Downloaded 34 times

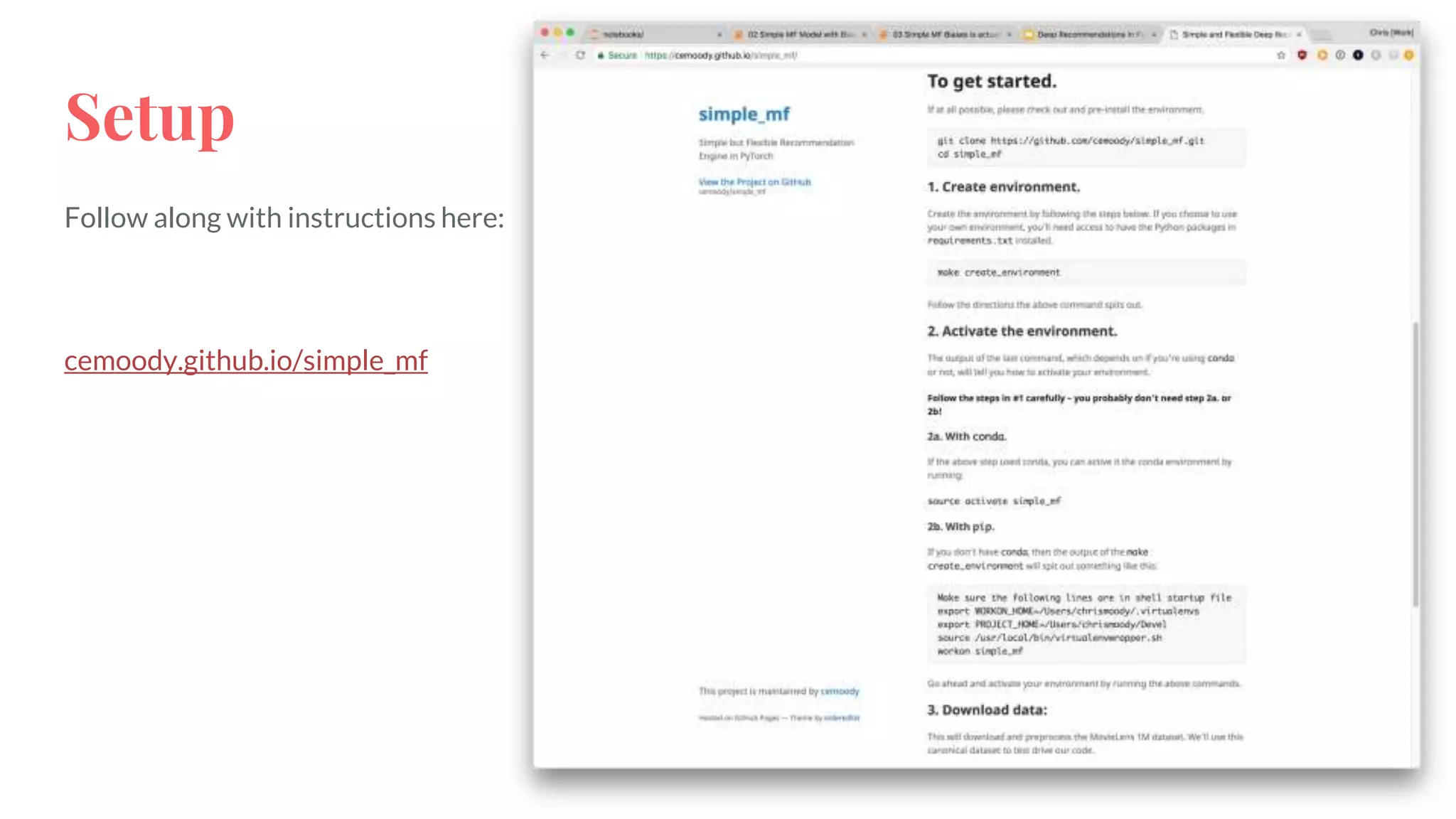














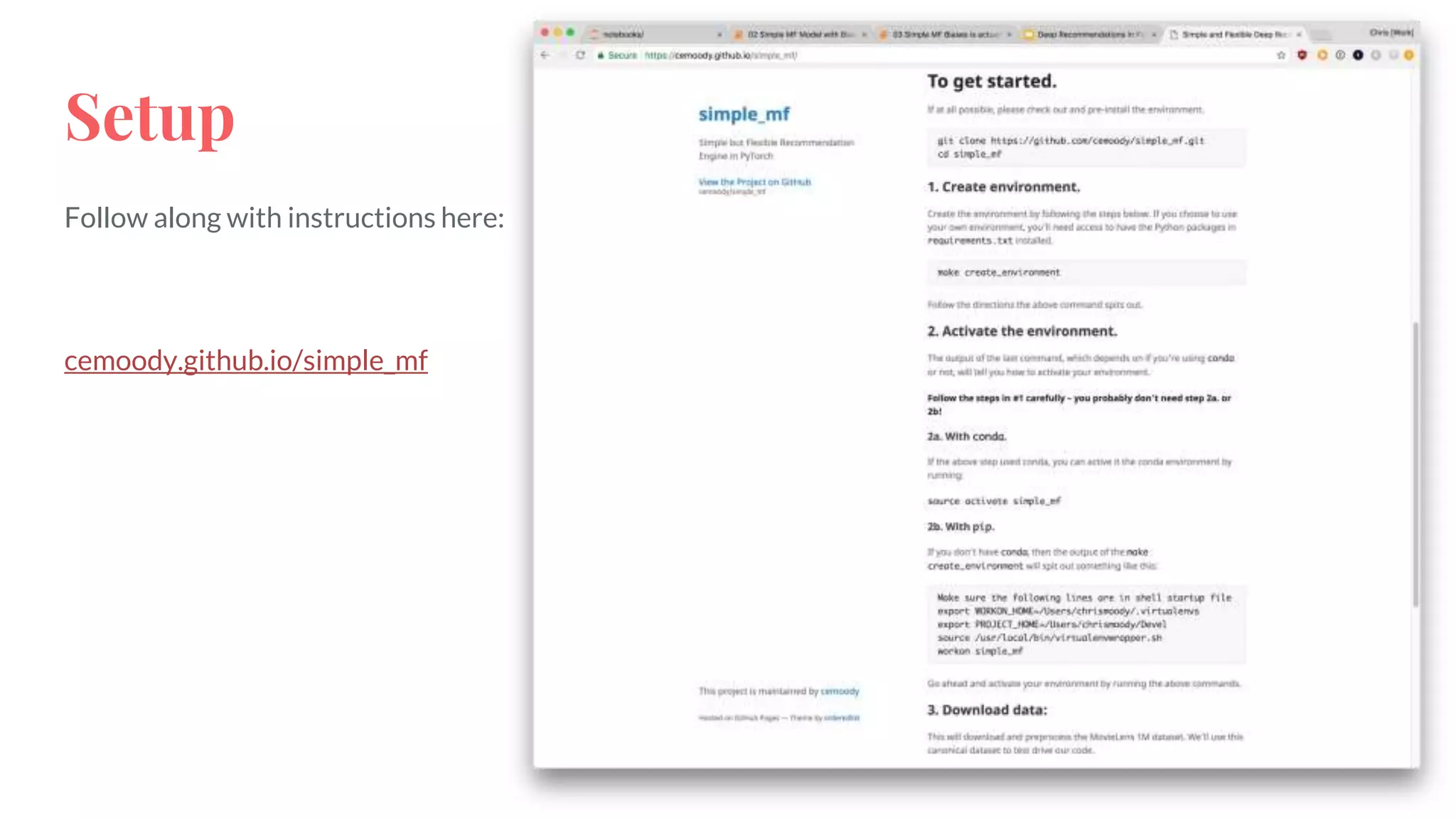

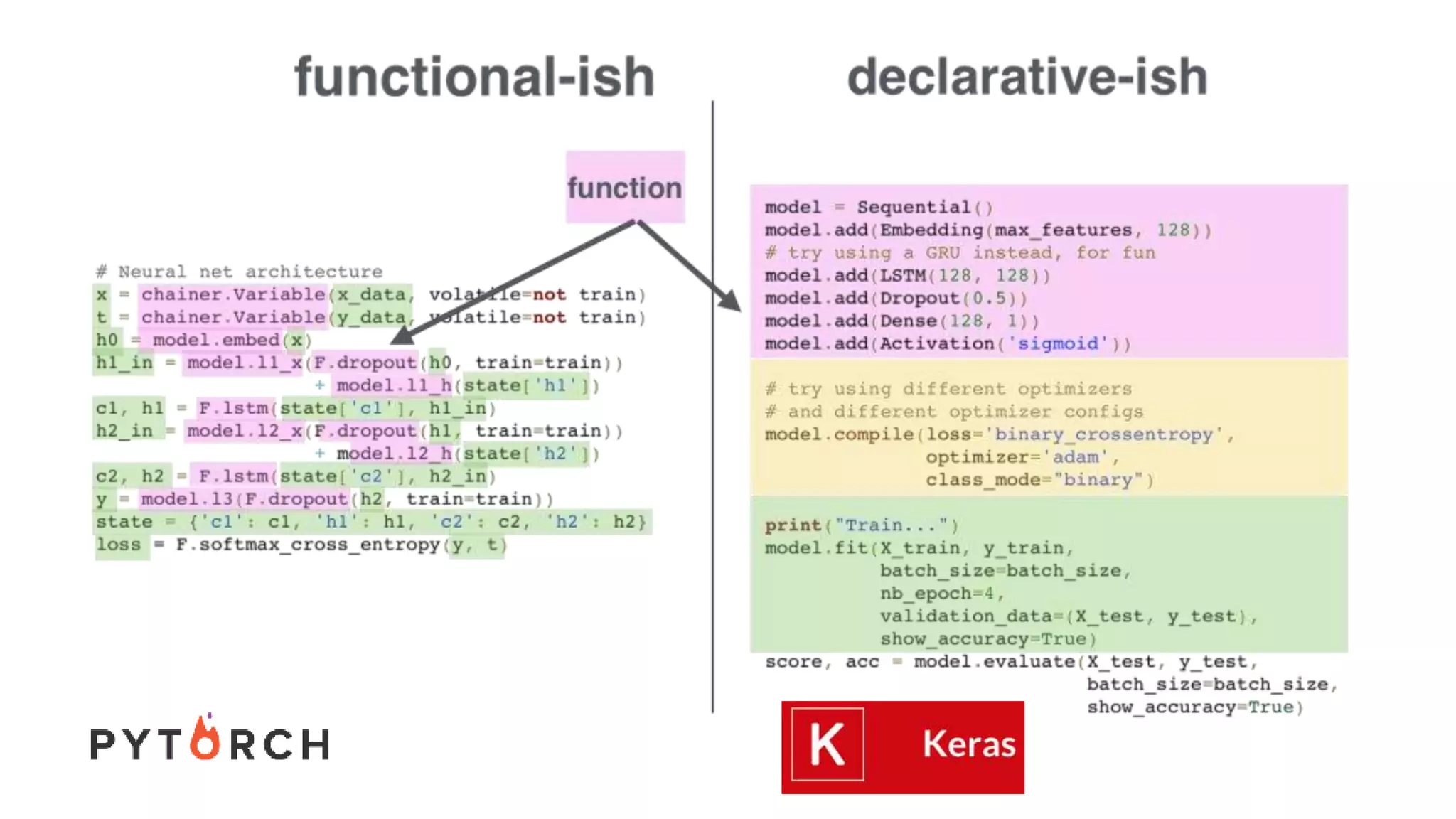
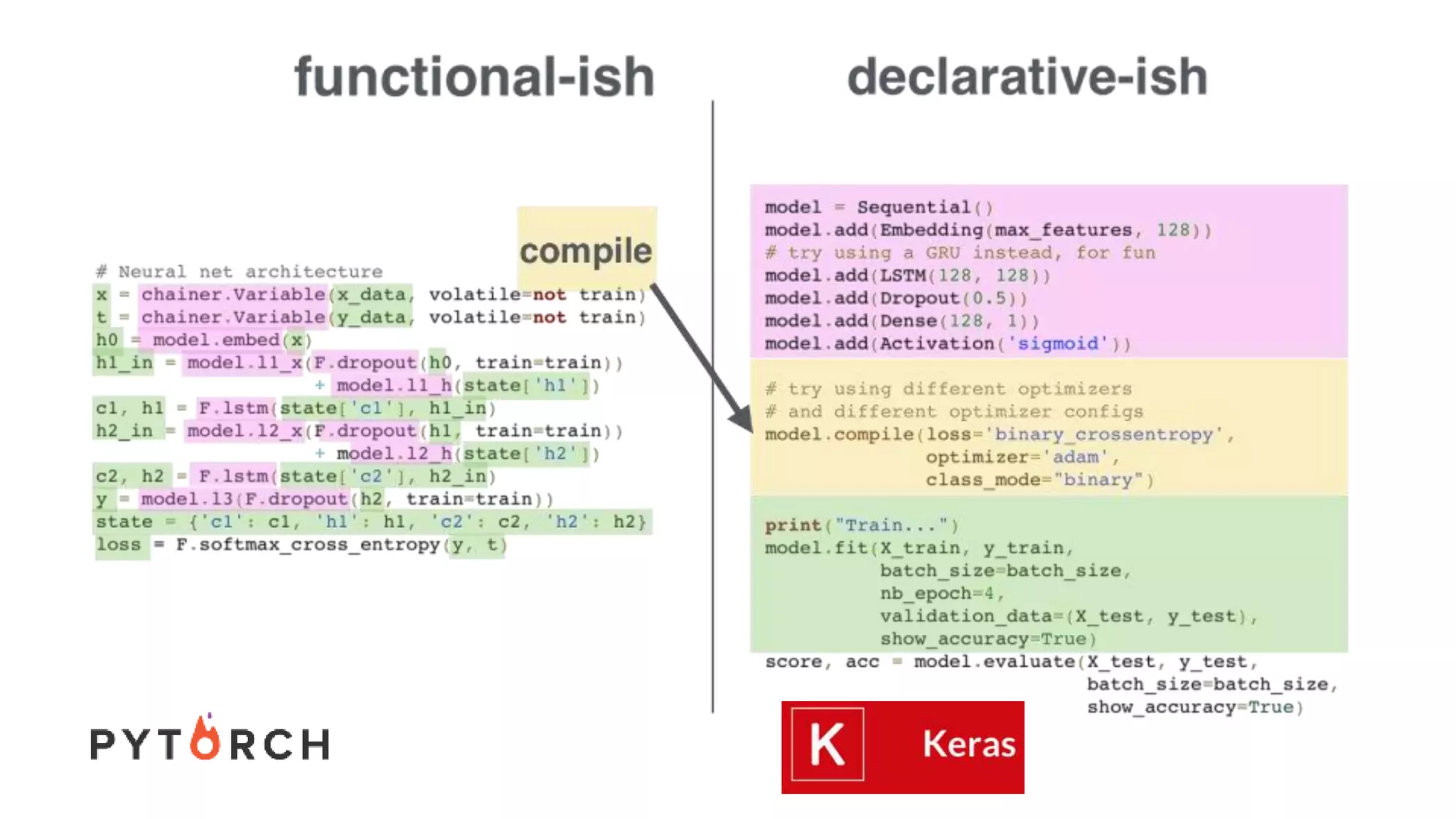
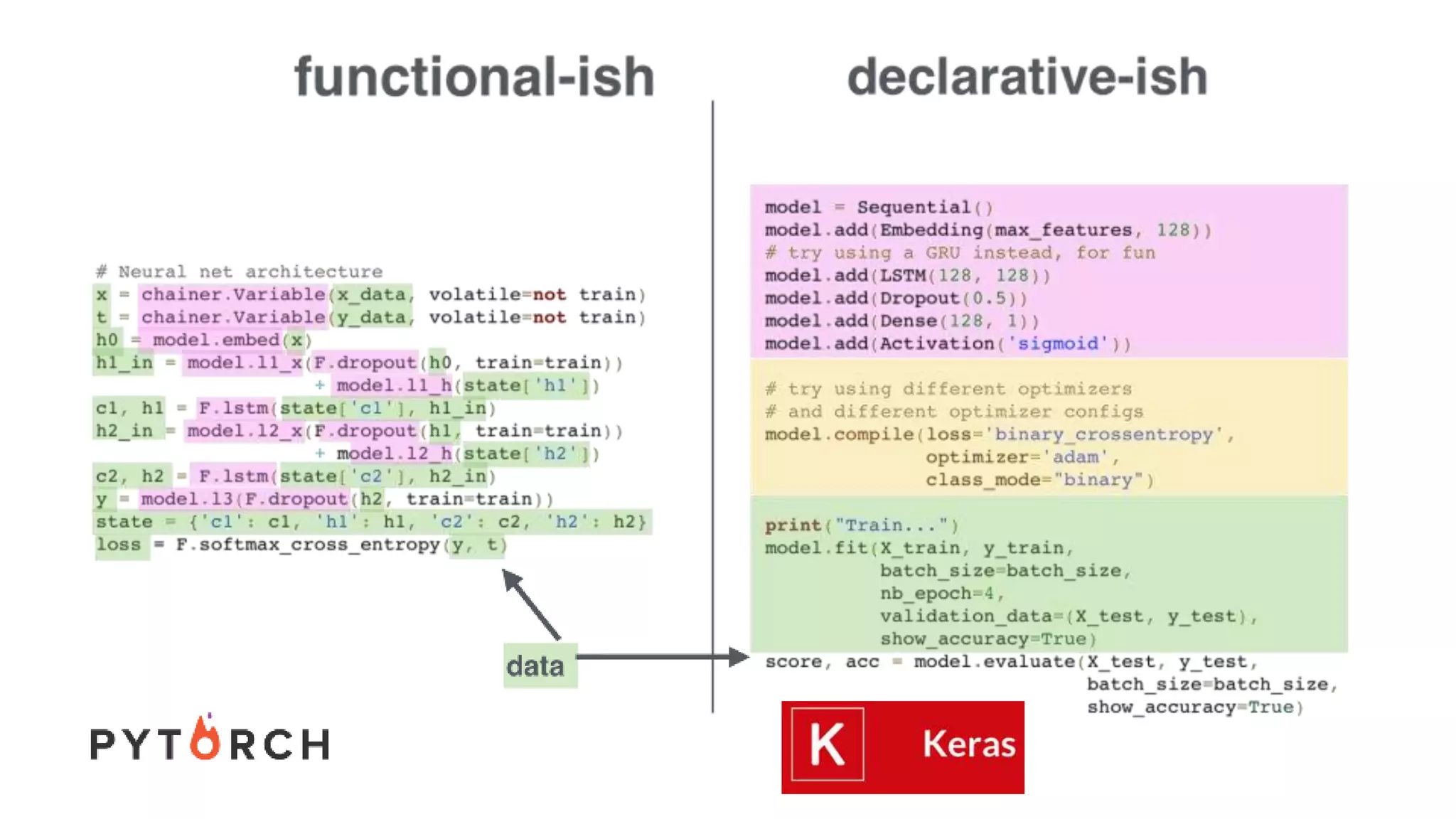
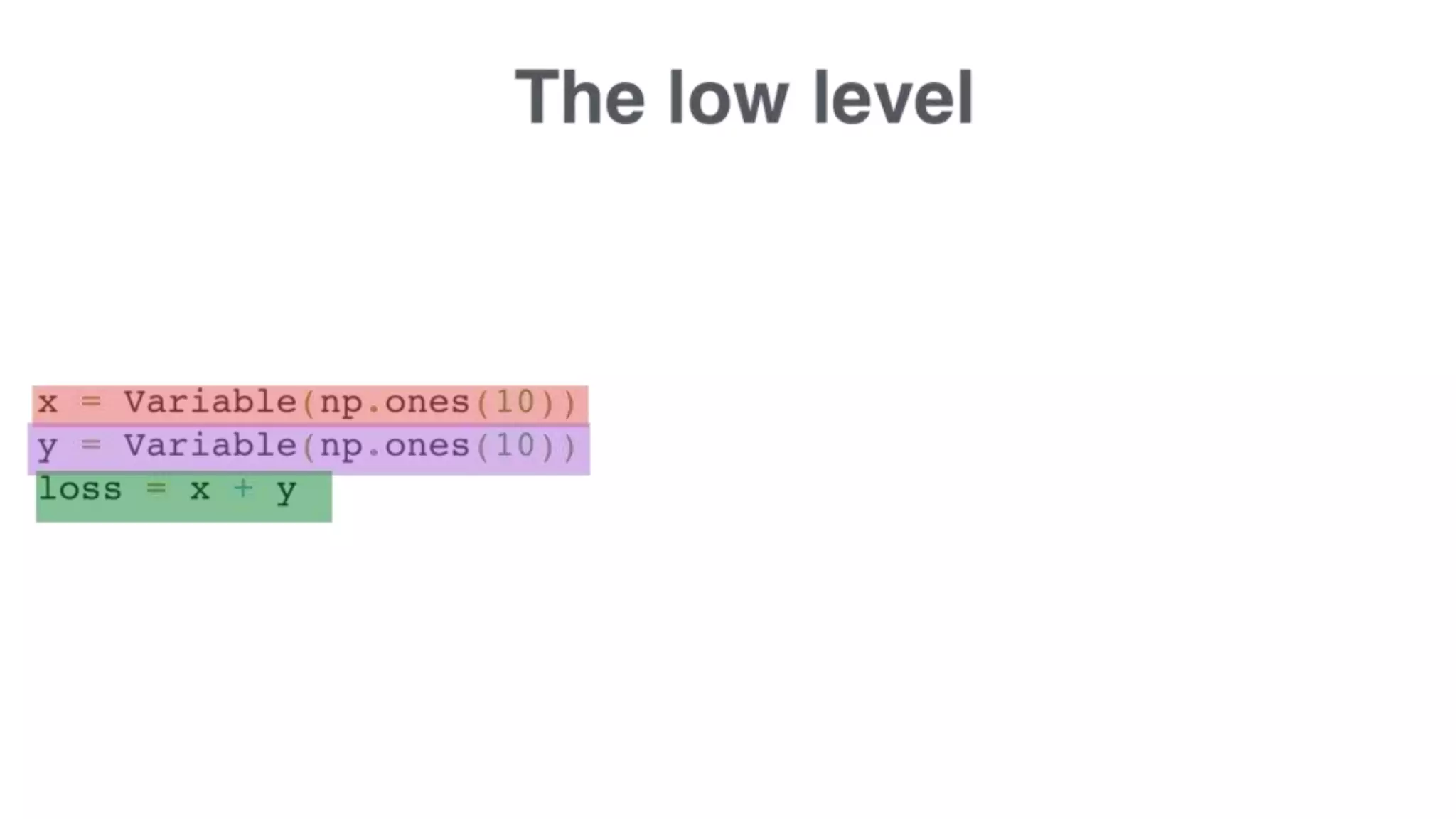
