汎化誤差の分解 [Bottou+11][得居15]
12
近似誤差 推定誤差最適化誤差
θ* : 汎化誤差最⼩解 argminθ E (θ)
θ^ : 訓練誤差最⼩解 argminθ E^(θ)
θ0 : アルゴリズムで実際に得られたパラメータ
L. Bottou and O. Bousquet, “The tradeoffs of large scale learning,” In
Optimization for Machine Learning, MIT Press, pp. 351‒368, 2011.
最適化から⾒たディープラーニングの考え⽅,
得居 誠也, オペレーションズ・リサーチ : 経営の科学 60(4), 191-197, 2015-04-01
E(✓0) = E(✓⇤
) +
h
E(ˆ✓) E(✓⇤
)
i
+
h
E(✓0) E(ˆ✓)
i
Tomaso Poggioの問題提起
[Poggio+16]
14
Poggio, T.,Mhaskar, H., Rosasco, L., Miranda, B., & Liao, Q. (2016). Why and When Can
Deep--but Not Shallow--Networks Avoid the Curse of Dimensionality: a Review. arXiv
preprint arXiv:1611.00740.
https://mcgovern.mit.edu/principal-investigators/tomaso-poggio
15.
近似誤差 推定誤差最適化誤差
E(✓0) =E(✓⇤
) +
h
E(ˆ✓) E(✓⇤
)
i
+
h
E(✓0) E(ˆ✓)
i
仮説集合は本物の分布をどのくらい
近似する能⼒があるか?
16.
Tomaso Poggioの問題提起
[Poggio+16]
16
Poggio, T.,Mhaskar, H., Rosasco, L., Miranda, B., & Liao, Q. (2016). Why and When Can
Deep--but Not Shallow--Networks Avoid the Curse of Dimensionality: a Review. arXiv
preprint arXiv:1611.00740.
https://mcgovern.mit.edu/principal-investigators/tomaso-poggio
17.
普遍性定理 ([Cybenko+89] etc..)
Note
•定義域の[-1, 1]dはコンパクト空間に拡張できる
• [Cybenko+89]以降⾊々なバリエーションで証明されている
• [Cybenko+89]ではHahn-Banachの定理とRieszの表現定理を使う。
• Nielsenによる証明が構成的で平易
17
Cybenko., G. (1989) "Approximations by superpositions of sigmoidal
functions", Mathematics of Control, Signals, and Systems, 2 (4), 303-314
http://neuralnetworksanddeeplearning.com
隠れ層1層で活性化関数がシグモイド関数のNN全体は、
supノルムに関して、C([-1, 1]d)の中で稠密
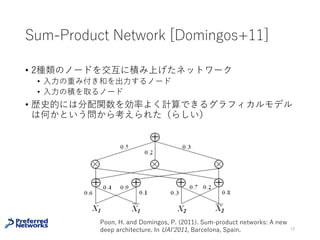
Sum-Product Network [Domingos+11]
•2種類のノードを交互に積み上げたネットワーク
• ⼊⼒の重み付き和を出⼒するノード
• ⼊⼒の積を取るノード
• 歴史的には分配関数を効率よく計算できるグラフィカルモデル
は何かという問いから考えられた(らしい)
19
Poon, H. and Domingos, P. (2011). Sum-product networks: A new
deep architecture. In UAIʼ2011, Barcelona, Spain.
20.
層を深くするメリット[Delalleau+11]
• ⾼さ2n段、各ノードが2⼊⼒のSum-product network(=⼊⼒
数4n)を2段のSum-product Networkで実現するには、1段⽬の
掛け算ノードが少なくとも22^n-1個必要 (Collorary 1)
20
Delalleau, Olivier, and Yoshua Bengio. "Shallow vs. deep sum-product
networks." Advances in Neural Information Processing Systems. 2011.
Proposition 3でも別のタイプの多層
Sum-product networkで似た主張を⽰す
多層では O(M) 個のパラメータで表現
できるが、2段では O(exp(M)) 個のパ
ラメータが必要な関数が存在する
近似誤差 推定誤差 最適化誤差
E(✓0)= E(✓⇤
) +
h
E(ˆ✓) E(✓⇤
)
i
+
h
E(✓0) E(ˆ✓)
i
訓練誤差を最⼩にする理想の解と実
際のアルゴリズムで得られる現実の
解はどのくらい違うか?
23.
Tomaso Poggioの問題提起
[Poggio+16]
23
Poggio, T.,Mhaskar, H., Rosasco, L., Miranda, B., & Liao, Q. (2016). Why and When Can
Deep--but Not Shallow--Networks Avoid the Curse of Dimensionality: a Review. arXiv
preprint arXiv:1611.00740.
https://mcgovern.mit.edu/principal-investigators/tomaso-poggio
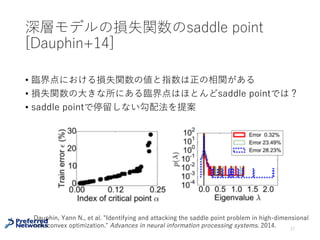
深層モデルの損失関数のsaddle point
[Dauphin+14]
• 臨界点における損失関数の値と指数は正の相関がある
•損失関数の⼤きな所にある臨界点はほとんどsaddle pointでは?
• saddle pointで停留しない勾配法を提案
28
Dauphin, Yann N., et al. "Identifying and attacking the saddle point problem in high-dimensional
non-convex optimization." Advances in neural information processing systems. 2014.
29.
物理モデルへの帰着
ニューラルネットや⼊⼒に適当な仮定を置くことで、損失関数
を適当な物理モデルのハミルトニアンの形に帰着させる
• ランダムガウシアンモデル [Bray+07]
•Spherical spin glass モデル [Choromanska+15]
ランダム⾏列理論やが使える⼀⽅で、仮定が現実的ではないと
いう批判もある([Kawaguchi16]など)
29
Bray, Alan J., and David S. Dean. "Statistics of critical points of gaussian fields on
large-dimensional spaces." Physical review letters 98.15 (2007): 150201.
Choromanska, Anna, et al. "The Loss Surfaces of Multilayer Networks." AISTATS.
2015.
38
Tomaso Poggio, Qianli
Liao,Theory II:
Landscape of the
Empirical Risk in Deep
Learning,
arXiv:1703.09833
Poggioらは、実験結果
から損失関数は右図
(A)のような形をして
いるという仮説を⽰し
ている[Poggio+17]
39.
近似誤差 推定誤差 最適化誤差
E(✓0)= E(✓⇤
) +
h
E(ˆ✓) E(✓⇤
)
i
+
h
E(✓0) E(ˆ✓)
i
汎化誤差と訓練誤差にはどのくらい
の違いがあるか?
40.
Tomaso Poggioの問題提起
[Poggio+16]
40
Poggio, T.,Mhaskar, H., Rosasco, L., Miranda, B., & Liao, Q. (2016). Why and When Can
Deep--but Not Shallow--Networks Avoid the Curse of Dimensionality: a Review. arXiv
preprint arXiv:1611.00740.
https://mcgovern.mit.edu/principal-investigators/tomaso-poggio
層を深くするメリット[Mhaskar+16]
• [Mhaskar+16 ,Theorem 1]
56
Mhaskar, Hrushikesh, Qianli Liao, and Tomaso Poggio. "Learning functions:
When is deep better than shallow." arXiv preprint arXiv:1603.00988 (2016).




