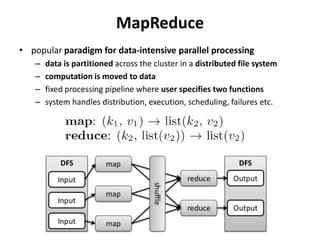
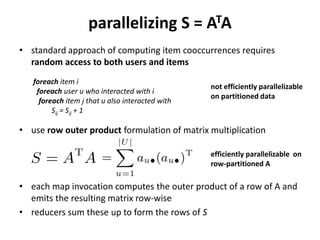
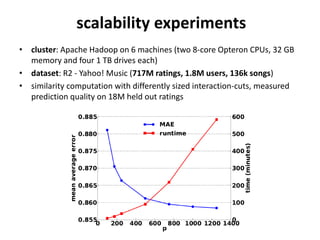
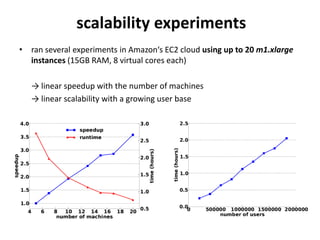
This document summarizes a research paper that proposes using MapReduce to scale up similarity-based neighborhood recommendation methods. The authors rephrase these algorithms to be efficiently parallelized across large datasets. They express common similarity measures like Jaccard coefficient in terms of canonical functions that can be embedded in their MapReduce approach. Experiments on a Yahoo! Music dataset with over 700 million ratings showed their method provided linear speedup and scalability with increasing data and cluster size.