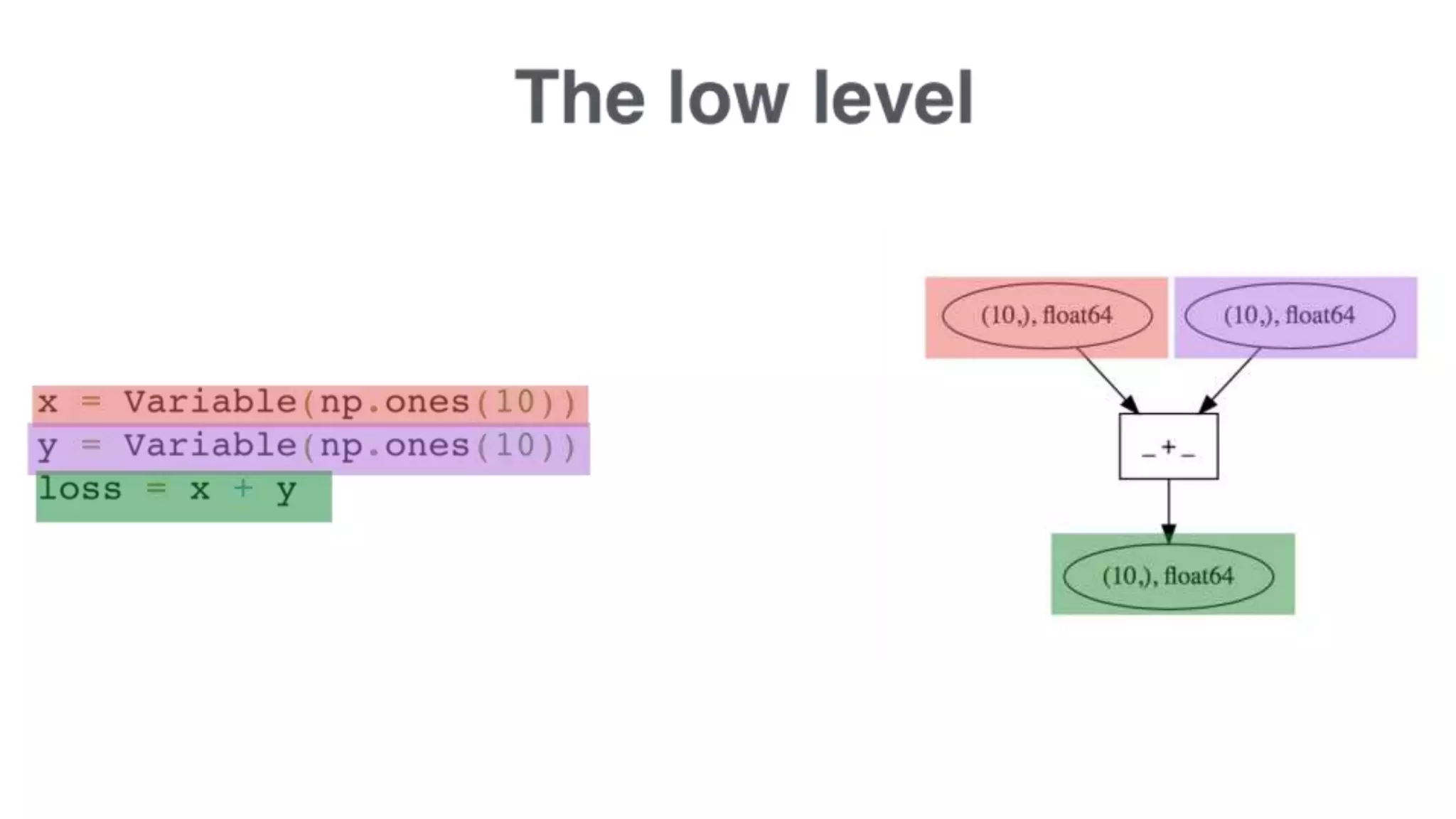
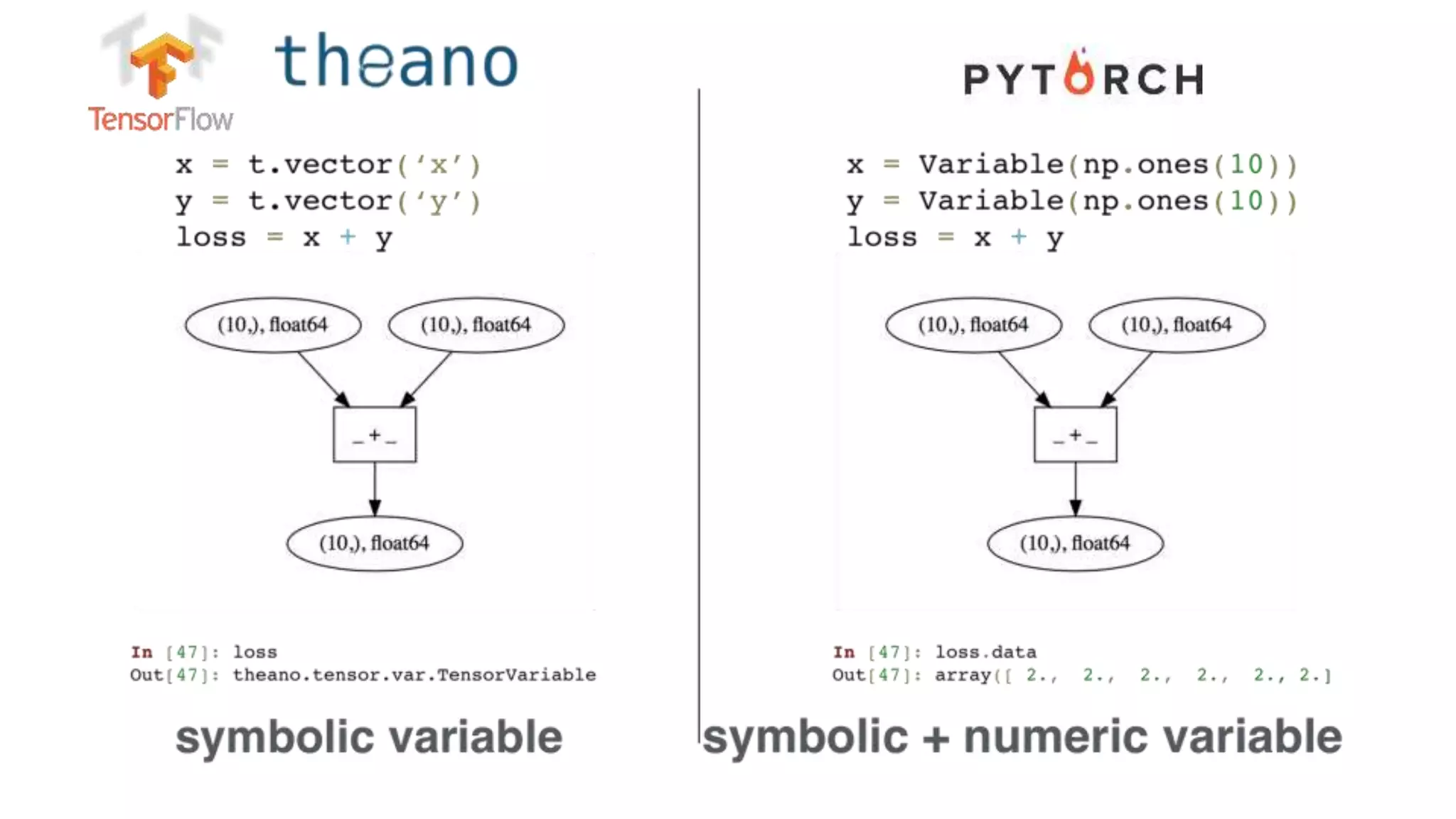
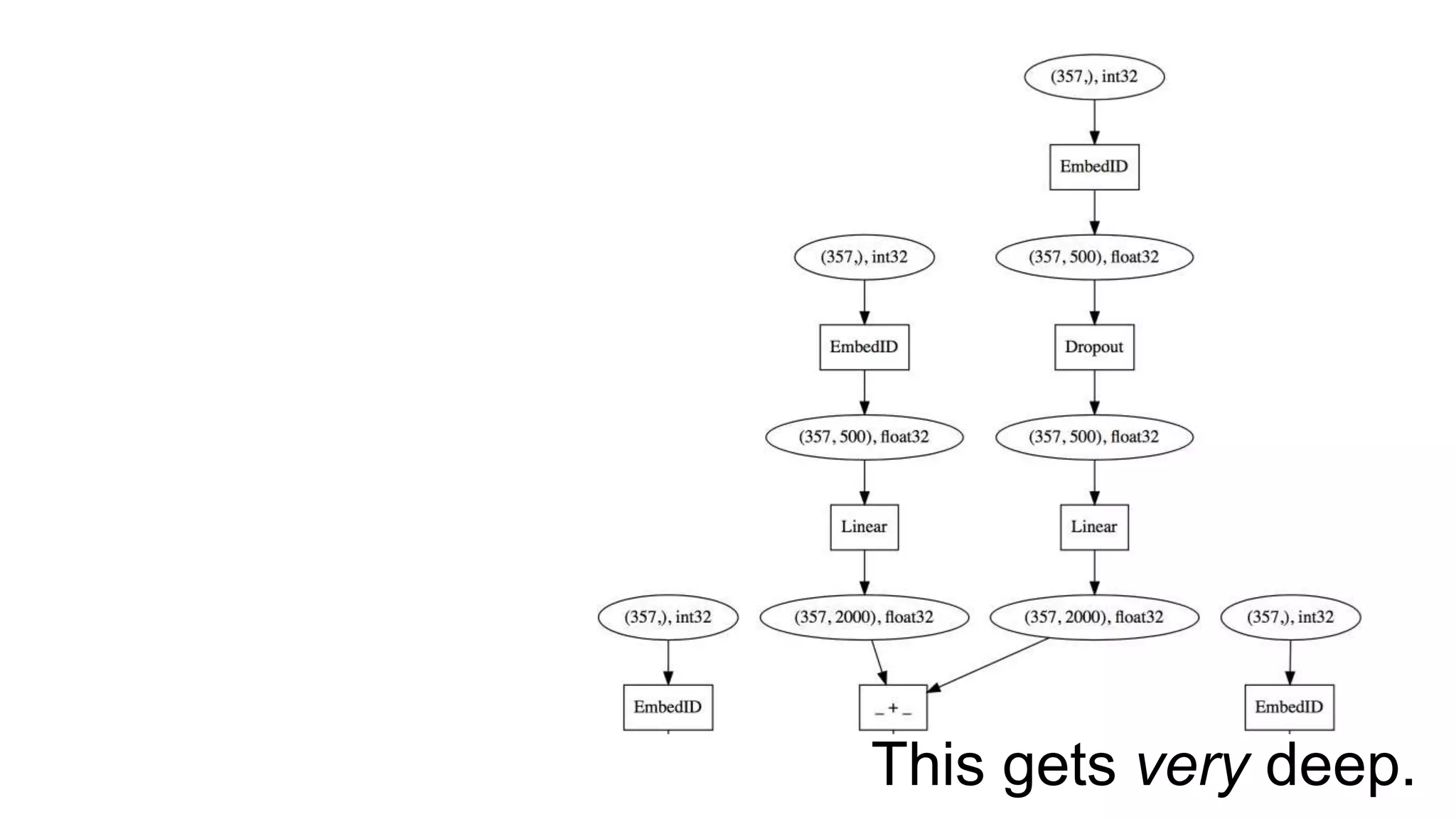
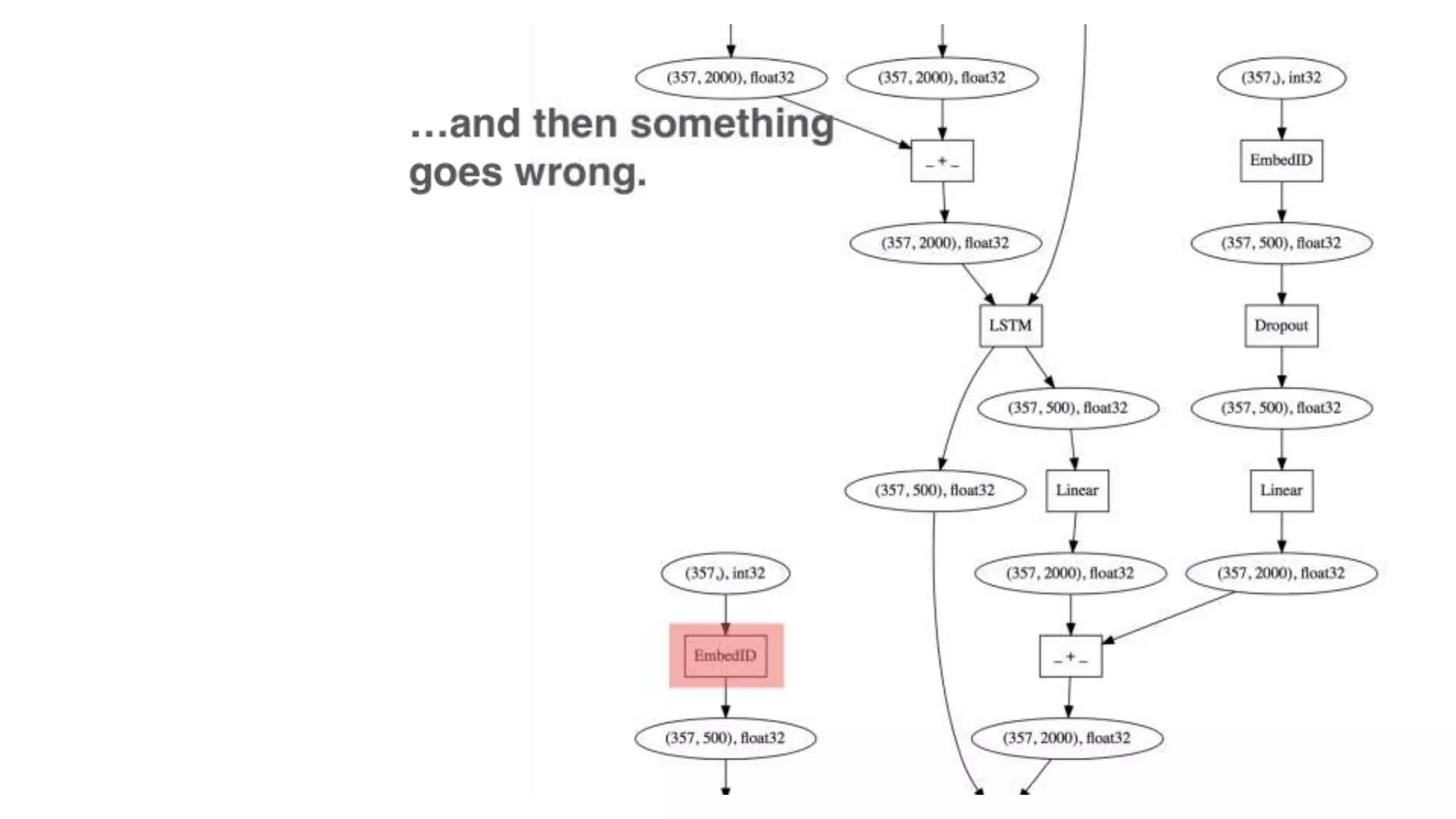
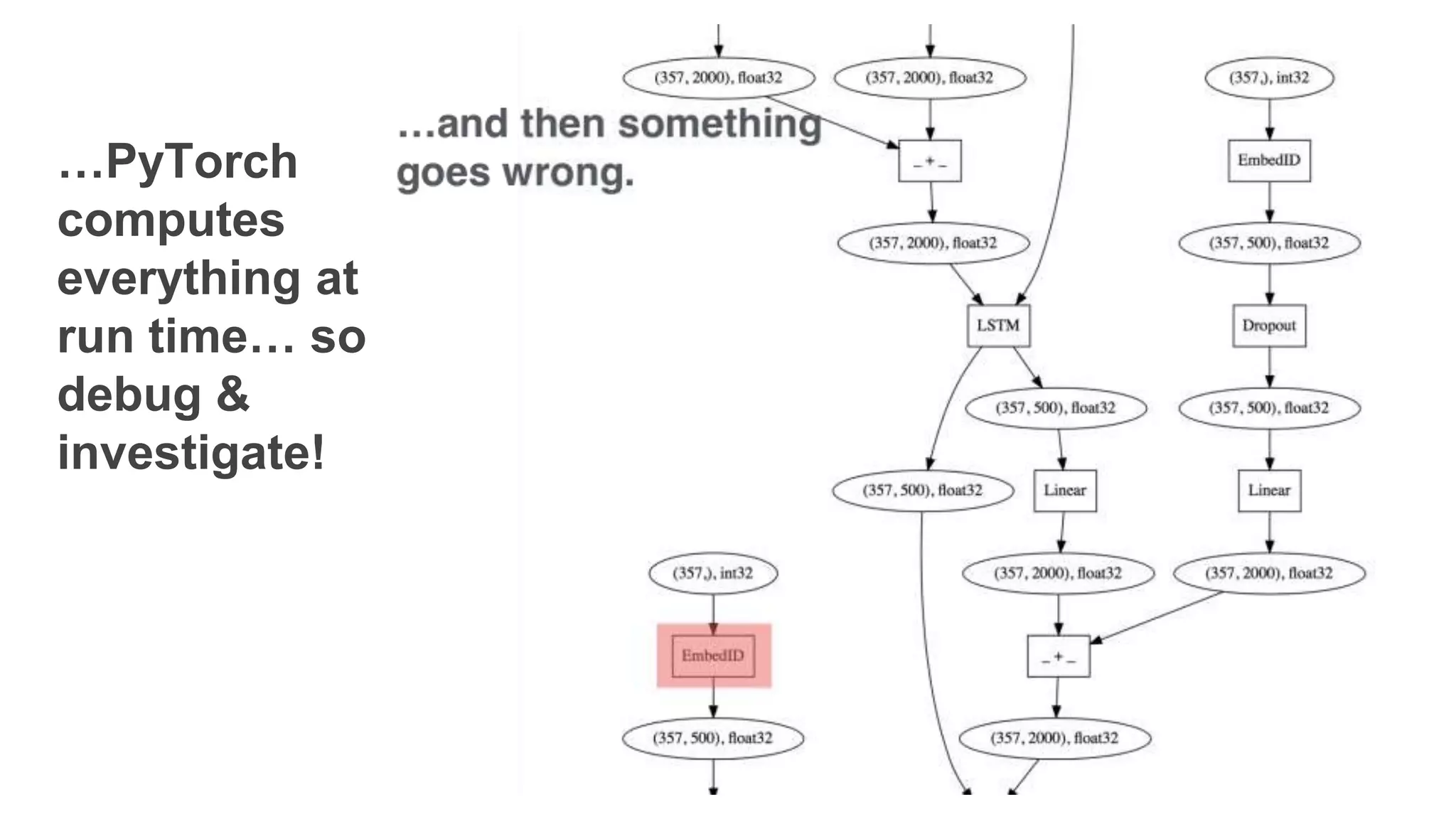
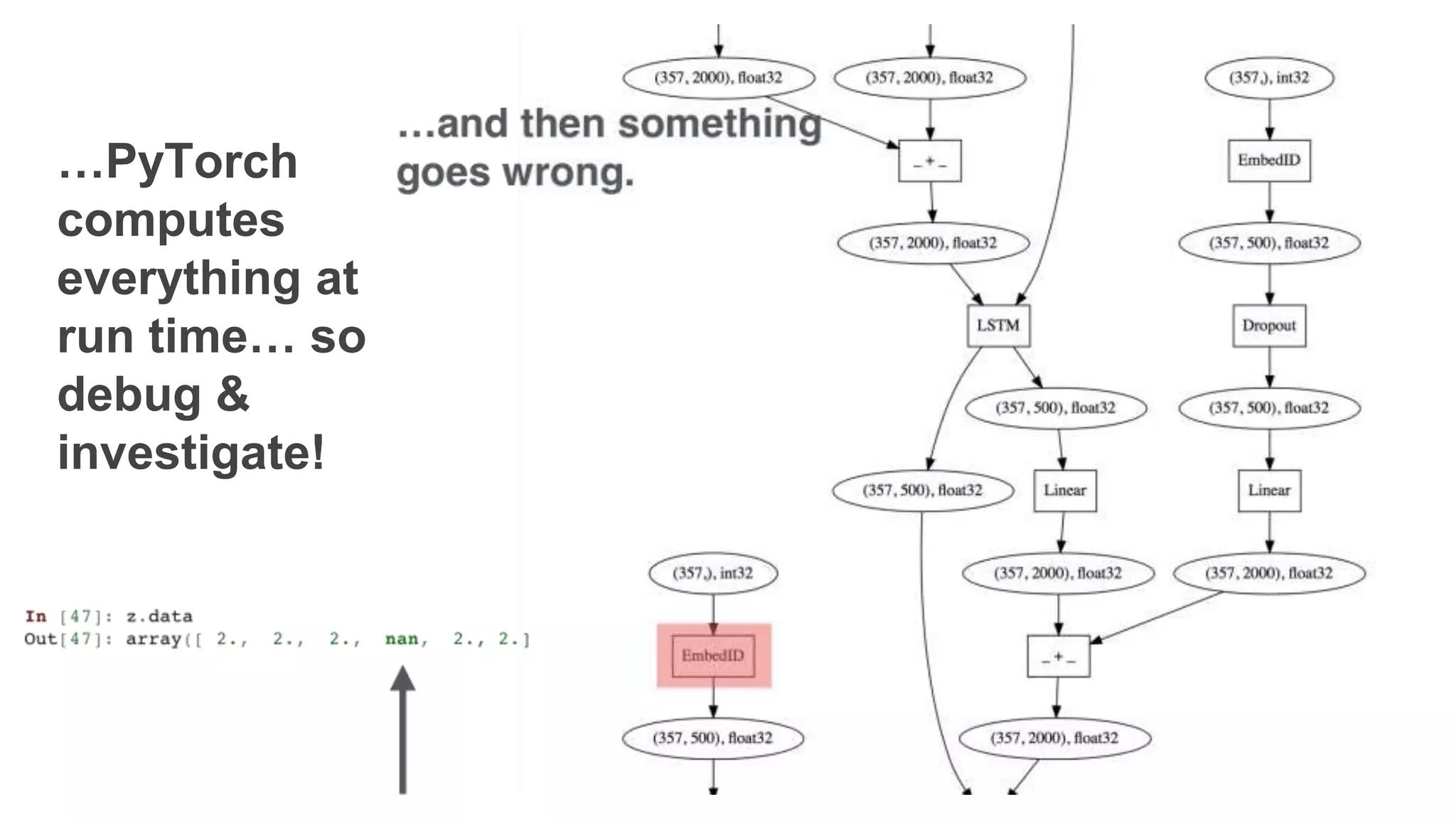

