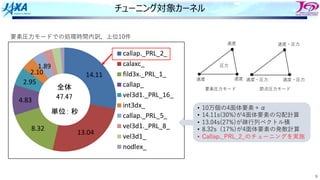
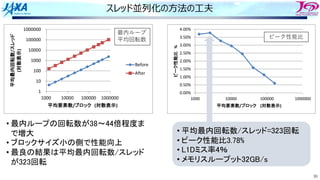
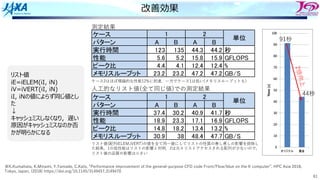
30
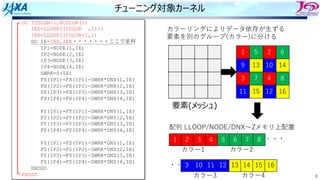
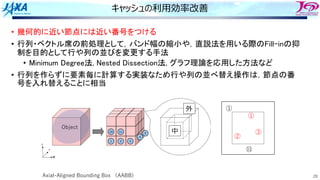
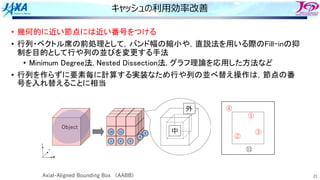
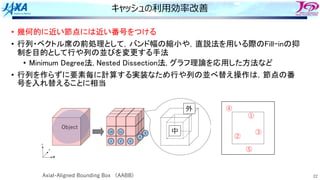
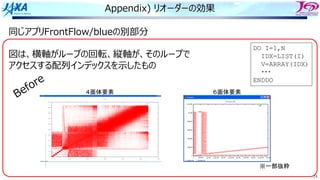
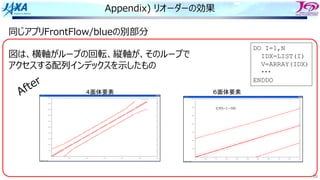
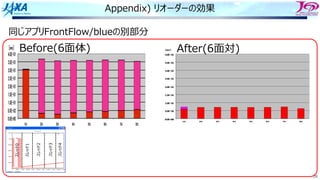
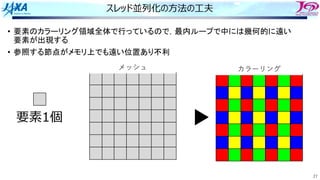
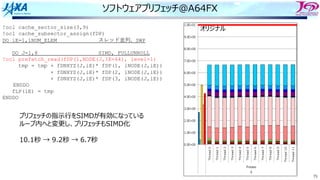
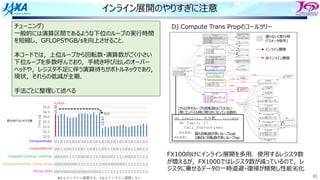
スレッド並列化の⽅法の⼯夫
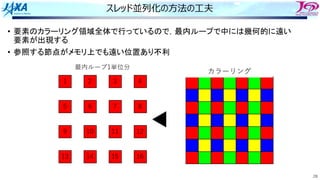
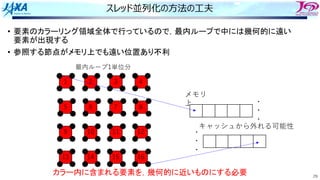
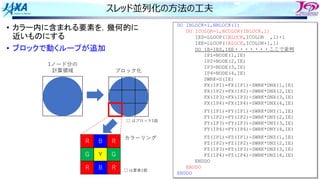
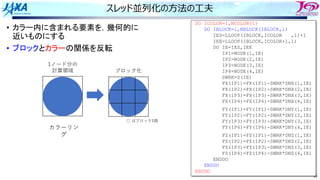
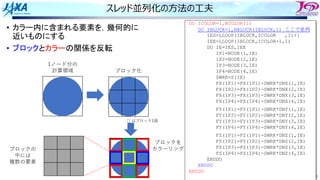
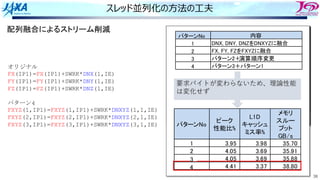
• カラー内に含まれる要素を,幾何的に
近いものにする
• ブロックで動くループが追加
DOIBLOCK=1,NBLOCK(1)
DO ICOLOR=1,NCOLOR(IBLOCK,1)
IES=LLOOP(IBLOCK,ICOLOR ,1)+1
IEE=LLOOP(IBLOCK,ICOLOR+1,1)
DO IE=IES,IEE・・・・・・・ここで並列
IP1=NODE(1,IE)
IP2=NODE(2,IE)
IP3=NODE(3,IE)
IP4=NODE(4,IE)
SWRK=S(IE)
FX(IP1)=FX(IP1)-SWRK*DNX(1,IE)
FX(IP2)=FX(IP2)-SWRK*DNX(2,IE)
FX(IP3)=FX(IP3)-SWRK*DNX(3,IE)
FX(IP4)=FX(IP4)-SWRK*DNX(4,IE)
FY(IP1)=FY(IP1)-SWRK*DNY(1,IE)
FY(IP2)=FY(IP2)-SWRK*DNY(2,IE)
FY(IP3)=FY(IP3)-SWRK*DNY(3,IE)
FY(IP4)=FY(IP4)-SWRK*DNY(4,IE)
FZ(IP1)=FZ(IP1)-SWRK*DNZ(1,IE)
FZ(IP2)=FZ(IP2)-SWRK*DNZ(2,IE)
FZ(IP3)=FZ(IP3)-SWRK*DNZ(3,IE)
FZ(IP4)=FZ(IP4)-SWRK*DNZ(4,IE)
ENDDO
ENDDO
ENDDO
1ノード分の
計算領域
R B R
R B R
G Y G
カラーリング
□ は要素1個
□ はブロック1個
ブロック化
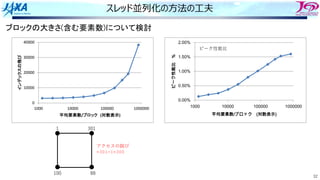
43
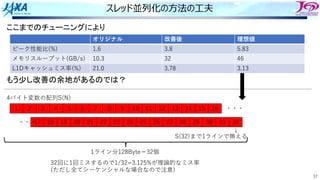
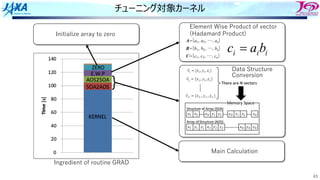
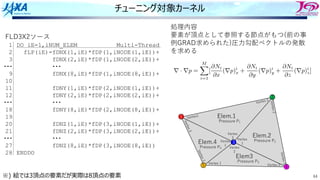
チューニング対象カーネル
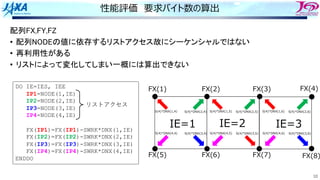
Ingredient of routineGRAD
Initialize array to zero
Element Wise Product of vector
(Hadamard Product)
i
i
i b
a
c =
Data Structure
Conversion
Main Calculation
A={a1, a2, …, an}
B={b1, b2, …, bn}
C={c1, c2, …, cn}
44.
