Downloaded 238 times










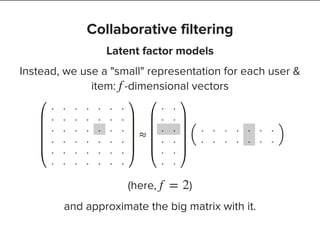


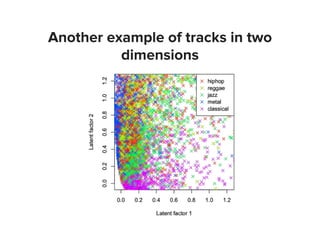





![Add up vectors from every data point
Then flip users ↔items and repeat!
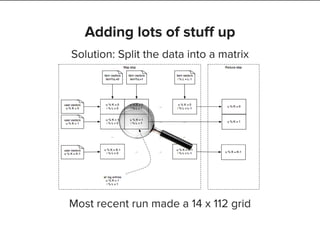
Adding stuff up
(user, item, count)
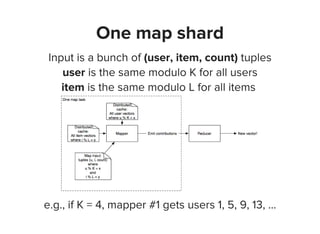
def mapper(self, input): # Luigi-style python job
user, item, count = parse(input)
conf = AdHocConfidenceFunction(count) # e.g. 1 + alpha*count
# add up user vectors from previous iteration
term1 = conf * self.user_vectors[user]
term2 = np.outer(user_vectors[user], user_vectors[user])
* (conf - 1)
yield item, np.array([term1, term2])
def reducer(self, item, terms):
term1, term2 = sum(terms)
item_vector = np.solve(
self.YTY + term2 + self.l2penalty * np.identity(self.dim),
term1)
yield item, item_vector](https://image.slidesharecdn.com/machinelearningatspotify-150128095944-conversion-gate01/85/Machine-learning-Spotify-Madison-Big-Data-Meetup-24-320.jpg)





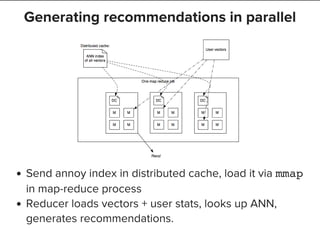




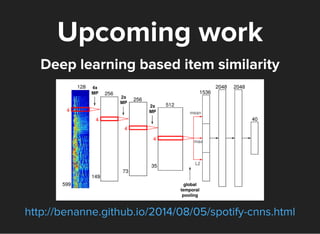



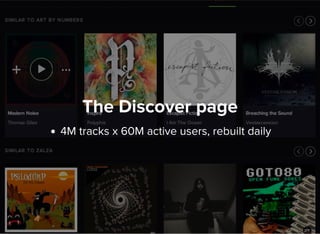
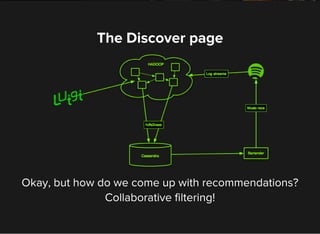
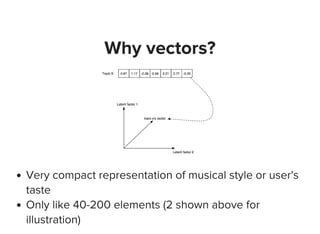
The document discusses machine learning and big data techniques used by Spotify, particularly focusing on collaborative filtering for music recommendations using user behavior and implicit feedback datasets. It explains the challenges faced with user and item data at scale, and how methods like alternating least squares and locality-sensitive hashing are utilized to optimize recommendations while managing large datasets. Additionally, the document touches on Spotify's infrastructure and upcoming work in deep learning and audio fingerprinting for content deduplication.





















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)