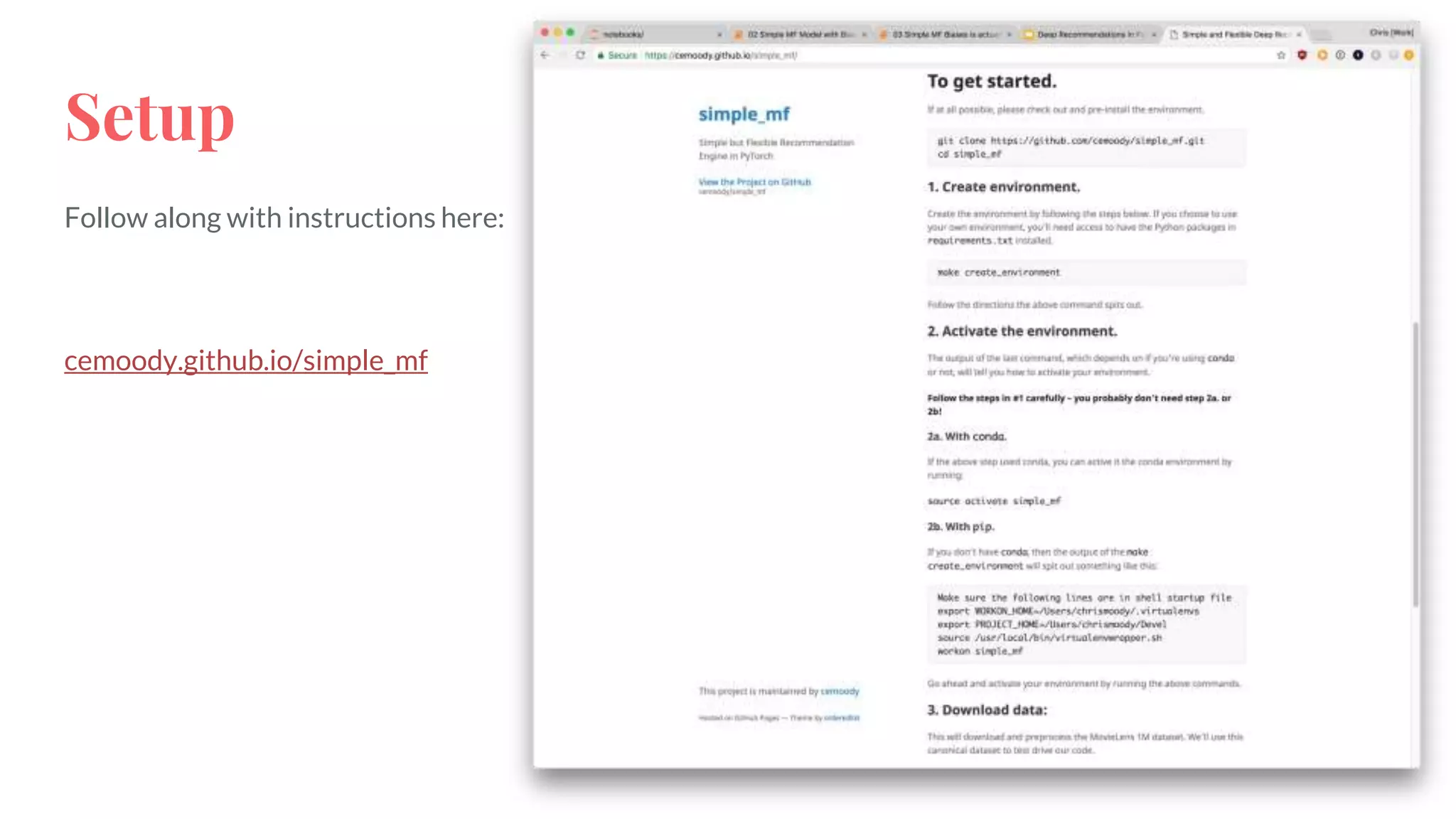






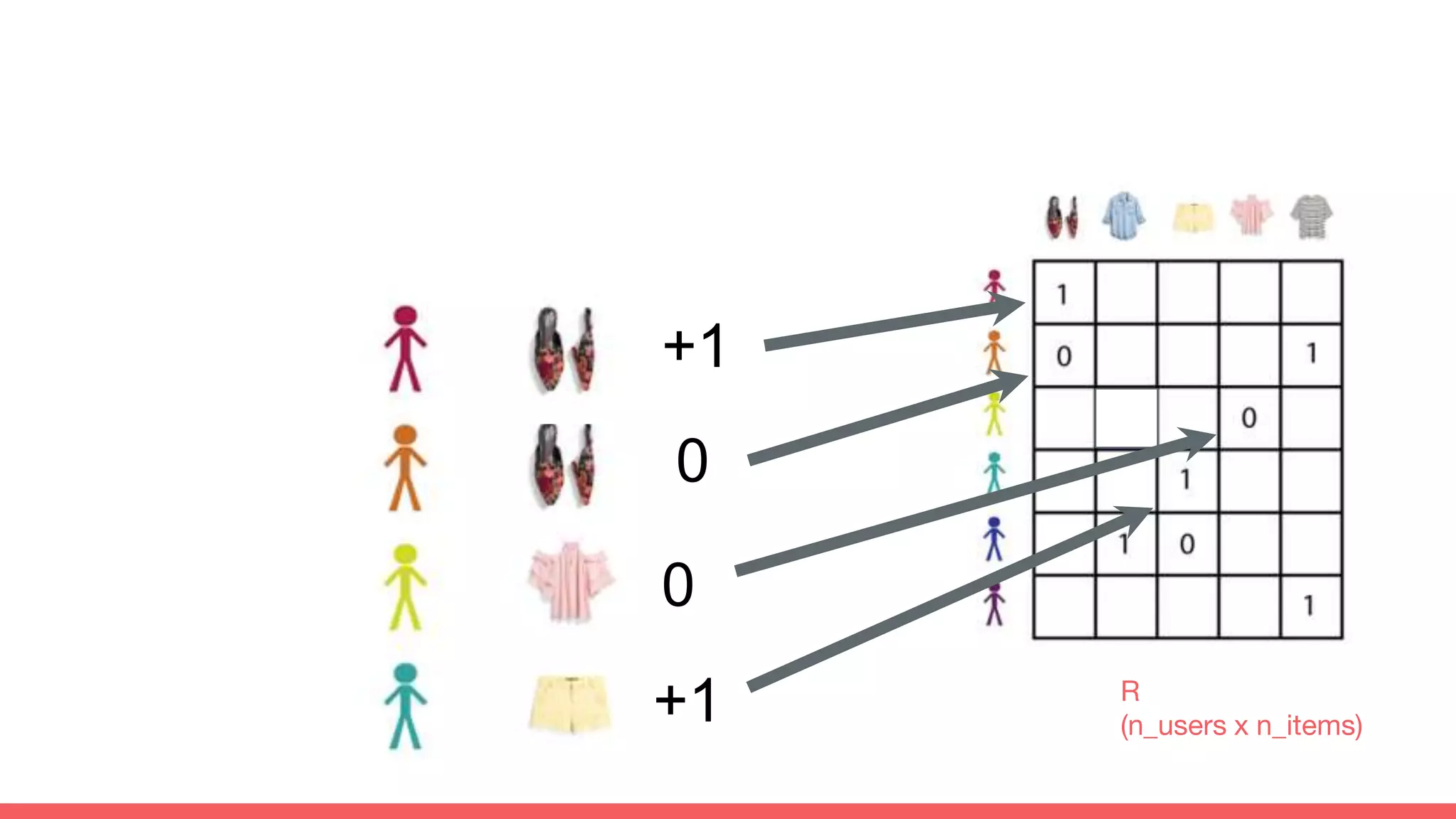
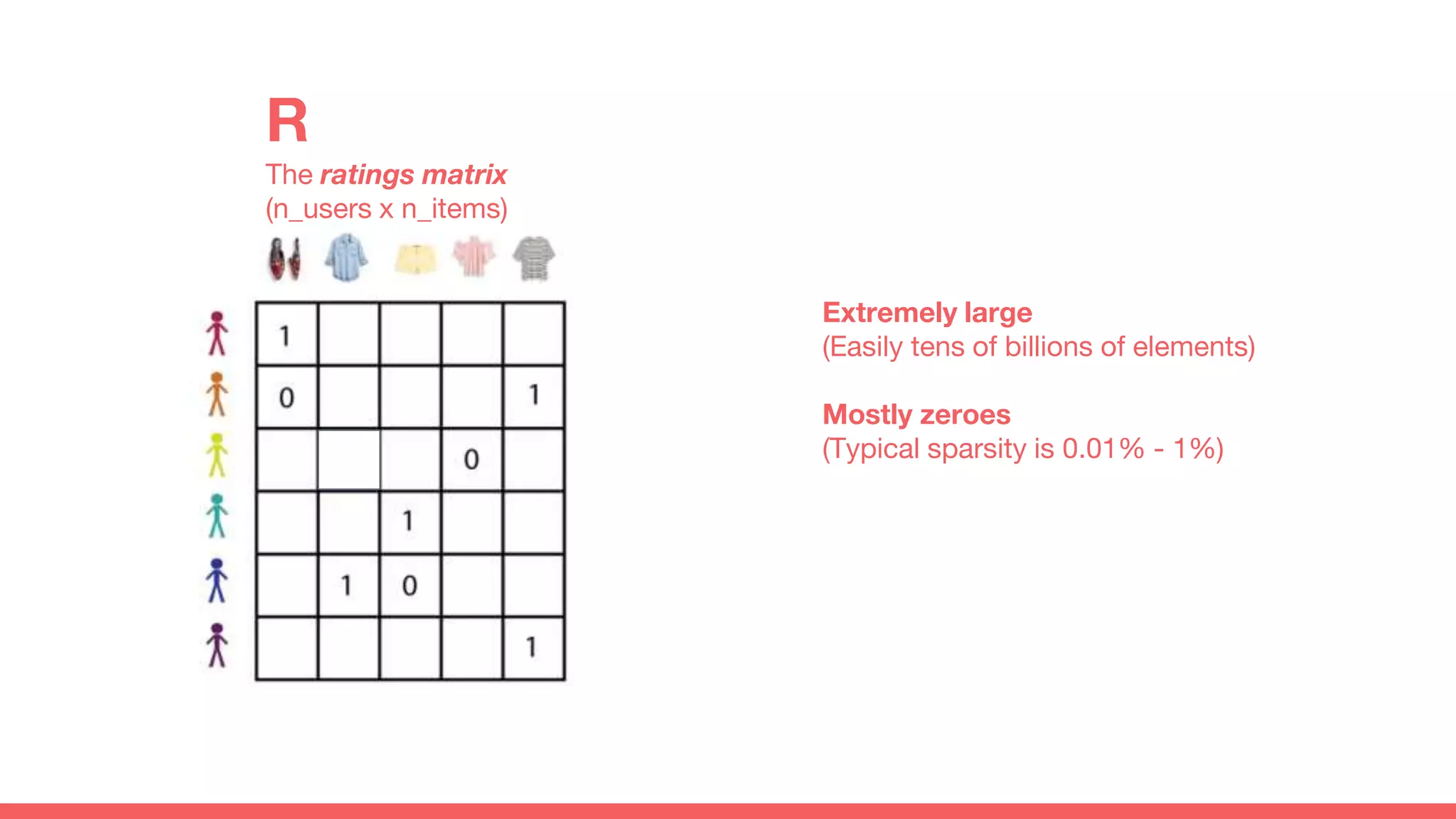
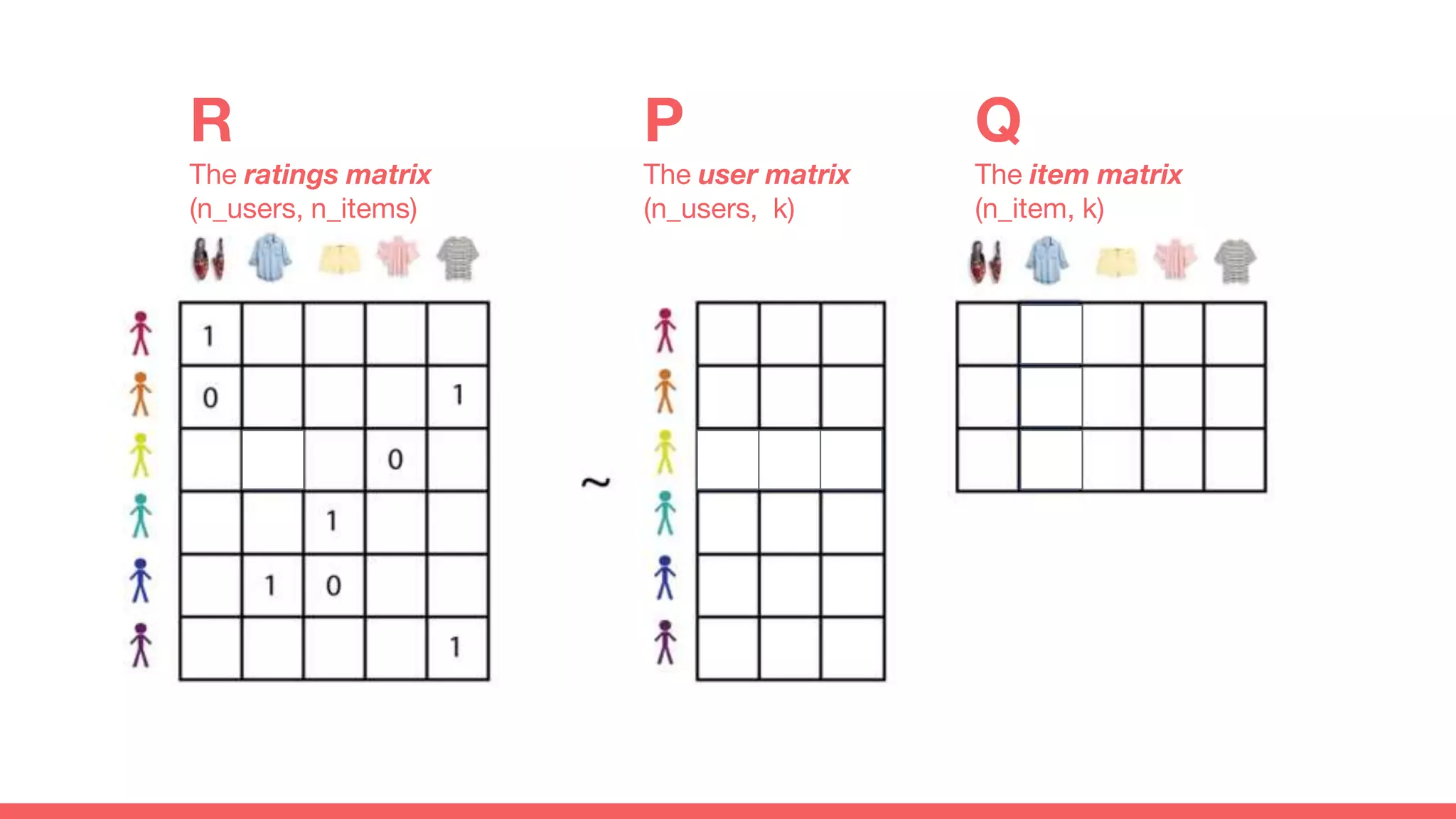
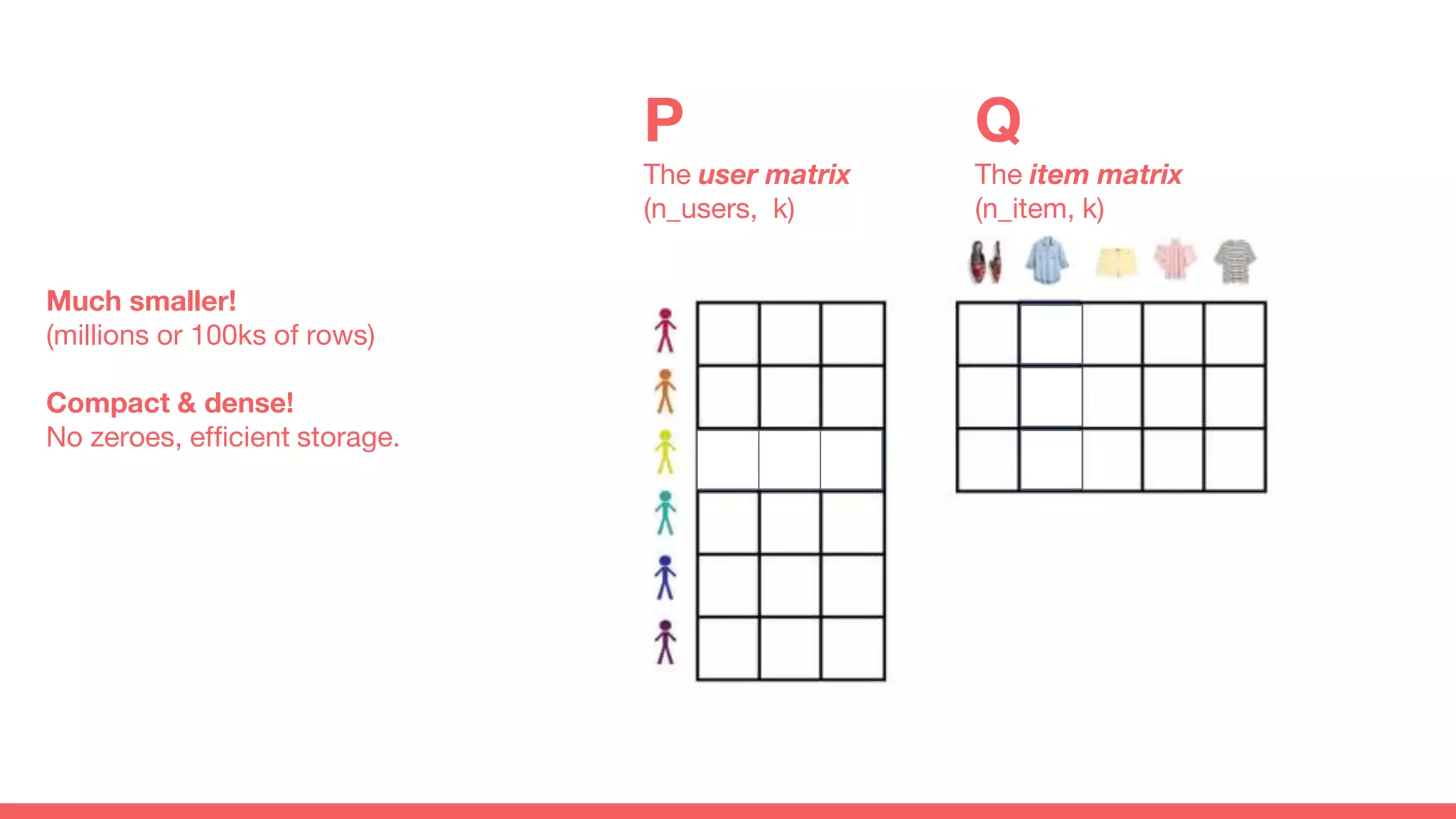
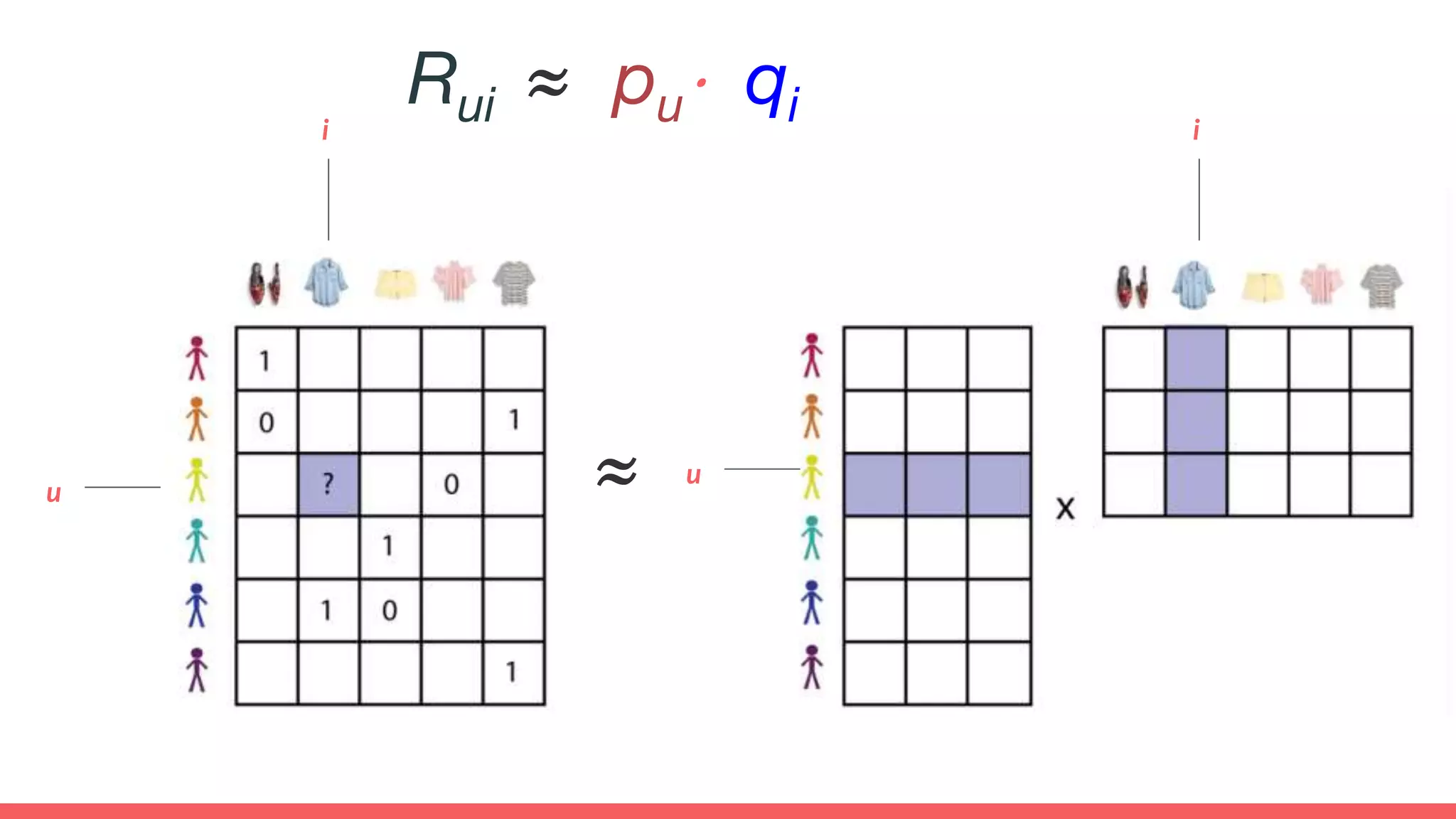
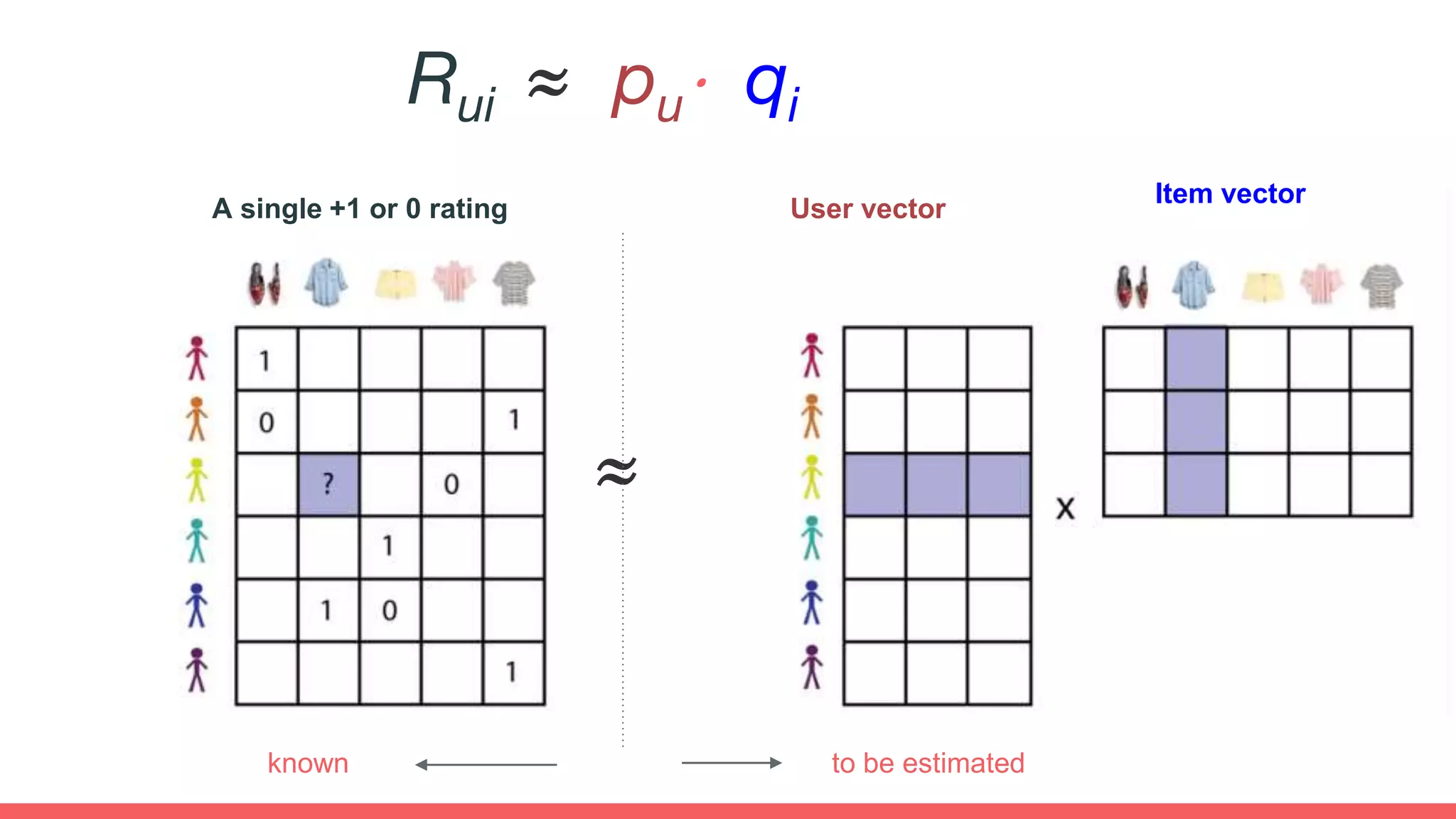