44
節点5 3
Elem.1
Pressure P1
Elem.2
PressureP2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
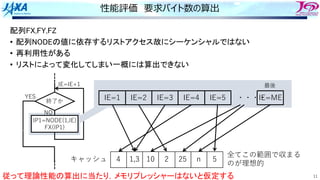
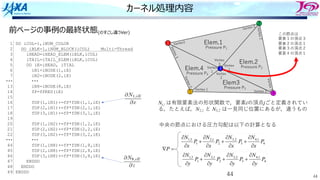
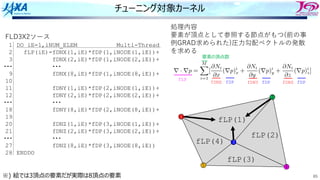
カーネル処理内容
44
DO iCOL=1,iNUM_COLOR
DO iBLK=1,iNUM_BLOCK(iCOL) Multi-Thread
iHEAD=iHEAD_ELEM(iBLK,iCOL)
iTAIL=iTAIL_ELEM(iBLK,iCOL)
DO iE=iHEAD, iTIAL
iN1=iNODE(1,iE)
iN2=iNODE(2,iE)
・・・
iN8=iNODE(8,iE)
fP=fPRES(iE)
fDP(1,iN1)+=fP*fDN(1,1,iE)
fDP(2,iN1)+=fP*fDN(2,1,iE)
fDP(3,iN1)+=fP*fDN(3,1,iE)
fDP(1,iN2)+=fP*fDN(1,2,iE)
fDP(2,iN2)+=fP*fDN(2,2,iE)
fDP(3,iN2)+=fP*fDN(3,2,iE)
・・・
fDP(1,iN8)+=fP*fDN(1,8,iE)
fDP(2,iN8)+=fP*fDN(2,8,iE)
fDP(3,iN8)+=fP*fDN(3,8,iE)
ENDDO
ENDDO
ENDDO
1
2
3
4
5
6
7
・・・
13
14
15
16
17
18
19
20
21
22
・・・
44
45
46
47
48
49
この節点は
要素1の頂点3
要素2の頂点1
要素3の頂点2
要素4の頂点1
中央の節点における圧⼒勾配は以下の計算となる
Ni,j は有限要素法の形状関数で,要素iの頂点jごと定義されてい
る,たとえば,N3,1 と N4,2 は⼀⾒同じ位置にあるが,違うもの
前ページの事例の最終状態(のすこし違うVer)
45.
45
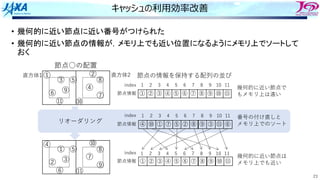
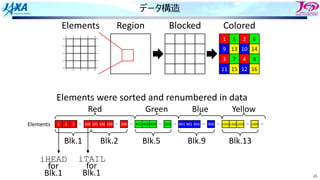
データ構造
Region
1 5 26
9 13 10 14
3 7 4 8
11 15 12 16
Colored
Elements
Elements were sorted and renumbered in data
Red
1 2 3 100
… 101 102 103 200
… 120112021203 1300
…
401 402 403 500
… 801 802 803 900
…
… … …
Green Blue Yellow
…
Blk.1 Blk.2 Blk.5 Blk.9 Blk.13
Blocked
iHEAD iTAIL
for
Blk.1
for
Blk.1
Elements
47
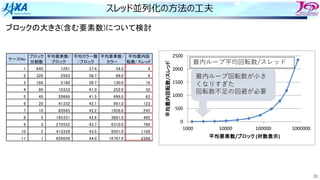
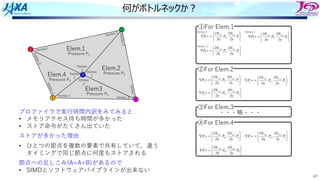
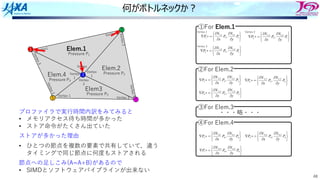
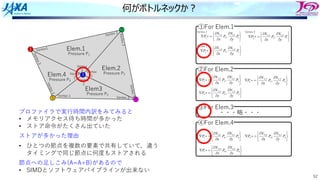
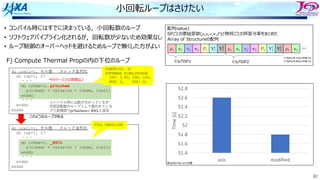
何がボトルネックか︖
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
1
,
1
1
1
,
1
1 ,P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
2
,
1
1
2
,
1
2 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
3
,
1
1
3
,
1
3 , P
y
N
P
x
N
P
Vertex 1
①For Elem.1
Vertex 2
Vertex 3
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
2
,
2
2
2
,
2
2 , P
y
N
P
x
N
P
②For Elem.2
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
1
,
2
2
1
,
2
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
3
,
2
2
3
,
2
4 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
2
,
4
4
2
,
4
5 , P
y
N
P
x
N
P
④For Elem.4
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
1
,
4
4
1
,
4
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
3
,
4
4
3
,
4
1 , P
y
N
P
x
N
P
③For Elem.3
・・・略・・・
プロファイラで実⾏時間内訳をみてみると
• メモリアクセス待ち時間が多かった
• ストア命令がたくさん出ていた
ストアが多かった理由
• ひとつの節点を複数の要素で共有していて,違う
タイミングで同じ節点に何度もストアされる
節点への⾜しこみ(A=A+B)があるので
• SIMDとソフトウェアパイプラインが出来ない
節点5 3
Elem.1
Pressure P1
Elem.2
Pressure P2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
48.
