Downloaded 13 times








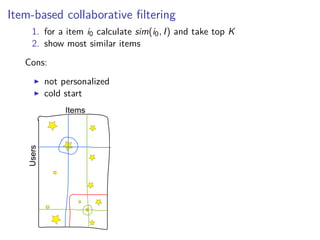
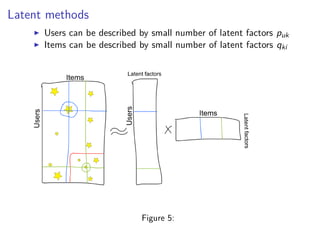

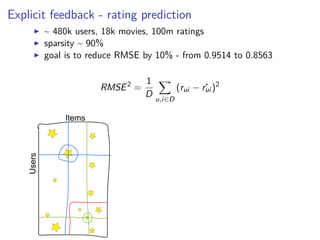
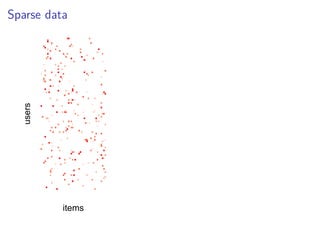
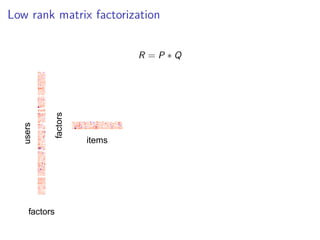
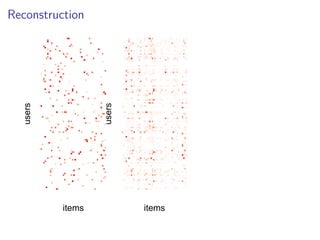


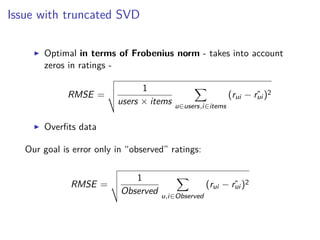





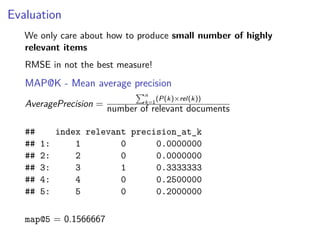



This document discusses matrix factorization techniques for recommender systems. It begins by describing common approaches like content-based, collaborative filtering, and hybrid recommender systems. It then focuses on collaborative filtering, discussing memory and cold start issues with user-based and item-based approaches. The document introduces latent factor models like matrix factorization that address these issues by representing users and items as vectors of factors. It covers optimization techniques like alternating least squares for explicit and implicit feedback datasets. Finally, it discusses evaluation metrics like MAP and NDCG that are more appropriate than RMSE for recommender systems.






























