![汎化誤差と訓練誤差
汎化誤差: E (θ) = E(x, y)~q [L(x, y; θ)]
• 本当に最⼩化したいもの
• 真のデータ分布 q がわからないので計算出来ない
訓練誤差: E^ (θ) = 1 / N Σi L(xi , yi ; θ)
• 計算できるけれど、本当に最⼩化したいものではない
• Dから決まる経験分布 q^ に関するLの期待値 E(x, y)~q^ [L(x, y; θ)]
と書ける
4
経験分布:q^ (x, y) = ((x, y)が出た回数) / N](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-4-320.jpg)

![KLダイバージェンス
このスライドだけ以下の状況を考える
• 損失関数は L(x, y; θ) = - log p(y | x; θ) (負の対数尤度)
• p (x; θ) は θ によらず⼀定
6
KL(qkp✓) = E(x,y)⇠q
log
q(x, y)
p(x, y; ✓)
= E(x,y)⇠q [ log p(x, y; ✓)] + const.
= E(x,y)⇠q [ log p(y | x; ✓) log p(x; ✓)] + const.
= E(x,y)⇠q [ log p(y | x; ✓)] + const.
= E(✓) + const.
このとき、汎化誤差最⼩化とKLダイバージェンス最⼩化は同値](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-6-320.jpg)