48
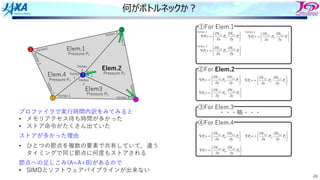
何がボトルネックか︖
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
1
,
1
1
1
,
1
1 ,P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
2
,
1
1
2
,
1
2 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
3
,
1
1
3
,
1
3 , P
y
N
P
x
N
P
Vertex 1
①For Elem.1
Vertex 2
Vertex 3
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
2
,
2
2
2
,
2
2 , P
y
N
P
x
N
P
②For Elem.2
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
1
,
2
2
1
,
2
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
3
,
2
2
3
,
2
4 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
2
,
4
4
2
,
4
5 , P
y
N
P
x
N
P
④For Elem.4
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
1
,
4
4
1
,
4
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
3
,
4
4
3
,
4
1 , P
y
N
P
x
N
P
③For Elem.3
・・・略・・・
節点5 3
Elem.1
Pressure P1
Elem.2
Pressure P2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
プロファイラで実⾏時間内訳をみてみると
• メモリアクセス待ち時間が多かった
• ストア命令がたくさん出ていた
ストアが多かった理由
• ひとつの節点を複数の要素で共有していて,違う
タイミングで同じ節点に何度もストアされる
節点への⾜しこみ(A=A+B)があるので
• SIMDとソフトウェアパイプラインが出来ない
49.
49
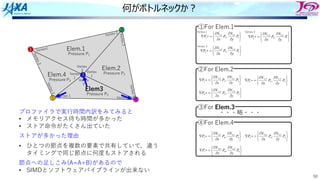
何がボトルネックか︖
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
1
,
1
1
1
,
1
1 ,P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
2
,
1
1
2
,
1
2 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
3
,
1
1
3
,
1
3 , P
y
N
P
x
N
P
Vertex 1
①For Elem.1
Vertex 2
Vertex 3
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
2
,
2
2
2
,
2
2 , P
y
N
P
x
N
P
②For Elem.2
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
1
,
2
2
1
,
2
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
3
,
2
2
3
,
2
4 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
2
,
4
4
2
,
4
5 , P
y
N
P
x
N
P
④For Elem.4
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
1
,
4
4
1
,
4
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
3
,
4
4
3
,
4
1 , P
y
N
P
x
N
P
③For Elem.3
・・・略・・・
節点5 3
Elem.1
Pressure P1
Elem.2
Pressure P2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
プロファイラで実⾏時間内訳をみてみると
• メモリアクセス待ち時間が多かった
• ストア命令がたくさん出ていた
ストアが多かった理由
• ひとつの節点を複数の要素で共有していて,違う
タイミングで同じ節点に何度もストアされる
節点への⾜しこみ(A=A+B)があるので
• SIMDとソフトウェアパイプラインが出来ない
50.
50
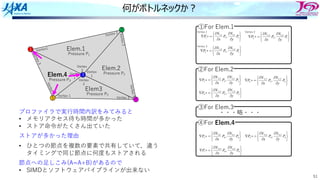
何がボトルネックか︖
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
1
,
1
1
1
,
1
1 ,P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
2
,
1
1
2
,
1
2 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
3
,
1
1
3
,
1
3 , P
y
N
P
x
N
P
Vertex 1
①For Elem.1
Vertex 2
Vertex 3
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
2
,
2
2
2
,
2
2 , P
y
N
P
x
N
P
②For Elem.2
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
1
,
2
2
1
,
2
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
3
,
2
2
3
,
2
4 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
2
,
4
4
2
,
4
5 , P
y
N
P
x
N
P
④For Elem.4
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
1
,
4
4
1
,
4
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
3
,
4
4
3
,
4
1 , P
y
N
P
x
N
P
③For Elem.3
・・・略・・・
節点5 3
Elem.1
Pressure P1
Elem.2
Pressure P2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
プロファイラで実⾏時間内訳をみてみると
• メモリアクセス待ち時間が多かった
• ストア命令がたくさん出ていた
ストアが多かった理由
• ひとつの節点を複数の要素で共有していて,違う
タイミングで同じ節点に何度もストアされる
節点への⾜しこみ(A=A+B)があるので
• SIMDとソフトウェアパイプラインが出来ない
51.
51
何がボトルネックか︖
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
1
,
1
1
1
,
1
1 ,P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
2
,
1
1
2
,
1
2 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
3
,
1
1
3
,
1
3 , P
y
N
P
x
N
P
Vertex 1
①For Elem.1
Vertex 2
Vertex 3
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
2
,
2
2
2
,
2
2 , P
y
N
P
x
N
P
②For Elem.2
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
1
,
2
2
1
,
2
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
3
,
2
2
3
,
2
4 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
2
,
4
4
2
,
4
5 , P
y
N
P
x
N
P
④For Elem.4
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
1
,
4
4
1
,
4
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
3
,
4
4
3
,
4
1 , P
y
N
P
x
N
P
③For Elem.3
・・・略・・・
節点5 3
Elem.1
Pressure P1
Elem.2
Pressure P2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
プロファイラで実⾏時間内訳をみてみると
• メモリアクセス待ち時間が多かった
• ストア命令がたくさん出ていた
ストアが多かった理由
• ひとつの節点を複数の要素で共有していて,違う
タイミングで同じ節点に何度もストアされる
節点への⾜しこみ(A=A+B)があるので
• SIMDとソフトウェアパイプラインが出来ない
52.
