Download as PDF, PPTX













![1 0 0 0 1 0 0 1
0 0 1 0 0 1 0 0
1 0 1 0 0 0 1 1
0 1 0 0 0 1 0 0
0 0 1 0 0 1 0 0
1 0 0 0 1 0 0 1
•Aggregate all (user, track) streams into a large matrix
•Goal: Approximate binary preference matrix by inner product of 2 smaller matrices by minimizing the
weighted RMSE (root mean squared error) using a function of plays, context, and recency as weight
X YUsers
Songs
• = bias for user
• = bias for item
• = regularization parameter
• = 1 if user streamed track else 0
•
• = user latent factor vector
• = item latent factor vector
[1] Hu Y. & Koren Y. & Volinsky C. (2008) Collaborative Filtering for Implicit Feedback Datasets 8th IEEE International Conference on Data Mining
Implicit Matrix Factorization](https://image.slidesharecdn.com/discoverweeklydataengconf-151116205329-lva1-app6892/75/From-Idea-to-Execution-Spotify-s-Discover-Weekly-31-2048.jpg)
![1 0 0 0 1 0 0 1
0 0 1 0 0 1 0 0
1 0 1 0 0 0 1 1
0 1 0 0 0 1 0 0
0 0 1 0 0 1 0 0
1 0 0 0 1 0 0 1
•Aggregate all (user, track) streams into a large matrix
