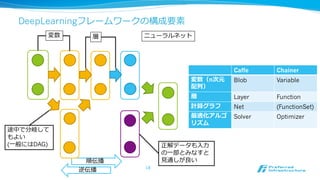
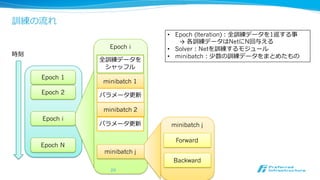
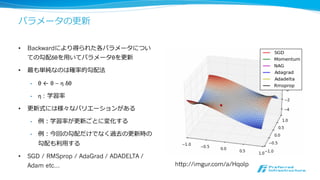
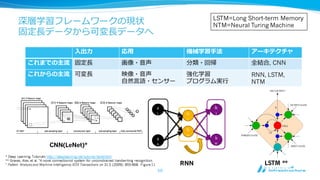
深層学習フレームワークの現状
固定⻑⾧長データから可変⻑⾧長データへ
x
1
x
N
h
1
h
H
k
M
k
1
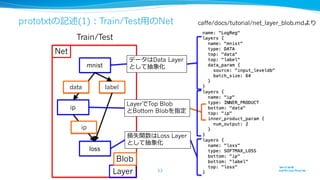
⼊入出⼒力力 応⽤用 機械学習⼿手法アーキテクチャ
これまでの主流流 固定⻑⾧長 画像・⾳音声 分類・回帰 全結合, CNN
これからの主流流 可変⻑⾧長 映像・⾳音声
⾃自然⾔言語・センサー
強化学習
プログラム実⾏行行
RNN, LSTM,
NTM
CNN(LeNet)*
RNN LSTM **
50
* Deep Learning Tutorials http://deeplearning.net/tutorial/lenet.html
** Graves, Alex, et al. "A novel connectionist system for unconstrained handwriting recognition.
" Pattern Analysis and Machine Intelligence, IEEE Transactions on 31.5 (2009): 855-868. Figure 11
LSTM=Long Short-term Memory
NTM=Neural Turing Machine
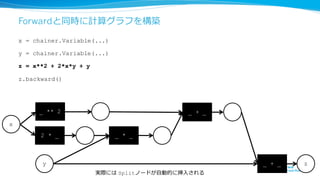
計算グラフ構築のパラダイム:Define-by-Run
• データの順伝播とそのデータに対する計算グラフの構築を
同時に⾏行行う
• ⻑⾧長所
•順伝播を通常のプログラムで記述できる
• コントロールフロー(条件分岐、forループ)を計
算グラフ構築に利利⽤用可能
• 設定ファイル⽤用のミニ⾔言語を作る必要がない
• 訓練データごとに異異なる計算グラフを変更更可能
• 短所
• 訓練データ全体に渡る最適化は⾃自明ではない
• 計算グラフを動的に構築するので、メモリ管理理が必要
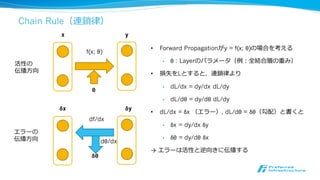
x yf
x = chainer.Variable(...)
y = f(x)
z = g(x)
zg
データフィード
= 計算グラフ構築
Chainerはこの
パラダイムを採⽤用
57.
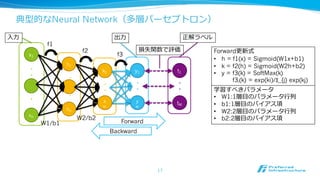
Chainerの構成要素(1):Variable / Function
•Variable:n次元配列列(ndarray/GPUArray)のラッパー
• x = chainer.Variable(numpy.ndarray(...))