52
何がボトルネックか︖
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
1
,
1
1
1
,
1
1 ,P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
2
,
1
1
2
,
1
2 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 1
3
,
1
1
3
,
1
3 , P
y
N
P
x
N
P
Vertex 1
①For Elem.1
Vertex 2
Vertex 3
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
2
,
2
2
2
,
2
2 , P
y
N
P
x
N
P
②For Elem.2
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
1
,
2
2
1
,
2
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 2
3
,
2
2
3
,
2
4 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
2
,
4
4
2
,
4
5 , P
y
N
P
x
N
P
④For Elem.4
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
1
,
4
4
1
,
4
3 , P
y
N
P
x
N
P
þ
ý
ü
î
í
ì
¶
¶
¶
¶
=
+
Ñ 4
3
,
4
4
3
,
4
1 , P
y
N
P
x
N
P
③For Elem.3
・・・略・・・
プロファイラで実⾏時間内訳をみてみると
• メモリアクセス待ち時間が多かった
• ストア命令がたくさん出ていた
ストアが多かった理由
• ひとつの節点を複数の要素で共有していて,違う
タイミングで同じ節点に何度もストアされる
節点への⾜しこみ(A=A+B)があるので
• SIMDとソフトウェアパイプラインが出来ない
節点5 3
Elem.1
Pressure P1
Elem.2
Pressure P2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
53.
53
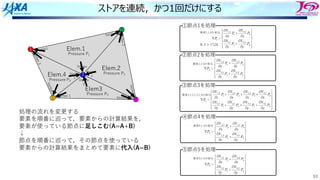
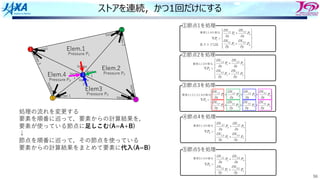
ストアを連続,かつ1回だけにする
節点5 3
Elem.1
Pressure P1
Elem.2
PressureP2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
処理の流れを変更する
要素を順番に巡って,要素からの計算結果を,
要素が使っている節点に⾜しこむ(A=A+B)
↓
節点を順番に巡って,その節点を使っている
要素からの計算結果をまとめて要素に代⼊(A=B)
54.
54
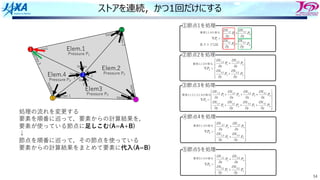
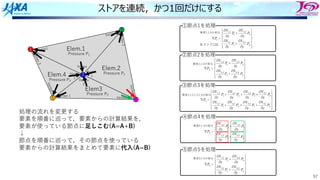
ストアを連続,かつ1回だけにする
節点5 3
Elem.1
Pressure P1
Elem.2
PressureP2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
処理の流れを変更する
要素を順番に巡って,要素からの計算結果を,
要素が使っている節点に⾜しこむ(A=A+B)
↓
節点を順番に巡って,その節点を使っている
要素からの計算結果をまとめて要素に代⼊(A=B)
55.
55
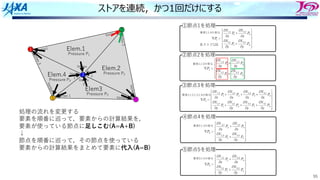
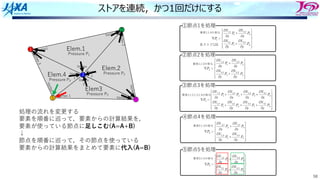
ストアを連続,かつ1回だけにする
節点5 3
Elem.1
Pressure P1
Elem.2
PressureP2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
処理の流れを変更する
要素を順番に巡って,要素からの計算結果を,
要素が使っている節点に⾜しこむ(A=A+B)
↓
節点を順番に巡って,その節点を使っている
要素からの計算結果をまとめて要素に代⼊(A=B)
56.
56
ストアを連続,かつ1回だけにする
節点5 3
Elem.1
Pressure P1
Elem.2
PressureP2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
処理の流れを変更する
要素を順番に巡って,要素からの計算結果を,
要素が使っている節点に⾜しこむ(A=A+B)
↓
節点を順番に巡って,その節点を使っている
要素からの計算結果をまとめて要素に代⼊(A=B)
57.
57
ストアを連続,かつ1回だけにする
節点5 3
Elem.1
Pressure P1
Elem.2
PressureP2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
処理の流れを変更する
要素を順番に巡って,要素からの計算結果を,
要素が使っている節点に⾜しこむ(A=A+B)
↓
節点を順番に巡って,その節点を使っている
要素からの計算結果をまとめて要素に代⼊(A=B)
58.
58
ストアを連続,かつ1回だけにする
節点5 3
Elem.1
Pressure P1
Elem.2
PressureP2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
処理の流れを変更する
要素を順番に巡って,要素からの計算結果を,
要素が使っている節点に⾜しこむ(A=A+B)
↓
節点を順番に巡って,その節点を使っている
要素からの計算結果をまとめて要素に代⼊(A=B)
59.
59
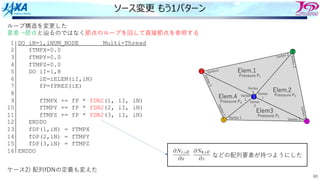
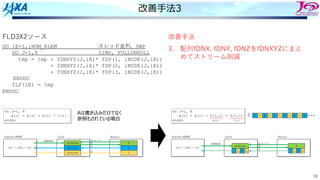
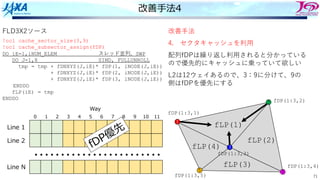
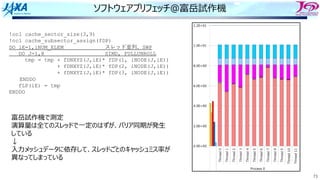
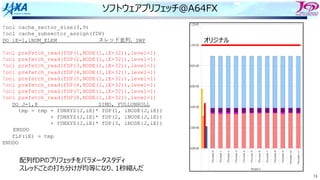
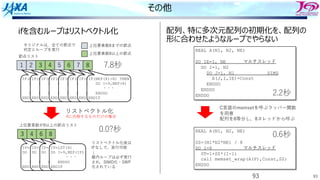
ソース変更
ループ構造を変更した
要素→節点と辿るのではなく節点のループを回して直接節点を参照する
1 DO iN=1,iNUM_NODEMulti-Thread
2 fTMPX=0.0
3 fTMPY=0.0
4 fTMPZ=0.0
5 DO iI=1,8 節点iNを使っている上位要素の数だけ回る
6 iE=iELEM(iI,iN)
7 iV=iERT(iI,iN)
8 fP=fPRES(iE)
9
10 fTMPX += fP * fDN(1, iV, iE)
11 fTMPY += fP * fDN(2, iV, iE)
12 fTMPZ += fP * fDN(3, iV, iE)
13 ENDDO
14 fDP(1,iN) = fTMPX
15 fDP(2,iN) = fTMPY
16 fDP(3,iN) = fTMPZ
17 ENDDO
節点5 3
Elem.1
Pressure P1
Elem.2
Pressure P2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
ケース1) 処理の流れだけ変更
60.
