Download as PDF, PPTX





































The document discusses the development of a music recommender system using the Beep Tunes dataset, outlining various approaches such as collaborative filtering and content-based filtering. It emphasizes the importance of user and item profiling, data analysis, and different model evaluation techniques including mean absolute error. The system's evaluation demonstrated significant improvements in recommendation accuracy by optimizing parameters and incorporating additional data features.
Overview of a presentation on building a Music Recommender System using the Beep Tunes dataset.
Emphasis on the importance of questioning results in data science to ensure thorough analysis.
Introduction to the dataset utilized for building the recommender system: BEEPTUNES.COM.
Different approaches to recommender systems including Manual Curation, Editorial Tagging, and Audio Signals.
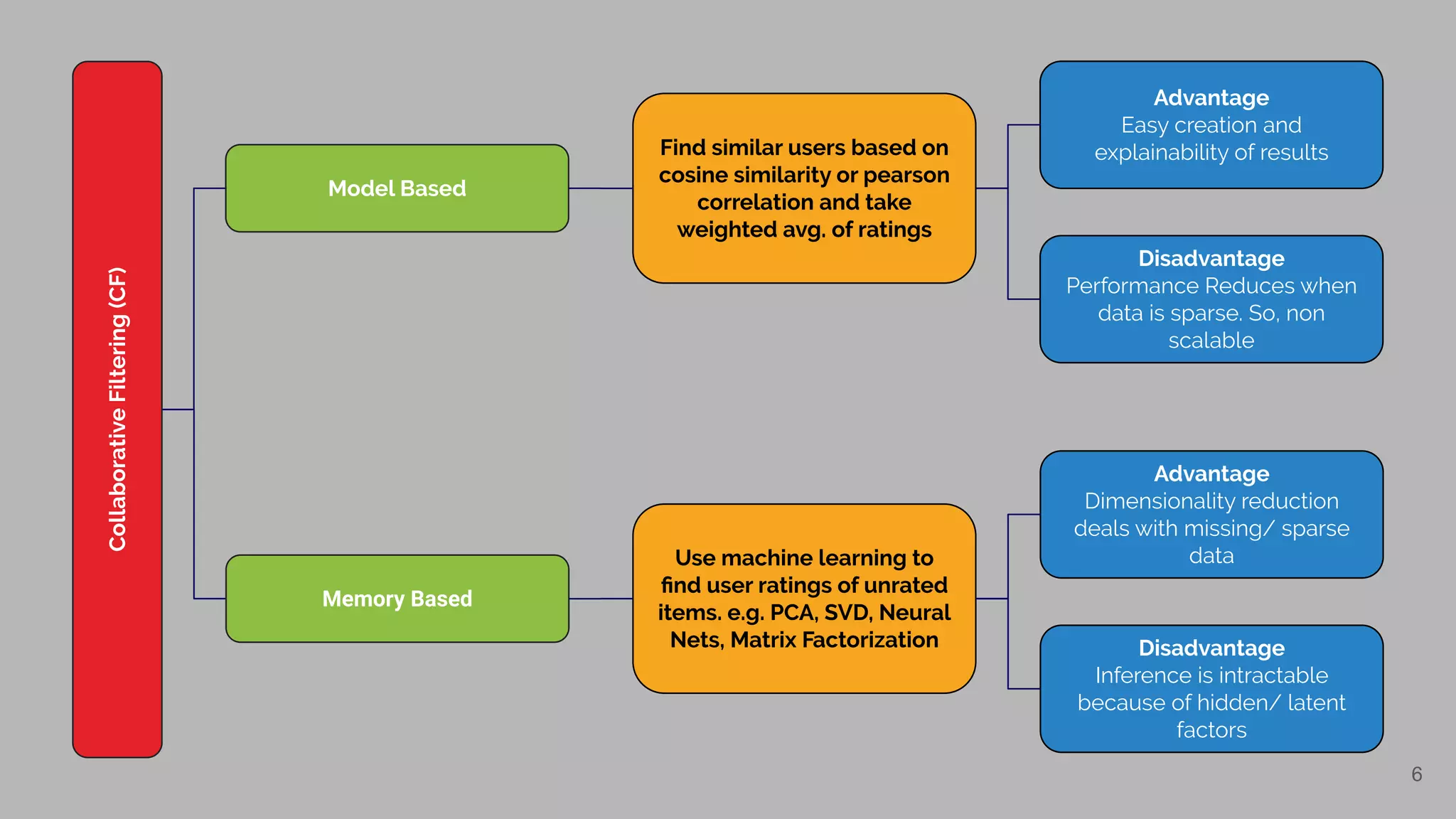
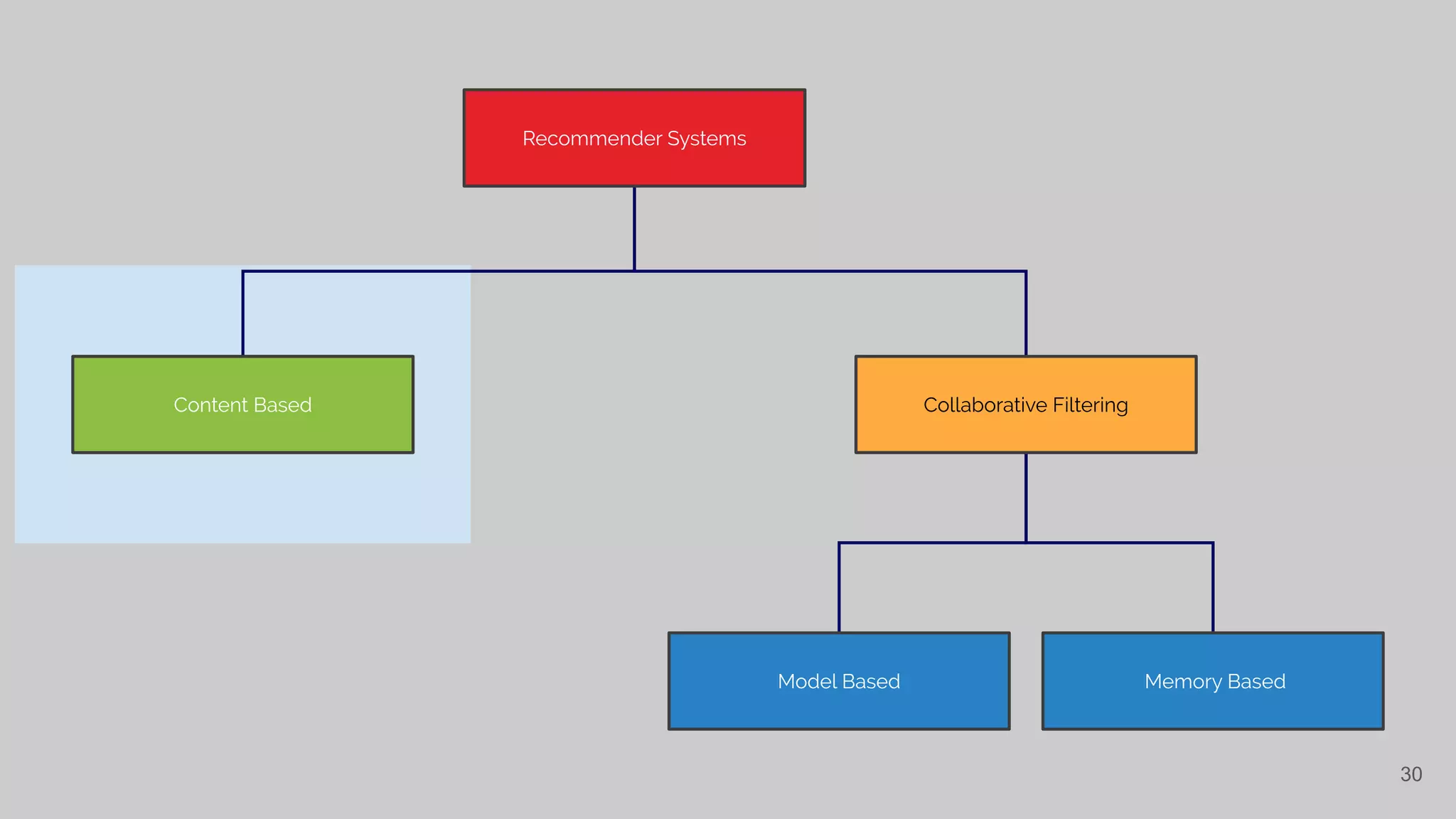
Explanation of Content-Based, Collaborative Filtering, Memory-Based, and Model-Based systems.