![汎化誤差の分解 [Bottou+11][得居15]
12
近似誤差 推定誤差 最適化誤差
θ* : 汎化誤差最⼩解 argminθ E (θ)
θ^ : 訓練誤差最⼩解 argminθ E^(θ)
θ0 : アルゴリズムで実際に得られたパラメータ
L. Bottou and O. Bousquet, “The tradeoffs of large scale learning,” In
Optimization for Machine Learning, MIT Press, pp. 351‒368, 2011.
最適化から⾒たディープラーニングの考え⽅,
得居 誠也, オペレーションズ・リサーチ : 経営の科学 60(4), 191-197, 2015-04-01
E(✓0) = E(✓⇤
) +
h
E(ˆ✓) E(✓⇤
)
i
+
h
E(✓0) E(ˆ✓)
i](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-12-320.jpg)

![Tomaso Poggioの問題提起
[Poggio+16]
14
Poggio, T., Mhaskar, H., Rosasco, L., Miranda, B., & Liao, Q. (2016). Why and When Can
Deep--but Not Shallow--Networks Avoid the Curse of Dimensionality: a Review. arXiv
preprint arXiv:1611.00740.
https://mcgovern.mit.edu/principal-investigators/tomaso-poggio](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-14-320.jpg)

![Tomaso Poggioの問題提起
[Poggio+16]
16
Poggio, T., Mhaskar, H., Rosasco, L., Miranda, B., & Liao, Q. (2016). Why and When Can
Deep--but Not Shallow--Networks Avoid the Curse of Dimensionality: a Review. arXiv
preprint arXiv:1611.00740.
https://mcgovern.mit.edu/principal-investigators/tomaso-poggio](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-16-320.jpg)
![普遍性定理 ([Cybenko+89] etc..)
Note
• 定義域の[-1, 1]dはコンパクト空間に拡張できる
• [Cybenko+89]以降⾊々なバリエーションで証明されている
• [Cybenko+89]ではHahn-Banachの定理とRieszの表現定理を使う。
• Nielsenによる証明が構成的で平易
17
Cybenko., G. (1989) "Approximations by superpositions of sigmoidal
functions", Mathematics of Control, Signals, and Systems, 2 (4), 303-314
http://neuralnetworksanddeeplearning.com
隠れ層1層で活性化関数がシグモイド関数のNN全体は、
supノルムに関して、C([-1, 1]d)の中で稠密](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-17-320.jpg)
![Sum-Product Network [Domingos+11]
• 2種類のノードを交互に積み上げたネットワーク
• ⼊⼒の重み付き和を出⼒するノード
• ⼊⼒の積を取るノード
• 歴史的には分配関数を効率よく計算できるグラフィカルモデル
は何かという問いから考えられた(らしい)
19
Poon, H. and Domingos, P. (2011). Sum-product networks: A new
deep architecture. In UAIʼ2011, Barcelona, Spain.](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-19-320.jpg)
![層を深くするメリット[Delalleau+11]
• ⾼さ2n段、各ノードが2⼊⼒のSum-product network (=⼊⼒
数4n)を2段のSum-product Networkで実現するには、1段⽬の
掛け算ノードが少なくとも22^n-1個必要 (Collorary 1)
20
Delalleau, Olivier, and Yoshua Bengio. "Shallow vs. deep sum-product
networks." Advances in Neural Information Processing Systems. 2011.
Proposition 3でも別のタイプの多層
Sum-product networkで似た主張を⽰す
多層では O(M) 個のパラメータで表現
できるが、2段では O(exp(M)) 個のパ
ラメータが必要な関数が存在する](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-20-320.jpg)

![Tomaso Poggioの問題提起
[Poggio+16]
23
Poggio, T., Mhaskar, H., Rosasco, L., Miranda, B., & Liao, Q. (2016). Why and When Can
Deep--but Not Shallow--Networks Avoid the Curse of Dimensionality: a Review. arXiv
preprint arXiv:1611.00740.
https://mcgovern.mit.edu/principal-investigators/tomaso-poggio](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-23-320.jpg)