60
ソース変更 もう1パターン
ループ構造を変更した
要素→節点と辿るのではなく節点のループを回して直接節点を参照する
1 DOiN=1,iNUM_NODE Multi-Thread
2 fTMPX=0.0
3 fTMPY=0.0
4 fTMPZ=0.0
5 DO iI=1,8
6 iE=iELEM(iI,iN)
7 fP=fPRES(iE)
8
9 fTMPX += fP * fDN2(1, iI, iN)
10 fTMPY += fP * fDN2(2, iI, iN)
11 fTMPZ += fP * fDN2(3, iI, iN)
12 ENDDO
13 fDP(1,iN) = fTMPX
14 fDP(2,iN) = fTMPY
15 fDP(3,iN) = fTMPZ
16 ENDDO
節点5 3
Elem.1
Pressure P1
Elem.2
Pressure P2
Elem3
Pressure P3
Elem.4
Pressure P4
Vertex1
1
5 4
2
Vertex 2
Vertex
3 Vertex
1
V
e
r
t
e
x
2
V
e
r
t
e
x
3
Vertex 3
Vertex 1
V
e
r
t
e
x
2
Vertex
1
V
e
r
t
e
x
3
Vertex
2
ケース2) 配列fDNの定義も変えた
などの配列要素が持つようにした
61.
61
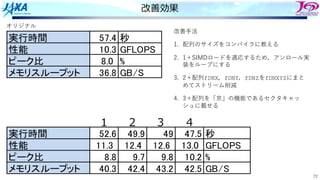
改善効果
ケース
パターン A BA B
実行時間 37.4 30.2 40.9 41.7 秒
性能 18.9 23.3 17.1 16.9 GFLOPS
ピーク比 14.8 18.2 13.4 13.2 %
メモリスループット 30.9 38 48.4 47.7 GB/S
1 2
単位
⼈⼯的なリスト値(全て同じ値)での測定結果
ケース
パターン A B A B
実行時間 123 135 44.3 44.2 秒
性能 5.6 5.2 15.8 15.9 GFLOPS
ピーク比 4.4 4.1 12.4 12.4 %
メモリスループット 23.2 23.2 47.2 47.2 GB/S
1 2
単位
測定結果
2
倍
向
上
リスト値(配列iELEM,iVERT)の値を全て同⼀値にしてリストの性質の善し悪しの影響を排除し
た結果,1の低性能はリストの影響と判明.2は元々リストアクセスされる配列が少ないので,
リスト値の品質の影響は⼩さい
ケース2はほぼ理論的な性能12%に到達.⼀⽅でケース1は低い(メモリスループットも)
91秒
44秒
※K.Kumahata, K.Minami, Y.Yamade, C.Kato, “Performance improvement of the general-purpose CFD code Front/Flow/blue on the K computer”, HPC Asia 2018,
Tokyo, Japan, (2018) https://doi.org/10.1145/3149457.3149470
リスト値
iE=iELEM(iI, iN)
iV=iVERT(iI, iN)
iI, iNの値によらず同じ値とし
た
↓
キャッシュミスしなくなり,遅い
原因がキャッシュミスなのか否
かが明らかになる
77
LS-FLOW-HO
• JAXA 研究開発部⾨第三研究ユニットで開発している⾼次精度の流体・燃焼解析ソルバー[1,2]
• 有限体積法に基づき,⾼次精度を達成するため Flux-Reconstruction 法[3]を採⽤
ロケット発射台の空⼒⾳響解析 エンジン燃焼器の乱流燃焼解析
[1] T. Haga, S. Kawai,"On a robust and accurate localized artificial diffusivity scheme for the high-order flux-reconstruction method.," J. Comput. Phys. 376 (2019), pp. 534-563.
[2] Y. Abe, I. Morinaka, T. Haga, T. Nonomura, H. Shibata, K. Miyaji, "Stable, non-dissipative, and conservative flux- reconstruction schemes in split forms." J. Comput. Phys. 353 (2018), pp. 193-227.
[3] H. T. Huynh,"A Flux Reconstruction Approach to High-Order SchemesIncluding Discontinuous Galerkin Methods.," 18th AIAA Computational Fluid Dynamics Conference Miami, Florida
78.
78
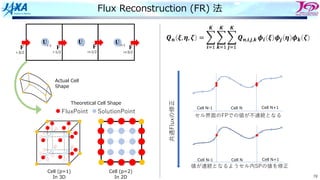
Flux Reconstruction (FR)法
U
U
U
F F
F F
i i+1
i-1
i-1/2 i+1/2 i+3/2
i-3/2
FluxPoint SolutionPoint
共通Fluxの修正
セル界⾯のFPでの値が不連続となる
値が連続となるようセル内SPの値を修正
Cell N-1 Cell N Cell N+1
Cell N-1 Cell N Cell N+1
Actual Cell
Shape
Theoretical Cell Shape
Cell (p=1)
In 3D
Cell (p=2)
In 2D
80
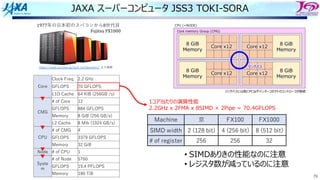
ベンチマーク問題
A Update Tand P H Correct Residual
B Compute E I Compute Residual F.G.
C Compute Cp J Compute Self Resiaual(A)
D Compute Trans Prop K Compute Self Residual(B)
E Compute Cv L Compute Gradient
F Compute Thermal Prop M Sum of under 1%
G Ref. flamelet tab.
