters
]
entries += self.postfi
x
print0('t'.join(entries)
)
def _get_batch_fmtstr(self, num_batches)
:
num_digits = len(str(num_batches // 1)
)
fmt = '{:' + str(num_digits) + 'd}
'
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
前にprintするもの
後にprintするもの
printしたい変数
printしたいものを連結
[ 今のbatch / 全batch数 ] のような表示をしたい](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-39-320.jpg)
![Weights and Biases
pip install wand
b
wandb login
import wand
b
os.environ['MASTER_ADDR'] = 'localhost
'
os.environ['MASTER_PORT'] = '8888
'
rank = int(os.getenv('OMPI_COMM_WORLD_RANK', '0')
)
world_size = int(os.getenv('OMPI_COMM_WORLD_SIZE', '1')
)
dist.init_process_group("nccl", rank=rank, world_size=world_size
)
device = torch.device('cuda',rank
)
if torch.distributed.get_rank() == 0
:
wandb.init(project="example-project"
)
wandb.config.update(args
)
epochs = args.epoch
s
batch_size = args.batch_siz
e
learning_rate = args.lr * world_size
for epoch in range(epochs)
:
model.train(
)
train_loss, train_acc = train(train_loader,model,criterion,optimizer,epoch,device
)
val_loss, val_acc = validate(val_loader,model,criterion,device
)
if torch.distributed.get_rank() == 0
:
wandb.log(
{
'train_loss': train_loss
,
'train_acc': train_acc
,
'val_loss': val_loss
,
'val_acc': val_ac
c
})
wandbで記録したい変数
trainとvalidateがlossとaccuracyを返すようにする
wandbの初期化
argsを渡すと実験条件を勝手に記録してくれる
16_wandb.py](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-40-320.jpg)
![train_dataset = datasets.CIFAR10('./data'
,
train=True
,
download=True
,
transform=transforms.ToTensor()
)
val_dataset = datasets.CIFAR10('./data'
,
train=False
,
download=True
,
transform=transforms.ToTensor())
CIFAR10
17_cifar10.py
model = VGG('VGG19').to(device
)
model = DDP(model, device_ids=[rank % 4]
)
criterion = nn.CrossEntropyLoss(
)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
データセットの変更
モデルの変更](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-41-320.jpg)
![transform_train = transforms.Compose(
[
transforms.RandomCrop(32, padding=4)
,
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
,
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]
)
transform_val = transforms.Compose(
[
transforms.ToTensor()
,
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
,
])
データ拡張
18_augmentation.py
輝度値の正規化](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-42-320.jpg)
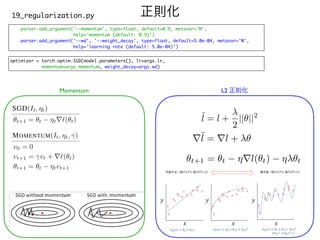
![Sweep
sweep.yaml
program: wrapper.p
y
method: gri
d
metric
:
goal: minimiz
e
name: val_los
s
parameters
:
epochs
:
values: [100
]
batch_size
:
values: [32
]
learning_rate
:
values: [0.005, 0.01, 0.02, 0.05, 0.1
]
momentum
:
values: [0.85, 0.9, 0.95
]
weight_decay
:
values: [1.0e-4, 2.0e-4, 5.0e-4, 1.0e-3, 2.0e-3]
wandb sweep sweep.yaml](https://image.slidesharecdn.com/0715yokota-210713015433/85/14-A-2021-44-320.jpg)













![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]自動運転技術の課題に役立つかもしれない論文3本](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20210507-210507031422-thumbnail.jpg?width=640&height=640&fit=bounds)















