Details on collaborative filtering distinguishing between memory-based and model-based methods with advantages and disadvantages.
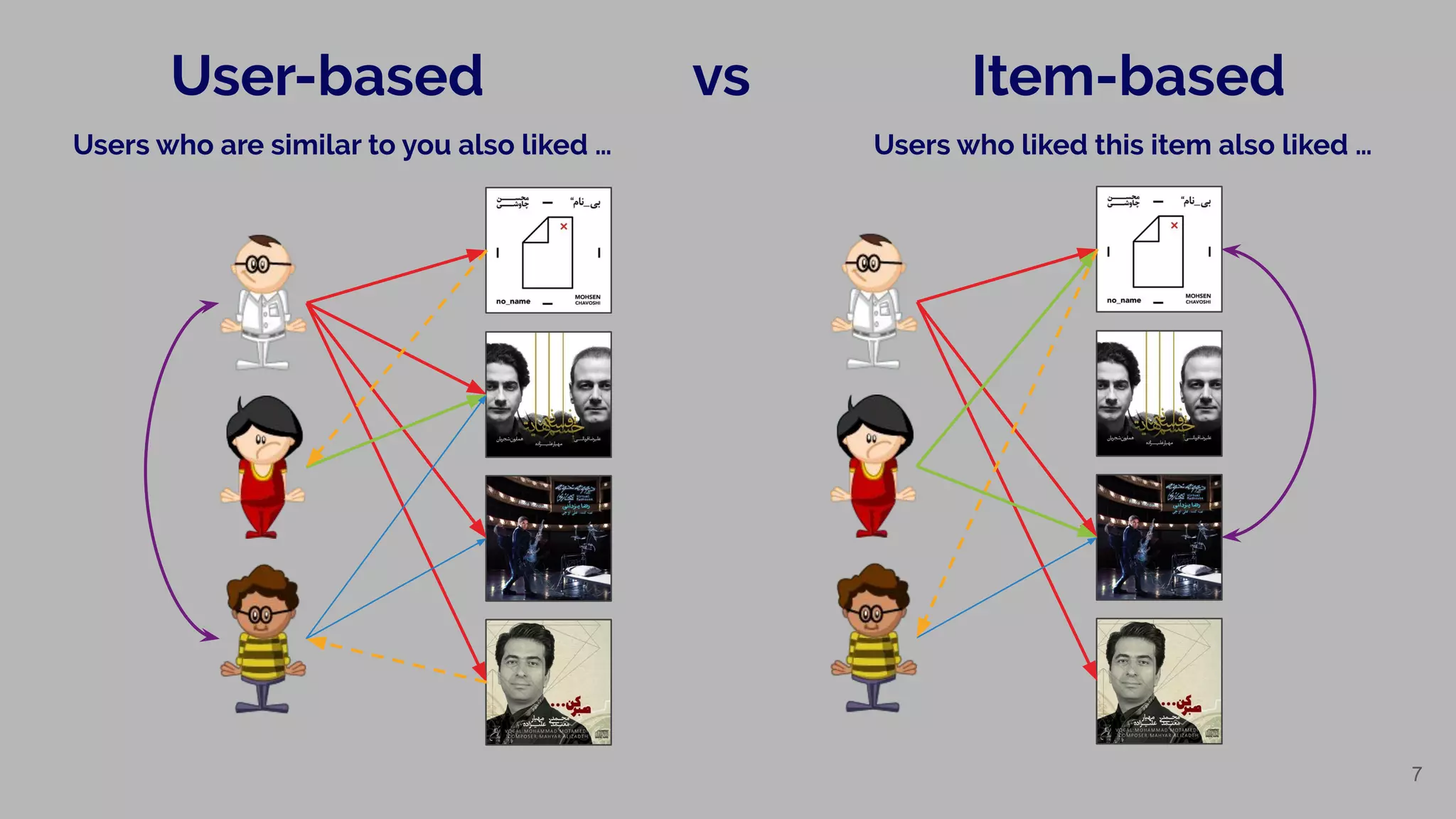
Description of user-based and item-based collaborative filtering approaches.
