Download as PDF, PPTX















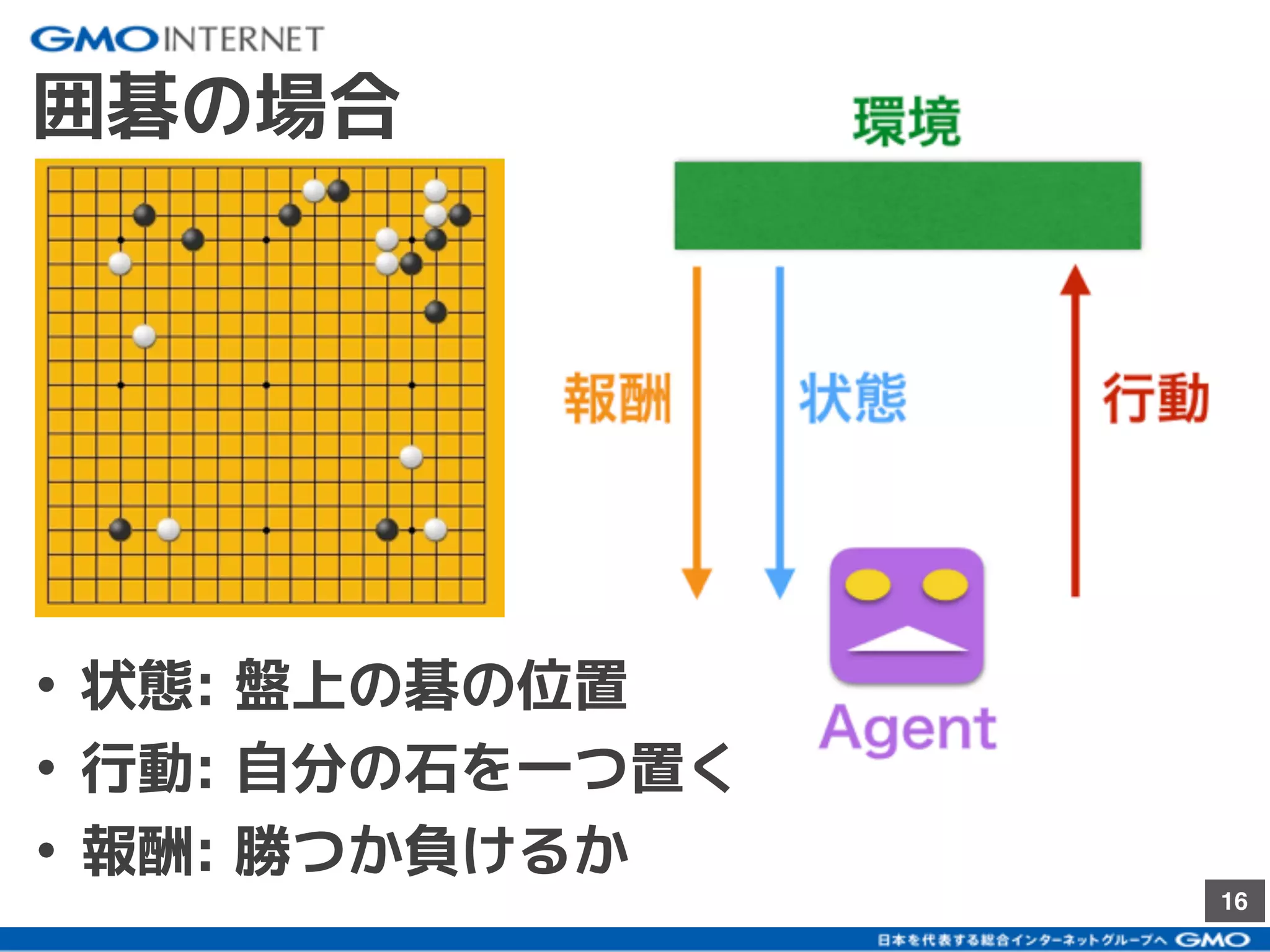



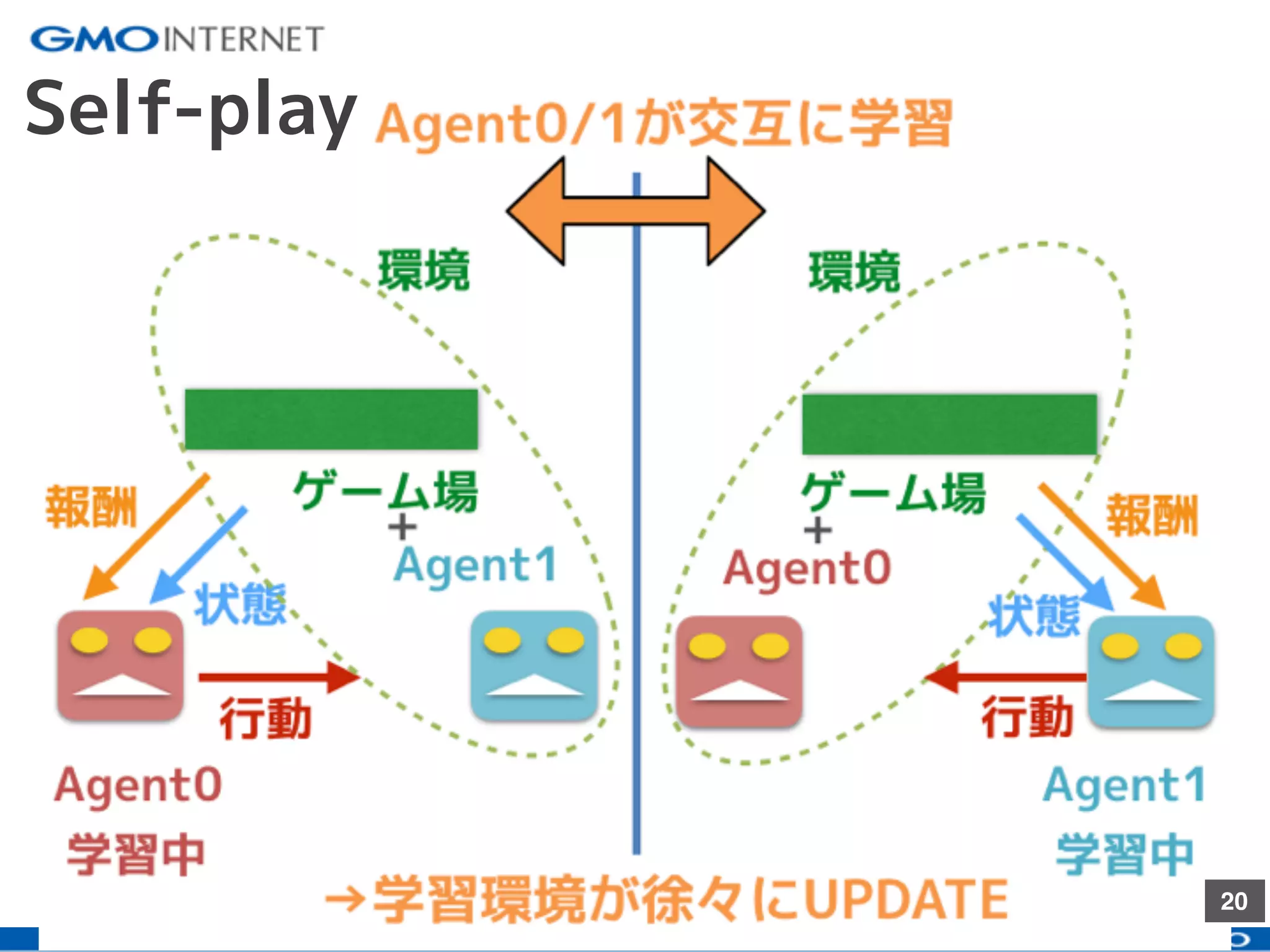


















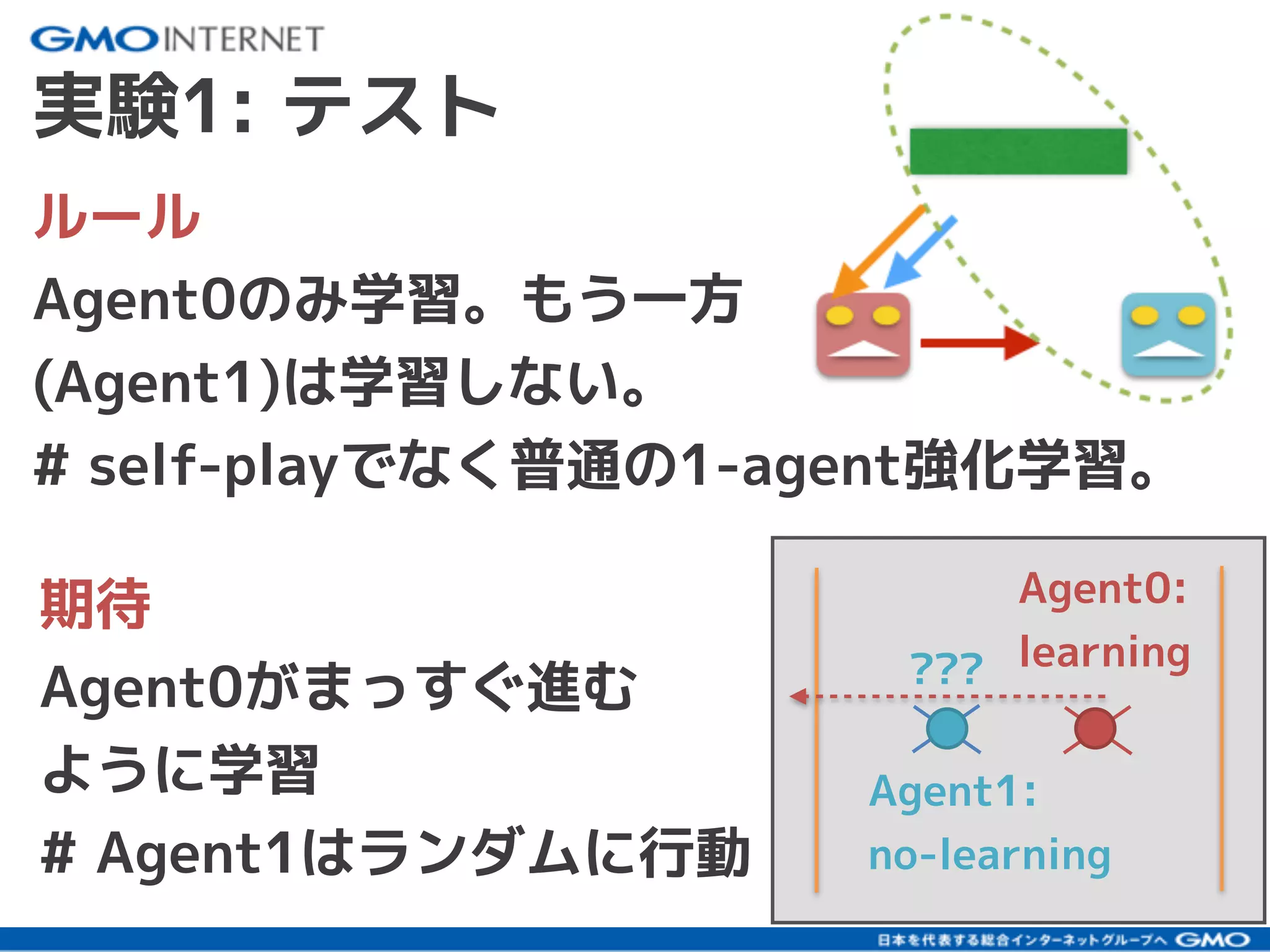
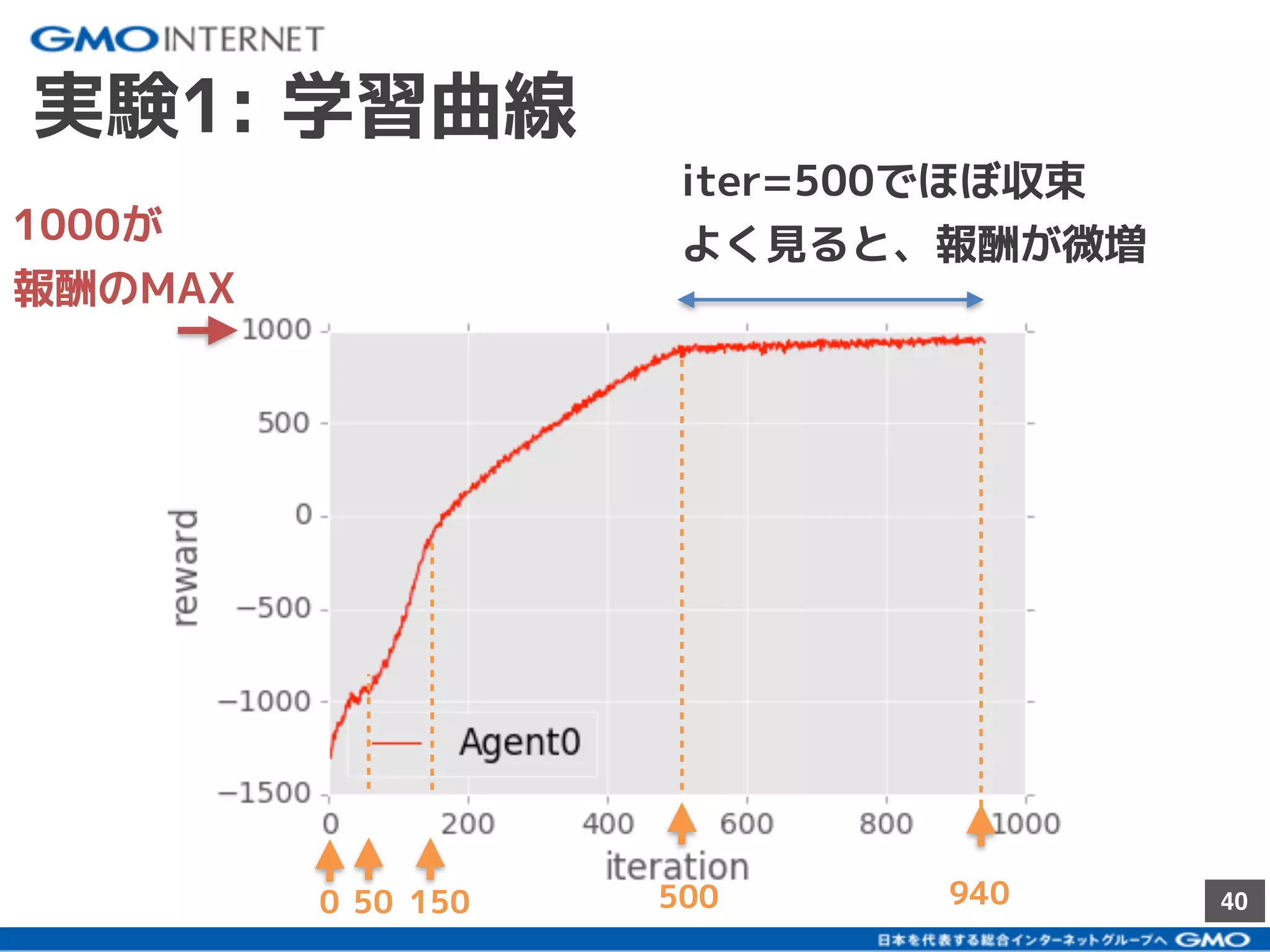



