![臨界点と指数
• θ = a が関数 f : Rd→Rの臨界点 ⇔ ∇θ f (a) (= [∂i f (a)]i=1,..,d ) = 0
• 臨界点でのHessianの負の固有値の数を指数という
25
Hessian H(a) = ∇θ∇θ
T f (a) ( = [∂i∂j f(a)]ij=1,…,d )
Hessianは対称⾏列 → 実数固有値を(重複度含めて)d個持つ](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-25-320.jpg)
![深層モデルの損失関数のsaddle point
[Dauphin+14]
• 臨界点における損失関数の値と指数は正の相関がある
• 損失関数の⼤きな所にある臨界点はほとんどsaddle pointでは?
• saddle pointで停留しない勾配法を提案
28
Dauphin, Yann N., et al. "Identifying and attacking the saddle point problem in high-dimensional
non-convex optimization." Advances in neural information processing systems. 2014.](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-28-320.jpg)
![物理モデルへの帰着
ニューラルネットや⼊⼒に適当な仮定を置くことで、損失関数
を適当な物理モデルのハミルトニアンの形に帰着させる
• ランダムガウシアンモデル [Bray+07]
• Spherical spin glass モデル [Choromanska+15]
ランダム⾏列理論やが使える⼀⽅で、仮定が現実的ではないと
いう批判もある([Kawaguchi16]など)
29
Bray, Alan J., and David S. Dean. "Statistics of critical points of gaussian fields on
large-dimensional spaces." Physical review letters 98.15 (2007): 150201.
Choromanska, Anna, et al. "The Loss Surfaces of Multilayer Networks." AISTATS.
2015.](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-29-320.jpg)
![深層モデルの損失関数のSaddle point
[Choromanska+15]など
ReLUを活性化関数とする多層パーセプト
ロンの損失関数を近似によりspherical
spin glassのエネルギー関数に帰着させる
⽰したこと(informal)
• 臨界点は指数が⼩さいほど、⾼確率で存
在するエネルギー帯が低エネルギー帯に
広がっている
• ネットワークのユニット数が増えるほど、
ある⼀定の値以下のエネルギー帯に含ま
れる臨界点のうち、指数が⼩さいもの割
合が指数的に増える
30
Choromanska, Anna, et al. "The Loss Surfaces of Multilayer Networks." AISTATS. 2015.
E
-E∞-E0 -E1 -E2 ・・・
例えば指数2の臨界点は
⾼確率でここにある](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-30-320.jpg)

![統計多様体と特異モデル
• 仮説空間として確率分布族を考える。
• Fisher 情報量が各点で⾮退化ならば、この族にはFisher情報量
を計量とするリーマン多様体の構造が⼊る
32
p q
Fisher 情報量
G(θ) = (Gij (θ)) ij=1,…,d
Gij (θ) = E [∂i log p(x, y; θ) ∂j log p(x, y; θ)]
(期待値は(x, y)~pθに関して)](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-32-320.jpg)
![Natural gradient [Amari+98]
Gradient Descent (GD)で勾配にFisher情報量の逆⾏列を掛ける
• 通常のGDはFisher情報量が潰れている箇所で移動距離が⼩さ
くなり、停滞してしまう
• Fisher情報量の逆⾏列でキャンセルする
33
Amari, Shun-Ichi. "Natural gradient works efficiently in learning." Neural
computation 10.2 (1998): 251-276.
θ ← θ - η Gθ
-1∇θ L(x, y; θ)](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-33-320.jpg)

![深層学習モデルの作る損失関数の
Local minima [Choromanska+15]
35
Choromanska, Anna, et al. "The Loss Surfaces of Multilayer
Networks." AISTATS. 2015.](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-35-320.jpg)
![No-bad-local-minima Theorem
[Kawaguchi16], [Lu+17]
• 訓練データとネットワークに関する緩い条件
• 線形NN(活性化関数が恒等関数)
• 損失関数は2乗誤差
→ 訓練誤差関数のlocal minimumはglobal minimumである
36
Kawaguchi, Kenji. "Deep learning without poor local minima." Advances In Neural
Information Processing Systems. 2016.
Lu, Haihao, and Kenji Kawaguchi. "Depth Creates No Bad Local Minima." arXiv preprint
arXiv:1702.08580 (2017).
余談:local minimum = global minimumという定理は深層学習以外の⽂脈でも幾つか存在する
(テンソル分解など)
フルランク・固有値が相異など、
ユークリッド空間でほとんど⾄る所成⽴する
ような条件](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-36-320.jpg)
![No-bad-local-minima Theorem
[Kawaguchi16], [Lu+17]
37
(画像はイメージです)
Kawaguchi, Kenji. "Deep learning without poor local minima." Advances In Neural
Information Processing Systems. 2016.
Lu, Haihao, and Kenji Kawaguchi. "Depth Creates No Bad Local Minima." arXiv preprint
arXiv:1702.08580 (2017).](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-37-320.jpg)
![38
Tomaso Poggio, Qianli
Liao, Theory II:
Landscape of the
Empirical Risk in Deep
Learning,
arXiv:1703.09833
Poggioらは、実験結果
から損失関数は右図
(A)のような形をして
いるという仮説を⽰し
ている[Poggio+17]](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-38-320.jpg)