Cost distribution
on SORA by
profiler
FIPP
Procedures for Combustion Calculations
10MPa
H2 150K
O2 100K
7100 Cells (1cell for thickness)
p=2 (# of SPs in Cell 27)
Use 1CMG (12threads)
on FX1000
100step
液体酸素と⽔素の同軸噴流⽕炎 反応機構で素反応を含む8化学種
実在気体の状態⽅程式 SRK⽅程式
輸送係数
Chung
CHEMKIN
Wilke混合則
燃焼モデル Flamelet Progress Variable (FPV)
90
なるべく⻑いループでSIMDに
0.46秒,2.35E+10FLOP,SIMD率90.4%
1.03秒,3.33E+10 FLOP, SIMD率40.0%
(1,2)do idx=1, max(=191700) SWP
(3-1) do ichem=1, spc_num(=8) 8SIMD
(3-2) do j=1,3 FULL UNROLL
(3-3) do j=1, spc_num(=8) 8SIMD
(1,2) do idx=1, max(=191700) 8SIMD
(3-1) do ichem=1, spc_num(=8) FULL UNROLL
(3-2) do j=1,3 FULL UNROLL
(3-3) do j=1, spc_num(=8) FULL UNROLL
SIMD化は最内ループに適応される
91.
91
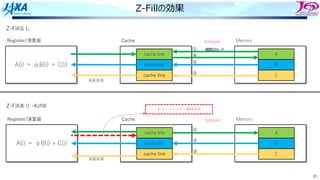
Z-Fillの効果
Z-Fillあり -Kzfill
Memory
A
B
C
A(i) =αB(i) + C(i)
Register/演算器 Cache
cache line
cache line
cache line
演算結果
4stream
Z-Fillなし
Memory
A
B
C
A(i) = αB(i) + C(i)
Register/演算器 Cache
cache line
cache line
cache line
演算結果
3stream
キャッシュライン確保命令
①
②
③
④
①
②
③
暗黙のロード











![15
性能評価
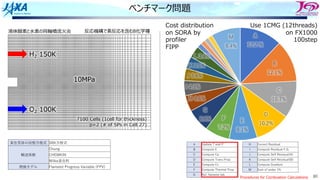
• 要求バイト
128+1152+1152×3=4736Byte
• 浮動小数点演算数
32回転×24FLOP=768Flop
• B/F値は 4736/768=6.17
• STREAMベンチマークによる「京」の
実効メモリバンド幅は46.6GB/s
• 「京」の実効B/F値は46.6/128=0.36
• メモリバンド幅がネックとなり実効上
の性能上限は128GFLOPSの
0.36/6.17=5.83%
• 82万個の4⾯体要素
• マルチスレッドで1.6%
• メモリスループットは10.29GB/s
• メモリアクセス関連待ちが70%程度
• L1Dキャッシュミス率21%
• キャッシュ利⽤効率が悪い
0.0
1.0
2.0
3.0
4.0
5.0
1 2 3 4 5 6 7 8
Time
[s]
スレッド
命令実行
待ち
メモリアクセス関連待
ち
計算時間内訳](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-15-320.jpg)
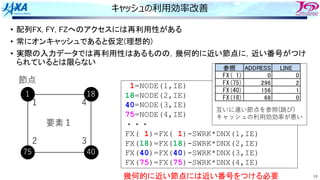
![31
スレッド並列化の⽅法の⼯夫
IP1=NODE(1,IE)
IP2=NODE(2,IE)
IP3=NODE(3,IE)
IP4=NODE(4,IE)
SWRK=S(IE)
FX(IP1)=FX(IP1)-SWRK*DNX(1,IE)
FX(IP2)=FX(IP2)-SWRK*DNX(2,IE)
FX(IP3)=FX(IP3)-SWRK*DNX(3,IE)
FX(IP4)=FX(IP4)-SWRK*DNX(4,IE)
FY(IP1)=FY(IP1)-SWRK*DNY(1,IE)
FY(IP2)=FY(IP2)-SWRK*DNY(2,IE)
FY(IP3)=FY(IP3)-SWRK*DNY(3,IE)
FY(IP4)=FY(IP4)-SWRK*DNY(4,IE)
FZ(IP1)=FZ(IP1)-SWRK*DNZ(1,IE)
FZ(IP2)=FZ(IP2)-SWRK*DNZ(2,IE)
FZ(IP3)=FZ(IP3)-SWRK*DNZ(3,IE)
FZ(IP4)=FZ(IP4)-SWRK*DNZ(4,IE)
ケースNo
ブロック
分割数
平均要素数/
ブロック
アクセスデー
タ量 [KB]
1スレッド当り
メモリ [KB]
on L1 on L2
1 640 1291 247.1 30.9 ○ ○
2 320 2583 494.4 61.8 × ○
3 160 5166 988.8 123.6 × ○
4 80 10333 1977.8 247.2 × ○
5 40 20666 3955.6 494.5 × ○
6 20 41332 7911.2 988.9 × ×
7 10 82665 15822.6 1977.8 × ×
8 5 165331 31645.4 3955.7 × ×
9 3 275552 52742.4 6592.8 × ×
10 2 413328 79113.6 9889.2 × ×
11 1 826656 158227.1 19778.4 × ×
1
10
100
1000
10000
100000
1000000
1000 10000 100000 1000000
アクセスデータ量
[KB]
平均要素数/ブロック (対数表示)
1要素当たりの必要メモリ量
NODE(1〜9, IE)
36バイト
S(IE)→4バイト
DNX(1-9,IE)
36バイト
DNY(1-9,IE)
36バイト
DNZ(1-9,IE)
36バイト
FX(IP1〜IP4)
FY(IP1〜IP4)
FZ(IP1〜IP4)
48バイト
196バイト/要素
ブロック当たりに
アクセスするデータ量
ブロックの大きさ(含む要素数)について検討](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-31-320.jpg)
![40
まとめ
ケース名 内容
ORG オリジナル
A
節点リナンバー,要素ブロック,
外側カラー化
B 配列融合
C ブロック化⼿法改善
0.0
1.0
2.0
3.0
4.0
5.0
ORG Sec.7 Sec.8 Sec.9
Time
[s]
命令実行
待&
'()*+,-関連待&
ORG C
B
A
0.0
1.0
2.0
3.0
4.0
5.0
1 2 3 4 5 6 7 8
Time
[s]
5
5.
