Downloaded 61 times










![12
#
sudo
addgroup
hadoop
#
sudo
adduser
—ingroup
hadoop
hdfs
#
sudo
adduser
—ingroup
hadoop
yarn
#
cp
/tmp/configs/*.xml
/etc/hadoop/conf/
#
apt-‐get
update
…
[hdfs@sj-‐hadoop-‐b20
~]
$
apt-‐get
install
hadoop-‐hdfs-‐datanode
…
[yarn@sj-‐hadoop-‐b20
~]
$
apt-‐get
install
hadoop-‐yarn-‐nodemanager](https://image.slidesharecdn.com/theevolutionofhadoopatspotify-throughfailuresandpain-150314153821-conversion-gate01/75/The-Evolution-of-Hadoop-at-Spotify-Through-Failures-and-Pain-18-2048.jpg)
![12
#
sudo
addgroup
hadoop
#
sudo
adduser
—ingroup
hadoop
hdfs
#
sudo
adduser
—ingroup
hadoop
yarn
#
cp
/tmp/configs/*.xml
/etc/hadoop/conf/
#
apt-‐get
update
…
[hdfs@sj-‐hadoop-‐b20
~]
$
apt-‐get
install
hadoop-‐hdfs-‐datanode
…
[yarn@sj-‐hadoop-‐b20
~]
$
apt-‐get
install
hadoop-‐yarn-‐nodemanager](https://image.slidesharecdn.com/theevolutionofhadoopatspotify-throughfailuresandpain-150314153821-conversion-gate