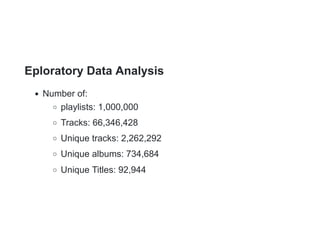
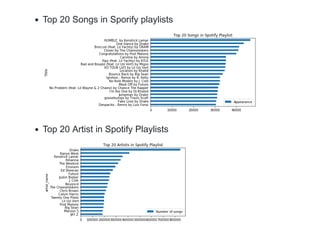
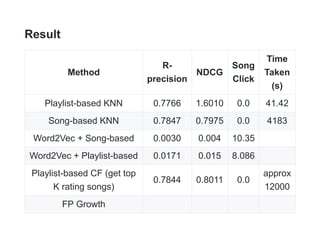
This document describes a Spotify playlist recommender system challenge. The goal is to develop a system that can automatically recommend new tracks to add to a playlist based on its existing tracks. Several proposed solutions are described including collaborative filtering, K-nearest neighbors (KNN), frequent pattern growth, and matrix factorization. Evaluation metrics like R-precision and NDCG are defined. Exploratory data analysis is performed on the Million Playlist Dataset and various solutions are tested, with playlist-based and song-based KNN performing the best in terms of metrics while being fast.