• 元の配列列はx.dataに格納される
• Function:Variableの操作の基本単位
• Variable(s)を受け取り、Variable(s)を出⼒力力する
• Functionは⾃自分がどのVariableを⼊入⼒力力としたかを記憶する
• 出⼒力力のVariableは⾃自分がどのFunctionから出⼒力力されたかを記憶する
x yf
x = chainer.Variable(...)
y = f(x)
z = g(x)
zg
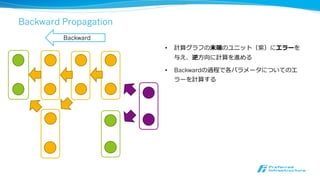
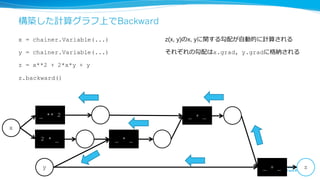
構築した計算グラフ上でBackward
x = chainer.Variable(...)
y= chainer.Variable(...)
z = x**2 + 2*x*y + y
z.backward()
z(x, y)のx, yに関する勾配が⾃自動的に計算される
それぞれの勾配はx.grad, y.gradに格納される
x
y
_ ** 2
2 * _ _ * _
_ + _ z
_ + _
60.
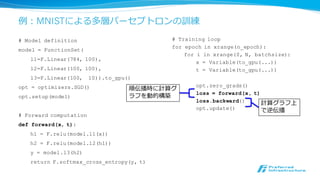
例例:MNISTによる多層パーセプトロンの訓練
# Model definition
model= FunctionSet(
l1=F.Linear(784, 100),
l2=F.Linear(100, 100),
l3=F.Linear(100, 10)).to_gpu()
opt = optimizers.SGD()
opt.setup(model)
# Forward computation
def forward(x, t):
h1 = F.relu(model.l1(x))
h2 = F.relu(model.l2(h1))
y = model.l3(h2)
return F.softmax_cross_entropy(y, t)
# Training loop
for epoch in xrange(n_epoch):
for i in xrange(0, N, batchsize):
x = Variable(to_gpu(...))
t = Variable(to_gpu(...))
opt.zero_grads()
loss = forward(x, t)
loss.backward()
opt.update()
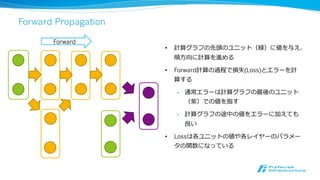
順伝播時に計算グ
ラフを動的構築
計算グラフ上
で逆伝播
61.
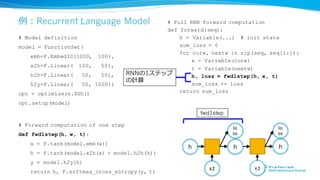
例例:Recurrent Language Model
#Model definition
model = FunctionSet(
emb=F.EmbedID(1000, 100),
x2h=F.Linear( 100, 50),
h2h=F.Linear( 50, 50),
h2y=F.Linear( 50, 1000))
opt = optimizers.SGD()
opt.setup(model)
# Forward computation of one step
def fwd1step(h, w, t):
x = F.tanh(model.emb(w))
h = F.tanh(model.x2h(x) + model.h2h(h))
y = model.h2y(h)
return h, F.softmax_cross_entropy(y, t)
# Full RNN forward computation
def forward(seq):
h = Variable(...) # init state
sum_loss = 0
for curw, nextw in zip(seq, seq[1:]):
x = Variable(curw)
t = Variable(nextw)
h, loss = fwd1step(h, x, t)
sum_loss += loss
return sum_loss
h h
x,t
lo
ss
x,t
lo
ss
h
fwd1step
RNNの1ステップ
の計算
例例:MNISTによる多層パーセプトロンの訓練
# Model definition
model= FunctionSet(
l1=F.Linear(784, 100),
l2=F.Linear(100, 100),
l3=F.Linear(100, 10)).to_gpu()
opt = optimizers.SGD()
opt.setup(model)
# Forward computation
def forward(x, t):
h1 = F.relu(model.l1(x))
h2 = F.relu(model.l2(h1))
y = model.l3(h2)
return F.softmax_cross_entropy(y, t)
# Training loop
for epoch in xrange(n_epoch):
for i in xrange(0, N, batchsize):
x = Variable(to_gpu(...))
t = Variable(to_gpu(...))
opt.zero_grads()
loss = forward(x, t)
loss.backward()
opt.update()
パラメータ・勾配を
まとめてGPUへ転送
Optimizerにパラ
メータ・勾配をま
とめてセット
64.