L1
FX, FY, FZ
1
B/F
83%
17 3 FX, FY, FZ
IE
2/3
18 4
2
4.72 1.76 2.7
0.0
0.5
1.0
1.5
2.0
1 2 3 4 5 6 7 8
Time
[s]
(1,IP1)=FXYZ(1,IP1)-SWRK*DNXYZ(1,1,IE)
(2,IP1)=FXYZ(2,IP1)-SWRK*DNXYZ(2,1,IE)
(3,IP1)=FXYZ(3,IP1)-SWRK*DNXYZ(3,1,IE)
(1,IP2)=FXYZ(1,IP2)-SWRK*DNXYZ(1,2,IE)
(2,IP2)=FXYZ(2,IP2)-SWRK*DNXYZ(2,2,IE)
(3,IP2)=FXYZ(3,IP2)-SWRK*DNXYZ(3,2,IE)
YZ(1,IP1)=FXYZ(1,IP1)-SWRK*DNX(1,IE)
YZ(2,IP1)=FXYZ(2,IP1)-SWRK*DNY(1,IE)
YZ(3,IP1)=FXYZ(3,IP1)-SWRK*DNZ(1,IE)
YZ(1,IP2)=FXYZ(1,IP2)-SWRK*DNX(2,IE)
YZ(2,IP2)=FXYZ(2,IP2)-SWRK*DNY(2,IE)
YZ(3,IP2)=FXYZ(3,IP2)-SWRK*DNZ(2,IE)
YZ(1,IP3)=FXYZ(1,IP3)-SWRK*DNX(3,IE)
YZ(2,IP3)=FXYZ(2,IP3)-SWRK*DNY(3,IE)
YZ(3,IP3)=FXYZ(3,IP3)-SWRK*DNZ(3,IE)
YZ(1,IP4)=FXYZ(1,IP4)-SWRK*DNX(4,IE)
YZ(2,IP4)=FXYZ(2,IP4)-SWRK*DNY(4,IE)
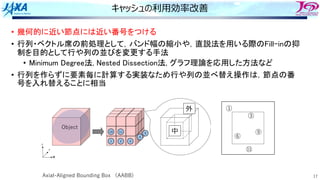
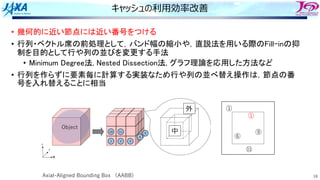
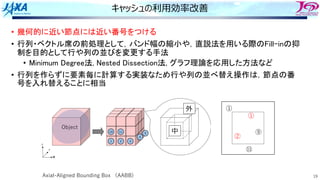
YZ(3,IP4)=FXYZ(3,IP4)-SWRK*DNZ(4,IE)](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-40-320.jpg)



![62
同じ改善を別カーネルへ
アプリ中に同じ改善が適応可能なカーネルがあり,それにも適⽤し,実⾏時間半減
0.0
10.0
20.0
30.0
40.0
50.0
60.0
ASIS tune1A tune2B tune2B1 tune2C
Time
[s]
ソース概要
DO IE=1, 全ヘキサ要素
DO I=1, ヘキサ要素の8頂点
IP=頂点Iのグローバル節点番号
演算(⻑いので略)
節点IPへのストア
ENDDO
ENDDO
CASE
実行時間
[秒]
向上率
1以上なら
高速化
チューニング内容
ASIS 32.0 1.00 オリジナル(要素で回すループ)
tune1A 55.1 0.58 節点で回すループに変更(配列アクセスはランダム)
tune2B 19.1 1.67 tune1Aを配列を並び替えて配列アクセスを連続アクセス化
tune2B1 20.7 1.54 tune2Bで最内ループ回転数固定化
tune2C 14.0 2.29 tune2B1で最内ループ内処理のアンロール実装を再度ループ化
配列へのストアは連続に、かつA=A+Bの形にしない](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-62-320.jpg)






![77
LS-FLOW-HO
• JAXA 研究開発部⾨ 第三研究ユニットで開発している⾼次精度の流体・燃焼解析ソルバー[1,2]
• 有限体積法に基づき,⾼次精度を達成するため Flux-Reconstruction 法[3]を採⽤
ロケット発射台の空⼒⾳響解析 エンジン燃焼器の乱流燃焼解析
[1] T. Haga, S. Kawai,"On a robust and accurate localized artificial diffusivity scheme for the high-order flux-reconstruction method.," J. Comput. Phys. 376 (2019), pp. 534-563.
[2] Y. Abe, I. Morinaka, T. Haga, T. Nonomura, H. Shibata, K. Miyaji, "Stable, non-dissipative, and conservative flux- reconstruction schemes in split forms." J. Comput. Phys. 353 (2018), pp. 193-227.
