機械学習界隈での公平性の注目
ACM FAT*
国際会議
ACM FAT*2018-19
AAAI/ACM AIES 2018-19
国際ワークショップ
FATML 2014-18
招待講演
•ICML2017(L. Sweeney)
•NIPS2017 (K. Crawford)
•KDD2017 (C. Dwork)
•KDD2018 (J. M. Wing)
AI for Social Good 2018-19
Challenges and Opportunities for AI
in Financial Services 2018
AI Ethics WS 2018
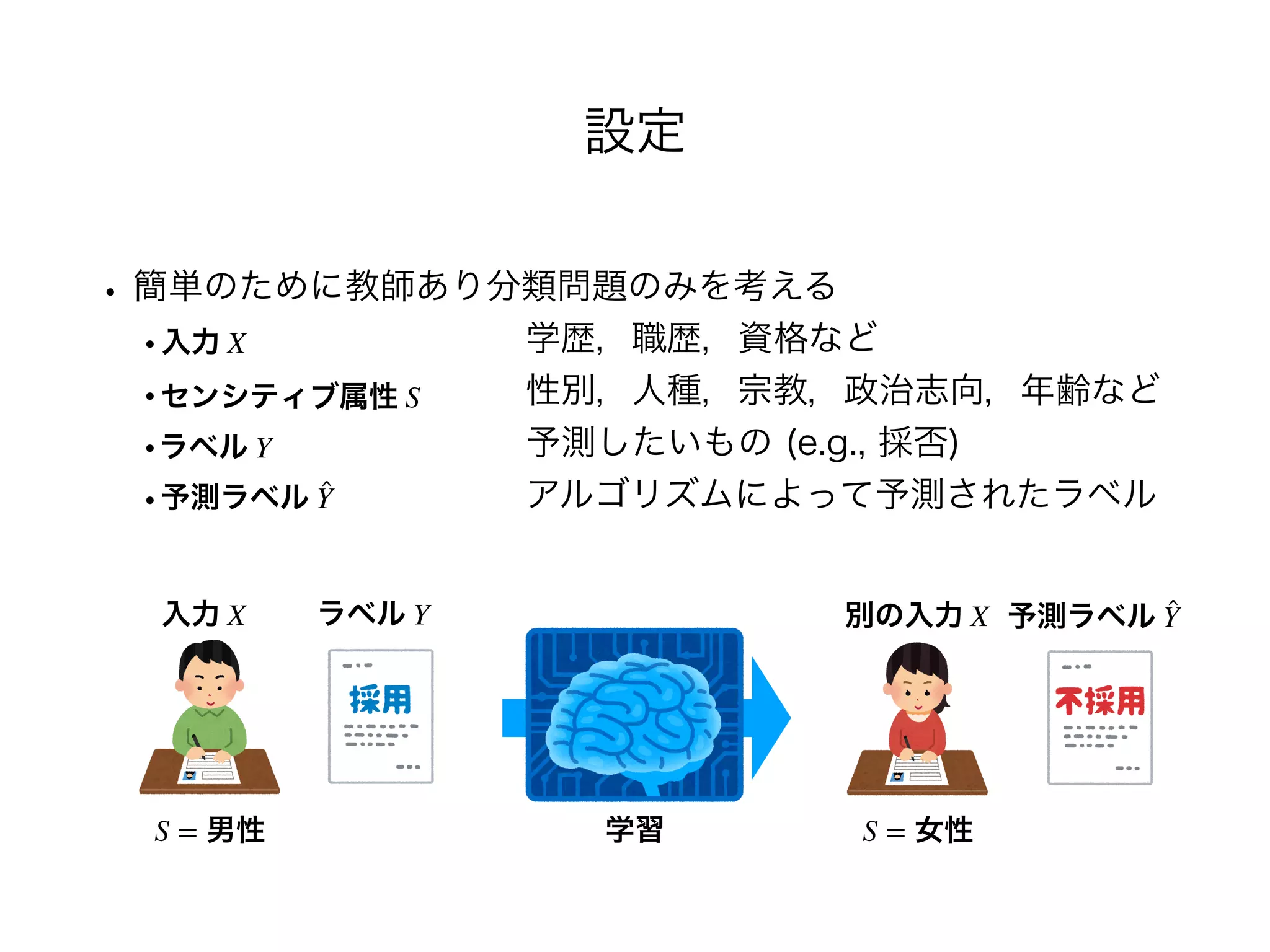
設定
• 簡単のために教師あり分類問題のみを考える
• 学歴,職歴,資格など
• 性別,人種,宗教,政治志向,年齢など
• 予測したいもの (e.g., 採否)
• アルゴリズムによって予測されたラベル
入力 X ラベル Y 予測ラベル ̂Y別の入力 X
S = 男性 S = 女性
入力 X
ラベル Y
センシティブ属性 S
予測ラベル ̂Y
学習
References 1
• [Hardt+16]Moritz Hardt, Eric Price, and Nathan Srebro.
Equality of Opportunity in Supervised Learning. In: NeurIPS,
pp. 3315-3323, 2016. https://arxiv.org/abs/1610.02413
• [Pleiss+17] Geoff Pleiss, Manish Raghavan, Felix Wu, Jon
Kleinberg, and Kilian Q. Weinberger. On Fairness and
Calibration. In: NeurIPS, pp. 5680-5689, 2017. https://arxiv.org/
abs/1709.02012
• [Dwork+12] Cynthia Dwork, Moritz Hardt, Toniann
Pitassi, Omer Reingold, Rich Zemel. Fairness Through
Awareness. In: the 3rd innovations in theoretical computer
science conference, pp. 214-226, 2012. https://arxiv.org/abs/
1104.3913
72.
References 2
• [Agarwal+18]Alekh Agarwal, Alina Beygelzimer, Miroslav
Dudík, John Langford, and Hanna Wallach. A Reductions
Approach to Fair Classification. In: ICML, PMLR 80, pp.
60-69, 2018. https://arxiv.org/abs/1803.02453
• [Agarwal+19] Alekh Agarwal, Miroslav Dudík, and Zhiwei
Steven Wu. Fair Regression: Quantitative Definitions and
Reduction-based Algorithms. In: ICML, PMLR 97, pp. 120-129,
2019. https://arxiv.org/abs/1905.12843
• [Zafar+13] Rich Zemel, Yu Wu, Kevin Swersky, Toni Pitassi,
and Cynthia Dwork. Learning Fair Representations. In: ICML,
PMLR 28, pp. 325-333, 2013.
73.
References 3
• [Zhao+19]Han Zhao, Geoffrey J. Gordon. Inherent Tradeoffs in
Learning Fair Representations. In: NeurIPS, 2019, to appear.
https://arxiv.org/abs/1906.08386
• [Xie+16] Qizhe Xie, Zihang Dai, Yulun Du, Eduard
Hovy, Graham Neubig. Controllable Invariance through
Adversarial Feature Learning. In: NeurIPS, pp. 585-596, 2016.
https://arxiv.org/abs/1705.11122
• [Moyer+18] Daniel Moyer, Shuyang Gao, Rob
Brekelmans, Greg Ver Steeg, and Aram Galstyan. Invariant
Representations without Adversarial Training. In: NeurIPS, pp.
9084-9893, 2018. https://arxiv.org/abs/1805.09458
74.
References 4
• [Woodworth+18]Blake Woodworth, Suriya Gunasekar, Mesrob
I. Ohannessian, Nathan Srebro. Learning Non-Discriminatory