01/75/The-Evolution-of-Hadoop-at-Spotify-Through-Failures-and-Pain-19-2048.jpg)

![14
[data-‐sci@sj-‐edge-‐a1
~]
$
hdfs
dfs
-‐ls
/data
Found
3
items
drwxr-‐xr-‐x
-‐
hdfs
hadoop
0
2015-‐01-‐01
12:00
lake
drwxr-‐xr-‐x
-‐
hdfs
hadoop
0
2015-‐01-‐01
12:00
pond
drwxr-‐xr-‐x
-‐
hdfs
hadoop
0
2015-‐01-‐01
12:00
ocean
[data-‐sci@sj-‐edge-‐a1
~]
$
hdfs
dfs
-‐ls
/data/lake
Found
1
items
drwxr-‐xr-‐x
-‐
hdfs
hadoop
1321451
2015-‐01-‐01
12:00
boats.txt
[data-‐sci@sj-‐edge-‐a1
~]
$
hdfs
dfs
-‐cat
/data/lake/boats.txt
…](https://image.slidesharecdn.com/theevolutionofhadoopatspotify-throughfailuresandpain-150314153821-conversion-gate01/75/The-Evolution-of-Hadoop-at-Spotify-Through-Failures-and-Pain-21-2048.jpg)
![14
[data-‐sci@sj-‐edge-‐a1
~]
$
hdfs
dfs
-‐ls
/data
Found
3
items
drwxr-‐xr-‐x
-‐
hdfs
hadoop
0
2015-‐01-‐01
12:00
lake
drwxr-‐xr-‐x
-‐
hdfs
hadoop
0
2015-‐01-‐01
12:00
pond
drwxr-‐xr-‐x
-‐
hdfs
hadoop
0
2015-‐01-‐01
12:00
ocean