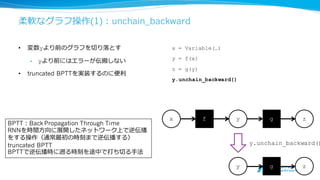
柔軟なグラフ操作(1):unchain_backward
• 変数yより前のグラフを切切り落落とす
• yより前にはエラーが伝搬しない
•truncated BPTTを実装するのに便便利利
x f y g z
y g z
y.unchain_backward()
x = Variable(…)
y = f(x)
z = g(y)
y.unchain_backward()
BPTT:Back Propagation Through Time
RNNを時間⽅方向に展開したネットワーク上で逆伝播
をする操作(通常最初の時刻まで逆伝播する)
truncated BPTT
BPTTで逆伝播時に遡る時刻を途中で打ち切切る⼿手法
65.
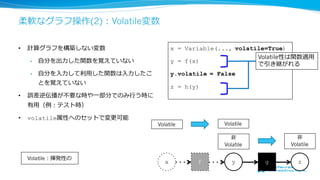
柔軟なグラフ操作(2):Volatile変数
• 計算グラフを構築しない変数
• ⾃自分を出⼒力力した関数を覚えていない
•⾃自分を⼊入⼒力力して利利⽤用した関数は⼊入⼒力力したこ
とを覚えていない
• 誤差逆伝播が不不要な時や⼀一部分でのみ⾏行行う時に
有⽤用(例例:テスト時)
• volatile属性へのセットで変更更可能
x = Variable(..., volatile=True)
y = f(x)
y.volatile = False
z = h(y)
x f y g z
Volatile
Volatile:揮発性の
⾮非
Volatile
Volatile
⾮非
Volatile
Volatile性は関数適⽤用
で引き継がれる
66.
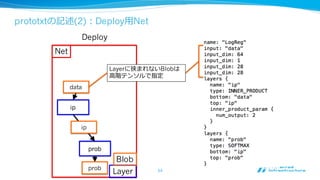
Caffe Reference Modelサポート
•Caffe Model Zooで提供されているBVLC
Reference ModelをChainerのfunctionとして利利
⽤用可能
func =
CaffeFunction('path/to/bvlc_reference_
caffenet.caffemodel')
x = Variable(…)
y, = func(inputs={'data': x},
outputs=['fc8'])
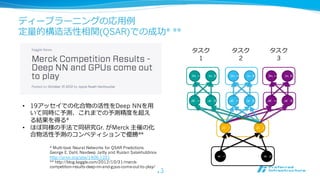
ディープラーニングの応⽤用例例
定量量的構造活性相関(QSAR)での成功* **
71
* Multi-taskNeural Networks for QSAR Predictions
George E. Dahl, Navdeep Jaitly and Ruslan Salakhutdinov
http://arxiv.org/abs/1406.1231
** http://blog.kaggle.com/2012/10/31/merck-
competition-results-deep-nn-and-gpus-come-out-to-play/
• 19アッセイでの化合物の活性をDeep NNを⽤用
いて同時に予測、これまでの予測精度度を超え
る結果を得る*
• ほぼ同様の⼿手法で同研究Gr. がMerck 主催の化
合物活性予測のコンペティションで優勝**
x
1
x
N
h
1
h
H
k
M
k
1
y
M
y
1
k
M
k
1
y
M
y
1
k
M
k
1
y
M
y
1
タスク
1
タスク
2
タスク
3
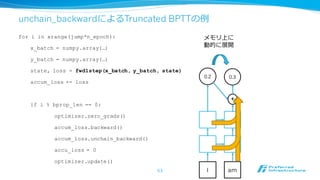
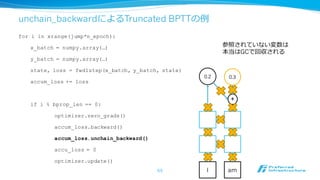
unchain_backwardによるTruncated BPTTの例例
I
0.2
am
0.3
+
メモリ上に
動的に展開
76
for iin xrange(jump*n_epoch):
x_batch = numpy.array(…)
y_batch = numpy.array(…)
state, loss = fwd1step(x_batch, y_batch, state)
accum_loss += loss
if i % bprop_len == 0:
optimizer.zero_grads()
accum_loss.backward()
accum_loss.unchain_backward()
accu_loss = 0
optimizer.update()
77.