Predictors. In: COLT, pp. 1920-1953, 2017. https://arxiv.org/abs/
1702.06081
• [Cotter+19] Andrew Cotter, Maya Gupta, Heinrich
Jiang, Nathan Srebro, Karthik Sridharan, Serena Wang, Blake
Woodworth, Seungil You. Training Well-Generalizing
Classifiers for Fairness Metrics and Other Data-Dependent
Constraints. In: ICML, PMLR 97, pp. 1397-1405, 2019. https://
arxiv.org/abs/1807.00028
• [Rothblum+18] Guy N. Rothblum, Gal Yona. Probably
Approximately Metric-Fair Learning. In: ICML, PMLR 80, pp.
5680-5688, 2018. https://arxiv.org/abs/1803.03242
75.
References 5
• [Joseph+16]Matthew Joseph, Michael Kearns, Jamie
Morgenstern, Aaron Roth. Fairness in Learning: Classic and
Contextual Bandits. In: NeurIPS, pp. 325-333, 2016.
• [Liu+17] Yang Liu, Goran Radanovic, Christos
Dimitrakakis, Debmalya Mandal, David C. Parkes. Calibrated
Fairness in Bandits. In: 4th Workshop on Fairness,
Accountability, and Transparency in Machine Learning
(FATML), 2017. https://arxiv.org/abs/1707.01875
• [Gillen+18] Stephen Gillen, Christopher Jung, Michael
Kearns, Aaron Roth. Online Learning with an Unknown
Fairness Metric. In: NeurIPS, pp. 2600-2609, 2018. https://
arxiv.org/abs/1802.06936
76.
References 6
• [Jabbari+17]Shahin Jabbari, Matthew Joseph, Michael Kearns, Jamie
Morgenstern, Aaron Roth. Fairness in Reinforcement Learning. In:
ICML, PMLR 70, pp. 1617-1626, 2017. https://arxiv.org/abs/1611.03071
• [Liu+18] Lydia T. Liu, Sarah Dean, Esther Rolf, Max
Simchowitz, Moritz Hardt. Delayed Impact of Fair Machine Learning.
In: ICML, PMLR 80, pp. 3150-3158, 2018. https://arxiv.org/abs/
1803.04383
• [Aivodji+19] Ulrich Aïvodji, Hiromi Arai, Olivier Fortineau, Sébastien
Gambs, Satoshi Hara, Alain Tapp. Fairwashing: the risk of
rationalization. In: ICML, 2019. https://arxiv.org/abs/1901.09749
• [Fukuchi+20] Kazuto Fukuchi, Satoshi Hara, Takanori Maehara. Faking
Fairness via Stealthily Biased Sampling. In: AAAI, Special Track on AI
for Social Impact (AISI), 2020, to appear. https://arxiv.org/abs/
1901.08291
On the Long-termImpact of Algorithmic Decision
Policies: Effort Unfairness and Feature Segregation
through Social Learning [Heidari+ICML 19]
• https://arxiv.org/abs/1903.01209
• effortを導入して,努力した量に対する報酬の違いによっ
て公平性を定義
Near Neighbor: Whois the Fairest of
Them All? [Har-Peled+NeurIPS 19]
• https://arxiv.org/abs/1906.02640
• Fair nearest neighbor問題
• 半径r内の点をuniformにサンプルする問題
• 計算量の解析など