[data-‐sci@sj-‐edge-‐a1
~]
$
hdfs
dfs
-‐ls
/data/lake
Found
1
items
drwxr-‐xr-‐x
-‐
hdfs
hadoop
1321451
2015-‐01-‐01
12:00
boats.txt
[data-‐sci@sj-‐edge-‐a1
~]
$
hdfs
dfs
-‐cat
/data/lake/boats.txt
…](https://image.slidesharecdn.com/theevolutionofhadoopatspotify-throughfailuresandpain-150314153821-conversion-gate01/75/The-Evolution-of-Hadoop-at-Spotify-Through-Failures-and-Pain-22-2048.jpg)



![[data-‐sci@sj-‐edge-‐a1
~]
$
snakebite
rm
-‐R
/team/disco/
CF/test-‐10/
22](https://image.slidesharecdn.com/theevolutionofhadoopatspotify-throughfailuresandpain-150314153821-conversion-gate01/75/The-Evolution-of-Hadoop-at-Spotify-Through-Failures-and-Pain-34-2048.jpg)
![Goodbye Data (1PB)
[data-‐sci@sj-‐edge-‐a1
~]
$
snakebite
rm
-‐R
/team/disco/
CF/test-‐10/
22
OK:
Deleted
/team/disco](https://image.slidesharecdn.com/theevolutionofhadoopatspotify-throughfailuresandpain-150314153821-conversion-gate01/75/The-Evolution-of-Hadoop-at-Spotify-Through-Failures-and-Pain-35-2048.jpg)