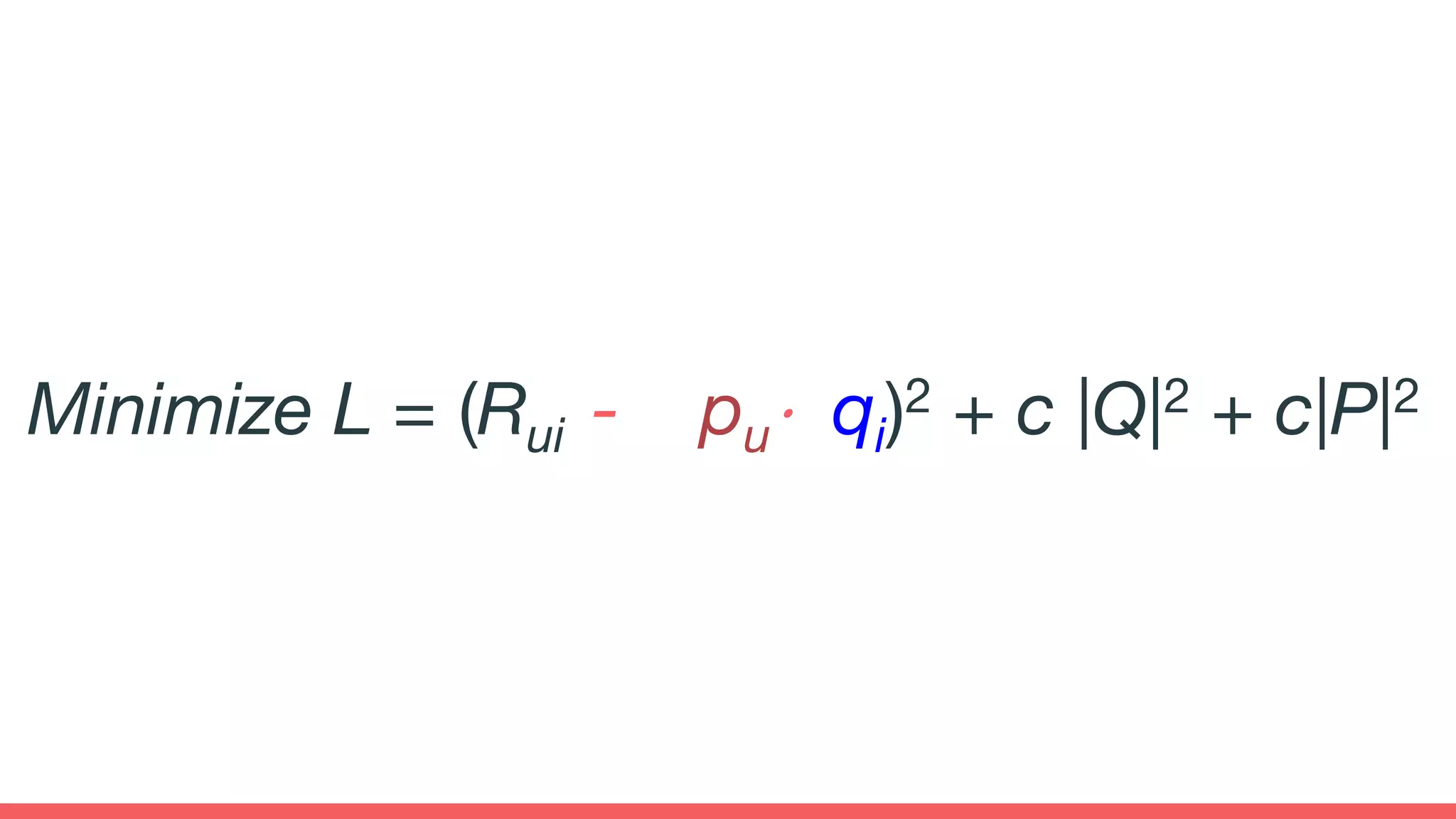




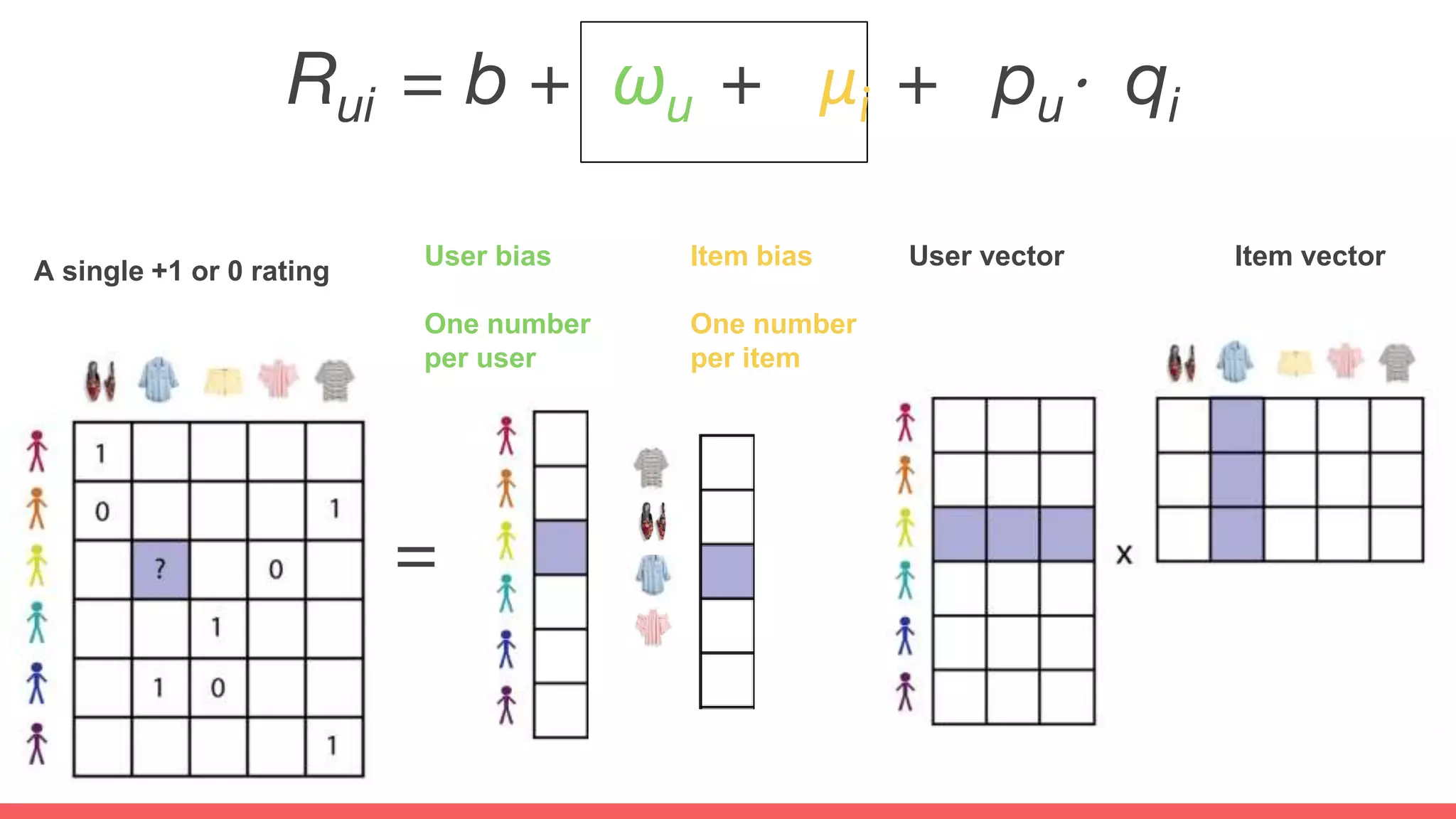
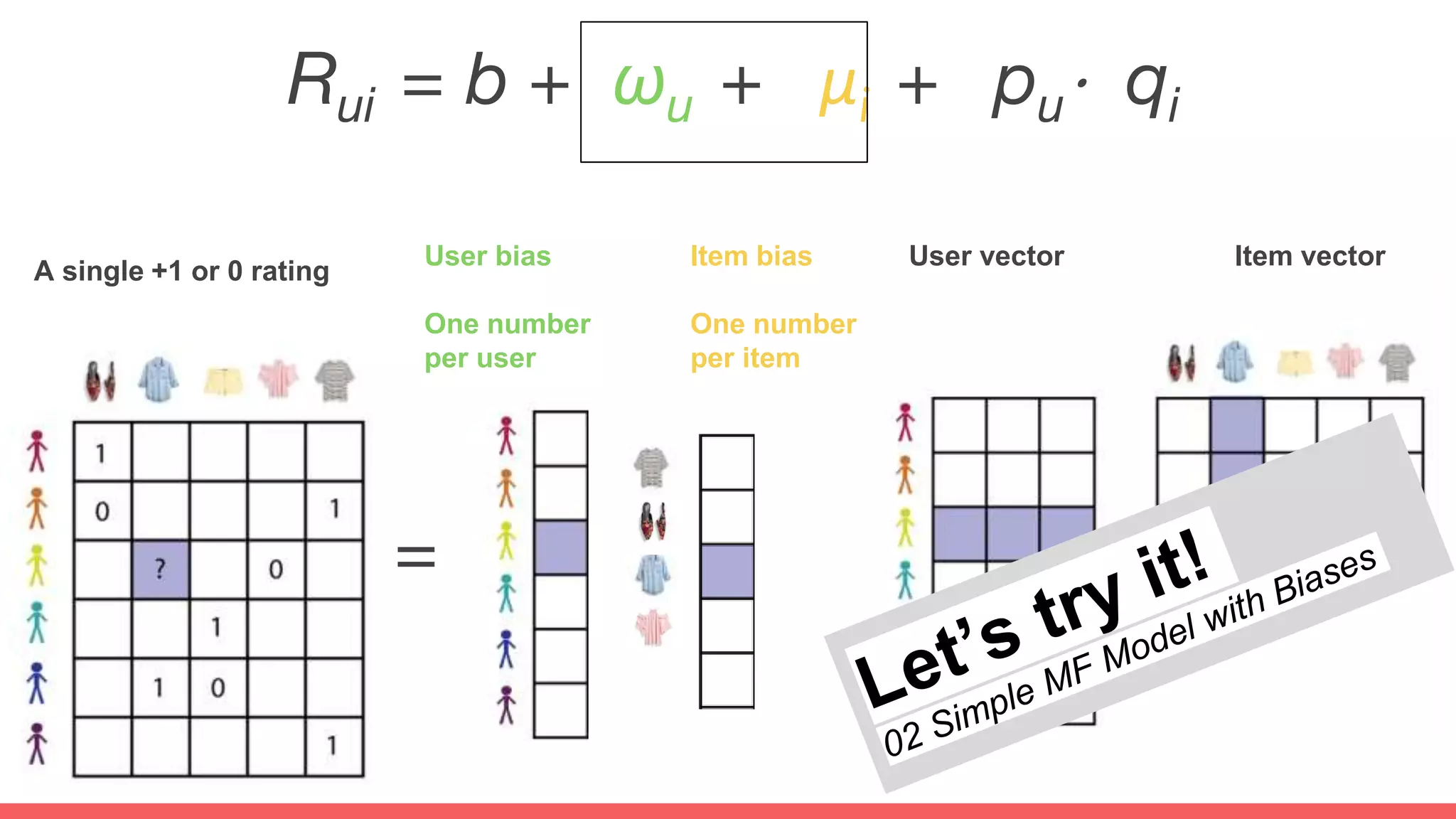

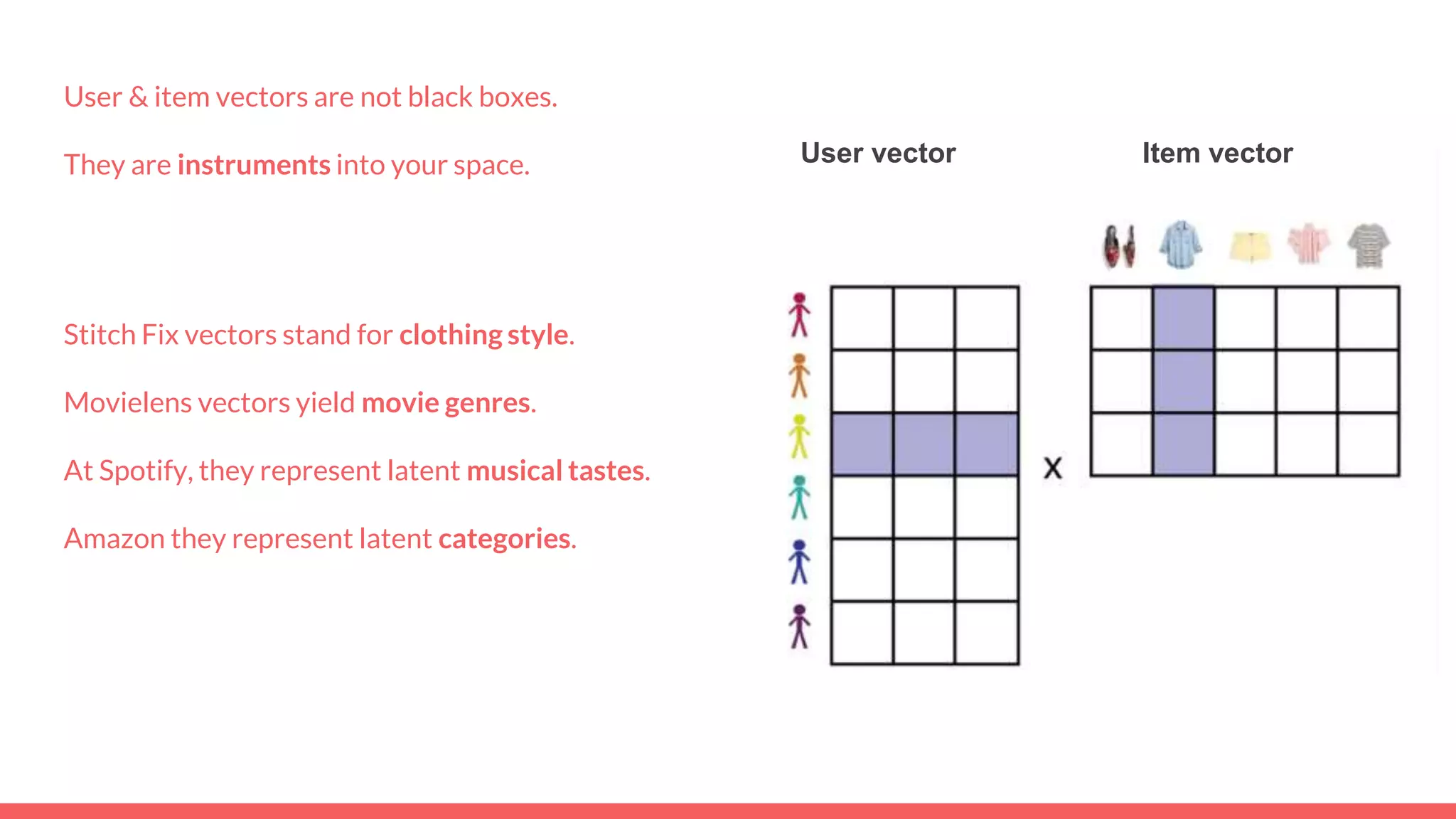
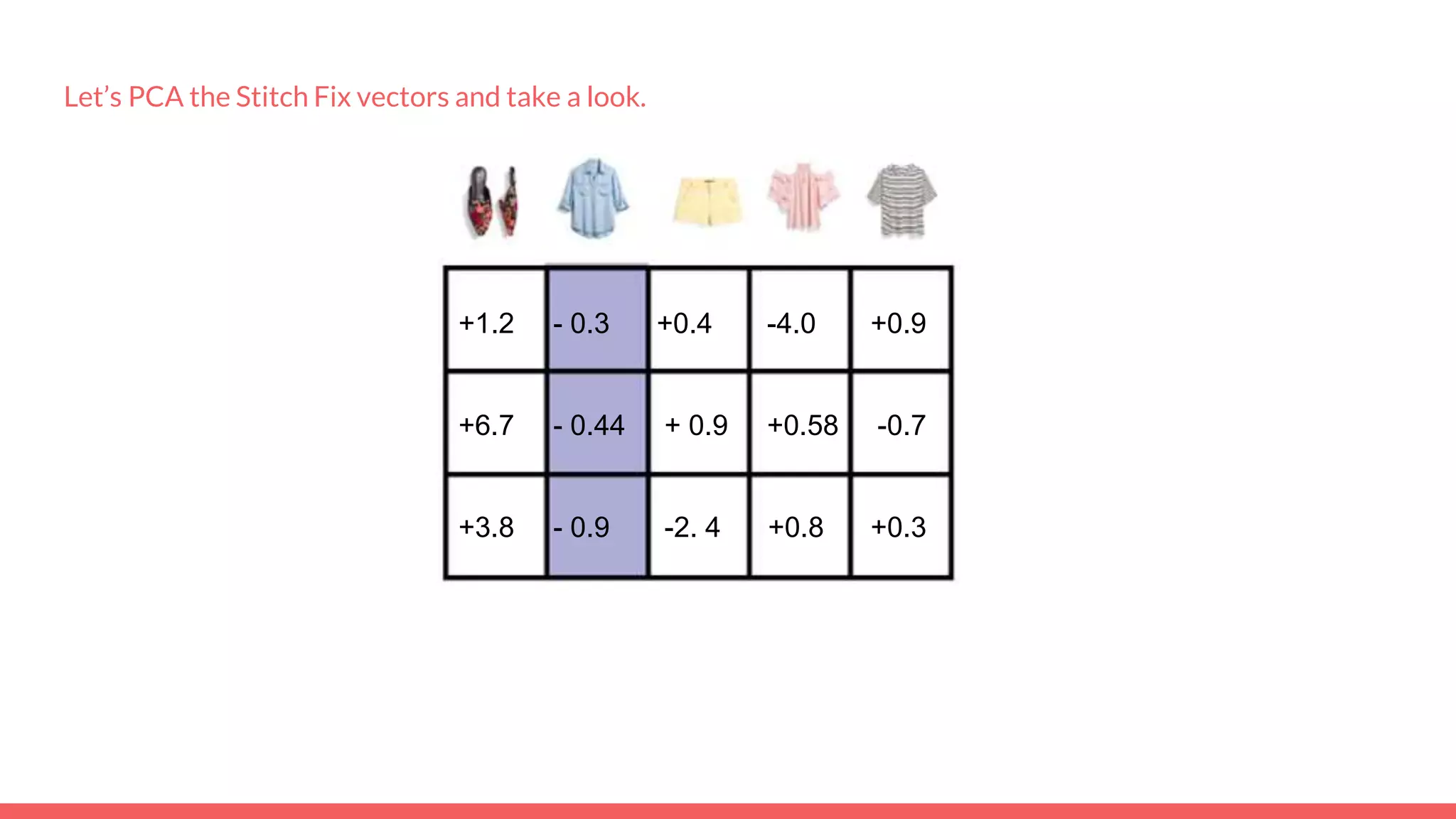
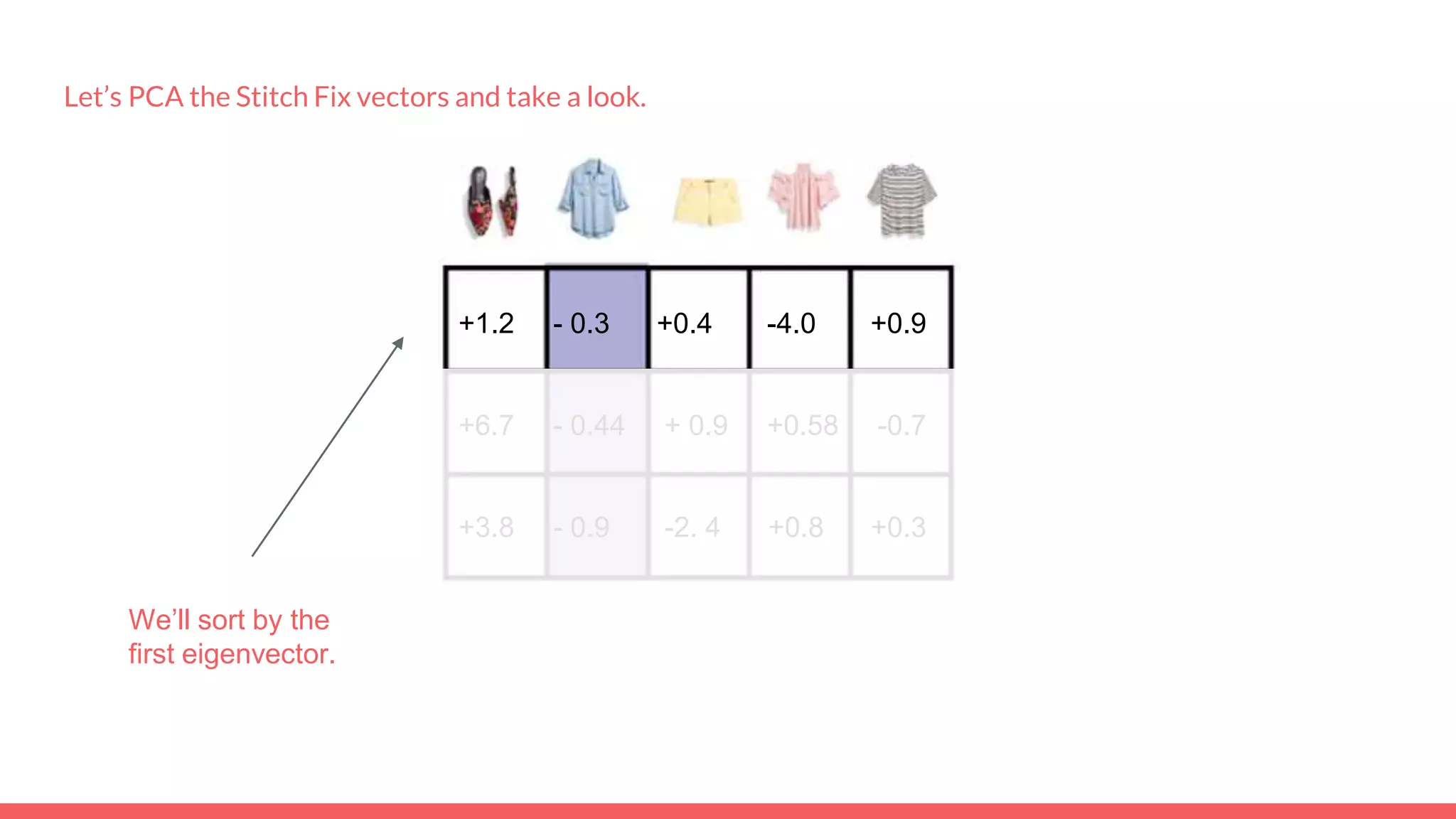