•Goal: Model probability of user playing a song as logistic, then maximize log likelihood of binary
preference matrix, weighting positive observations by a function of plays, context, and recency
X YUsers
Songs
• = bias for user
• = bias for item
• = regularization parameter
• = user latent factor vector
• = item latent factor vector
[2] Johnson C. (2014) Logistic Matrix Factorization for Implicit Feedback Data NIPS Workshop on Distributed Matrix Computations
Can also use Logistic Loss!](https://image.slidesharecdn.com/discoverweeklydataengconf-151116205329-lva1-app6892/75/From-Idea-to-Execution-Spotify-s-Discover-Weekly-32-2048.jpg)

![[3] http://benanne.github.io/2014/08/05/spotify-cnns.html
Deep Learning on Audio](https://image.slidesharecdn.com/discoverweeklydataengconf-151116205329-lva1-app6892/75/From-Idea-to-Execution-Spotify-s-Discover-Weekly-35-2048.jpg)



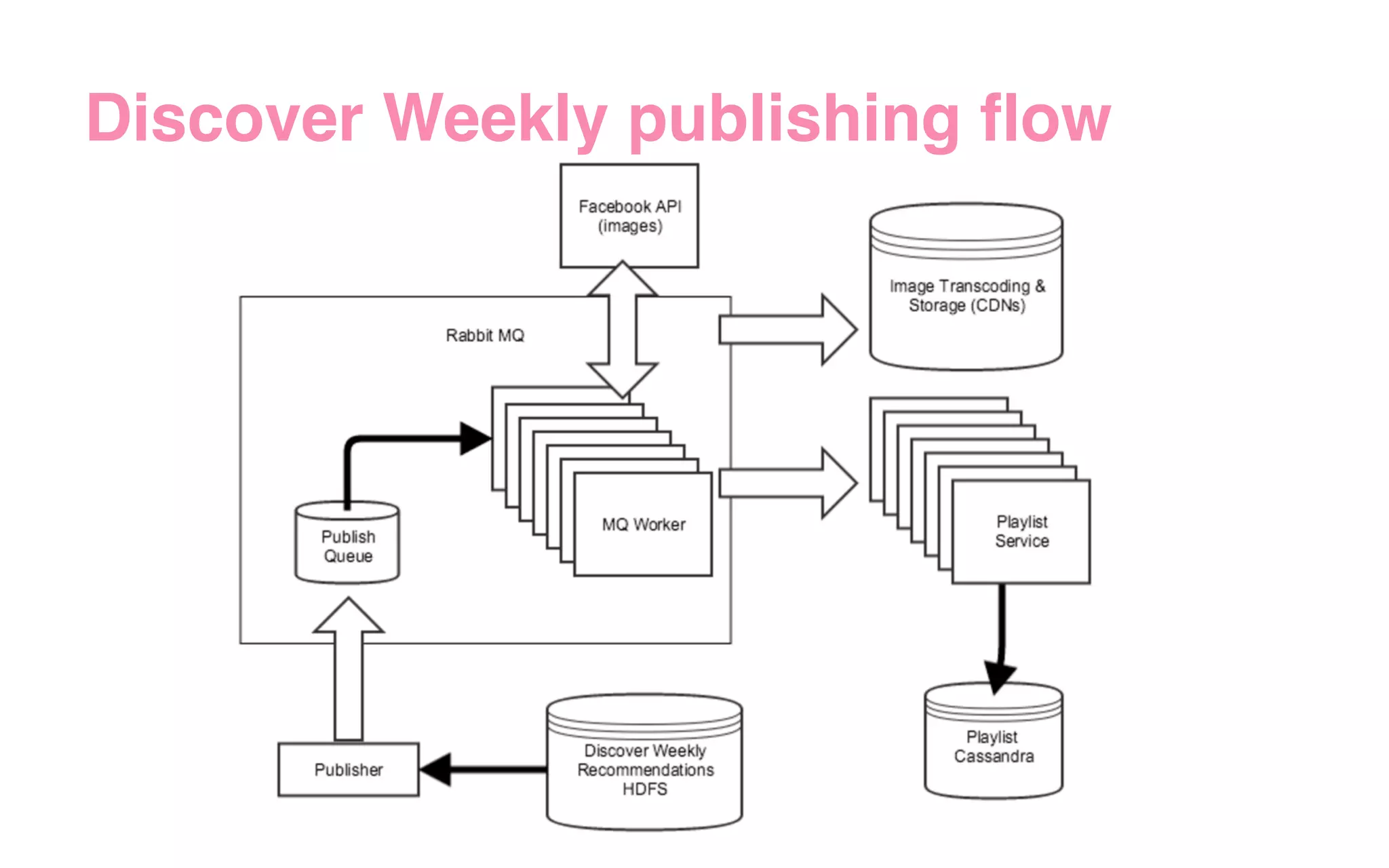
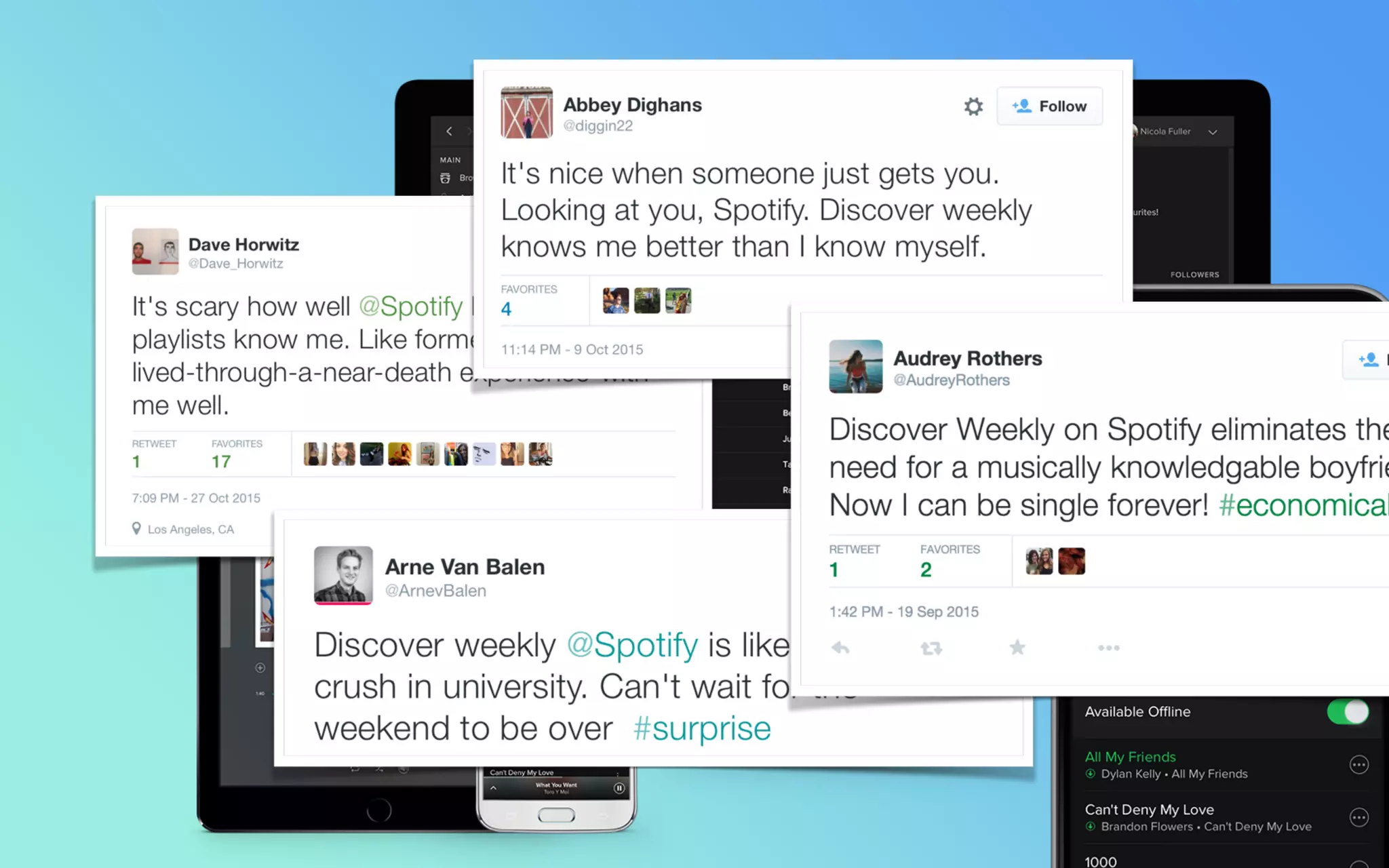
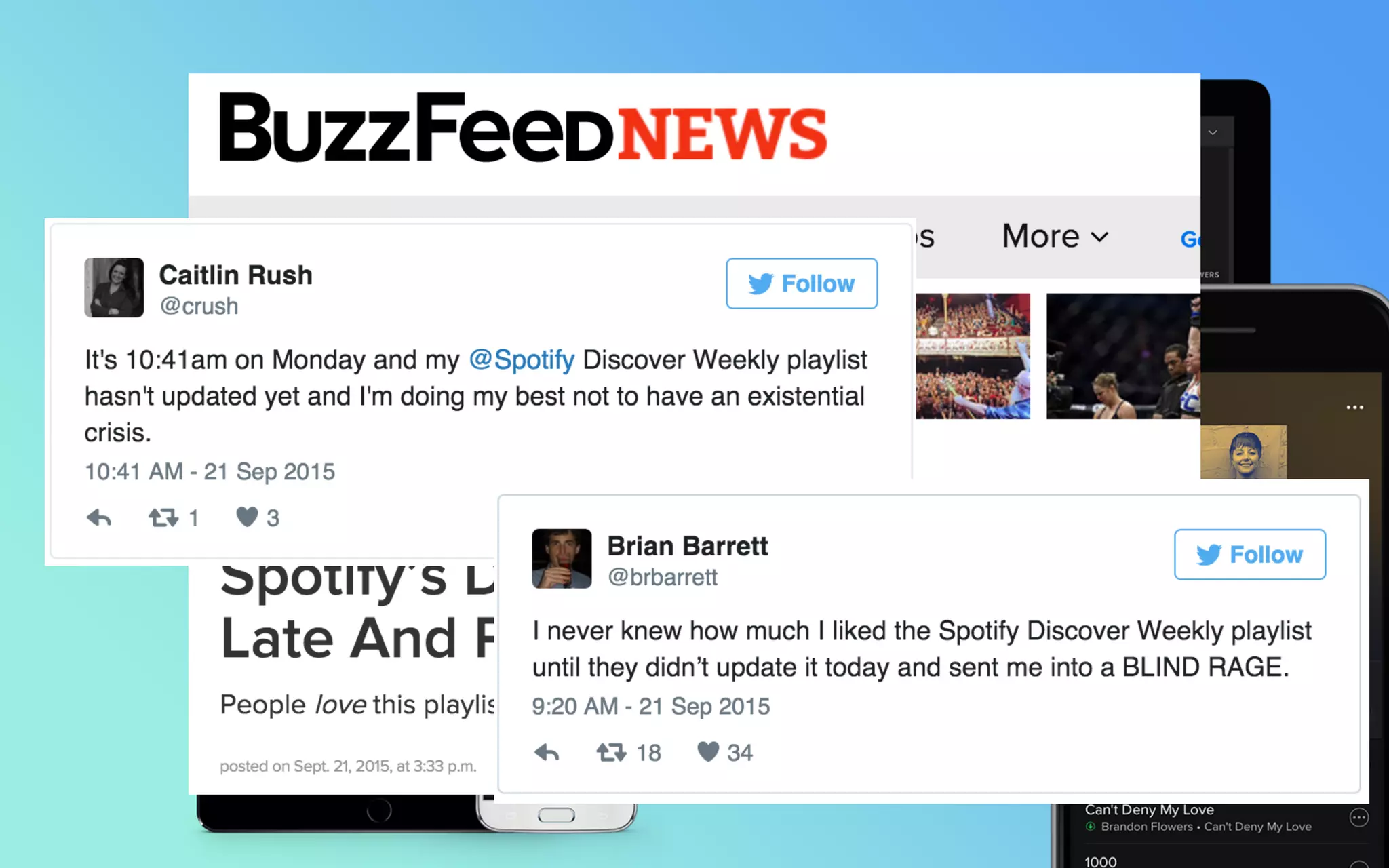

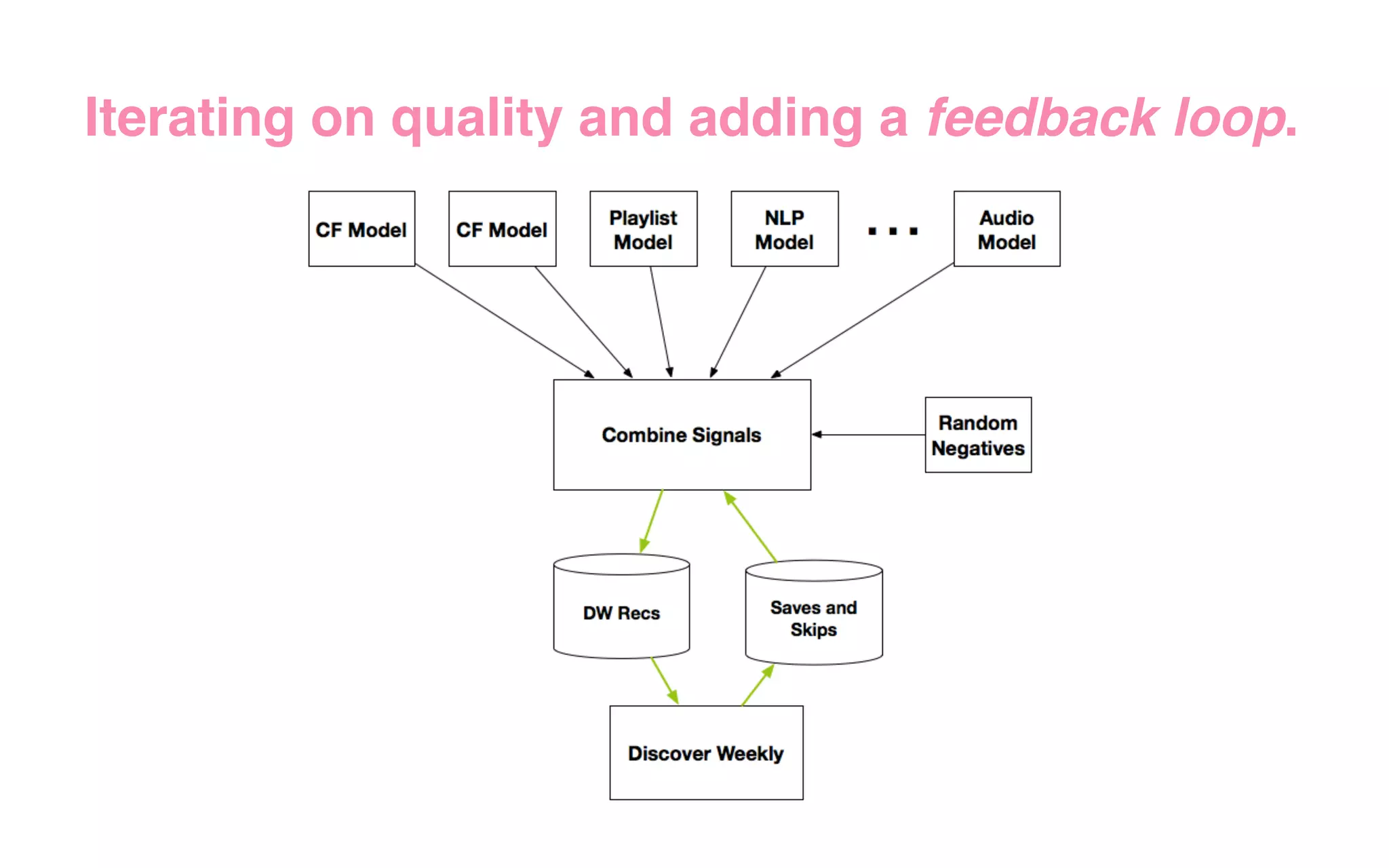
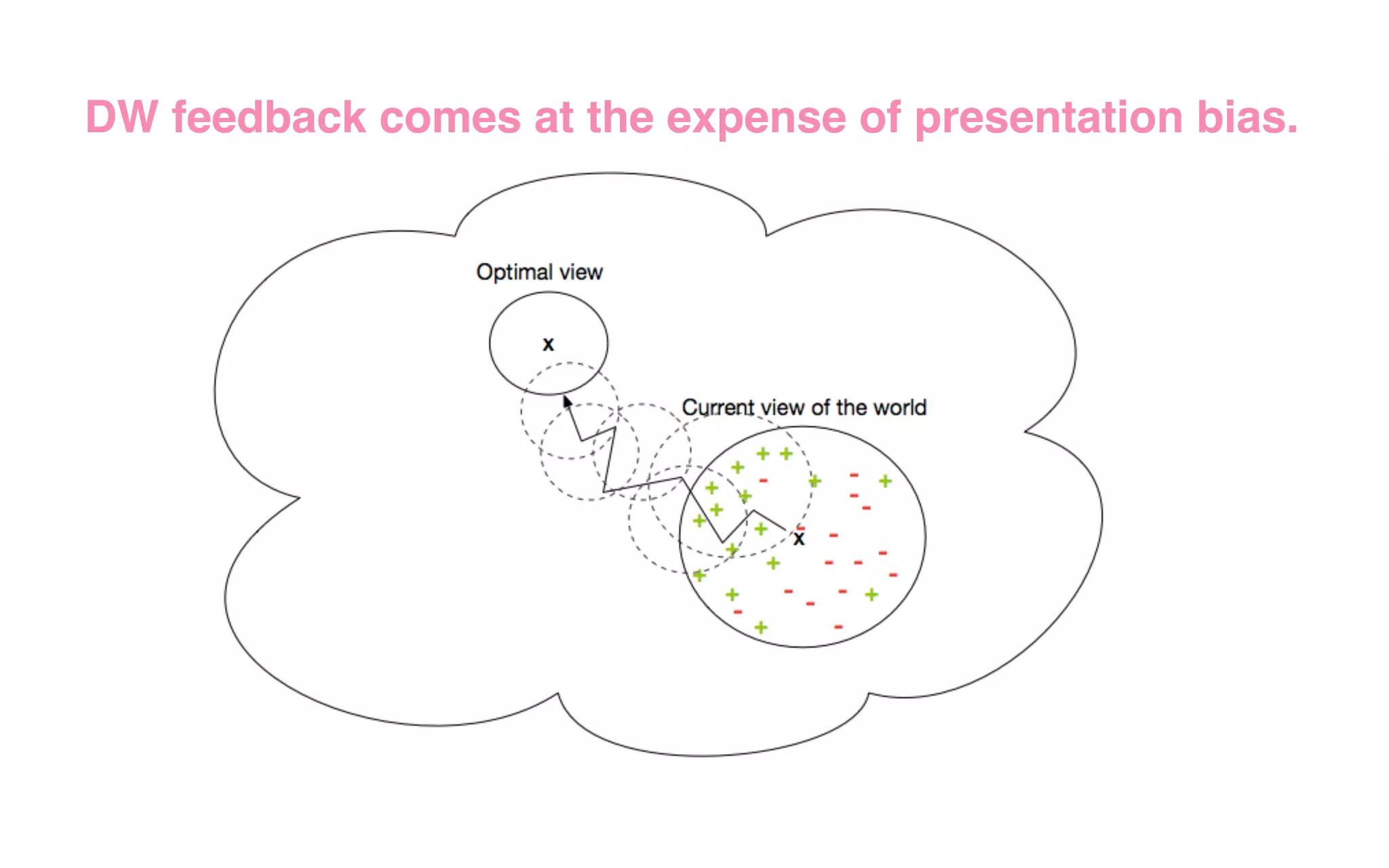