![Tomaso Poggioの問題提起
[Poggio+16]
40
Poggio, T., Mhaskar, H., Rosasco, L., Miranda, B., & Liao, Q. (2016). Why and When Can
Deep--but Not Shallow--Networks Avoid the Curse of Dimensionality: a Review. arXiv
preprint arXiv:1611.00740.
https://mcgovern.mit.edu/principal-investigators/tomaso-poggio](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-40-320.jpg)
![汎化誤差と訓練誤差(再掲)
• 汎化誤差: E (θ) = E(x, y)~q [L(x, y; θ)]
• 本当に最⼩化したいもの
• qがわからないのでこれを計算することは出来ない
• 訓練誤差: E^ (θ) = 1 / N Σi L(xi , yi ; θ)
• これならば計算できる代わりに最⼩化するもの
• けれど、本当に最⼩化したいものではない
41
θ* : 汎化誤差最⼩化 θ* = argminθ E (θ)
θ^ : 訓練誤差最⼩化 θ^ = argminθ E^(θ)](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-41-320.jpg)



![Rademacher complexity
仮説空間の「複雑度」を図る指標
45
R(H, D) = E
"
sup
h2H
X
i
ih(zi)
#
= ( 1, . . . , n), i ⇠ Ber
✓
1
2
◆
R(H) = ED⇠q [R(H, D)]
経験 Rademacher complexity
Rademacher complexity
特に、ラベル y∈{-1, +1}で、仮説空間内のモデルが確定的な関数の場合
i.e. H ⊂ {f | f : Rd → {±1}}](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-45-320.jpg)

![Uniform stabilityを⽤いた汎化性能の評価
[Hardt+15]
47
Hardt, Moritz, Benjamin Recht, and Yoram Singer. "Train faster, generalize better:
Stability of stochastic gradient descent." arXiv preprint arXiv:1509.01240(2015).
損失関数には有界性・Lipschitz性
とsmooth性しか仮定していない
(⾮凸関数(NNなど)でもよい)
ε-uniformly stableならば汎化
性能(の期待値)を評価できる
SGDで得られる予測モデルは
ε-uniformly stable](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-47-320.jpg)
![深層学習の汎化性能 [Zhang+16]
深層学習のモデルをでラベルをランダムなものに⼊れ替えた
データセットで学習したら訓練誤差を0にできた
経験Rademacher complexityがほぼ1であることを⽰唆
48
Zhang, Chiyuan, et al. "Understanding deep learning requires rethinking
generalization." arXiv preprint arXiv:1611.03530 (2016).
VC次元やuniform stabilityなど、その他の汎化性
能を評価する指標でも説明できないと主張
ここが1だと不等式は⾃明に成⽴](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-48-320.jpg)
![[Zhang+16] に対する批判
• Rademacher complexityによる汎化性能の評価は、仮説集合のすべての
元で成⽴する、⼀様な評価なので、これが使えないことは統計的学習理
論の⽅ではよく知られていた(ということを講演者は最近知った)
• その他には[David+17][Akiba17]などによる後続検証がある
49
David Krueger et al, Deep Nets Don't Learn via Memorization, ICLR2017 workshop
https://medium.com/@iwiwi/it-is-not-only-deep-learning-that-requires-rethinking-
generalization-32ec7062d0b3
深層学習の汎化性能は⽐較的まだ
理論解析されていない](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-49-320.jpg)






![層を深くするメリット[Mhaskar+16]
• [Mhaskar+16 , Theorem 1]
56
Mhaskar, Hrushikesh, Qianli Liao, and Tomaso Poggio. "Learning functions:
When is deep better than shallow." arXiv preprint arXiv:1603.00988 (2016).](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-56-320.jpg)

![適応⾃然勾配法 [Amari+00] [Park+00]
• Fisher情報量の逆⾏列の計算が重いので、それをオンラインで
推定したものを使う、適応⾃然勾配法という⼿法もある
58
Amari, Shun-Ichi, Hyeyoung Park, and Kenji Fukumizu. "Adaptive method of
realizing natural gradient learning for multilayer perceptrons." Neural
Computation 12.6 (2000): 1399-1409.
Park, Hyeyoung, S-I. Amari, and Kenji Fukumizu. "Adaptive natural gradient learning
algorithms for various stochastic models." Neural Networks 13.7 (2000): 755-764.](https://image.slidesharecdn.com/201704222-170420123415/85/20170422-Part2-58-320.jpg)





















![[DL輪読会]“Highly accurate protein structure prediction with AlphaFold”](https://cdn.slidesharecdn.com/ss_thumbnails/210910dlver11-210910034033-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)












