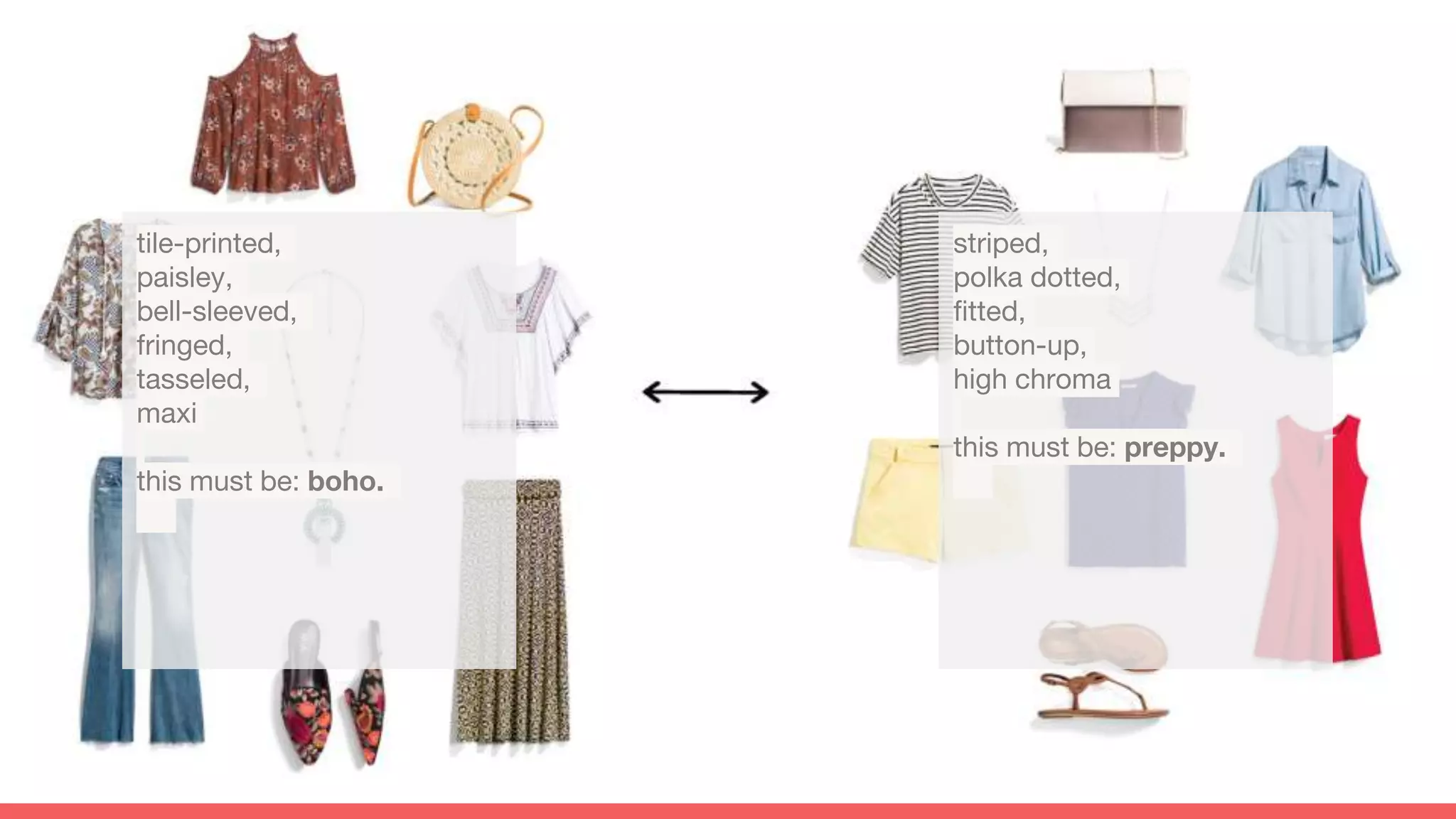

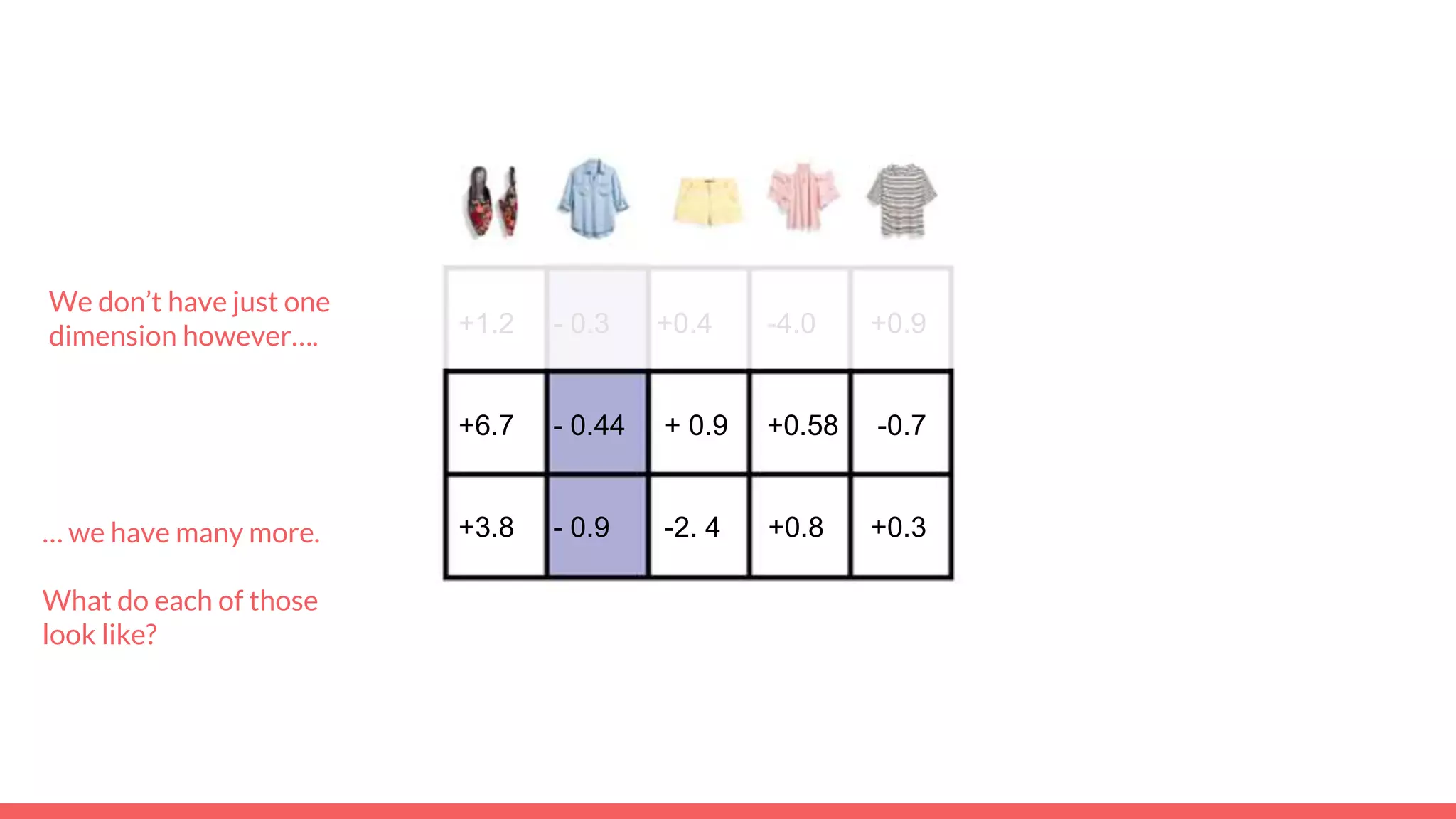







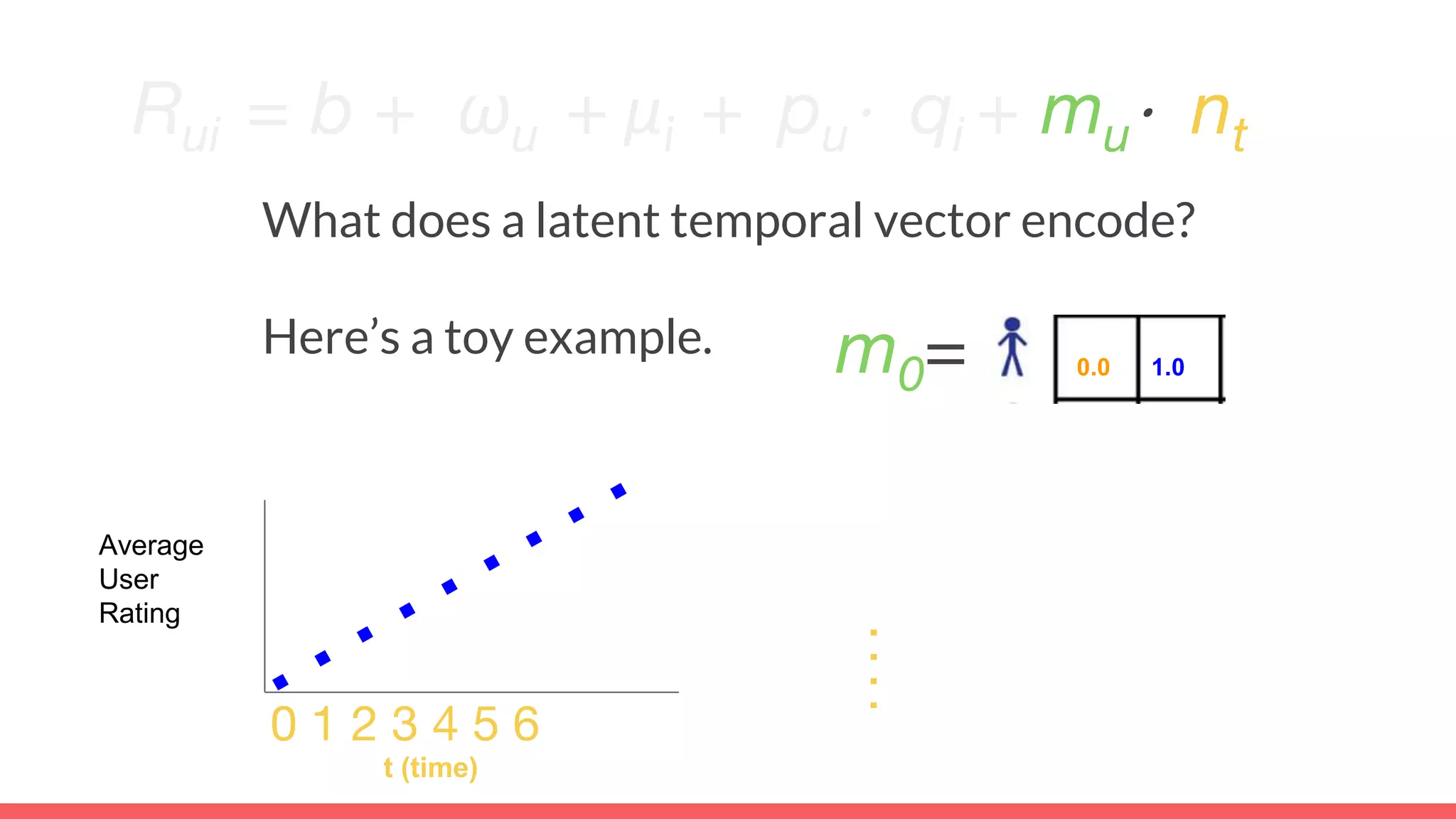
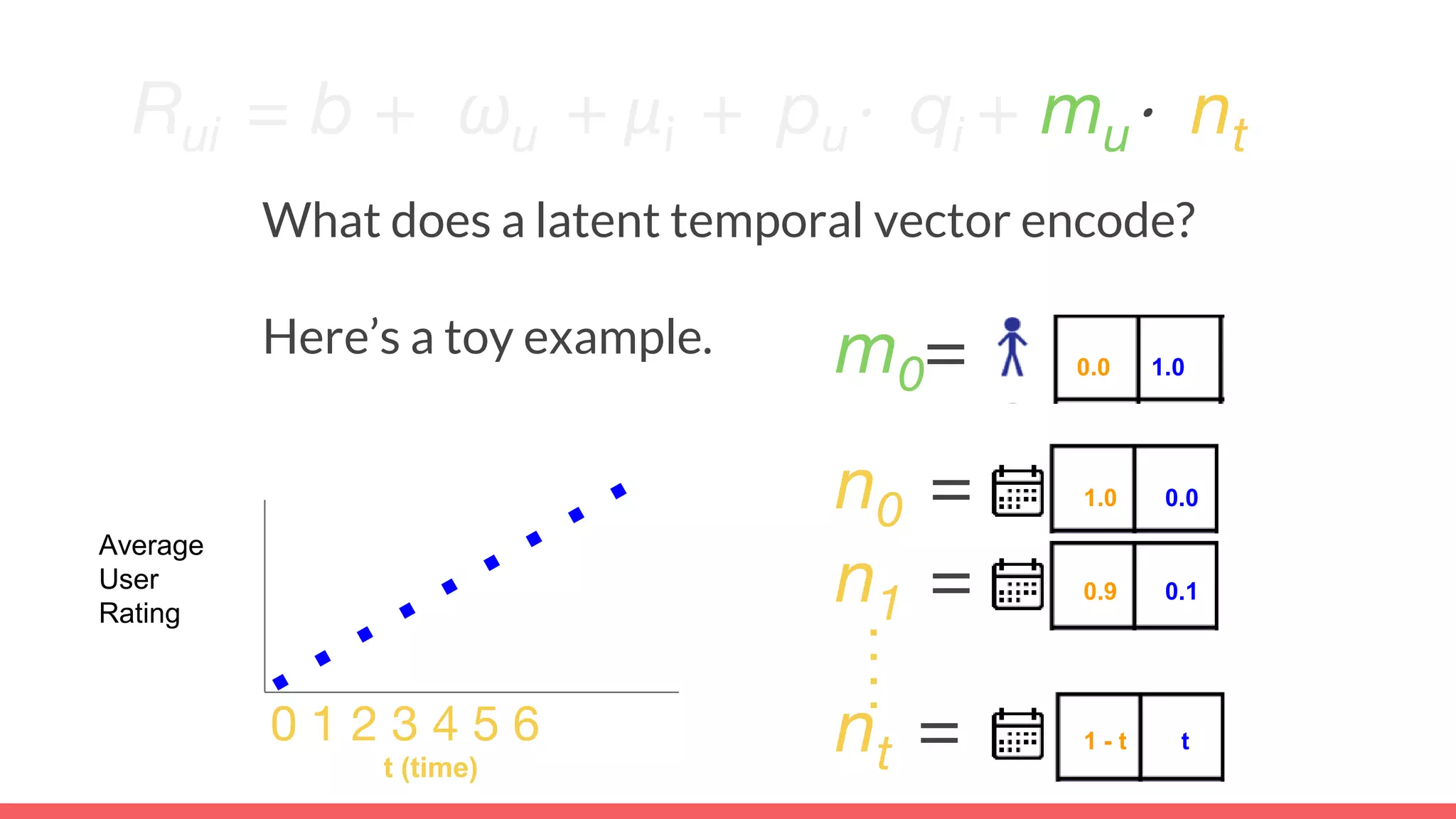
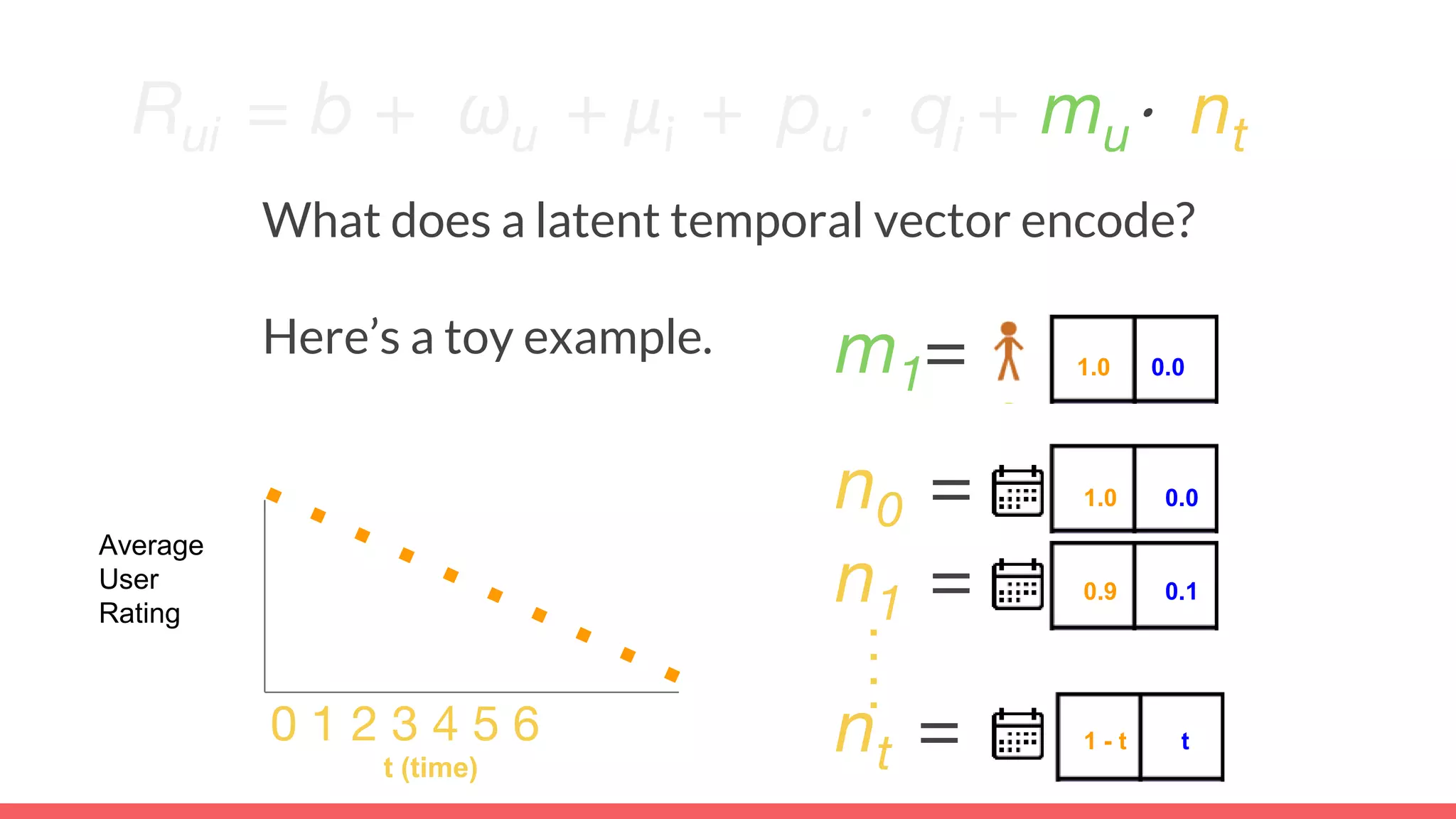
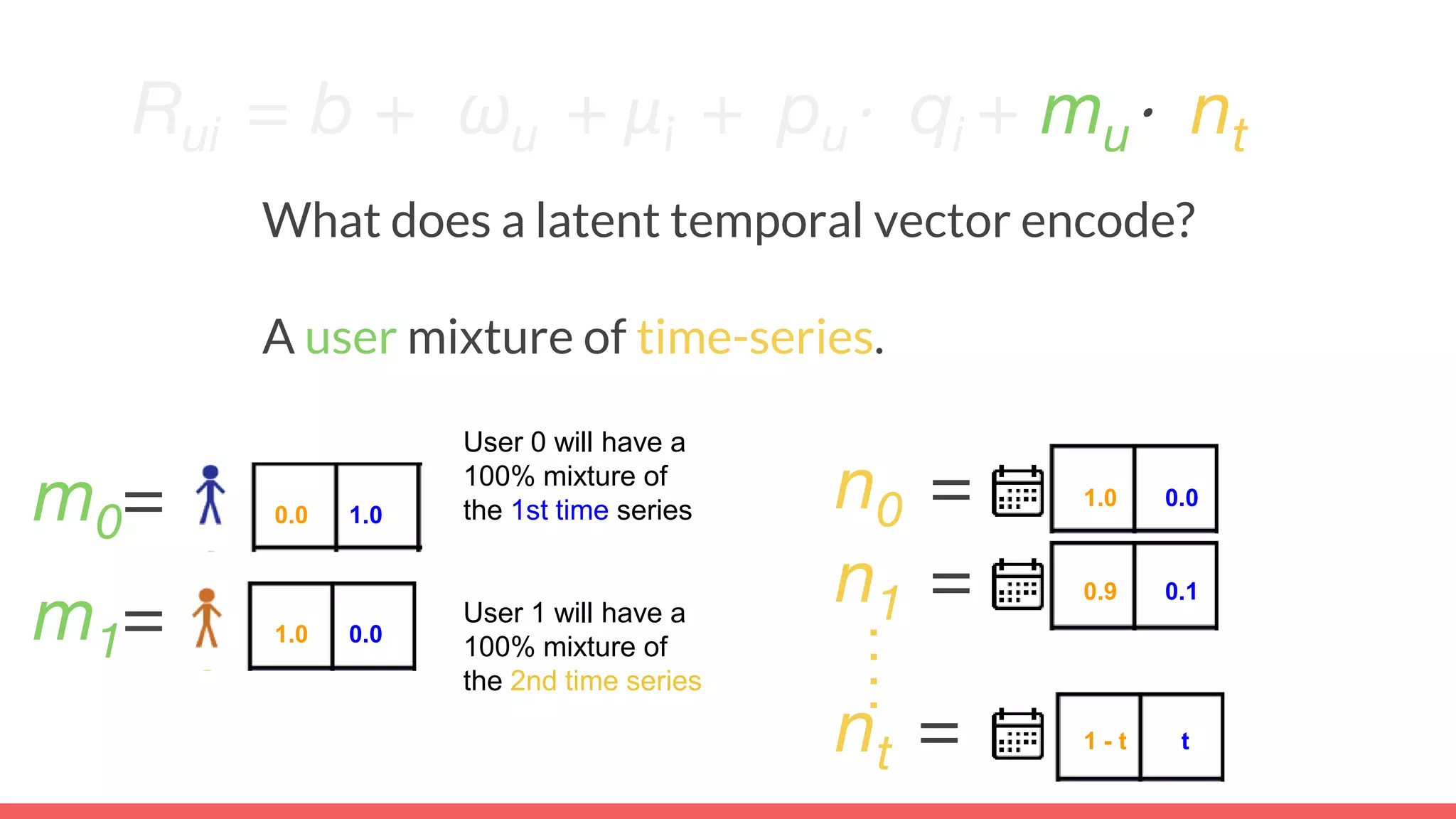


