![公平性基準
• 様々な公平性基準
• Demographic parity
• Equalized odds [Hardt+16]
• Calibration [Pleiss+17]
• Individual fairness [Dwork+12]](https://image.slidesharecdn.com/present-191126042307/75/AI-15-2048.jpg)

![Equalized odds [Hardt+16]
• と を一致させるように学習できる
• Demographic parityではできない
Equalized odds
ℙ{ ̂Y ∈ 𝒜|Y = y, S = s} = ℙ{ ̂Y ∈ 𝒜|Y = y, S = s′}
任意の𝒜, y, s, s′について
Y ̂Y
採用 非採用男性
採用 非採用女性
真の採用分布
学習
採用 非採用
採用 非採用
公平 =
学習の結果変化した部分
(緑の部分)の一致](https://image.slidesharecdn.com/present-191126042307/75/AI-17-2048.jpg)
![Calibration [Pleiss+17]
• である確率の予測値を とする
• である予測が のみによって決まるように制約
Y = 1 ̂p
Y = 1 ̂p
Calibration
ℙ{Y = 1| ̂p = p, S = s} = p
任意のp, sについて
男性 採用 非採用
p
̂p = p|S = 男性](https://image.slidesharecdn.com/present-191126042307/75/AI-18-2048.jpg)
![Individual fairness [Dwork+12]
• 性別以外全く同じ人がいれば採否も同じにするべき
• 似たような人は似た結果を受け取るべき
• 確率的予測関数 :
•
Lipschitz property
任意のx, x′について
D( f(x), f(x′)) ≤ d(x, x′)
≈ ⟹
f : 𝒳 → Δ(𝒴)
結果の分布間の
距離](https://image.slidesharecdn.com/present-191126042307/75/AI-19-2048.jpg)



![Reduction Approach [Agarwal+18]
• 確率的な分類器 を学習
• は分類器 上の分布
• Reduction
• 学習問題をコストセンシティブ学習の系列に置き換え
Q
Q f
minQ 𝔼f∼Qℙ{f(X) ≠ Y} sub to M𝔼f∼Q[μ(f )] ≤ c
最適化問題
公平性基準を有限個の制約で表現
例 DP)
𝔼{f(X)|S = 0} = 𝔼{f(X)}
𝔼{f(X)|S = 1} = 𝔼{f(X)}](https://image.slidesharecdn.com/present-191126042307/75/AI-23-2048.jpg)
![Reduction Approach [Agarwal+18]
minQ 𝔼f∼Qℙ{f(X) ≠ Y} sub to M𝔼f∼Q[μ(f )] ≤ c
元の最適化問題
maxλ∈ℝK
+,∥λ∥≤B minQ 𝔼f∼Qℙ{f(X) ≠ Y} + λ⊤
(M𝔼f∼Q[μ(f )] − c)
制約無し最適化問題
ラグランジュ乗数
交互最適化によって鞍点を探索](https://image.slidesharecdn.com/present-191126042307/75/AI-24-2048.jpg)