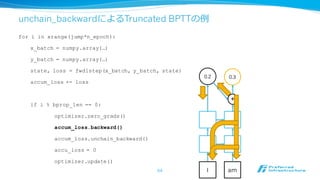
unchain_backwardによるTruncated BPTTの例例
I
0.2
am
0.3
+
77
for iin xrange(jump*n_epoch):
x_batch = numpy.array(…)
y_batch = numpy.array(…)
state, loss = fwd1step(x_batch, y_batch, state)
accum_loss += loss
if i % bprop_len == 0:
optimizer.zero_grads()
accum_loss.backward()
accum_loss.unchain_backward()
accu_loss = 0
optimizer.update()
78.
unchain_backwardによるTruncated BPTTの例例
I
0.2
am
0.3
+
参照されていない変数は
本当はGCで回収される
78
for iin xrange(jump*n_epoch):
x_batch = numpy.array(…)
y_batch = numpy.array(…)
state, loss = fwd1step(x_batch, y_batch, state)
accum_loss += loss
if i % bprop_len == 0:
optimizer.zero_grads()
accum_loss.backward()
accum_loss.unchain_backward()
accu_loss = 0
optimizer.update()
79.
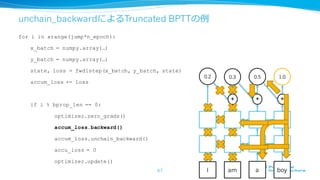
unchain_backwardによるTruncated BPTTの例例
I
0.2
am
0.3
+
a
0.5
+
boy
1.0
+
79
for iin xrange(jump*n_epoch):
x_batch = numpy.array(…)
y_batch = numpy.array(…)
state, loss = fwd1step(x_batch, y_batch, state)
accum_loss += loss
if i % bprop_len == 0:
optimizer.zero_grads()
accum_loss.backward()
accum_loss.unchain_backward()
accu_loss = 0
optimizer.update()
80.
unchain_backwardによるTruncated BPTTの例例
I
0.2
am
0.3
+
a
0.5
+
boy
1.0
+
80
for iin xrange(jump*n_epoch):
x_batch = numpy.array(…)
y_batch = numpy.array(…)
state, loss = fwd1step(x_batch, y_batch, state)
accum_loss += loss
if i % bprop_len == 0:
optimizer.zero_grads()
accum_loss.backward()
accum_loss.unchain_backward()
accu_loss = 0
optimizer.update()




![10
2012年年画像認識識コンテストで
Deep Learningを⽤用いたチームが優勝
→
ILSVRC2012
優勝チームSupervisonの結果
[Krizhevsky+ ‘12]
• 限界と思われた認識識エラーを4割も減らした
(26%→16%)
• 特徴抽出を⾏行行わず、⽣生の画素をNNに与えた
翌年年の同コンテストの上位チームはほぼDeep
Learningベースの⼿手法](https://image.slidesharecdn.com/20150901jnns-150826014346-lva1-app6892/85/DeepLearning-10-320.jpg)
![Neural Netブーム
• 様々なコンペティションでDLが既存⼿手法を凌凌駕
• 16%(‘12) → 11%(‘13) → 6.6%(’14) → 4.8%('15)
• 各企業がDL研究者の獲得競争
• Google/FaceBook/Microsoft/Baidu
• 実サービスもDLベースに置き換えられる
• Siri/Google画像検索索
GoogLeNetのアーキテクチャ↓
11
http://research.google.com/archive/un
supervised_icml2012.html
Google Brainによる猫認識識↑
[Le, Ng, Jeffrey+ ’12]](https://image.slidesharecdn.com/20150901jnns-150826014346-lva1-app6892/85/DeepLearning-11-320.jpg)







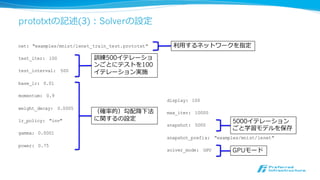

![コマンドラインからの実⾏行行
• 訓練
• build/tools/caffe train --solver solver.prototxt [--snapshot