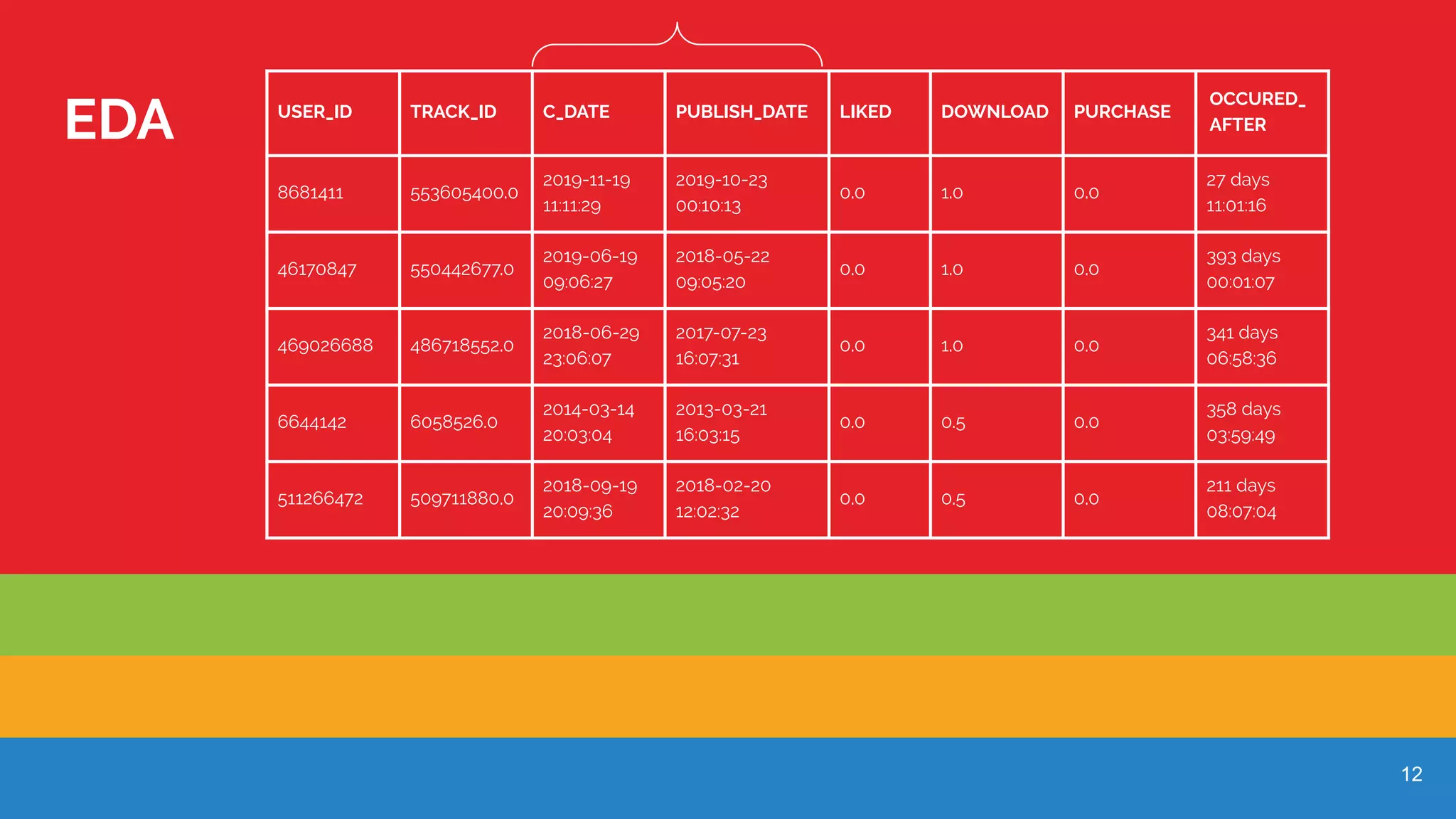
List of datasets used for Exploratory Data Analysis, relevant to the recommender system.