![Fair Regression: Quantitative Definitions
and Reduction-based Algorithms
[Agarwal+19]
• 回帰における公平性を扱えるように拡張
• Demographic parityか 全てのグループの損失が一定以
下 という公平性制約が扱える
連続変数の密度分布の一致は難しい 離散化してビンを当てる
分類問題に書き換え](https://image.slidesharecdn.com/present-191126042307/75/AI-28-2048.jpg)

![Fair Representation [Zafar+13]
• センシティブ属性に依存しないような表現の獲得
g( )
g( )
z](https://image.slidesharecdn.com/present-191126042307/75/AI-30-2048.jpg)
![Fair Representation [Zafar+13]
• センシティブ属性に依存しないような表現の獲得
g( )
g( )
z](https://image.slidesharecdn.com/present-191126042307/75/AI-31-2048.jpg)
![Inherent Tradeoffs in Learning Fair
Representations [Zhao+19]
• Fair Reperesentationから分類器を作った時に公平性が
どうなるか解析
g( )
g( )
z
f( )=A氏
z
分類器
ここまでは公平
これは公平?](https://image.slidesharecdn.com/present-191126042307/75/AI-32-2048.jpg)

![敵対的学習を使った手法[Xie+16]
• DPを元にした公平性=
• 表現からセンシティブ属性が識別できない
• 実際にセンシティブ属性を識別するモデルを作る
• このモデルの識別精度が悪くなるように学習
g( )=
f( )=A氏
d( )=黒人z
z
z
表現器
分類器
識別器
分類器はなるべく
当たるように
識別器はなるべく
外れるように](https://image.slidesharecdn.com/present-191126042307/75/AI-34-2048.jpg)
![実験結果 [Xie+16]
公平性Random guessと同等しか
センシティブ属性を予測できない
提案手法(右端)の予測精度が高い](https://image.slidesharecdn.com/present-191126042307/75/AI-35-2048.jpg)
![VAEとInformation bottleneckを
元にした方法[Moyer+18]
• 敵対的学習の問題:学習が遅い!
• Variational Auto Encoder (VAE)を元に効率的な学習
minf Likelihood(f(X), Y) + ηI(f(X), S)
最適化問題
VAEのテクニックを使って上記の問題を近似しながら解く](https://image.slidesharecdn.com/present-191126042307/75/AI-36-2048.jpg)



![Learning Non-Discriminatory Predictors
[Woodworth+18]
• Equalized-oddsを保証するためのアルゴリズム
[Hardt+ICML 16]
• スコアベースの分類器を学習
• スコア0以上 <=>
• ROCが一致するようにスコアの閾値を調節
• このアルゴリズムはsuboptimal
• post-hocでは1/2エラーだが
Equalized-odds制約を満たすエラーが小さい
分類器が存在する問題が作れる
̂Y = 1](https://image.slidesharecdn.com/present-191126042307/75/AI-43-2048.jpg)


![Training Well-Generalizing Classifiers for
Fairness Metrics and Other Data-
Dependent Constraints [Cotter+19]
• [Woodworth+18]のさらなる一般化
• 目的関数が分類誤差
• 制約が公平性
• Reductionと似た戦略でアルゴリズムを構築
• ただし[Woodworth+18]と同様の戦略も使う
• データセットを2つに分けて目的関数と制約を別々に評価
minθ 𝔼[ℓ0(X, θ)] sub to 𝔼[ℓi(X, θ)] ≤ 0
対象とする問題](https://image.slidesharecdn.com/present-191126042307/75/AI-46-2048.jpg)



![Probably Approximately Metric-Fair
Learning [Rothblum+18]
• である確率を返す分類器 を学習
• ゴール:
• 上記の制約のもと真のラベルと の 損失を最小化
̂Y = 1 h : 𝒳 → [0,1]
h ℓ0
ℙx,x′{|h(x) − h(x′)| > d(x, x′) + γ} ≤ α
-個人公平性制約(γ, α)](https://image.slidesharecdn.com/present-191126042307/75/AI-50-2048.jpg)