snapshot.solverstate]
• テスト
• build/tools/caffe test --model train_val.prototxt --weight
network.caffemodel
• ベンチマーク
• build/tools/caffe time --model train_val.prototxt
• 学習済モデルを利利⽤用して画像分類
• build/examples/cpp_classification/classification.bin deploy.prototxt
network.caffemodel mean.binaryproto labels.txt img.jpg
ソースコードは
caffe/tools/caffe.cpp参照](https://image.slidesharecdn.com/20150901jnns-150826014346-lva1-app6892/85/DeepLearning-39-320.jpg)
















![例例:Recurrent Language Model
# Model definition
model = FunctionSet(
emb=F.EmbedID(1000, 100),
x2h=F.Linear( 100, 50),
h2h=F.Linear( 50, 50),
h2y=F.Linear( 50, 1000))
opt = optimizers.SGD()
opt.setup(model)
# Forward computation of one step
def fwd1step(h, w, t):
x = F.tanh(model.emb(w))
h = F.tanh(model.x2h(x) + model.h2h(h))
y = model.h2y(h)
return h, F.softmax_cross_entropy(y, t)
# Full RNN forward computation
def forward(seq):
h = Variable(...) # init state
sum_loss = 0
for curw, nextw in zip(seq, seq[1:]):
x = Variable(curw)
t = Variable(nextw)
h, loss = fwd1step(h, x, t)
sum_loss += loss
return sum_loss
h h
x,t
lo
ss
x,t
lo
ss
h
fwd1step
RNNの1ステップ
の計算](https://image.slidesharecdn.com/20150901jnns-150826014346-lva1-app6892/85/DeepLearning-61-320.jpg)
![Caffe Reference Modelサポート
• Caffe Model Zooで提供されているBVLC
Reference ModelをChainerのfunctionとして利利
⽤用可能
func =
CaffeFunction('path/to/bvlc_reference_
caffenet.caffemodel')
x = Variable(…)
y, = func(inputs={'data': x},
outputs=['fc8'])](https://image.slidesharecdn.com/20150901jnns-150826014346-lva1-app6892/85/DeepLearning-66-320.jpg)




![Caffeで定義済のLayer
• 画像認識識関連(畳み込み・プーリング・正規化など): vision_layers.hpp
• [De]ConvolutionLayer/Im2ColLayer/LRNLayer/[CuDNN]PoolingLayer/SPPLayer…
• 基本的な操作(Blobの変形など): common_layers.hpp
• ConcatLayer/SplitLayer/EltwiseLayer/ReshapeLayer…
• データフィーダーの抽象化: data_layers.hpp
• DummyDataLayer/HDF5DataLayer/ImageDataLayer/MemoryDataLayer…
• 損失関数: loss_layers.hpp
• AccuracyLayer/EucledianLossLayer/SigmoidCrossEntropyLayer/SoftmaxLayer…
• Elementwiseな操作(活性化関数など): neuron_layers.hpp
• AbsLayer/ExpLayer/LogLayer/DropoutLayer…](https://image.slidesharecdn.com/20150901jnns-150826014346-lva1-app6892/85/DeepLearning-73-320.jpg)





































![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)





