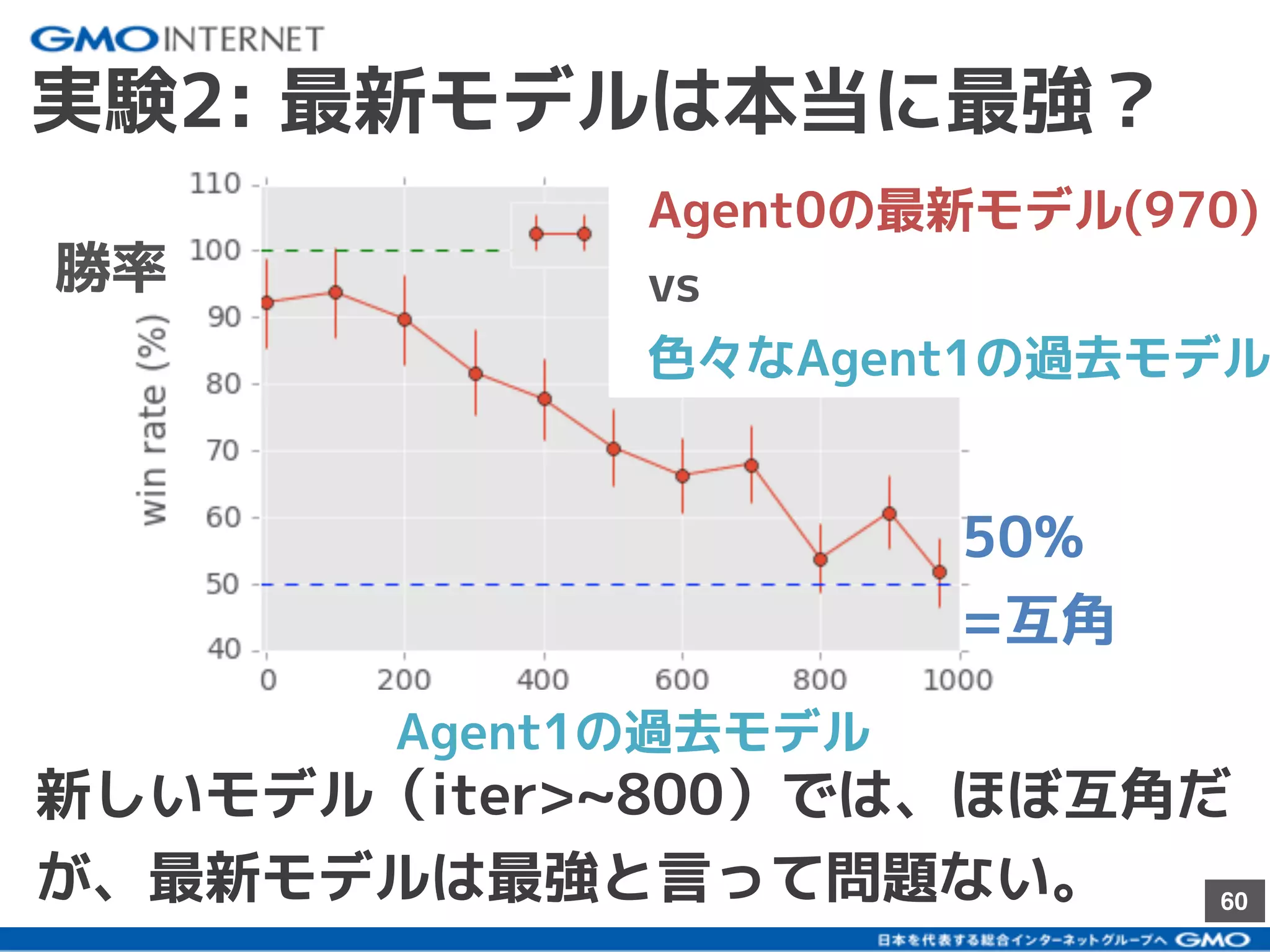



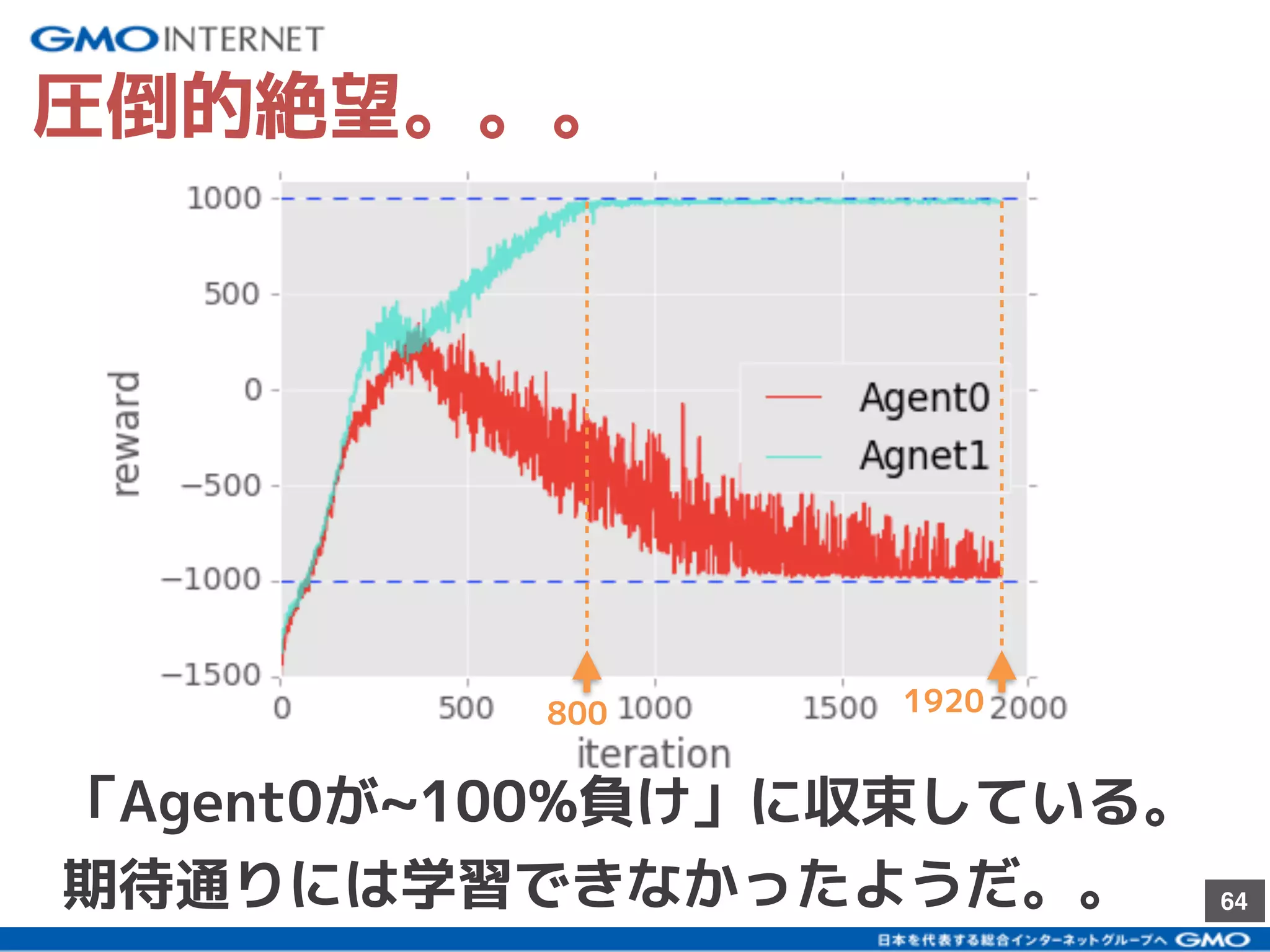






















社内向けに発表した研究会のスライドです。ハイライト版が以下のブログです。 「深層強化学習のself-playで遊んでみた」:https://recruit.gmo.jp/engineer/jisedai/blog/self-play/ 結果のアニメーションが以下のgithubにあります。 https://github.com/jkatsuta/17_4q_supplement 2017/10に発表されたBansal+17を参考に、深層強化学習のself-playを使って、2体のAgentを戦わせることで複雑な行動の学習を試みた結果について話しました。論文にはない初期位置などでも学習をさせて、どのように変化するかの考察などもしました。








![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete...](https://cdn.slidesharecdn.com/ss_thumbnails/20200904furuta-200904014839-thumbnail.jpg?width=640&height=640&fit=bounds)



![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/model-basedreinforcementlearningviameta-policyoptimization-190705000247-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Mastering the Dungeon: Grounded Language Learning by Mechanical Turker...](https://cdn.slidesharecdn.com/ss_thumbnails/180126groundedlanguagelearningbymechanicalturkerdecent1-180126004830-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning to Reach Goals via Iterated Supervised Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20210319zhangxin-210319022919-thumbnail.jpg?width=640&height=640&fit=bounds)