![Fair bandit [Joseph+16]
• 報酬の大きさ = その人の能力の高さ
• 能力が高い人以外を優先的に選んではいけない
πi(t) > πj(t) only if fi(x(t)
i ) > fj(x(t)
j )
能力主義的公平性
A B C D E
fi(x(t)
i )](https://image.slidesharecdn.com/present-191126042307/75/AI-54-2048.jpg)


![Calibrated Fairness in Bandits [Liu+17]
• 個人公平性制約を満たしCalibration違反を最小にする
πi(t) ≠ ℙ{i = arg maxj rj}
Calibration違反
D(π(t)
i , π(t)
j ) ≤ ϵ1D(ri, rj) + ϵ2
個人公平性制約](https://image.slidesharecdn.com/present-191126042307/75/AI-57-2048.jpg)


![Online Learning with an Unknown
Fairness Metric [Gillen+18]
• 線形文脈付きバンディット問題+個人公平性制約
• 距離函数を知らない
• 代わりにフィードバックに距離情報が含まれる
|πi(t) − πj(t)| ≤ d(x(t)
i , x(t)
j )
個人公平性制約
ユーザ情報x(t)
i
広告分布π(t)
フィードバックr(t)
距離オラクルO(t)
制約違反している
ペアを返す
実際には ぐらいの
違反を許す
ϵ](https://image.slidesharecdn.com/present-191126042307/75/AI-60-2048.jpg)



![Fairness in Reinforcement Learning
[Jabbari+17]
• 強化学習において[Joseph+16]と同様な公平性制約
• 結果
• Exactな公平性を達成するには指数的試行が必要
• 最適なポリシーが得られるまでに十分なステップ数は
• 割引率 については指数的でこれが最適
• 他の項に関しては多項式
ϵ
1/(1 − γ)
πi(t) > πj(t) only if fi(s(t)
i ) > fj(s(t)
j )
能力主義的公平性](https://image.slidesharecdn.com/present-191126042307/75/AI-64-2048.jpg)


![Delayed Effect [Liu+18]
• 学習とテストの間に時間的隔たりがある
• その間にサンプルの分布が変化する
• Demographic parityの正当性 (入試)
• 貧困層の学生を取らないことで将来貧困が拡大することの防止
• DP, EOの制約をつけた時予測時の性能はどうなるか?
時刻
データ収集+学習 予測
サンプルの分布が変化](https://image.slidesharecdn.com/present-191126042307/75/AI-67-2048.jpg)

![公平性を装う技術
• 本当は不公平であるのにかかわらず世間には公平に見せか
ける
• 不公平なモデル から 公平な説明 が生成できる
[Aivodji+19]
• 不公平なモデル から 公平なラベルづけデータセット を
生成できる [Fukuchi+20]
f
これは不公平
説明
ベンチマークデータ
これは公平](https://image.slidesharecdn.com/present-191126042307/75/AI-69-2048.jpg)

