
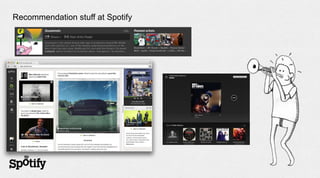


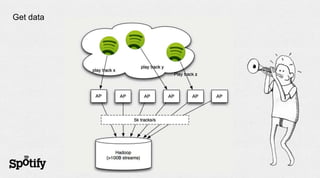

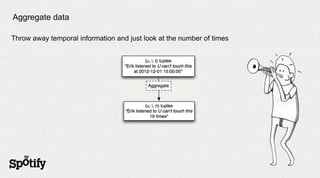
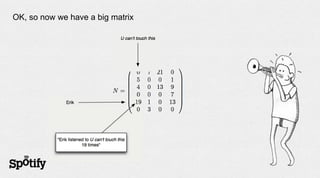
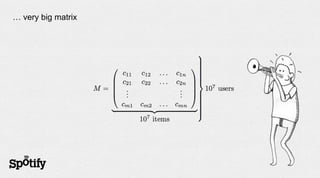












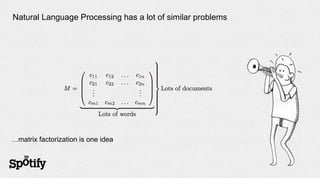


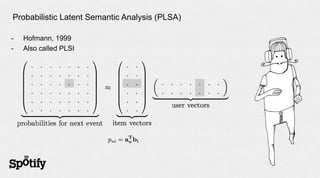










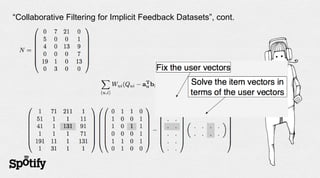

















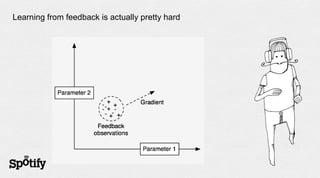


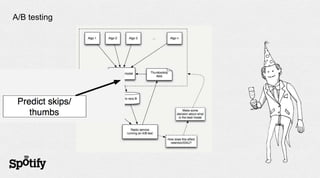


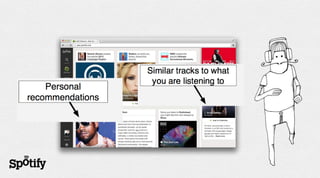




The document discusses Spotify's use of collaborative filtering for music recommendations, focusing on techniques like matrix completion and latent factor models. It highlights the challenges of parallelization and explores various methods for measuring item similarity, such as cosine similarity and Pearson correlation. Additionally, the text touches on the need for scalable solutions in different domains, presents the importance of A/B testing, and concludes with a hiring note.









































