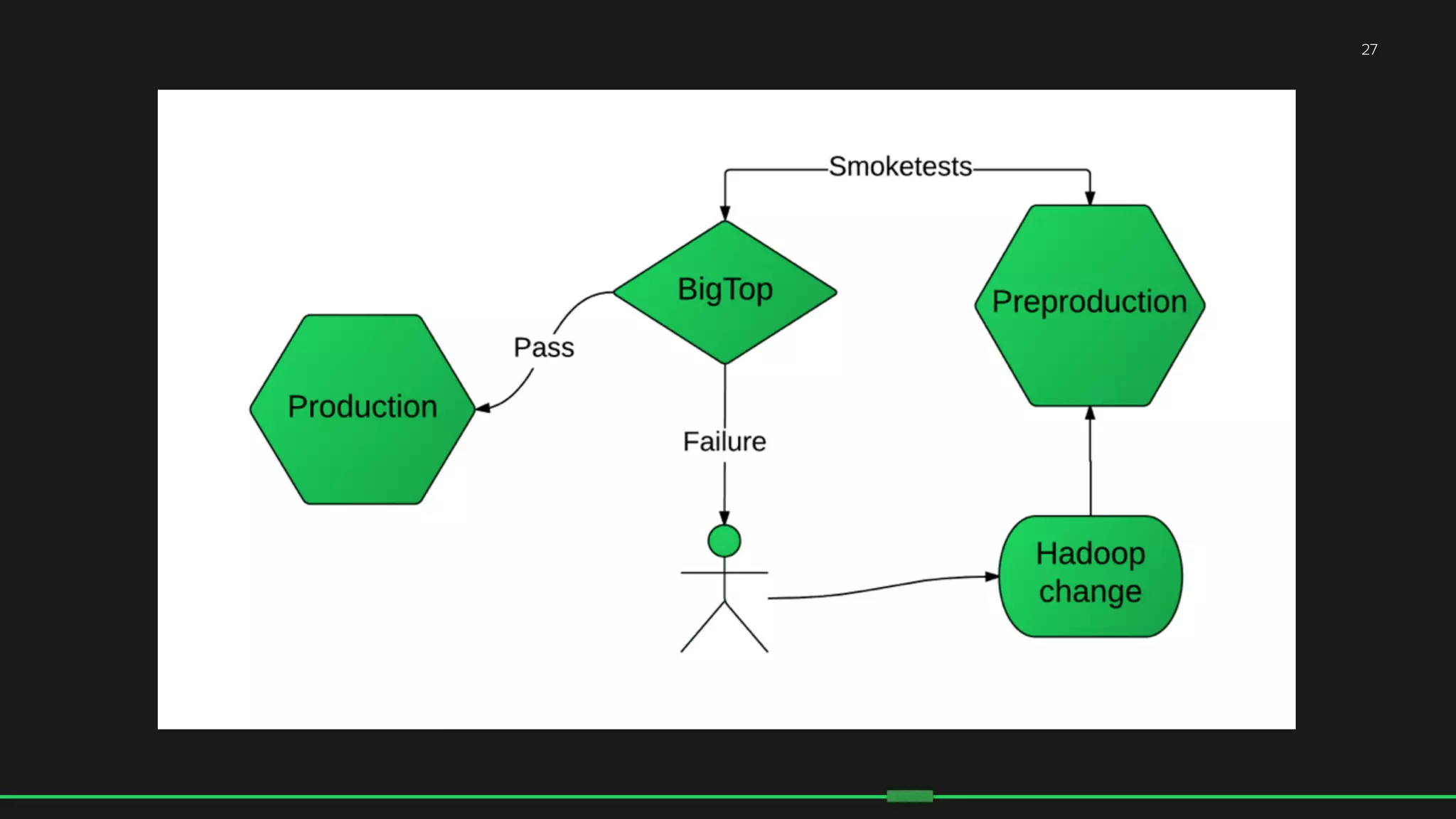




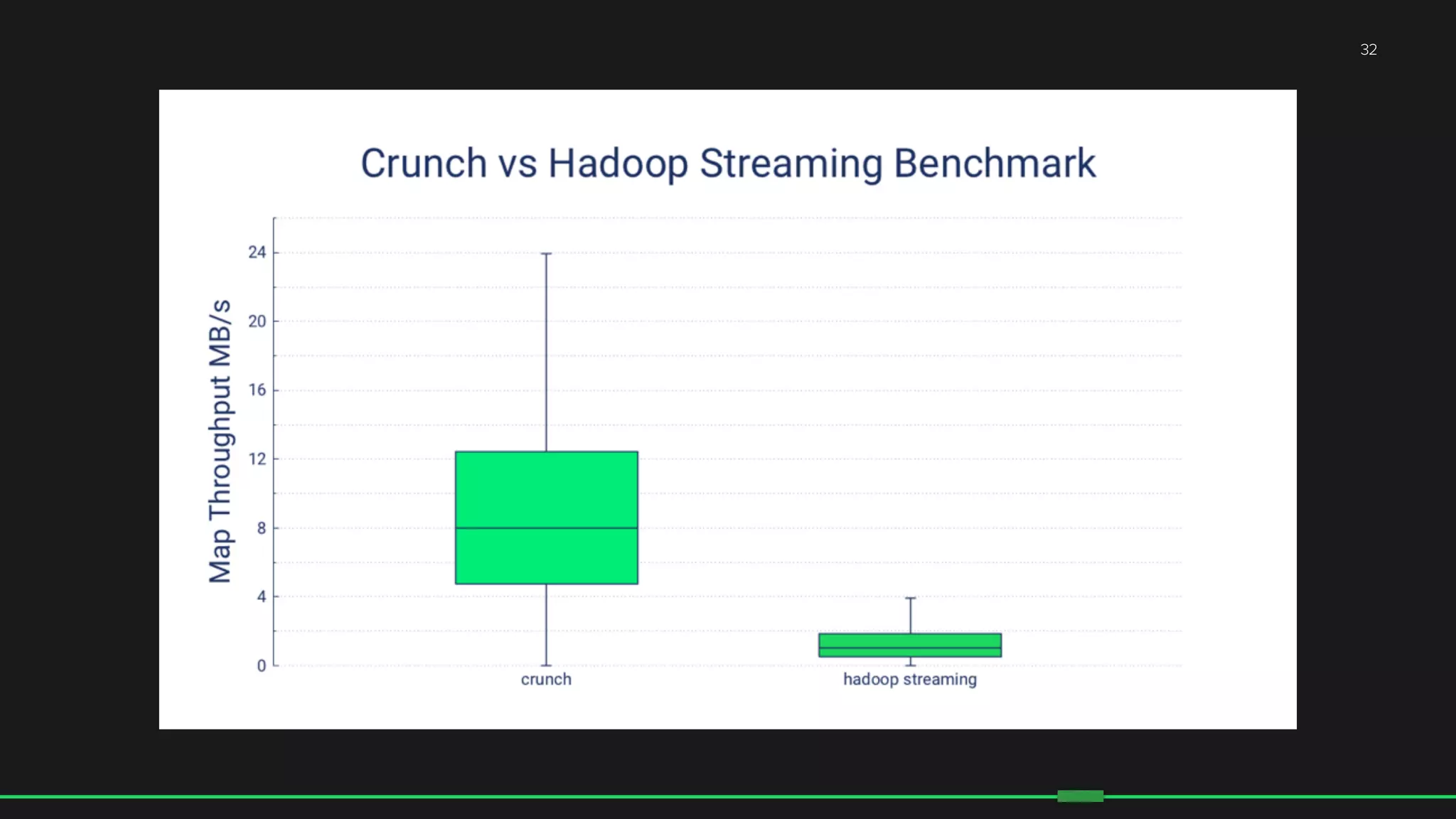
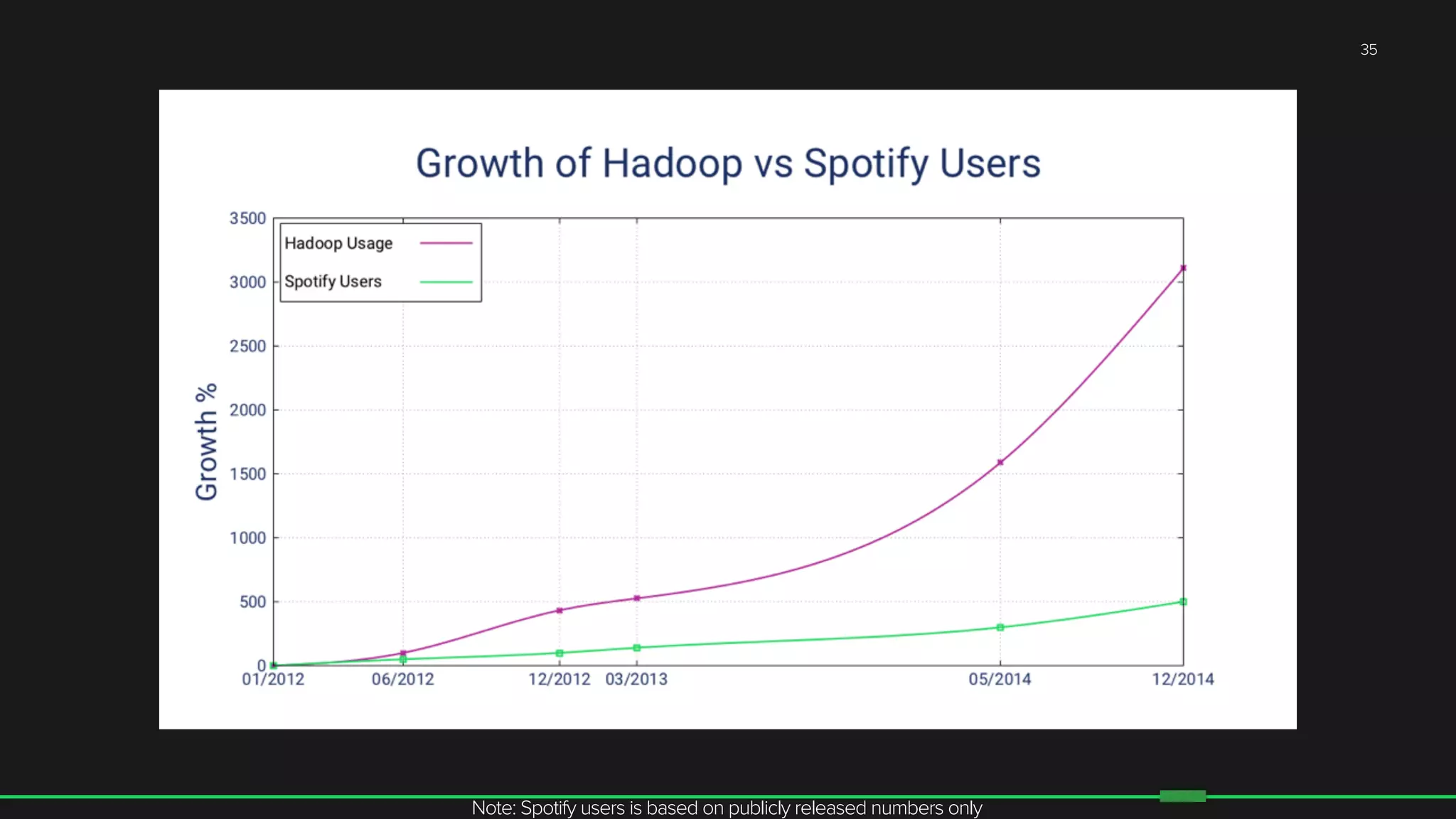







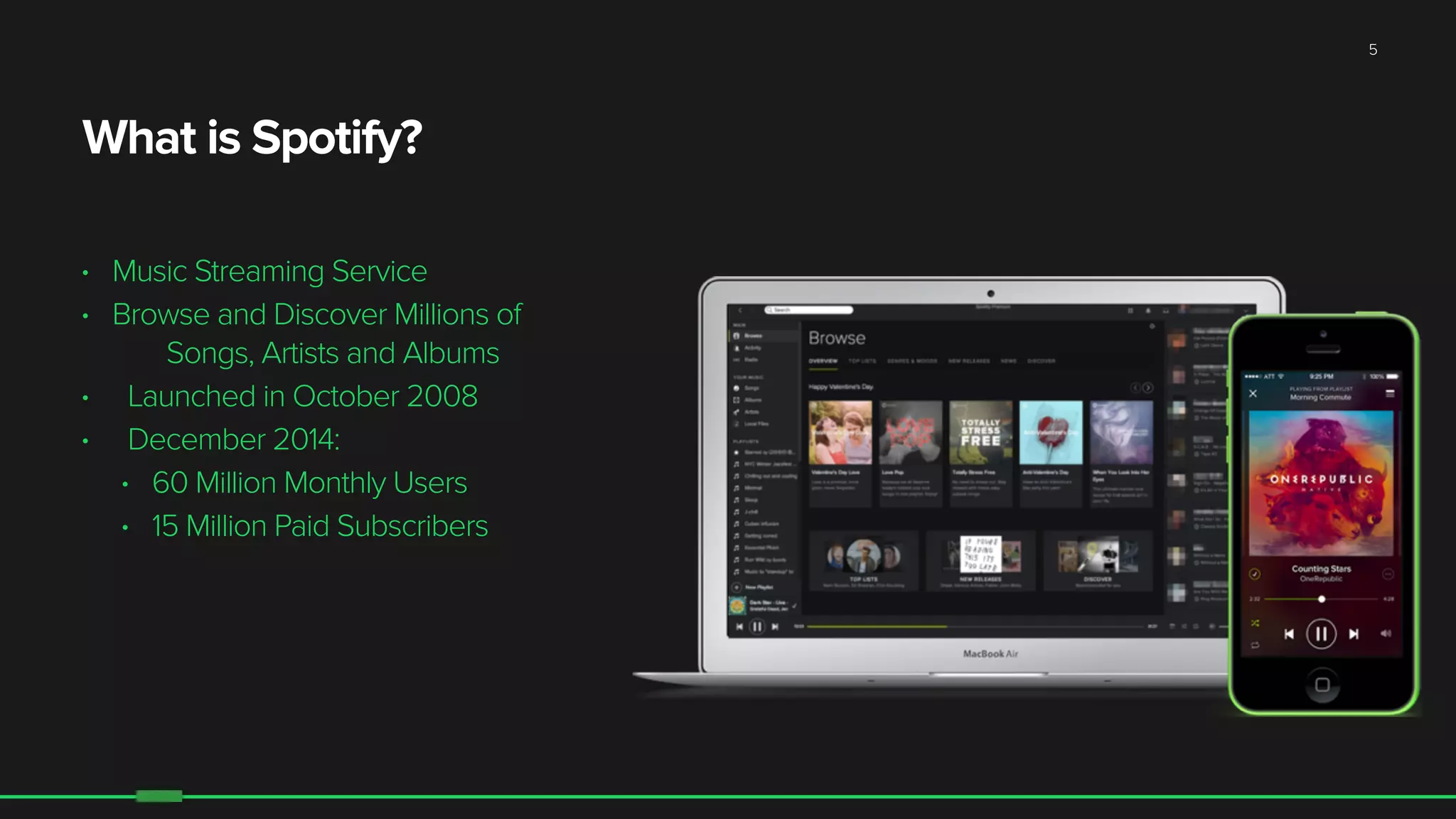
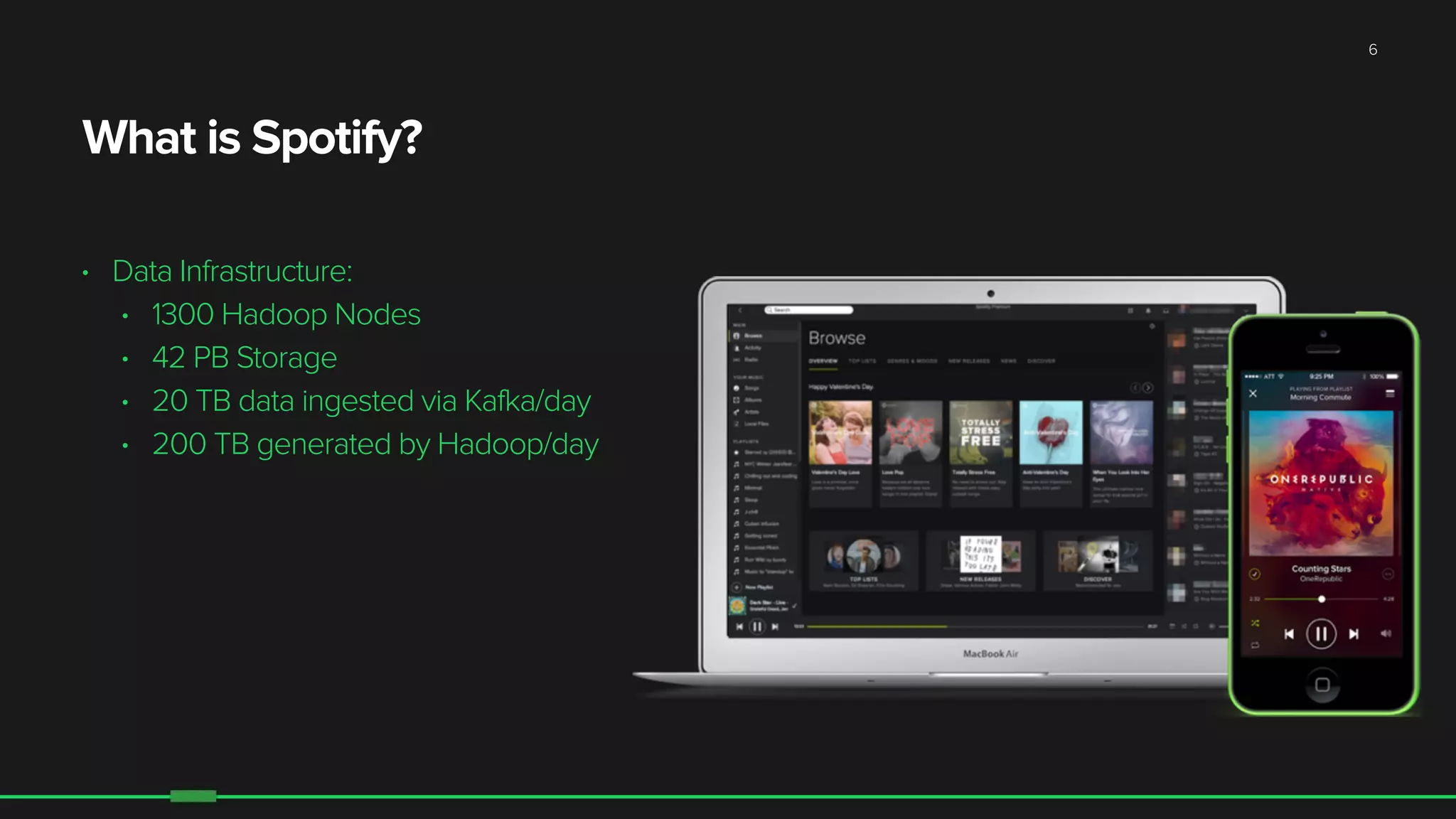
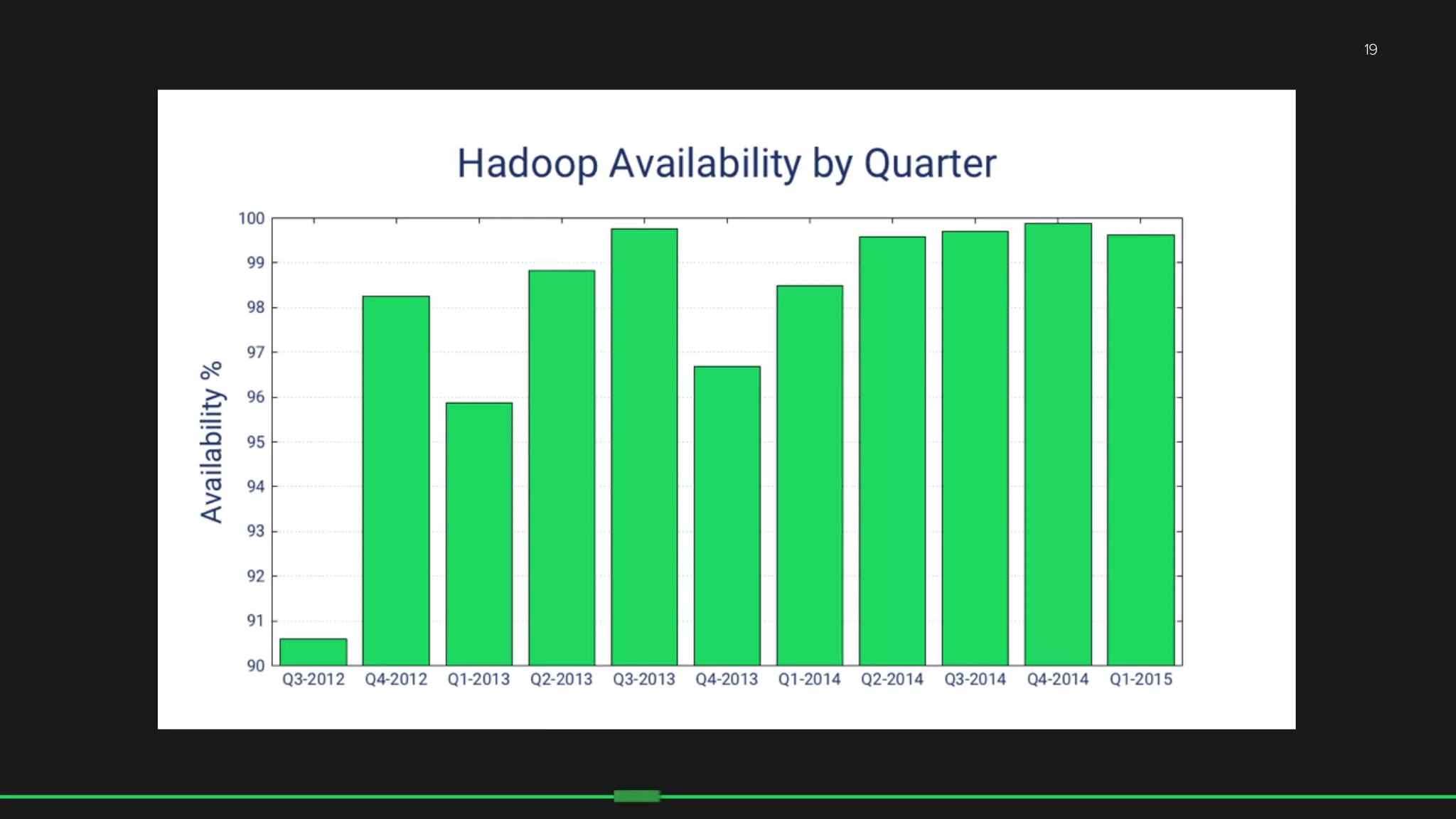
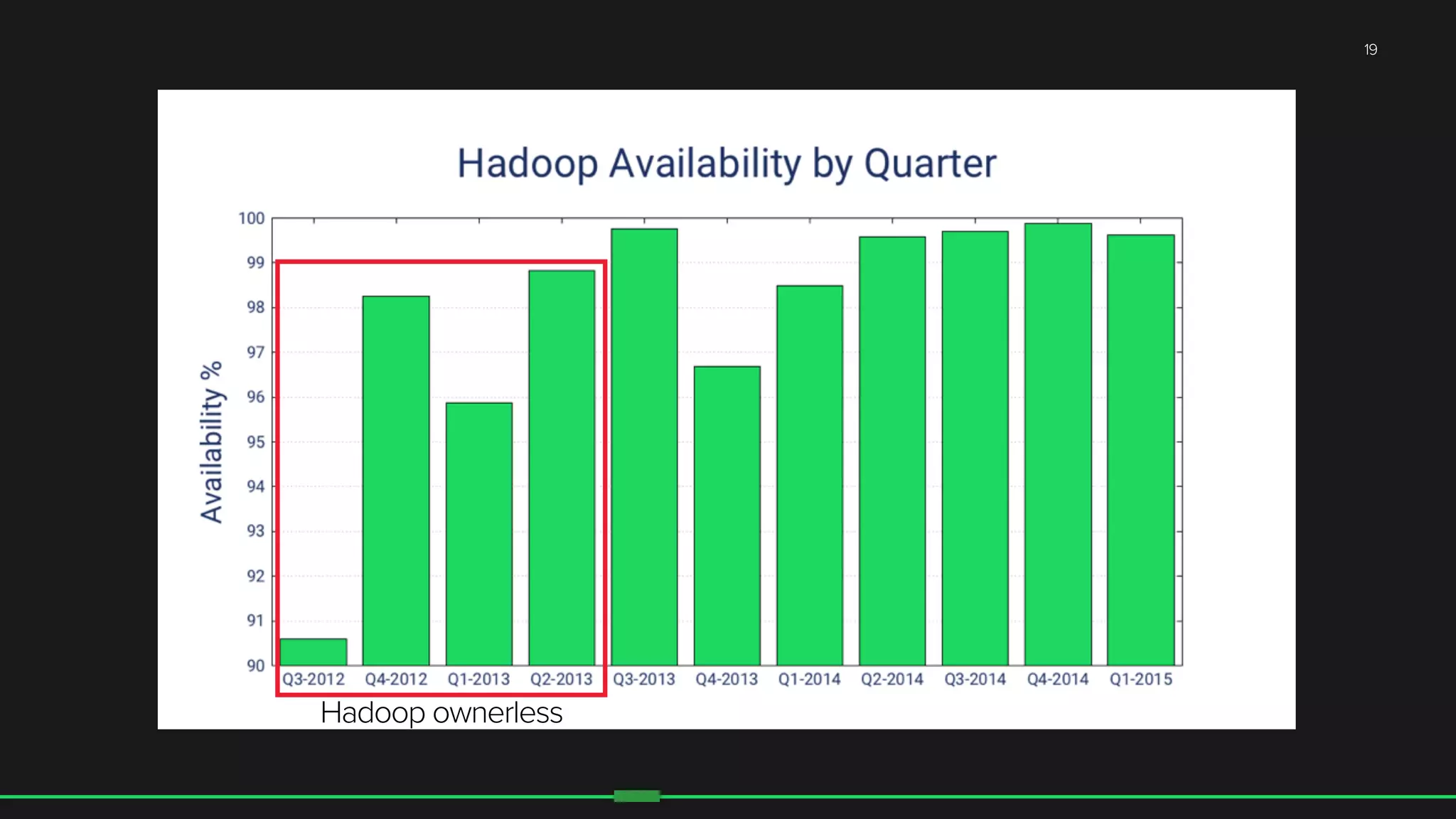
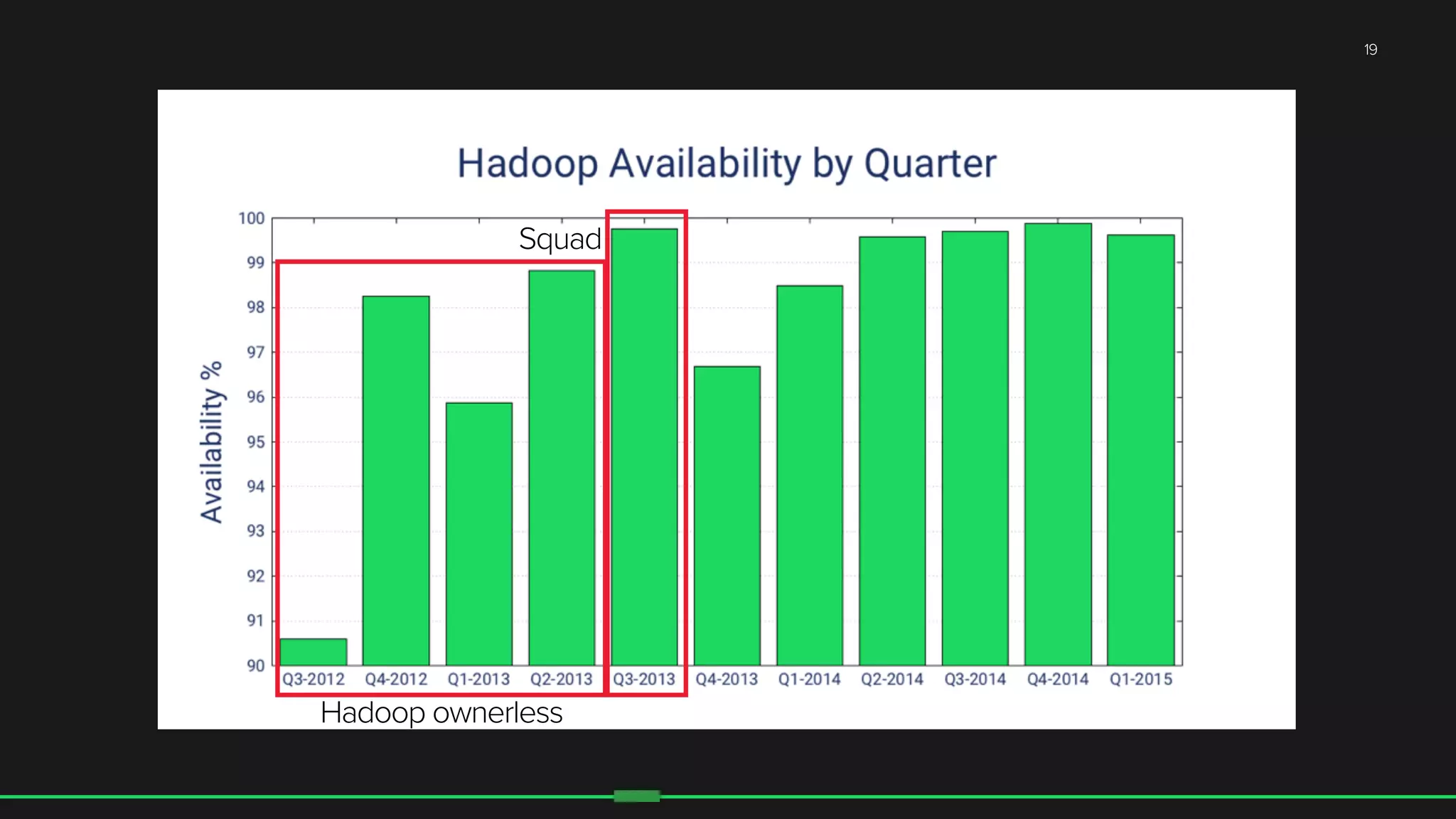
The document discusses the evolution of Hadoop at Spotify from 2009 to 2015, highlighting the company's growth, challenges, and improvements in their data infrastructure. It details the transition to a more reliable Hadoop setup with dedicated teams and automation tools, as well as lessons learned from failures. Additionally, it emphasizes the importance of user feedback and automation in scaling their data management systems.




































































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)