![References 1
• [Hardt+16] Moritz Hardt, Eric Price, and Nathan Srebro.
Equality of Opportunity in Supervised Learning. In: NeurIPS,
pp. 3315-3323, 2016. https://arxiv.org/abs/1610.02413
• [Pleiss+17] Geoff Pleiss, Manish Raghavan, Felix Wu, Jon
Kleinberg, and Kilian Q. Weinberger. On Fairness and
Calibration. In: NeurIPS, pp. 5680-5689, 2017. https://arxiv.org/
abs/1709.02012
• [Dwork+12] Cynthia Dwork, Moritz Hardt, Toniann
Pitassi, Omer Reingold, Rich Zemel. Fairness Through
Awareness. In: the 3rd innovations in theoretical computer
science conference, pp. 214-226, 2012. https://arxiv.org/abs/
1104.3913](https://image.slidesharecdn.com/present-191126042307/75/AI-71-2048.jpg)
![References 2
• [Agarwal+18] Alekh Agarwal, Alina Beygelzimer, Miroslav
Dudík, John Langford, and Hanna Wallach. A Reductions
Approach to Fair Classification. In: ICML, PMLR 80, pp.
60-69, 2018. https://arxiv.org/abs/1803.02453
• [Agarwal+19] Alekh Agarwal, Miroslav Dudík, and Zhiwei
Steven Wu. Fair Regression: Quantitative Definitions and
Reduction-based Algorithms. In: ICML, PMLR 97, pp. 120-129,
2019. https://arxiv.org/abs/1905.12843
• [Zafar+13] Rich Zemel, Yu Wu, Kevin Swersky, Toni Pitassi,
and Cynthia Dwork. Learning Fair Representations. In: ICML,
PMLR 28, pp. 325-333, 2013.](https://image.slidesharecdn.com/present-191126042307/75/AI-72-2048.jpg)
![References 3
• [Zhao+19] Han Zhao, Geoffrey J. Gordon. Inherent Tradeoffs in
Learning Fair Representations. In: NeurIPS, 2019, to appear.
https://arxiv.org/abs/1906.08386
• [Xie+16] Qizhe Xie, Zihang Dai, Yulun Du, Eduard
Hovy, Graham Neubig. Controllable Invariance through
Adversarial Feature Learning. In: NeurIPS, pp. 585-596, 2016.
https://arxiv.org/abs/1705.11122
• [Moyer+18] Daniel Moyer, Shuyang Gao, Rob
Brekelmans, Greg Ver Steeg, and Aram Galstyan. Invariant
Representations without Adversarial Training. In: NeurIPS, pp.
9084-9893, 2018. https://arxiv.org/abs/1805.09458](https://image.slidesharecdn.com/present-191126042307/75/AI-73-2048.jpg)
![References 4
• [Woodworth+18] Blake Woodworth, Suriya Gunasekar, Mesrob
I. Ohannessian, Nathan Srebro. Learning Non-Discriminatory
Predictors. In: COLT, pp. 1920-1953, 2017. https://arxiv.org/abs/
1702.06081
• [Cotter+19] Andrew Cotter, Maya Gupta, Heinrich
Jiang, Nathan Srebro, Karthik Sridharan, Serena Wang, Blake
Woodworth, Seungil You. Training Well-Generalizing
Classifiers for Fairness Metrics and Other Data-Dependent
Constraints. In: ICML, PMLR 97, pp. 1397-1405, 2019. https://
arxiv.org/abs/1807.00028
• [Rothblum+18] Guy N. Rothblum, Gal Yona. Probably
Approximately Metric-Fair Learning. In: ICML, PMLR 80, pp.
5680-5688, 2018. https://arxiv.org/abs/1803.03242](https://image.slidesharecdn.com/present-191126042307/75/AI-74-2048.jpg)
![References 5
• [Joseph+16] Matthew Joseph, Michael Kearns, Jamie
Morgenstern, Aaron Roth. Fairness in Learning: Classic and
Contextual Bandits. In: NeurIPS, pp. 325-333, 2016.
• [Liu+17] Yang Liu, Goran Radanovic, Christos
Dimitrakakis, Debmalya Mandal, David C. Parkes. Calibrated
Fairness in Bandits. In: 4th Workshop on Fairness,
Accountability, and Transparency in Machine Learning
(FATML), 2017. https://arxiv.org/abs/1707.01875
• [Gillen+18] Stephen Gillen, Christopher Jung, Michael
Kearns, Aaron Roth. Online Learning with an Unknown
Fairness Metric. In: NeurIPS, pp. 2600-2609, 2018. https://
arxiv.org/abs/1802.06936](https://image.slidesharecdn.com/present-191126042307/75/AI-75-2048.jpg)
![References 6
• [Jabbari+17] Shahin Jabbari, Matthew Joseph, Michael Kearns, Jamie
Morgenstern, Aaron Roth. Fairness in Reinforcement Learning. In:
ICML, PMLR 70, pp. 1617-1626, 2017. https://arxiv.org/abs/1611.03071
• [Liu+18] Lydia T. Liu, Sarah Dean, Esther Rolf, Max
Simchowitz, Moritz Hardt. Delayed Impact of Fair Machine Learning.
In: ICML, PMLR 80, pp. 3150-3158, 2018. https://arxiv.org/abs/
1803.04383
• [Aivodji+19] Ulrich Aïvodji, Hiromi Arai, Olivier Fortineau, Sébastien
Gambs, Satoshi Hara, Alain Tapp. Fairwashing: the risk of
rationalization. In: ICML, 2019. https://arxiv.org/abs/1901.09749
• [Fukuchi+20] Kazuto Fukuchi, Satoshi Hara, Takanori Maehara. Faking
Fairness via Stealthily Biased Sampling. In: AAAI, Special Track on AI
for Social Impact (AISI), 2020, to appear. https://arxiv.org/abs/
1901.08291](https://image.slidesharecdn.com/present-191126042307/75/AI-76-2048.jpg)