[3] H. T. Huynh,"A Flux Reconstruction Approach to High-Order SchemesIncluding Discontinuous Galerkin Methods.," 18th AIAA Computational Fluid Dynamics Conference Miami, Florida](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-77-320.jpg)
![83
⼩回転ループはさけたい
52.0
52.1
52.2
52.3
52.4
52.5
52.6
0 1 0 1 0 1 0 1
0 0 1 1 0 0 1 1
0 0 0 0 1 1 1 1
Time
[s]
Loop C
Loop B
Loop A
0) Original (Implemented as Loop)
1) Modified (Unrolled)
別のルーチンにも同様の⼿法を当てはめてみた
Loop A)
前ページと同じく,コンパイル時には
回転数が確定しているが,コンパイ
ラにはわからない
今のケースでは8回転
Loop B,C)
ソース上で直接回転数をハードコー
ドしている
do i=1,10など
原点が0でないので注意](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-83-320.jpg)
![84
OpenMPのスケジュール調整
0.0
2.0
4.0
6.0
8.0
10.0
12.0
0 1 2 3 4 5 6 7 8 9 10 11
Time
[s]
Thread
Inctruction Commit
Barrier Wait
Instruction Wait
Memory/Cache
AccessWait
0.0E+00
5.0E+09
1.0E+10
1.5E+10
2.0E+10
0.0E+00
2.0E+10
4.0E+10
6.0E+10
8.0E+10
1.0E+11
0 1 2 3 4 5 6 7 8 9 10 11
■Number
of
Instructions
■Number
of
FLOP
Thread
0.0
2.0
4.0
6.0
8.0
10.0
12.0
0 1 2 3 4 5 6 7 8 9 10 11
Time
[s]
Thread
Inctruction Commit
Barrier Wait
Instruction Wait
Memory/Cache
AccessWait
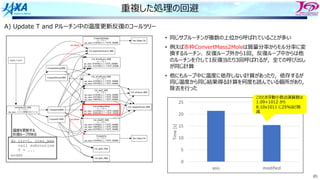
A) Update T and P ルーチンの実⾏時間内訳
• FX1000のCPU性能解析レポートの出⼒,バリア同期待ちが多い
• セルを巡るループでスレッド並列化しており,各スレッドへのセルの割当量
は均⼀だが演算数に違いが出ている
• 当該ループのOpenMPのディレクティブに schedule(dynamic, 1)
を指定し !$omp parallel do schedule(dynamic, 1)
とした
do itr=1, max
res = ・・・
if(res < EPS) exit
enddo
収束判定に合格して
ループを抜けるタイミングが
まちまちだった](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-84-320.jpg)
![86
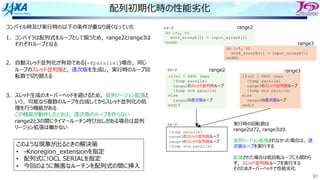
配列初期化時の性能劣化
※前ページまでの事例とは,ソースの版数と⼊⼒データが異なる
1ルーチン単体(下位のルーチン含まず)
でコストの18%弱を占める
C ase N o. A Total range1 range2 range3 range4 other
31 12.
80 0.
12 1.
08 11.
60
32 2.
81 0.
11 0.
12 0.
11 2.
48
33 2.
99 0.
11 0.
11 0.
10 0.
11 2.
56
34 2.
81 0.
11 0.
11 0.
11 2.
49
単位 [s]
ルーチン内に細かくタイマールーチンを挿⼊.
特定部分を計るためのタイマーが有効な
時だけ速い
range2,3でおかしなことが起きている
01 subroutine sample(n1, n2, input_arrayA, input_arrayB)
02 implicit none
03
04 ! argument
05 integer, intent(in) :: n1, n2
06 real(8), intent(in) :: input_arrayA(n1), input_arrayB(n2)
07
08 ! local
09 real(8) :: work_arrayA(n1), work_arrayB(n2)
10 ・
11 ・
12 ! call timer_start(range2)
13 work_arrayA(:) = input_arrayA(:)
14 ! call timer_stop(range2)
15
16 ! call timer_start(range3)
17 work_arrayB(:) = input_arrayB(:)
20 ! call timer_stop(range3)
21 ・
22 ・
23 end subroutine sample
当該ルーチン概要
range3
• range2,3は引数の値をワーク配列へコピーする配列式
• コンパイラは配列式をループとして扱いループ最適化
(実⾏時回転数889以上でスレッド並列,SIMD,ソフトウェアパイプライン
など適応)
• コメントアウトしてあるタイマールーチン呼び出しを有効にすると速くなる](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-86-320.jpg)
![88
まとめ
0.0
20.0
40.0
60.0
80.0
100.0
As-Is Current
Time
[s]
Thread
Inctruction Commit
Barrier Wait
Instruction Wait
Memory/Cache
AccessWait
With Array Init Problem
チューニング)
⼀般的には演算区間であるような下位のループの実⾏時
間を短縮し,GFLOPSやGB/sを向上させること.
本コードでは,上位ループから回転数・演算数がごく⼩さい
下位ループを多数呼んでおり,⼿続き呼び出しのオーバー
ヘッドや,レジスタ不⾜に伴う演算待ちがボトルネックであり,
今回はそれらボトルネックの低減が主眼でした
他にも,コンパイルオプションの再考として,元々FX100向け
だったので⾊々指定されていた
-Kfast,parallel,noalias=s,array_private,
preex,ocl,nounroll,autoobjstack を再整理し
て -Kfast,parallel,ocl として56.0秒から53.8秒
With Array Init. Problem
プロファイラ(CPU性能解析レポート)を使うとバーヘッドが出る
ため,ここではプロファイラを⽤いて求めた実⾏時間の内訳を,
プロファイラなしで実⾏した際の全体実⾏時間で補正
今回ご紹介した紹介したチューニング事例を全て適応
アプリ全体の実⾏時間は,81秒程度から51秒程度に
改善
配列初期化時の性能劣化は,統⼀して測定できな
かったので,その分10秒を個別に加えると90秒程度か
ら51秒程度に改善](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-88-320.jpg)


![92
Z-Fillの効果
疑似コード
integer*8 :: I, SZ, ITR, NITR
parameter(SZ=104857600)
parameter(NITR=100)
real*8 :: A(SZ), B(SZ), C(SZ), alpha
start = gettime()
call FAPP_START()
do ITR=1, NITR
do I=1, SZ
A(I)=alpha * B(I) + C(I)
enddo
enddo
call FAPP_STOP()
dt = start – gettime()
本体部分
配列ひと
つのサイ
ズ MB
case GB dt [s] GB/s
withoutzfill 335.544 1.616 207.657
withoutzfill_numactl 335.544 1.618 207.343
withzfill 251.658 1.236 203.634
withzfill_numactl 251.658 1.237 203.382
withoutzfill 335.544 1.601 209.577
withoutzfill_numactl 335.544 1.623 206.767
withzfill 251.658 1.242 202.633
withzfill_numactl 251.658 1.241 202.788
withoutzfill 335.544 1.463 229.422
withoutzfill_numactl 335.544 1.674 200.500
withzfill 251.658 1.279 196.833
withzfill_numactl 251.658 1.284 195.948
800
80
8
Z-Fillにより暗黙のAのロードがなくなり
ストリームが削減し性能改善](https://image.slidesharecdn.com/2022-220516042234-71ef8a91/85/5-B-2022-92-320.jpg)












![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)









