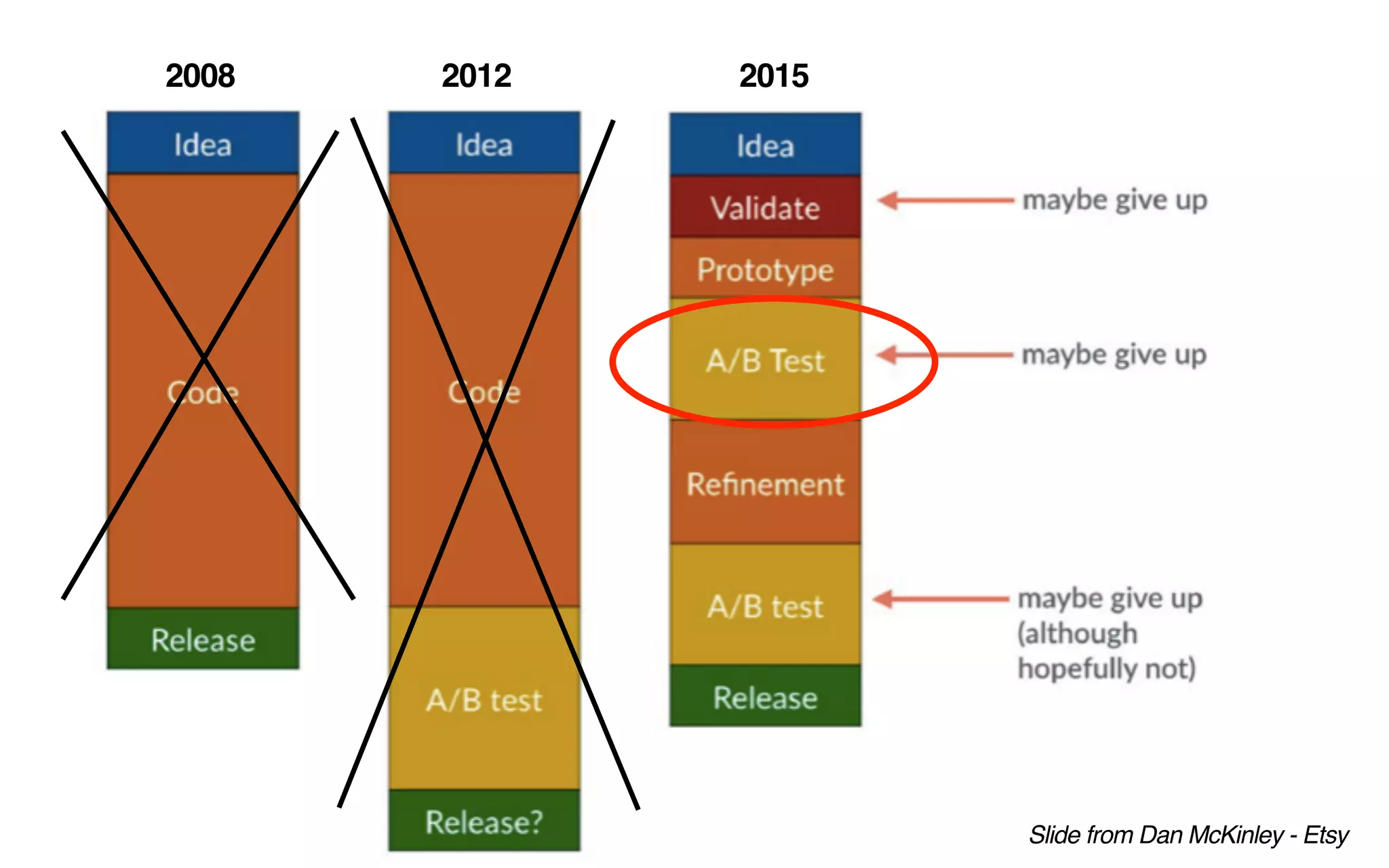
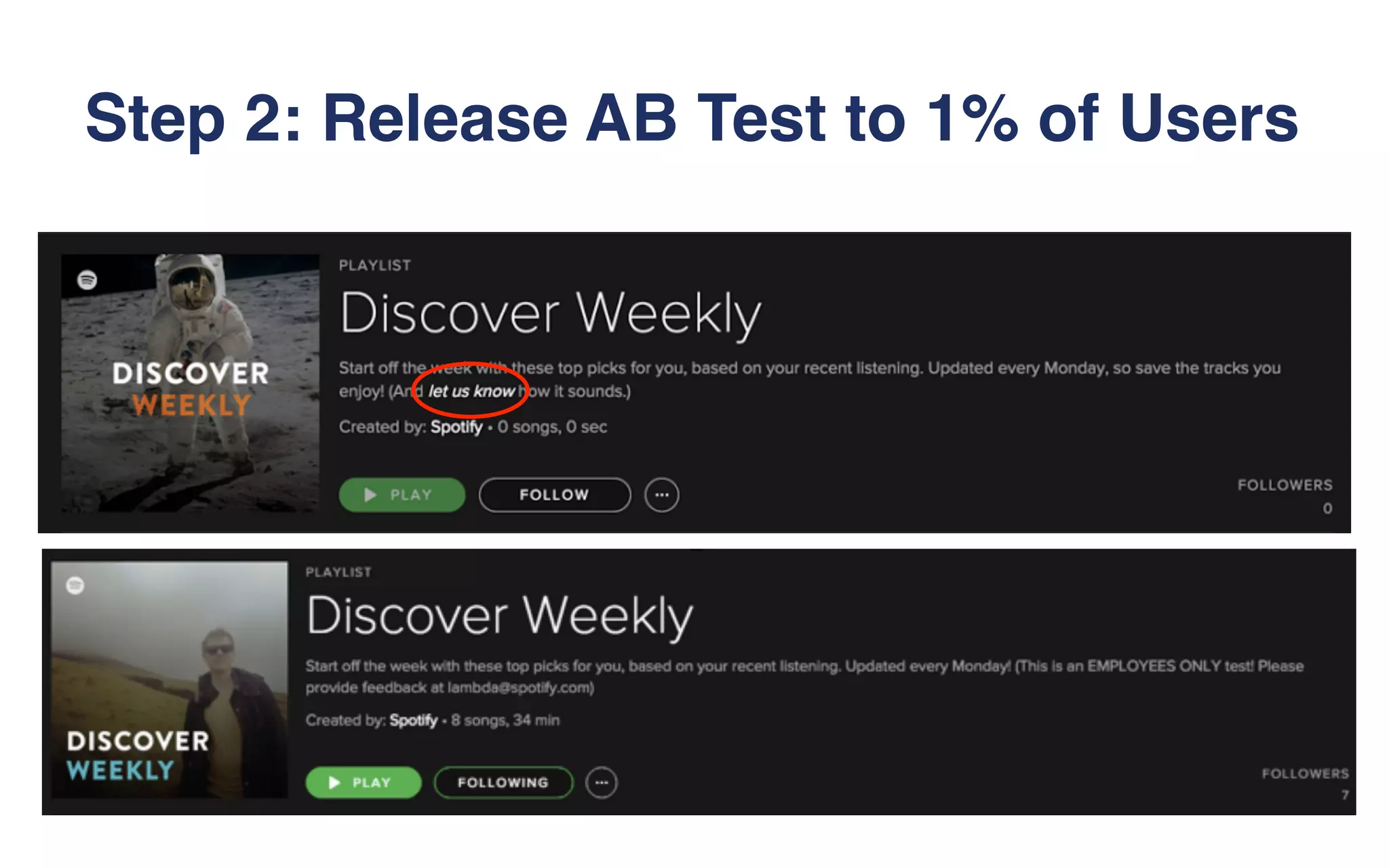
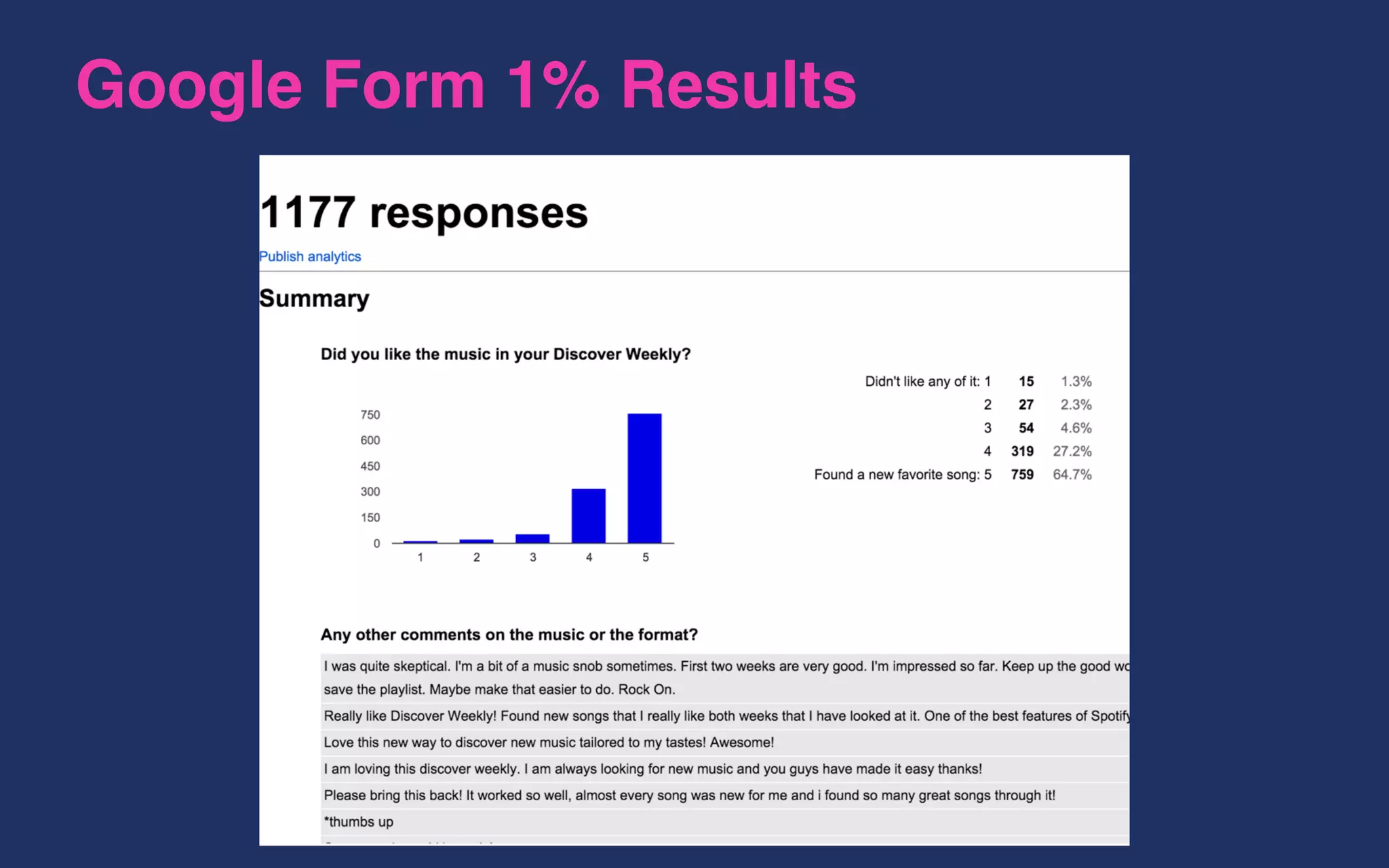
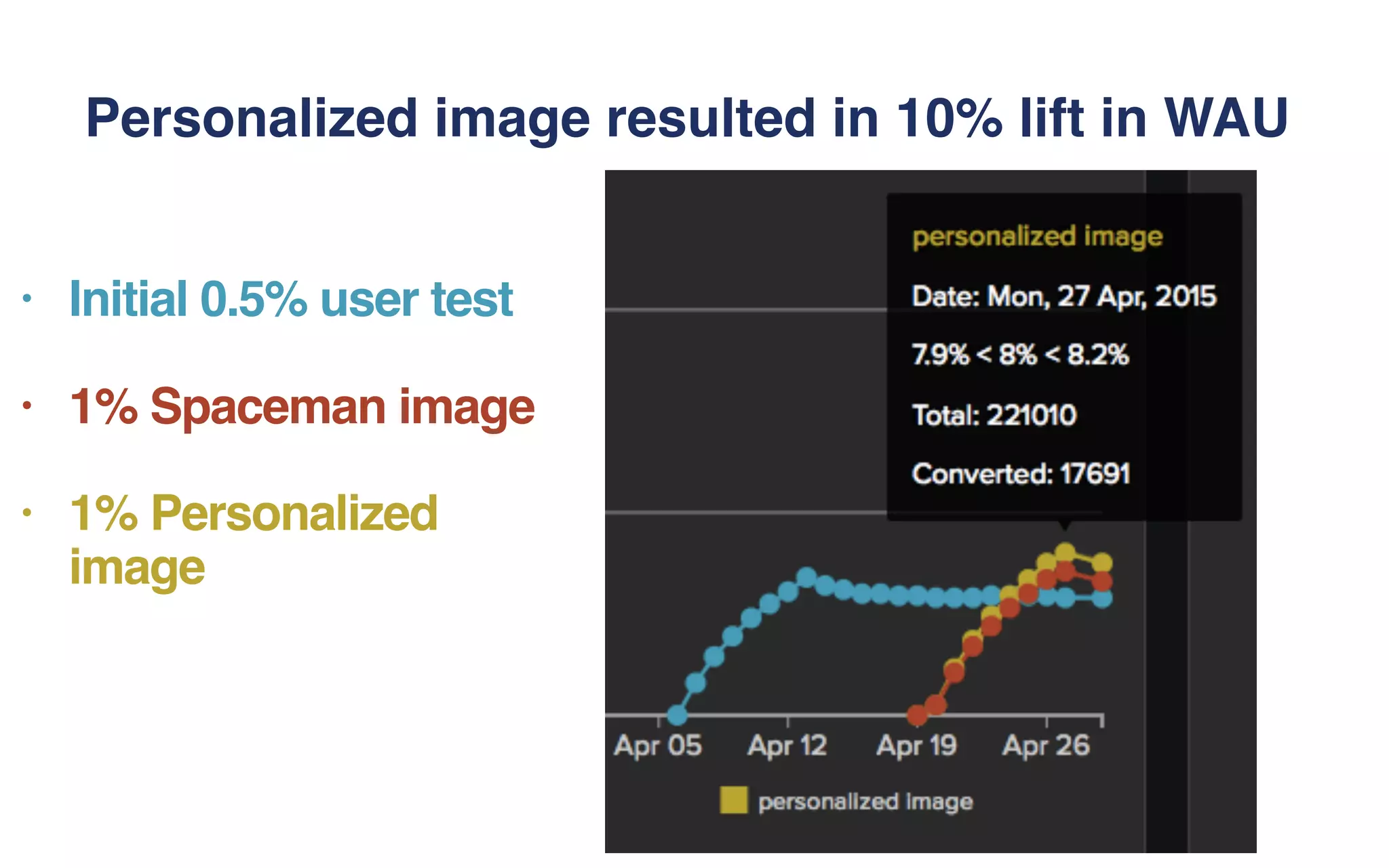
The document outlines the development of Spotify's Discover Weekly feature, highlighting its evolution from initial prototype stages in 2013 to its current successful model. Key lessons learned in building scalable recommendation systems include being data-driven, creatively reusing existing infrastructure, and conducting extensive A/B testing. The presentation also emphasizes the importance of user feedback and fostering innovation within the organization.



































