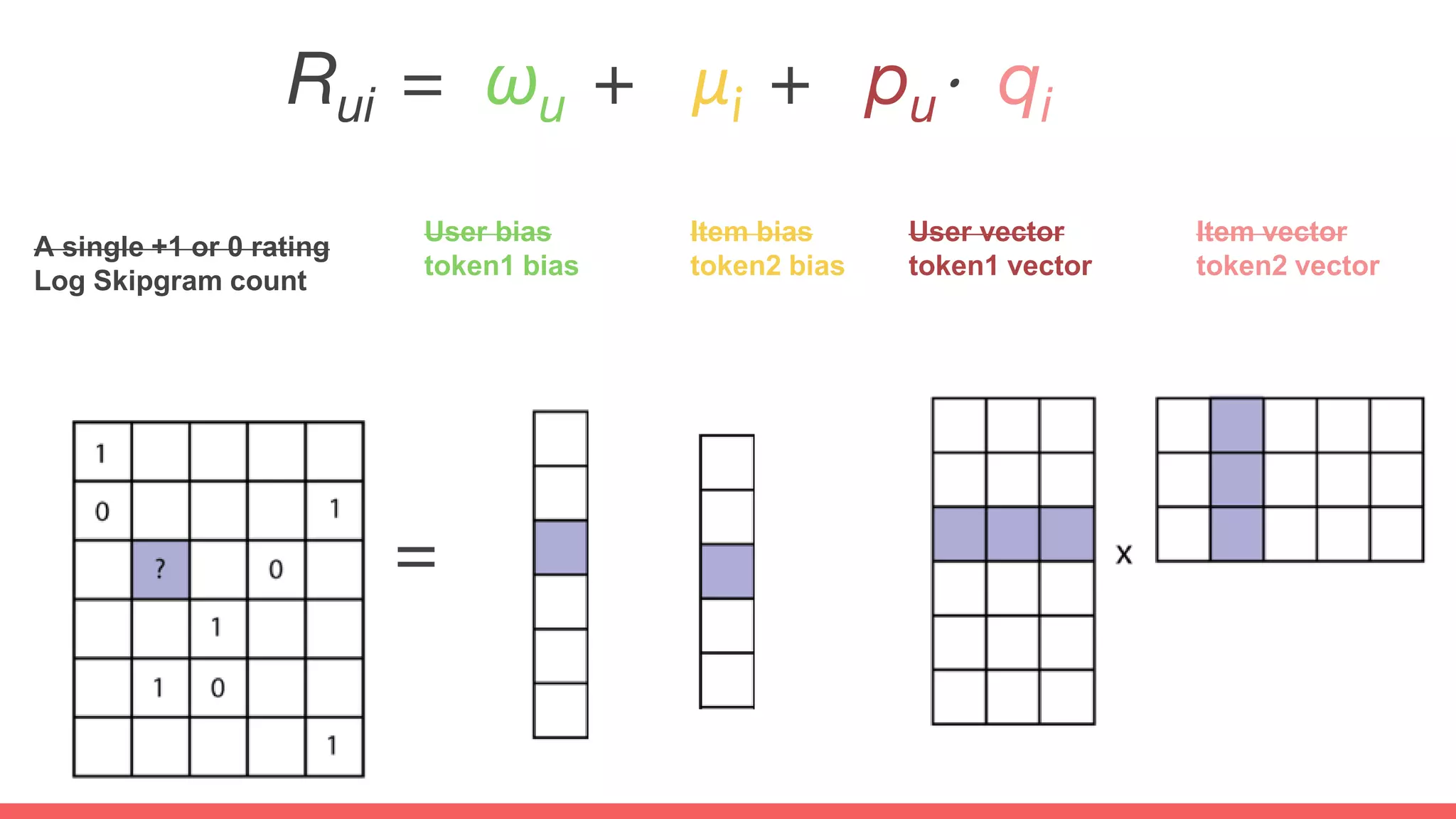
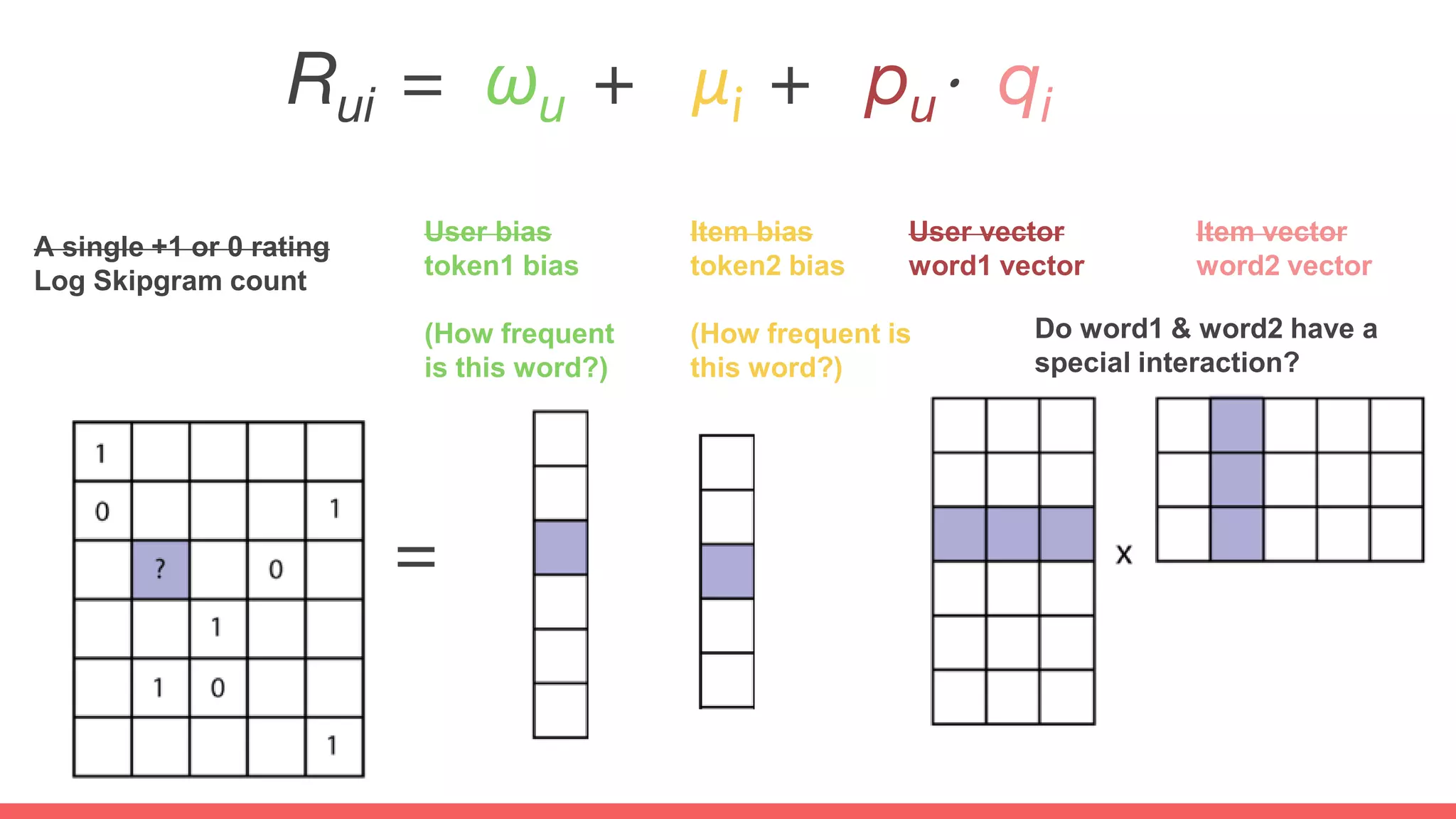
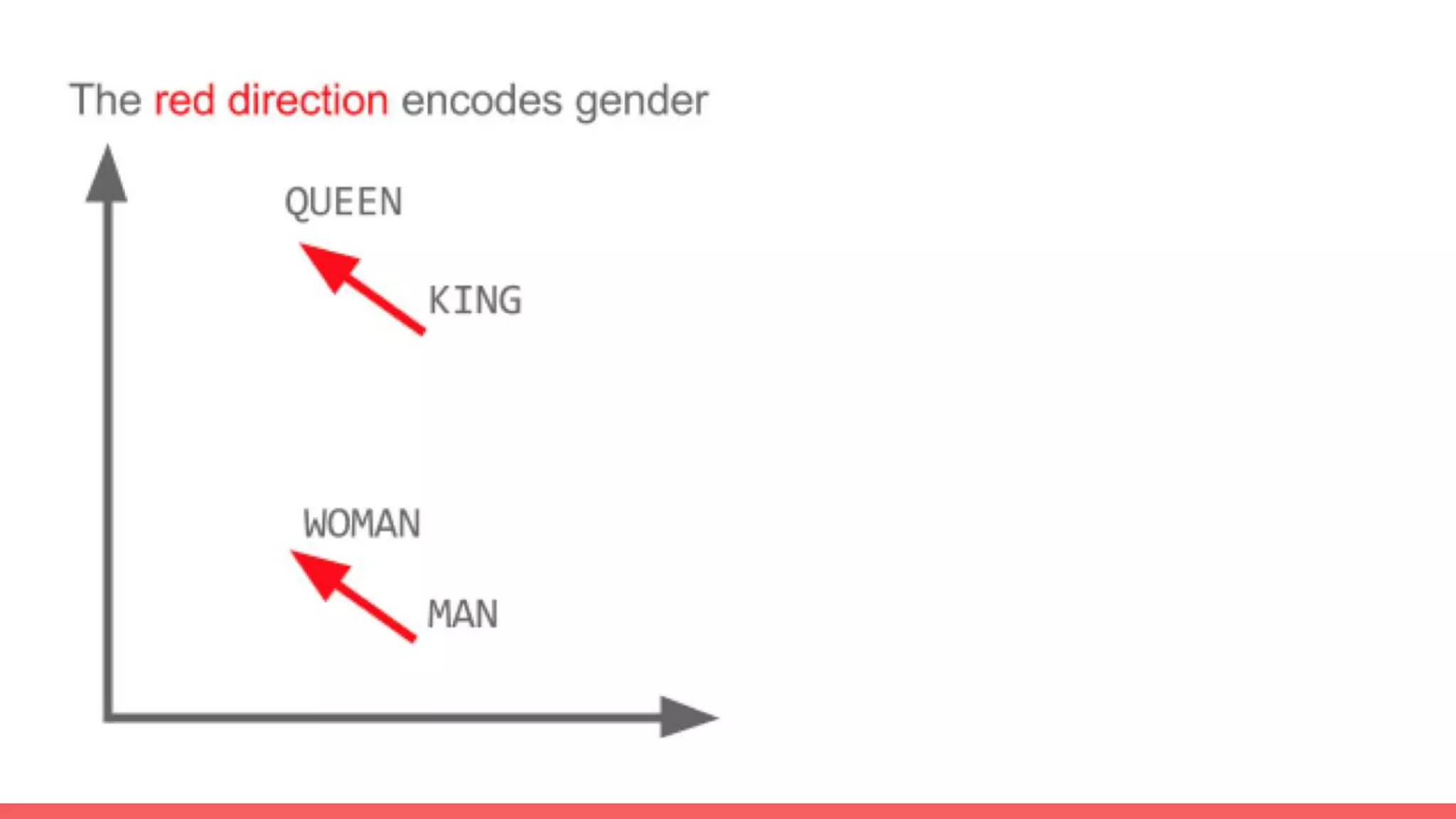
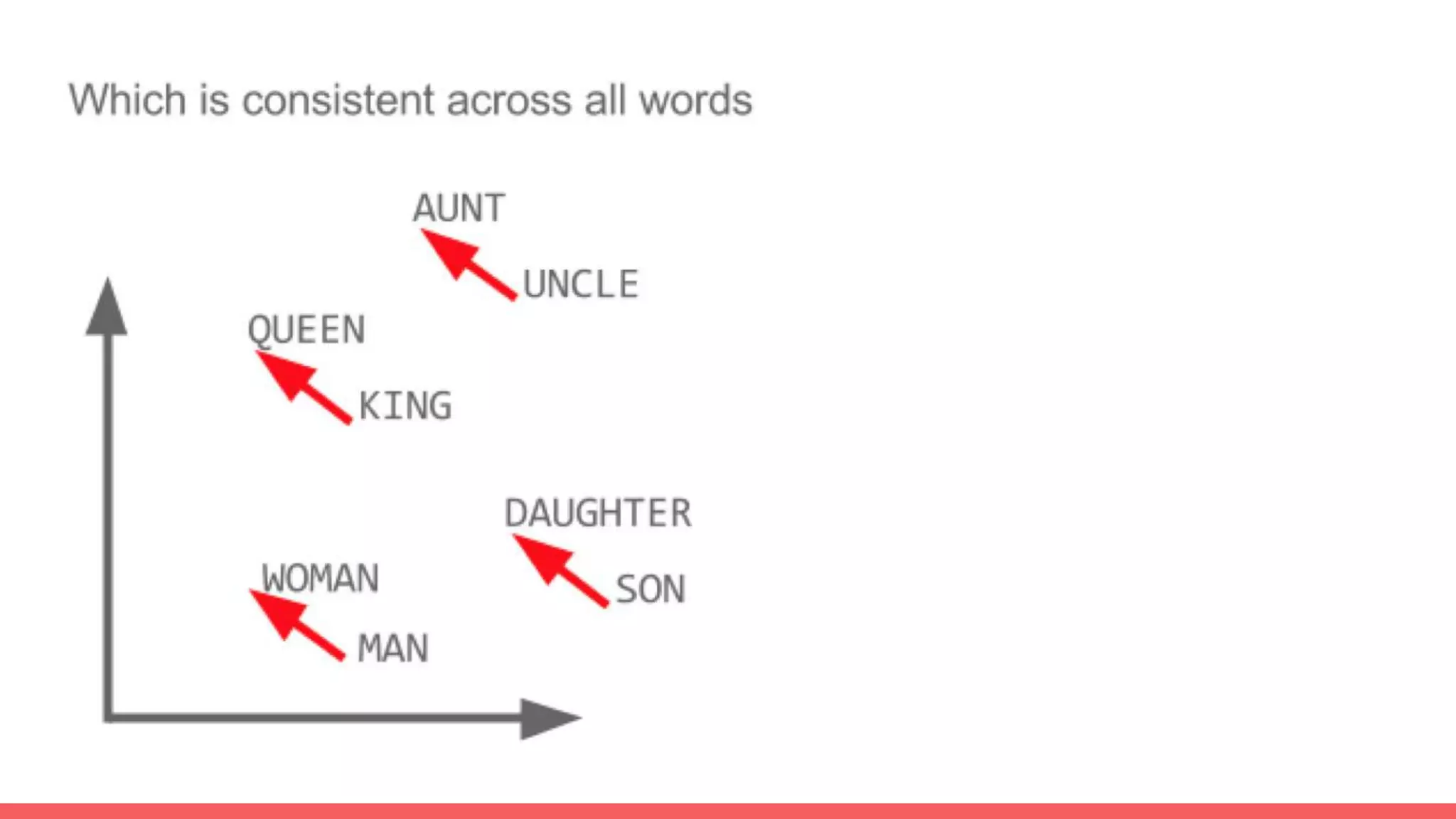
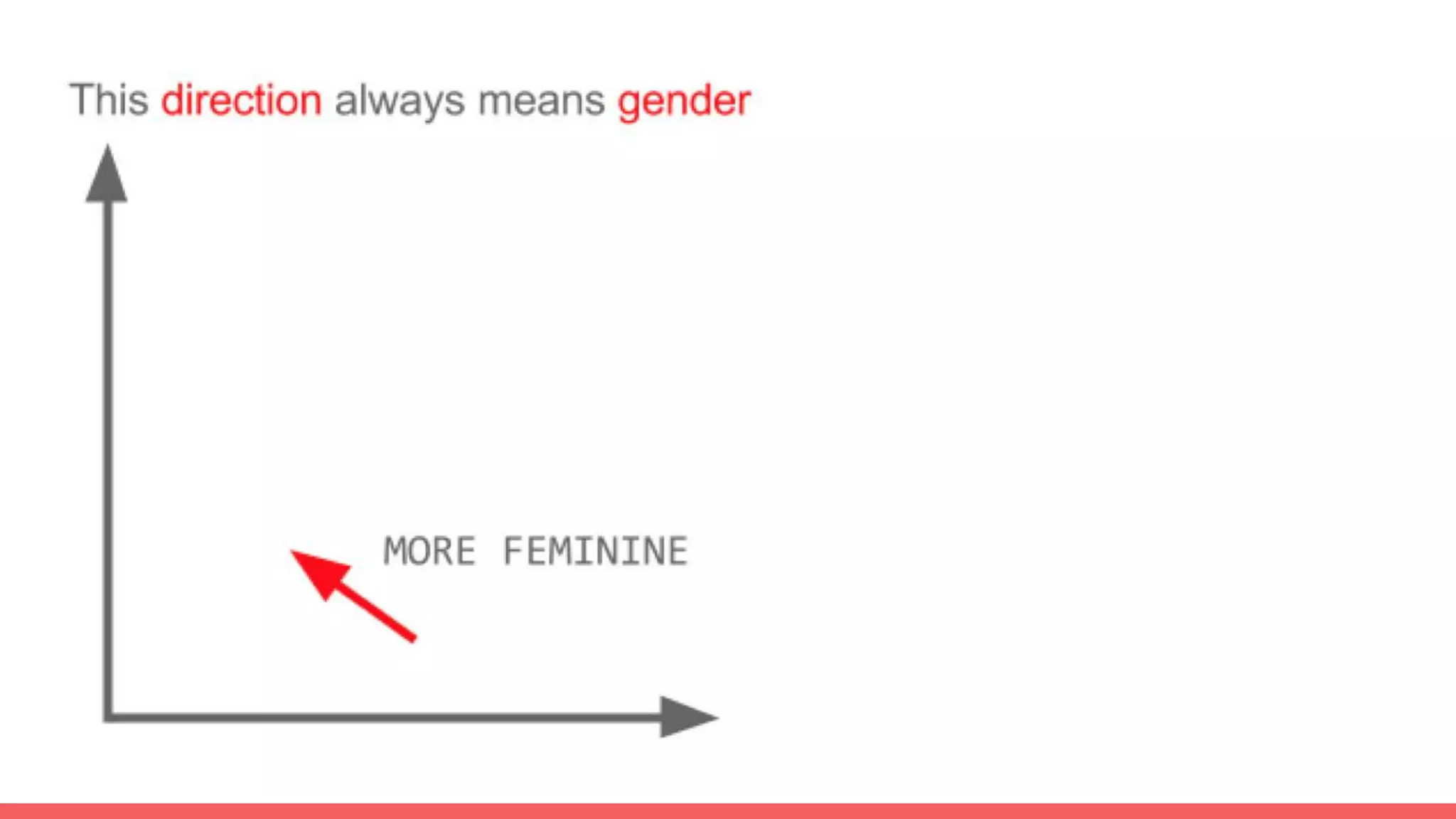
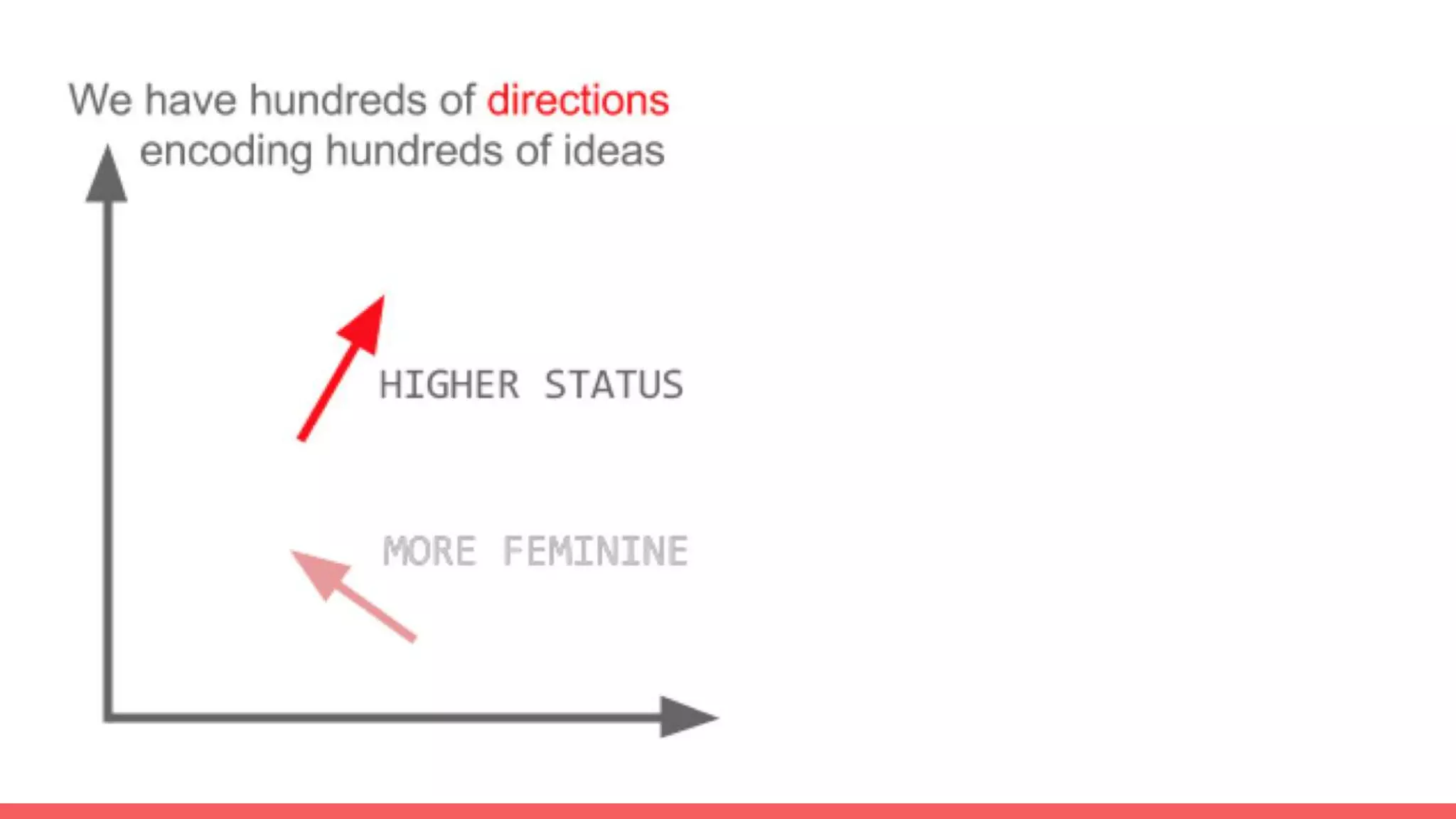
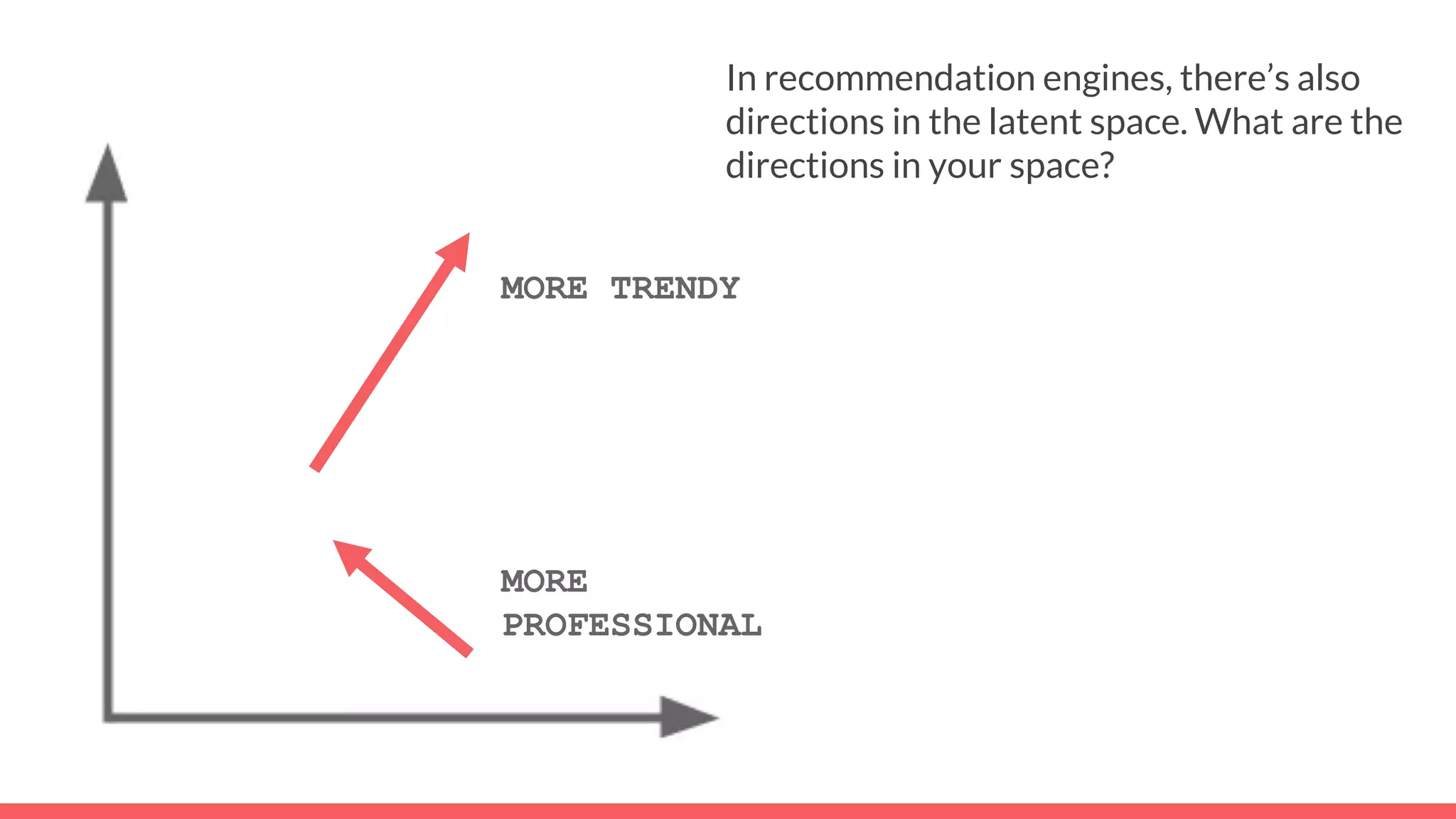



