









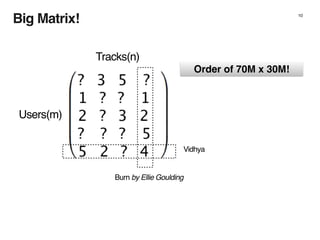
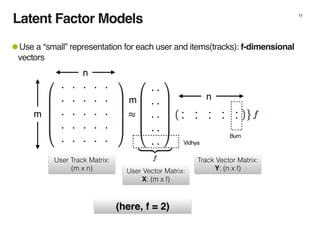

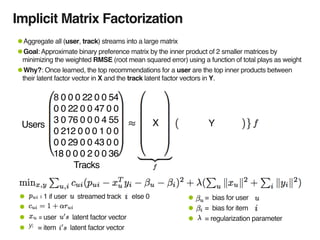
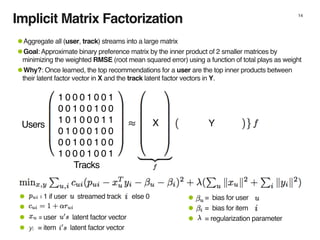





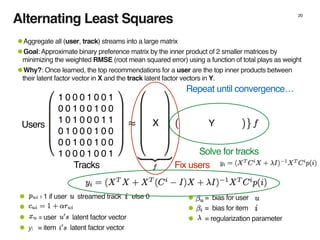

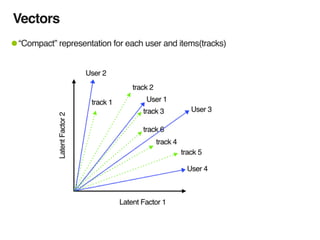

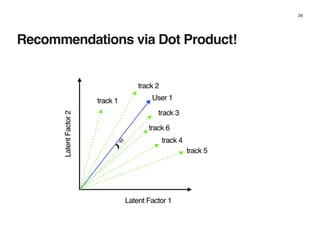

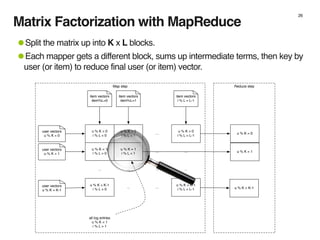
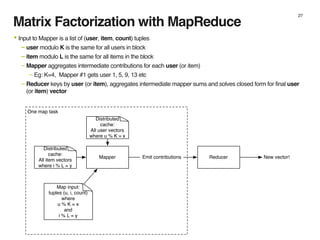



The document discusses music recommendation systems at Spotify, detailing the scale of its data operations and various approaches to recommending tracks, including collaborative filtering and matrix factorization. It highlights the challenges of predicting user preferences given the vast catalog of songs and the presence of implicit feedback from user behavior. Additionally, it outlines the use of MapReduce for efficient computation of user and track vectors to improve recommendation accuracy.



































































