第4回 Machine Learning 15 minutes! http://machine-learning15minutes.connpass.com/event/36652/ LT資料 機械学習で大富豪プログラムを作った話と、DQNがアドベンチャーゲームをプレーできるようになった話





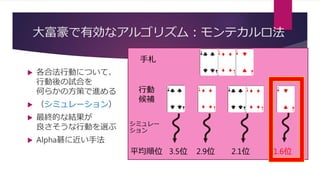
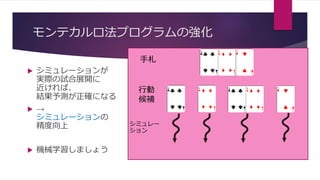



![学習手法
重みパラメータ 𝜃 の更新式
𝜃 ← 𝜃 +
𝛼
𝑇
[𝜙 𝑠, 𝑥 − 𝑏∈𝐴{𝜙 𝑠, 𝑏 𝜋 𝜃(𝑠, 𝑏)}]
𝑠 : 主観的な状態
𝐴 : sにおける合法行動全体
の集合
𝜃 ∶ 重みベクトル(学習対象)
𝑇 : 温度
𝛼 :学習率](https://image.slidesharecdn.com/ml15mohto-160925232230/85/slide-11-320.jpg)


























![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Tutorial] Sentence Representation](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsentencerepresentation-181121030653-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Hybrid Reward Architecture for Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl20170630-170707003146-thumbnail.jpg?width=640&height=640&fit=bounds)