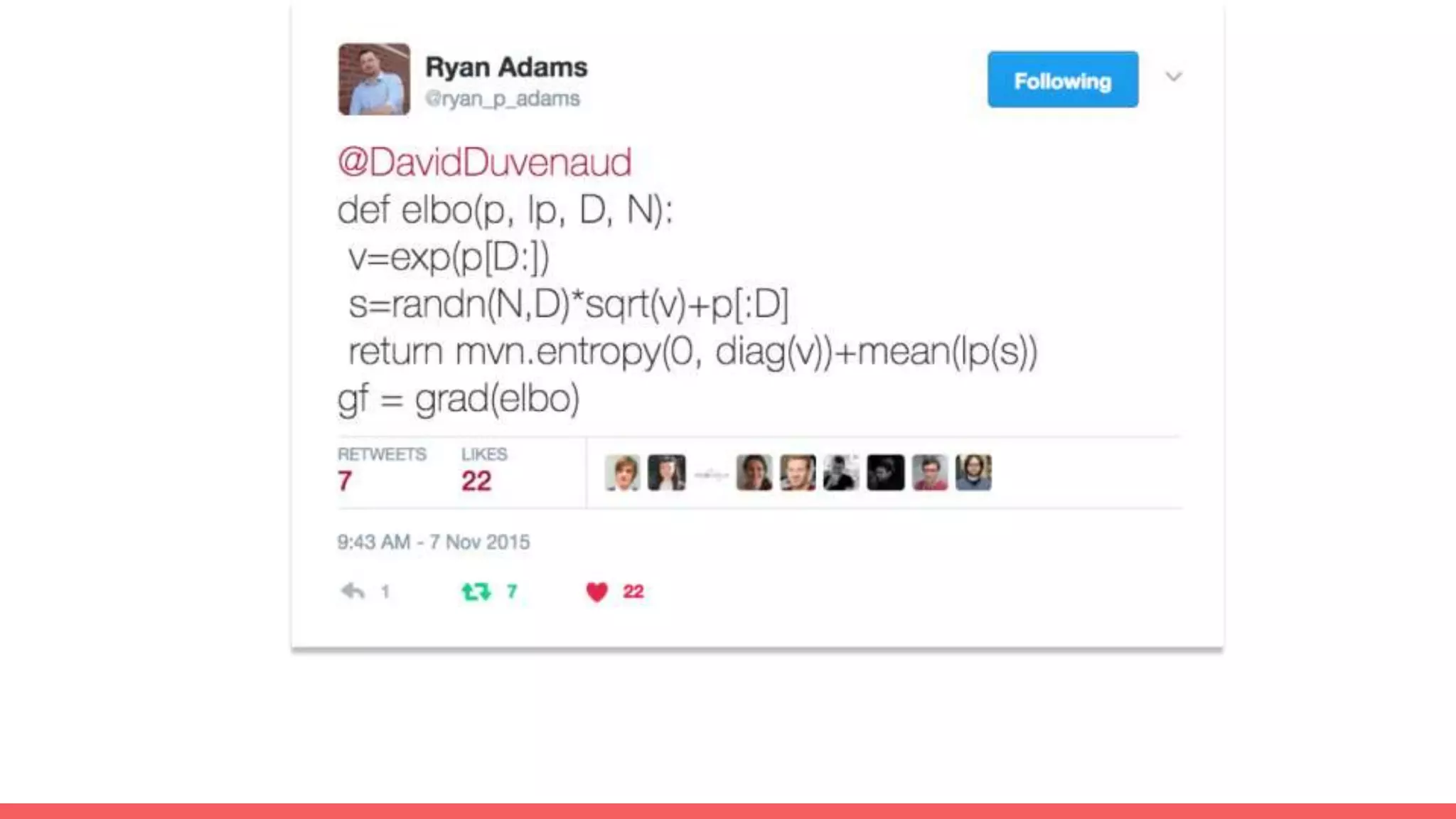
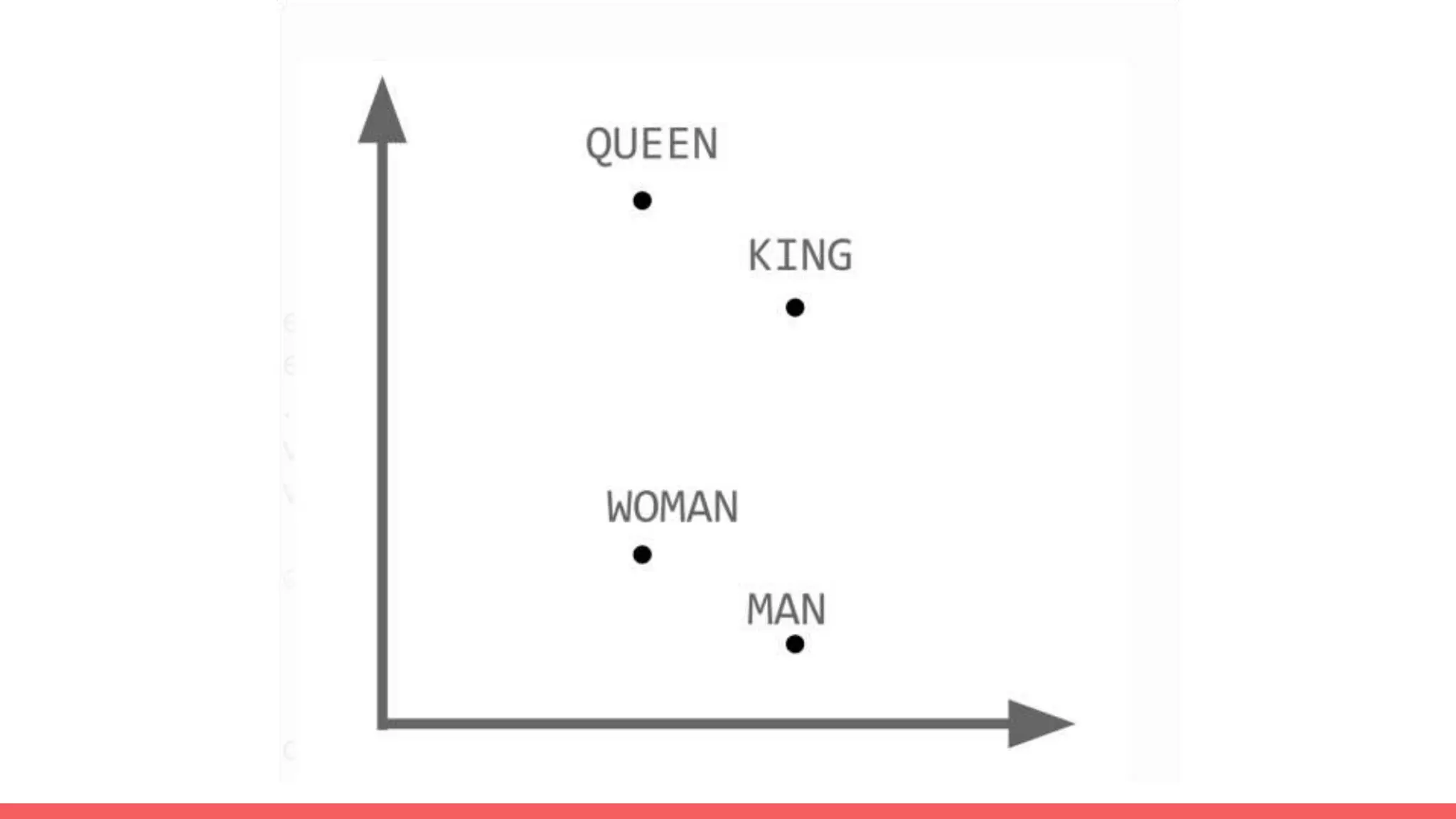
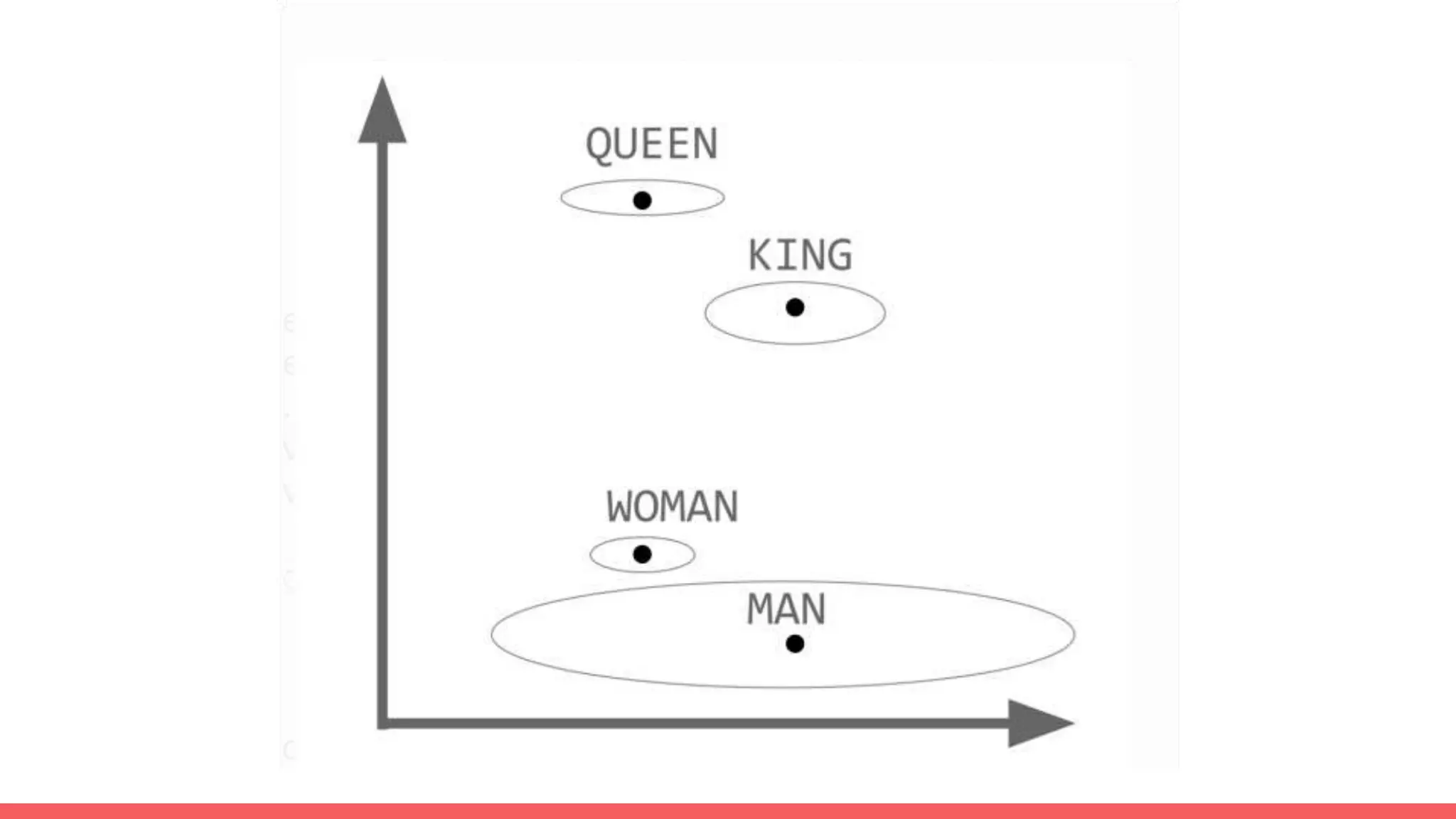
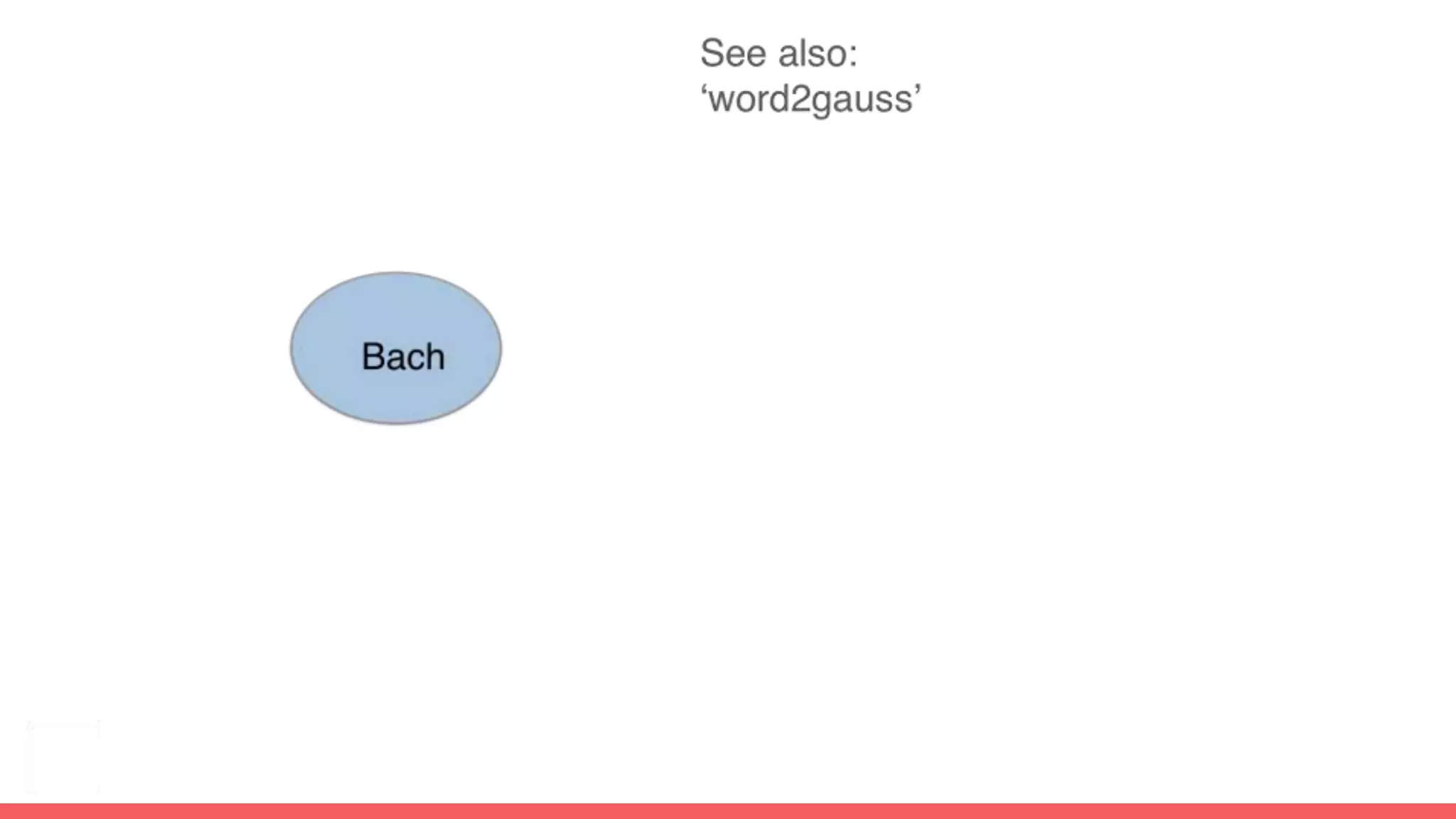
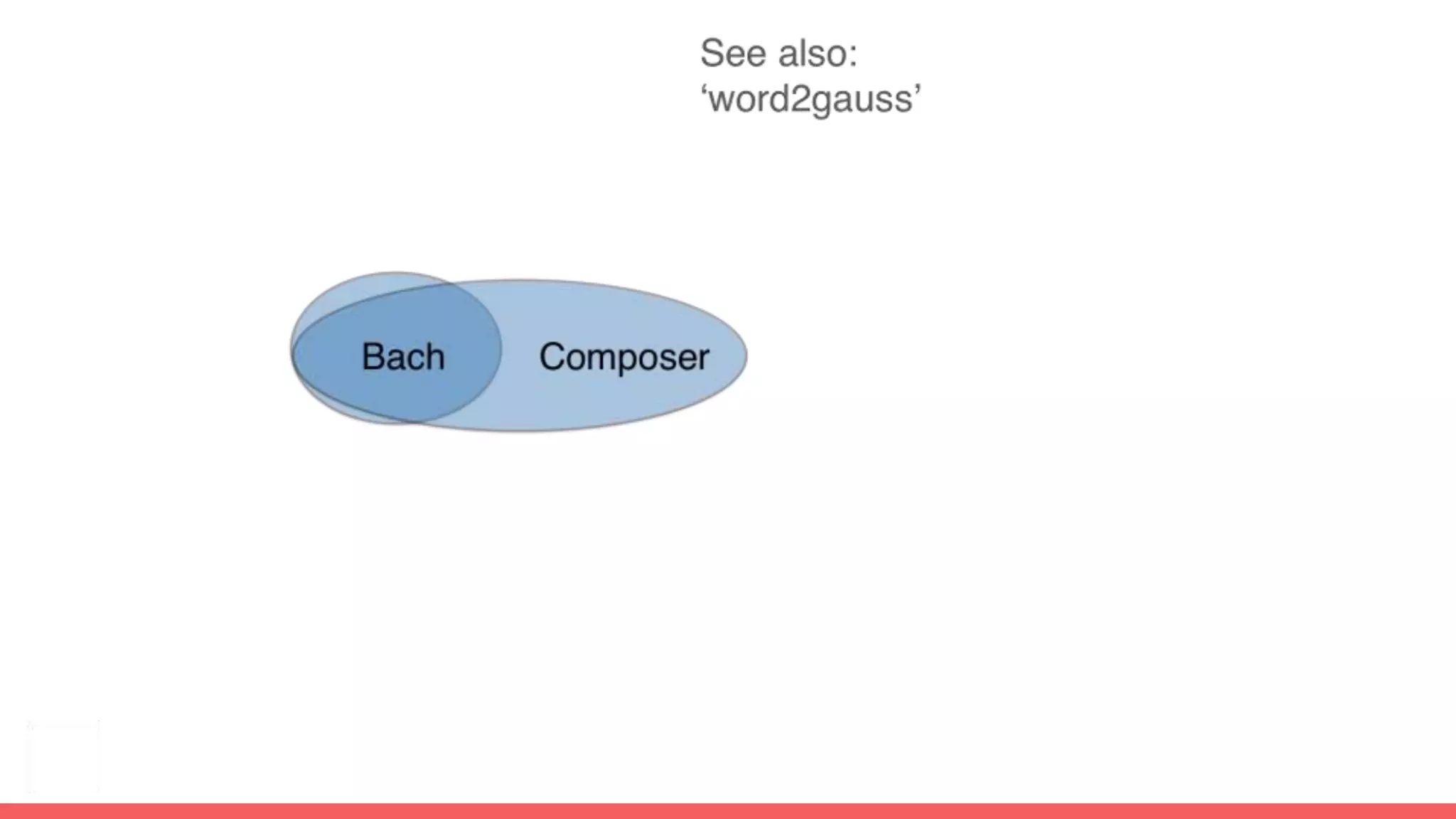
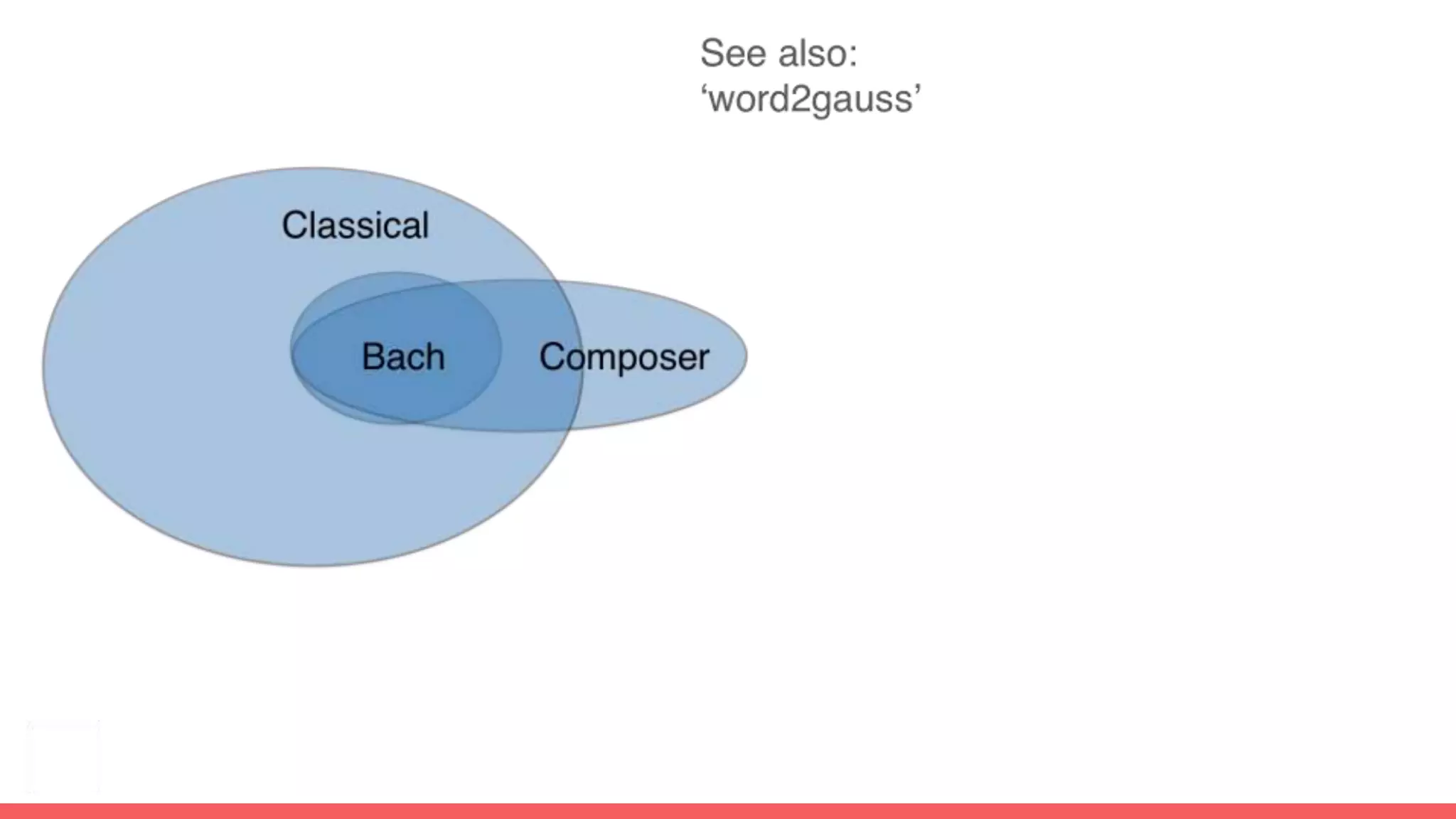
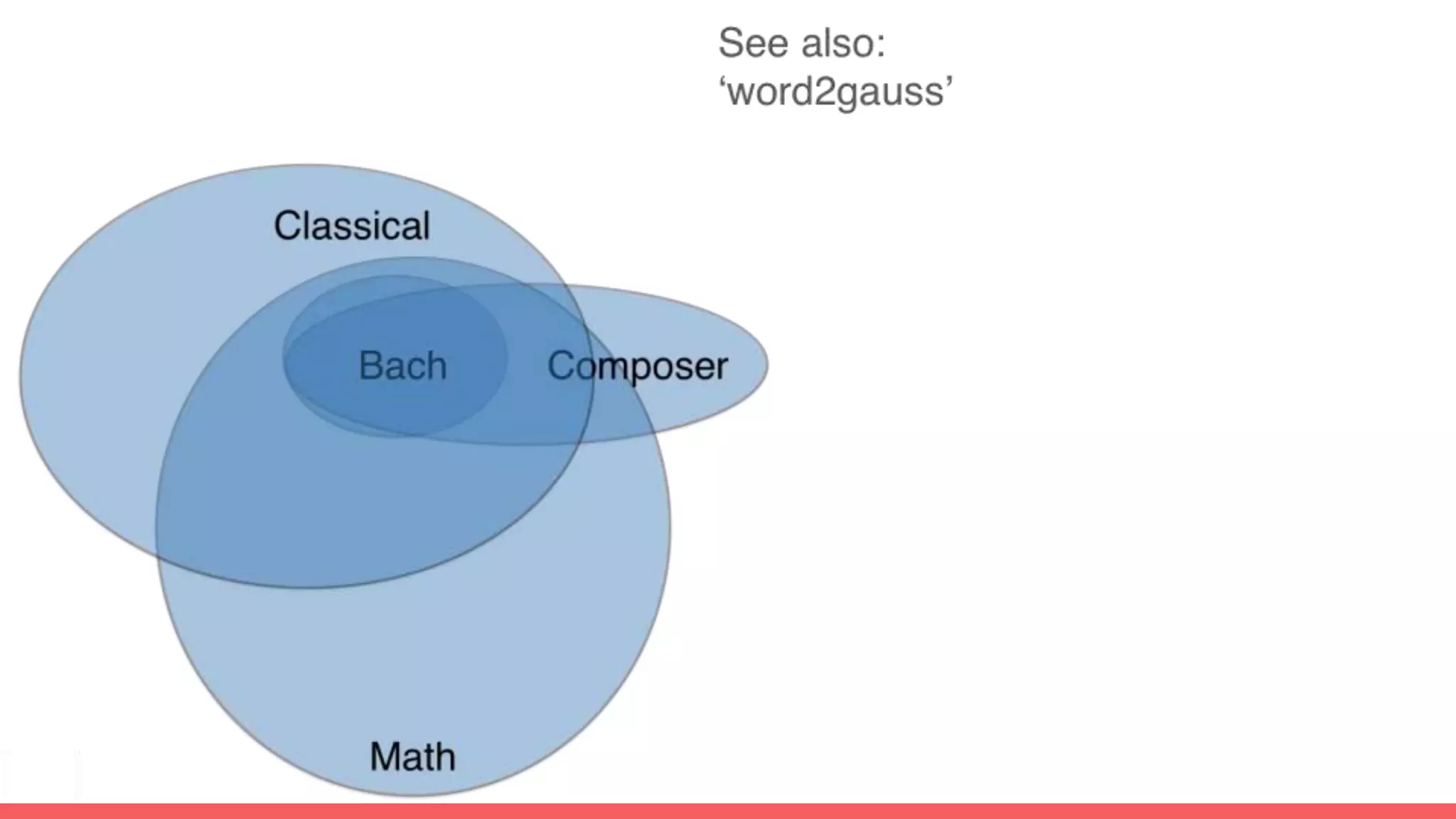