![Training Well-Generalizing Classifiers for
Fairness Metrics and Other Data-
Dependent Constraints [Cotter+ICML 19]
• https://arxiv.org/abs/1807.00028
• データ依存制約の汎化性能の解析
• [Woodworth+COLT 18]の拡張
• [Agarwal+ICML 18]を元に解析](https://image.slidesharecdn.com/present-191126042307/75/AI-78-2048.jpg)
![Fairness without Harm: Decoupled
Classifiers with Preference Guarantees
[Ustun+ICML 19]
• http://proceedings.mlr.press/v97/ustun19a
• Preference-basedな公平性を保証
• rationalityとenvy-freenessを目指した学習手法
• [Zafar+ICML 18]の後続
• [Dwork+ICML'18]の拡張](https://image.slidesharecdn.com/present-191126042307/75/AI-79-2048.jpg)
![Fairness risk measures
[Williamson+ICML'19]
• https://arxiv.org/abs/1901.08665
• subgroupを考慮した新しいFairness scoreを与える
• 持つべき公理を定義してそこからスコアを求める
• その定義のもと学習アルゴリズムを与える
• [Zafar+WWW 18], [Dwork+ICML 18],
[Donini+NeurIPS 18]の後続](https://image.slidesharecdn.com/present-191126042307/75/AI-80-2048.jpg)
![On the Long-term Impact of Algorithmic Decision
Policies: Effort Unfairness and Feature Segregation
through Social Learning [Heidari+ICML 19]
• https://arxiv.org/abs/1903.01209
• effortを導入して,努力した量に対する報酬の違いによっ
て公平性を定義](https://image.slidesharecdn.com/present-191126042307/75/AI-81-2048.jpg)
![Obtaining fairness using optimal
transport theory [Barrio+ICML 19]
• https://arxiv.org/abs/1806.03195
• Wassserstain distanceを使ってDisparete Impact
scoreを拡張
• 最適な(approximately) Fairなデータ分布を求めるアルゴ
リズムを開発
• [Feldman+KDD 15]の後続](https://image.slidesharecdn.com/present-191126042307/75/AI-82-2048.jpg)
![Fair Regression: Quantitative Definitions
and Reduction-based Algorithms
[Agarwal+ ICML19]
• https://arxiv.org/abs/1905.12843
• 回帰における公平性
• リプシッツ関数を予測する問題
• Demographic parityか 全てのグループの損失が一定以
下 が公平性制約
• 自身の[Agrawal+ICML 18]の後続](https://image.slidesharecdn.com/present-191126042307/75/AI-83-2048.jpg)
![Differentially Private Fair Learning
[Jagielski+ICML 19]
• https://arxiv.org/abs/1812.02696
• 差分プライバシーと同時にEqualized oddsを保証する方
法を開発
• Reduction approach [Agrawal+ICML 18]と同様な方法
で公平性の保証を行う](https://image.slidesharecdn.com/present-191126042307/75/AI-84-2048.jpg)
![Fairness-Aware Learning for Continuous
Attributes and Treatments [Mary+ICML 19]
• http://proceedings.mlr.press/v97/mary19a
• 回帰への対応や連続センシティブ属性への対応
• 独立性のmeasureとして機能する指標HGRを使う
• 他の指標は独立かそうでないかしかわからない](https://image.slidesharecdn.com/present-191126042307/75/AI-85-2048.jpg)
![The implicit fairness criterion of
unconstrained learning [Liu+ICML 19]
• https://arxiv.org/abs/1808.10013
• 制約を設けないリスク最小化がCalibrationを達成する最
も良い方法であることを証明](https://image.slidesharecdn.com/present-191126042307/75/AI-86-2048.jpg)
![Flexibly Fair Representation Learning by
Disentanglement [Creager+ICML 19]
• https://arxiv.org/abs/1906.02589
• Fairなセンシティブ属性の分布変化にadaptiveな表現学習
の方法の開発
• VAEを元にした手法](https://image.slidesharecdn.com/present-191126042307/75/AI-87-2048.jpg)
![Learning Optimal Fair Policies
[Nabi+ICML 19]
• https://arxiv.org/abs/1809.02244
• causalベースの公平性定義
• 逐次意思決定における公平性
• 最適な意思決定指針とそれを推定するアルゴリズムの開発
• 自身の[Nabi+AAAI 18]の拡張](https://image.slidesharecdn.com/present-191126042307/75/AI-88-2048.jpg)
![Toward Controlling Discrimination in
Online Ad Auctions [Celis+ICML 19]
• https://arxiv.org/abs/1901.10450
• Ad allocationにおける不公平に対処
• Fair coverageを達成するように制約
• revenueの制約付きnon-convex最適化を行うが,fact