Analysis of user interactions and their metrics in terms of downloaded tracks, purchased tracks, and likes.
Sample data presentation showing various user actions and timestamps related to track interactions.
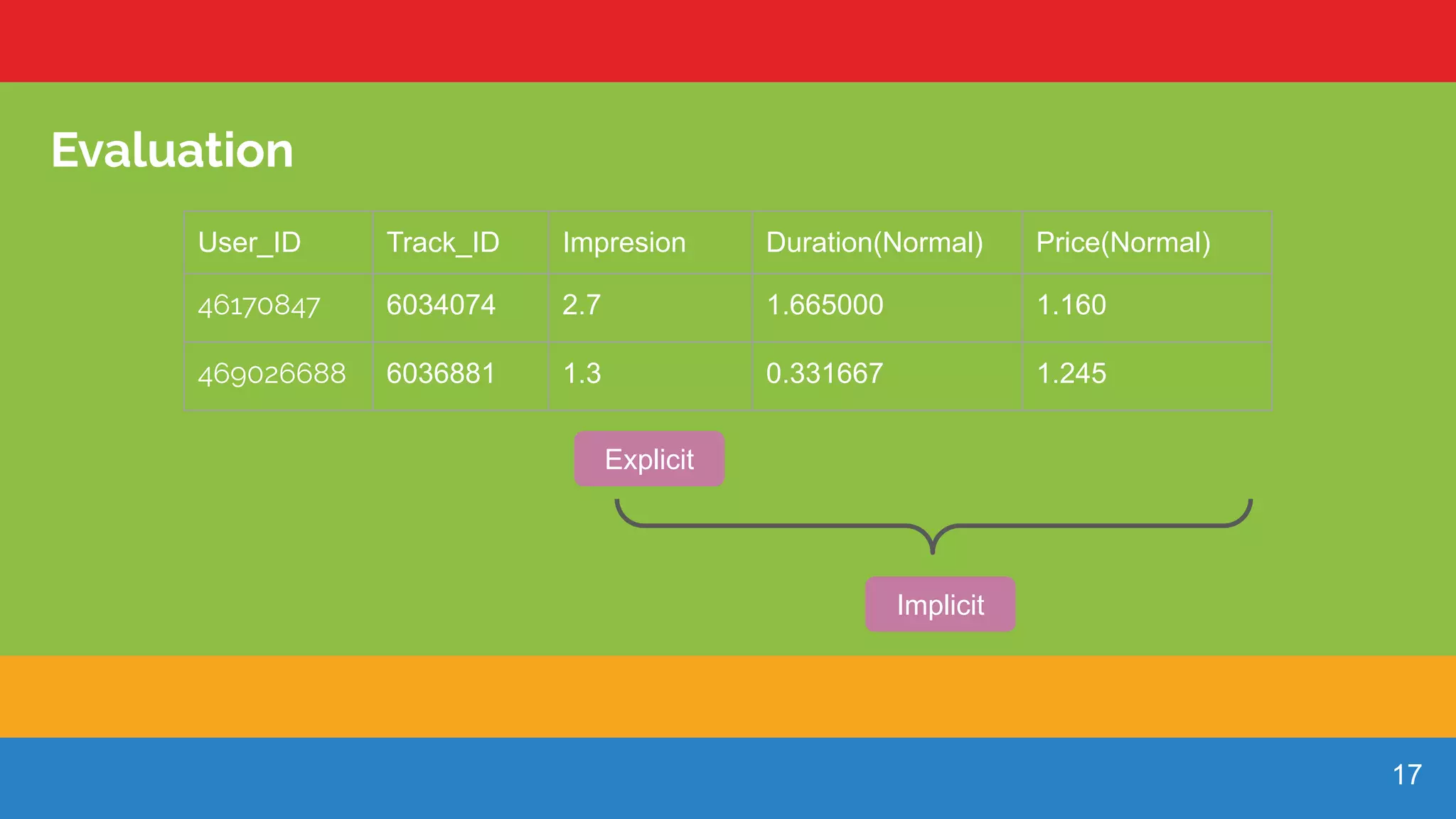
Explanation of how the interaction score (Impression) combines likes, downloads, and purchases.