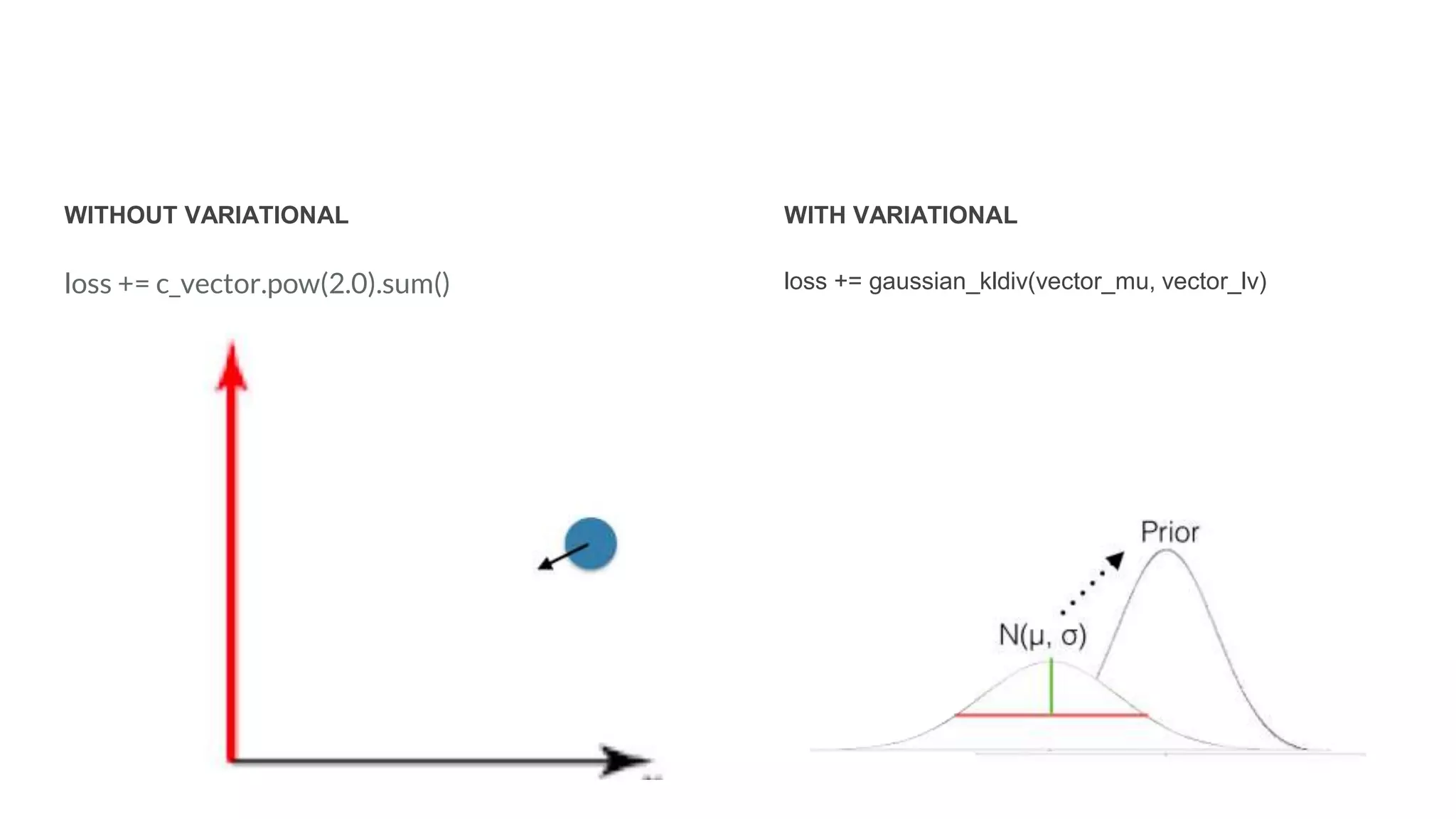









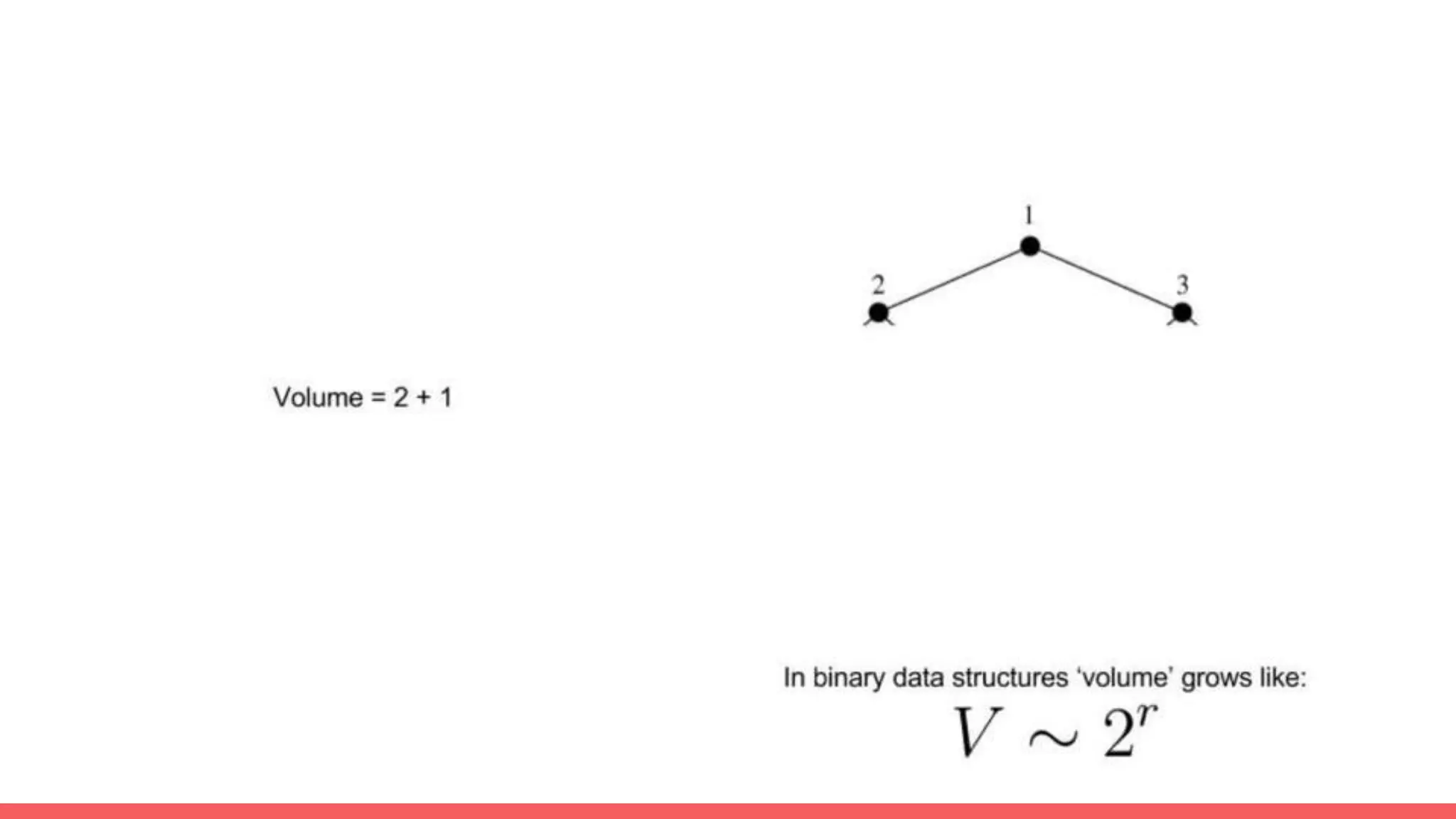
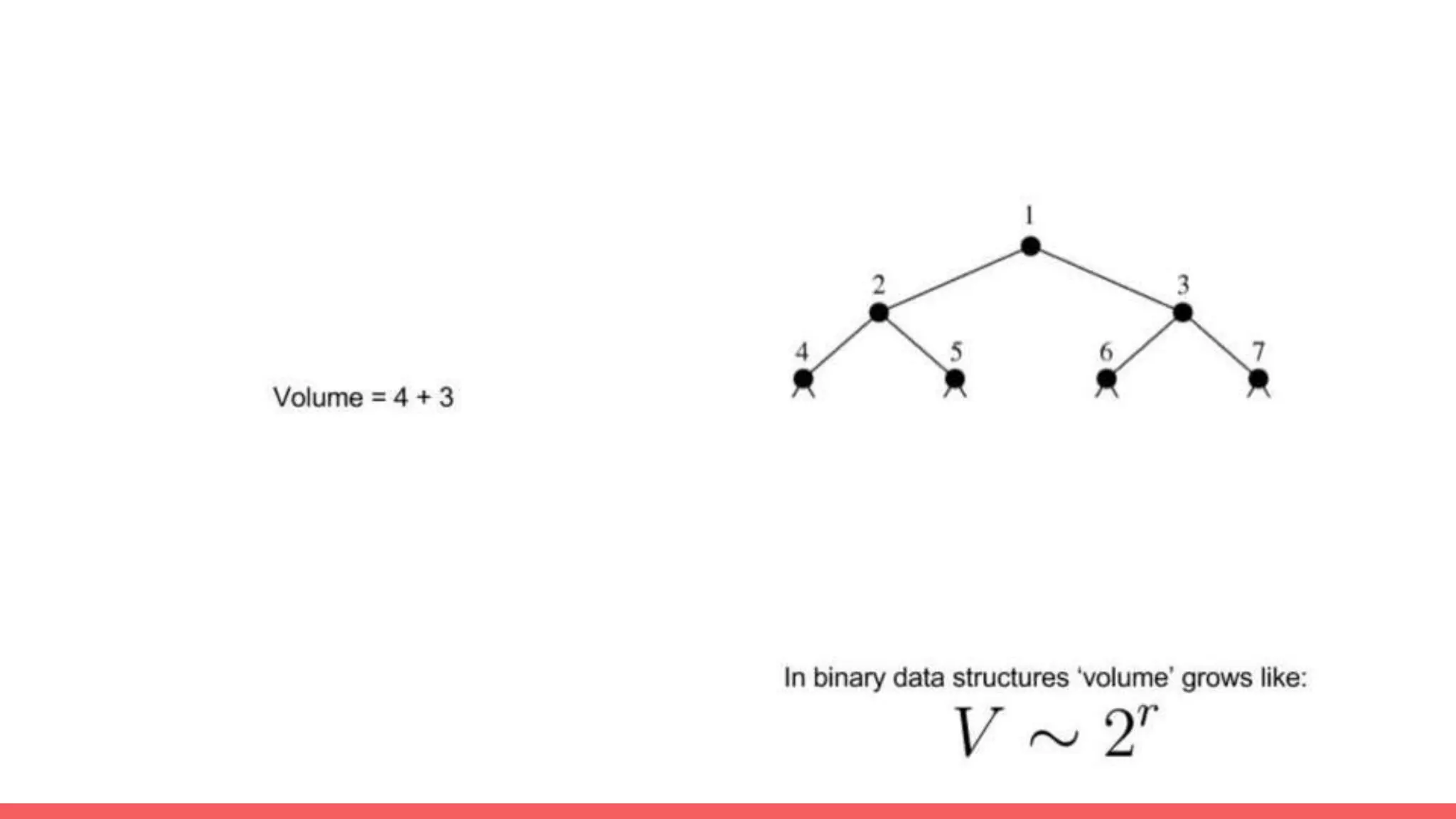
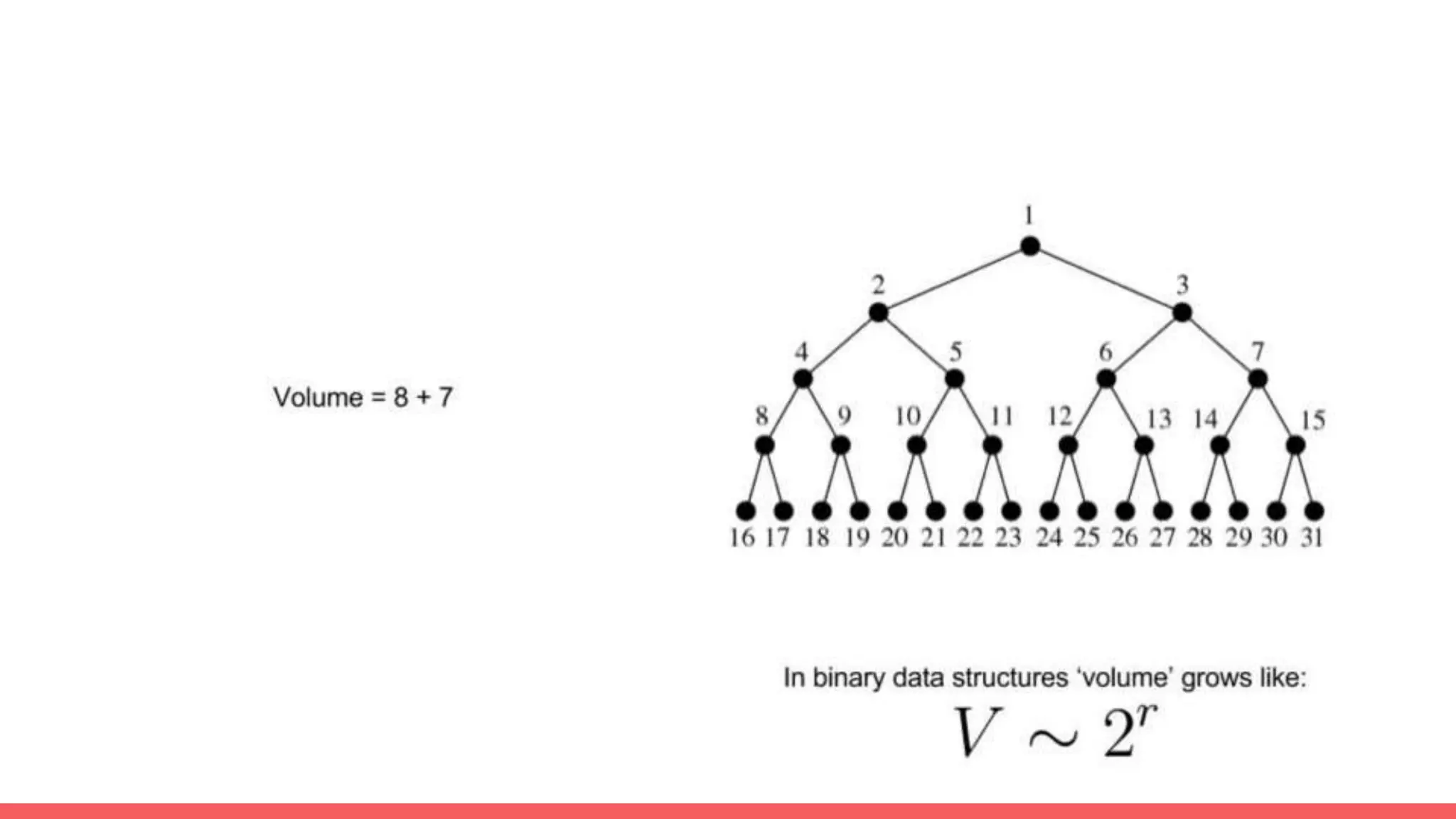
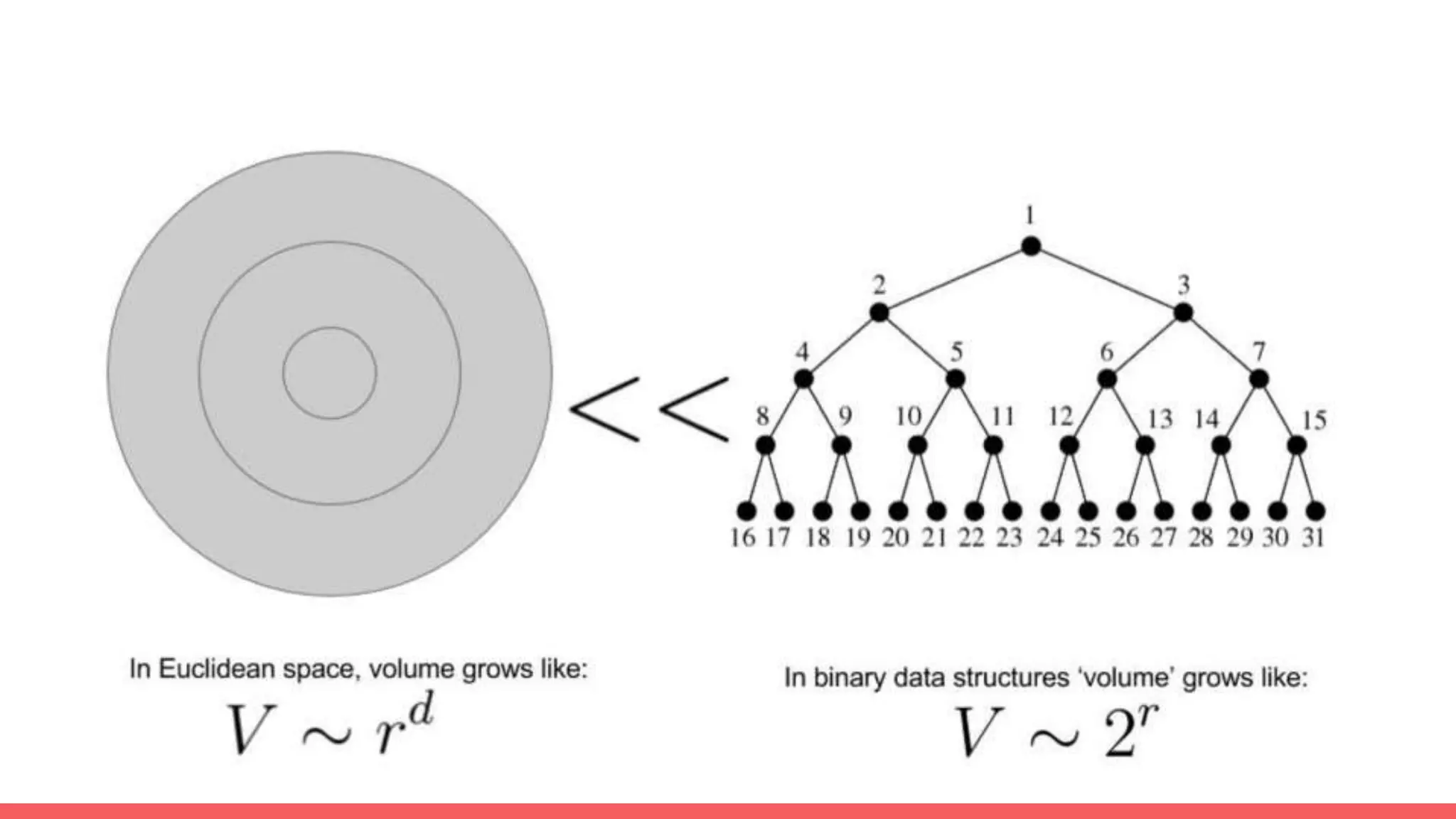
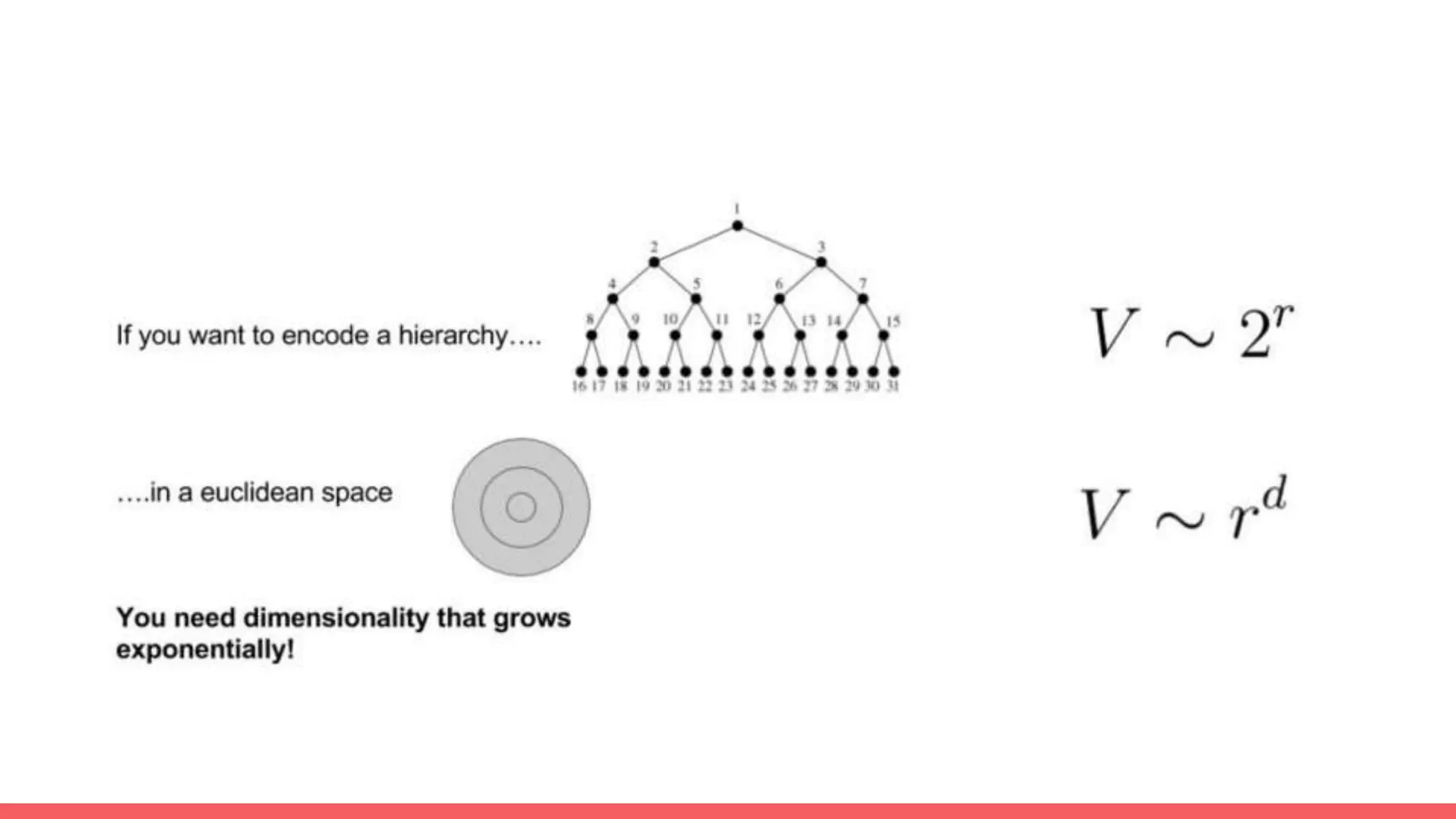
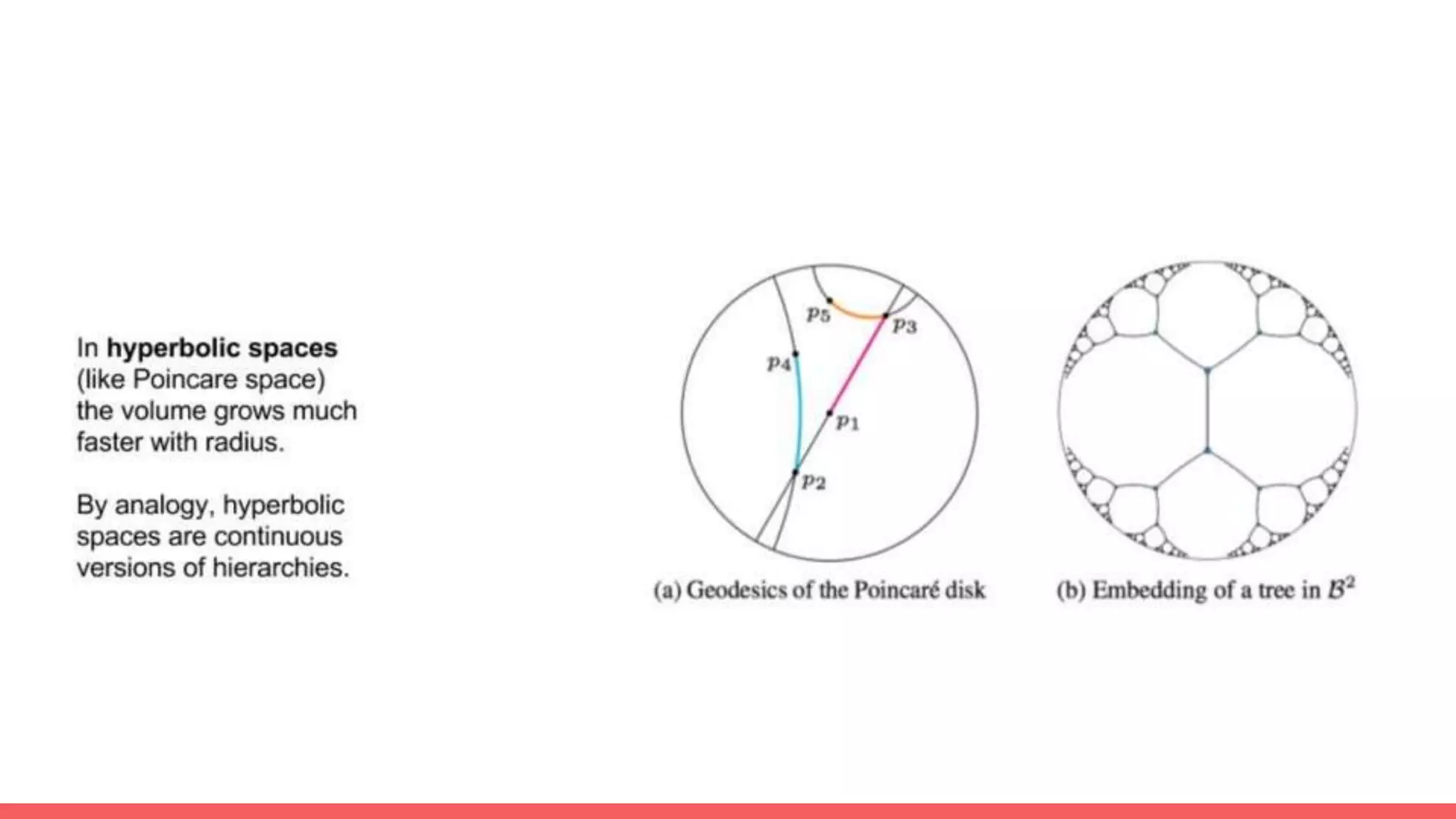
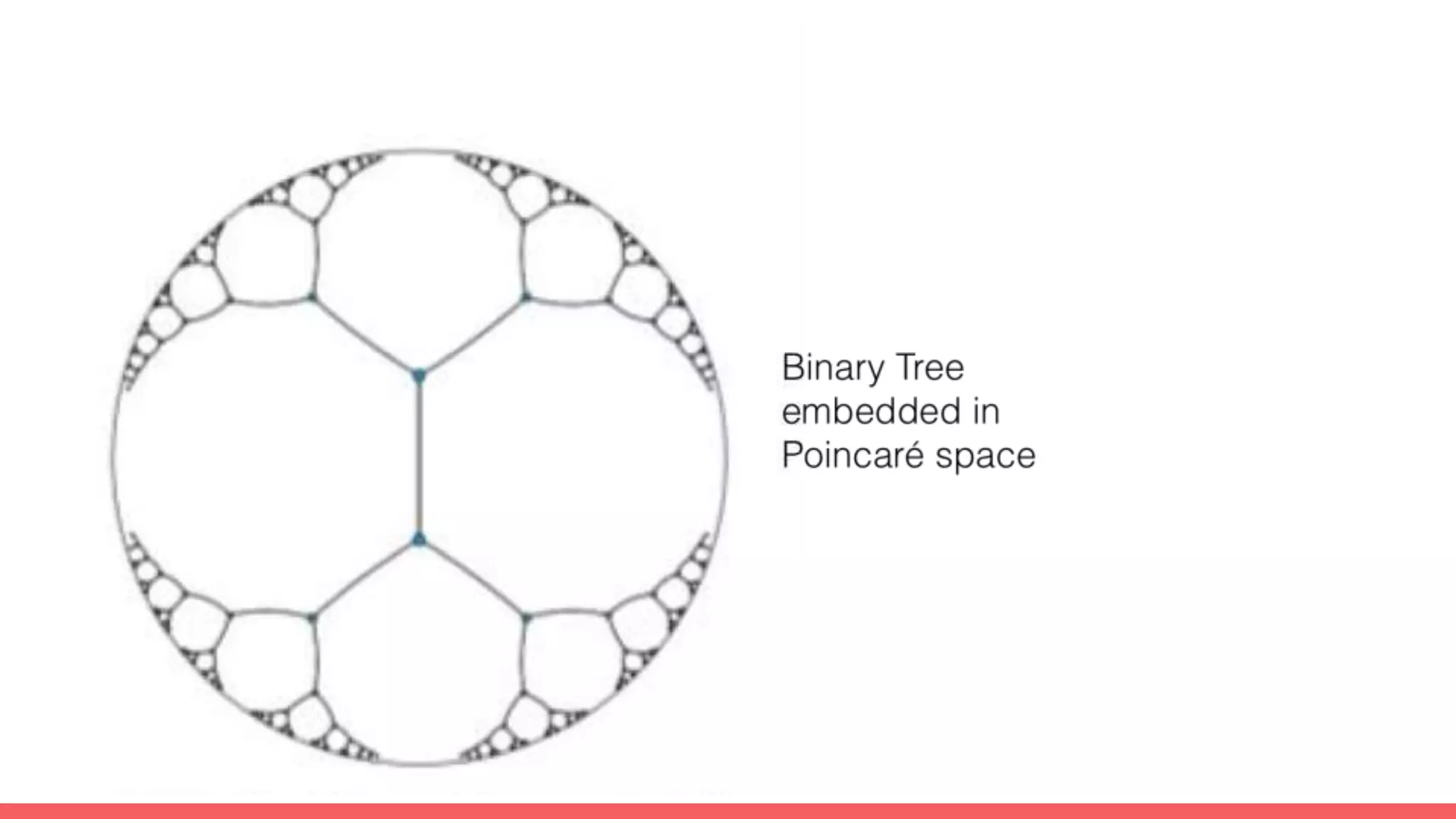
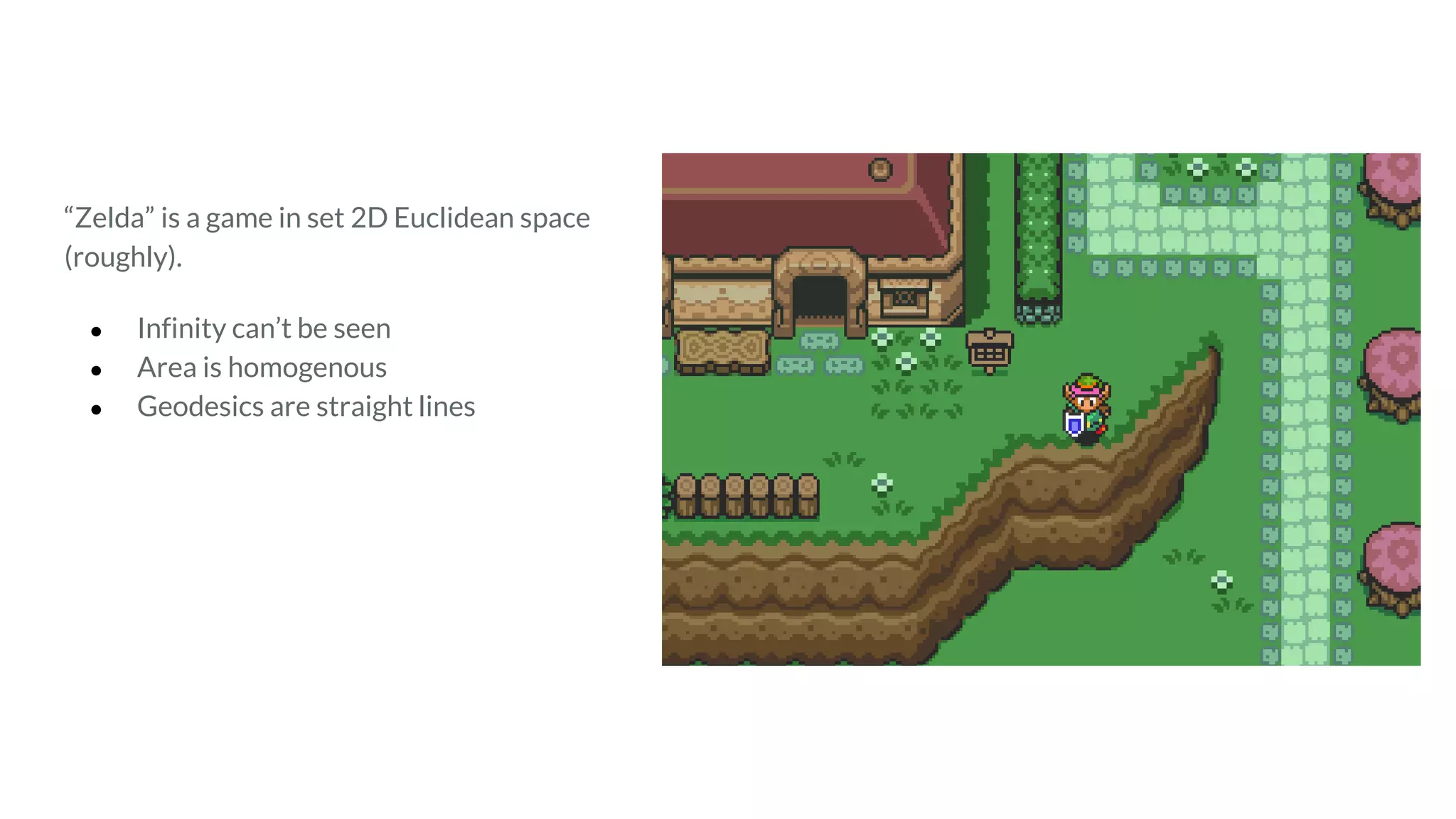

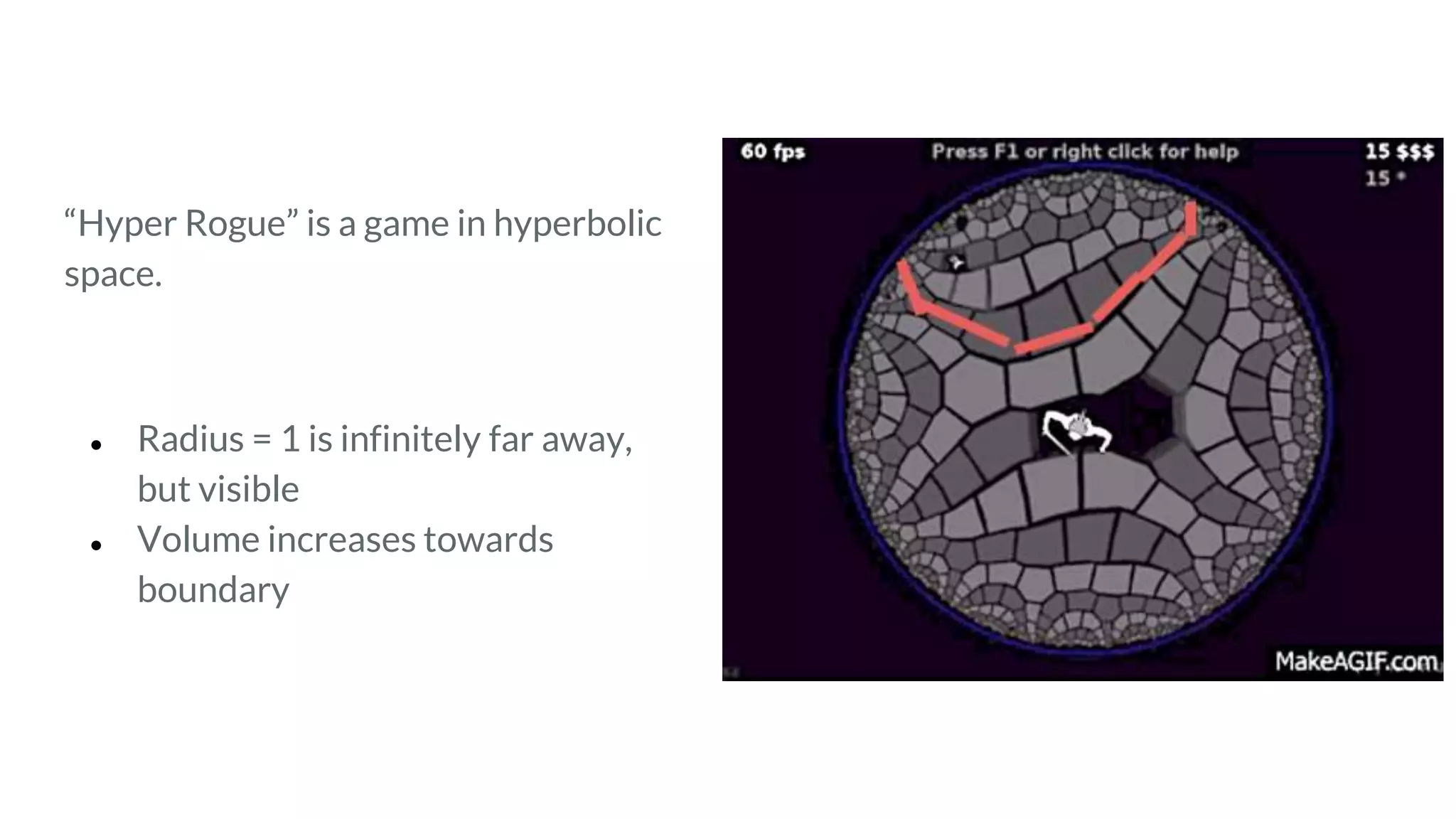



The document discusses recommendations and matrix factorization models in PyTorch. It begins with an introduction and instructions for following along with a tutorial on simple matrix factorization models. It then discusses how matrix factorization works by decomposing a sparse user-item rating matrix into dense user and item embedding matrices. Biases and additional features are also discussed. It notes that recommendation models can be used to understand latent dimensions or "styles" in the data. Further techniques like variational modeling, temporal embeddings, and connections to word2vec are presented. Finally, it discusses directions for future work like factorization machines, mixture of tastes models, and non-Euclidean embedding spaces.

























