convergenceを証明](https://image.slidesharecdn.com/present-191126042307/75/AI-89-2048.jpg)
![Stable and Fair Classification
[Huang+ICML 19]
• https://arxiv.org/abs/1902.07823
• Regularized ERMに公平性制約 or 公平性正則化を入れ
た時のstabilityを解析](https://image.slidesharecdn.com/present-191126042307/75/AI-90-2048.jpg)
![Noise-tolerant fair classification
[Lamy+NeurIPS 19]
• https://arxiv.org/abs/1901.10837
• センシティブ属性にノイズが入っている場合における学習
アルゴリズム
• ノイズを考慮してより強い制約を科す
• 差分プライベートなセンシティブ属性を使った学習として
みたときの解析もあり](https://image.slidesharecdn.com/present-191126042307/75/AI-91-2048.jpg)
![The Fairness of Risk Scores Beyond
Classification: Bipartite Ranking and the
xAUC Metric [Kallus+NeurIPS 19]
• https://arxiv.org/abs/1902.05826
• スコアベースのランキング予測問題における公平性
• 新しく定義したxAUCの一致性によって公平性を定義](https://image.slidesharecdn.com/present-191126042307/75/AI-92-2048.jpg)
![Policy Learning for Fairness in Ranking
[Singh+NeurIPS 19]
• https://arxiv.org/abs/1902.04056
• 文章セットとそのrelevance scoreが与えられる
• その上で公平性に配慮しつつutilityを最大にする確率的ラ
ンキングを求める](https://image.slidesharecdn.com/present-191126042307/75/AI-93-2048.jpg)
![Average Individual Fairness: Algorithms,
Generalization and Experiments
[Kearns+NeurIPS 19]
• https://arxiv.org/abs/1905.10607
• 同一個人に複数の2値ラベルがデータとして与えられる
• ラベルはiidに複数の関数が生成され,別にiidに生成され
た個人に関数を適応する形でえらえる
• ゴールは誤差最小となる関数の分布を得ること
• この設定上で関数の分布に対して平均的な個人公平性を与
えて
• その学習アルゴリズムとサンプル複雑度を求めている](https://image.slidesharecdn.com/present-191126042307/75/AI-94-2048.jpg)
![Paradoxes in Fair Machine Learning
[Goelz+NeurIPS 19]
• https://papers.nips.cc/paper/9043-paradoxes-in-
fair-machine-learning
• 複数のbucketがあってそれにリソース配置する問題にお
いてequalized odds制約を課す
• 制約下における最適配置を求めた
• [Hardt+ICML 16]の後続](https://image.slidesharecdn.com/present-191126042307/75/AI-95-2048.jpg)
![Leveraging Labeled and Unlabeled Data
for Consistent Fair Binary Classification
[Chzhen+NeurIPS 19]
• https://arxiv.org/abs/1906.05082
• Equal opportunity制約下でのsemi-supervised
learning
• consistencyの証明
• AsymptoticにEqual opportunityの達成と同時に最適
分類器に収束](https://image.slidesharecdn.com/present-191126042307/75/AI-96-2048.jpg)
![Near Neighbor: Who is the Fairest of
Them All? [Har-Peled+NeurIPS 19]
• https://arxiv.org/abs/1906.02640
• Fair nearest neighbor問題
• 半径r内の点をuniformにサンプルする問題
• 計算量の解析など](https://image.slidesharecdn.com/present-191126042307/75/AI-97-2048.jpg)
![Inherent Tradeoffs in Learning Fair
Representations [Zhao+NeurIPS 19]
• https://arxiv.org/abs/1906.08386
• [Zemel+ICML 13のFair Reperesentationから分類器を
作った時に公平性がどうなるか解析
• またutility-fairness trade-offも解析](https://image.slidesharecdn.com/present-191126042307/75/AI-98-2048.jpg)
![Exploring Algorithmic Fairness in Robust
Graph Covering Problems
[Rahmattalabi+NeurIPS 19]
• https://papers.nips.cc/paper/9707-exploring-
algorithmic-fairness-in-robust-graph-covering-
problems
• Robust graph cover問題における公平性
• ノードがグループで分かれている
• 少なくともW個の同一グループのノードを選択する必要が
ある
• 公平性制約によるcoverの悪さの解析やNP-Hardなので近
似アルゴリズムを開発](https://image.slidesharecdn.com/present-191126042307/75/AI-99-2048.jpg)






![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)
![[読会]Long tail learning via logit adjustment](https://cdn.slidesharecdn.com/ss_thumbnails/long-taillearningvialogitadjustment-211229095016-thumbnail.jpg?width=640&height=640&fit=bounds)