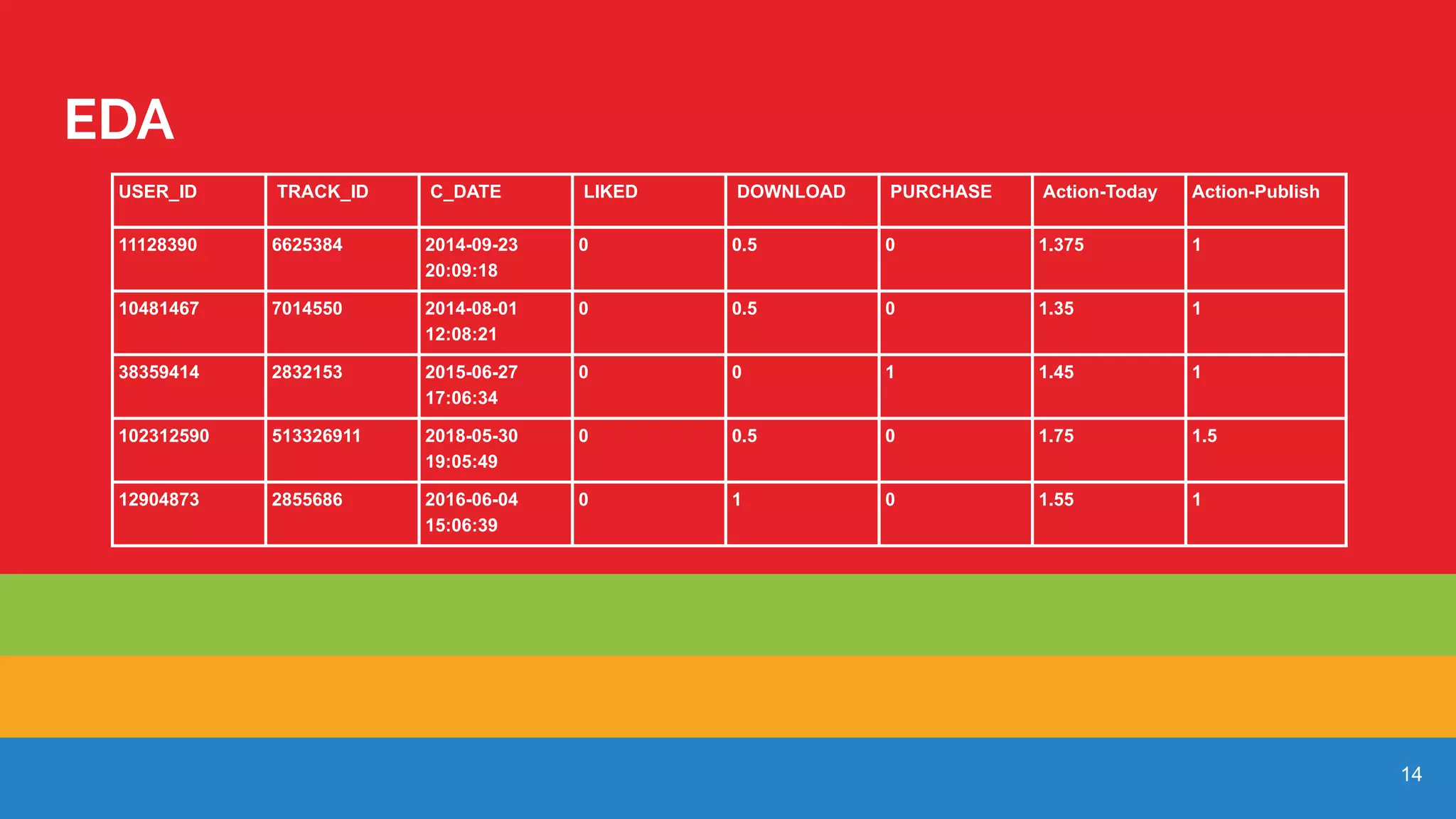
Discusses the time analysis of user actions concerning track publication and user interaction.
Methodology for weighing user actions based on the time of interaction and frequency of actions.
Additional data on user actions, incorporating time parameters for deeper analysis.
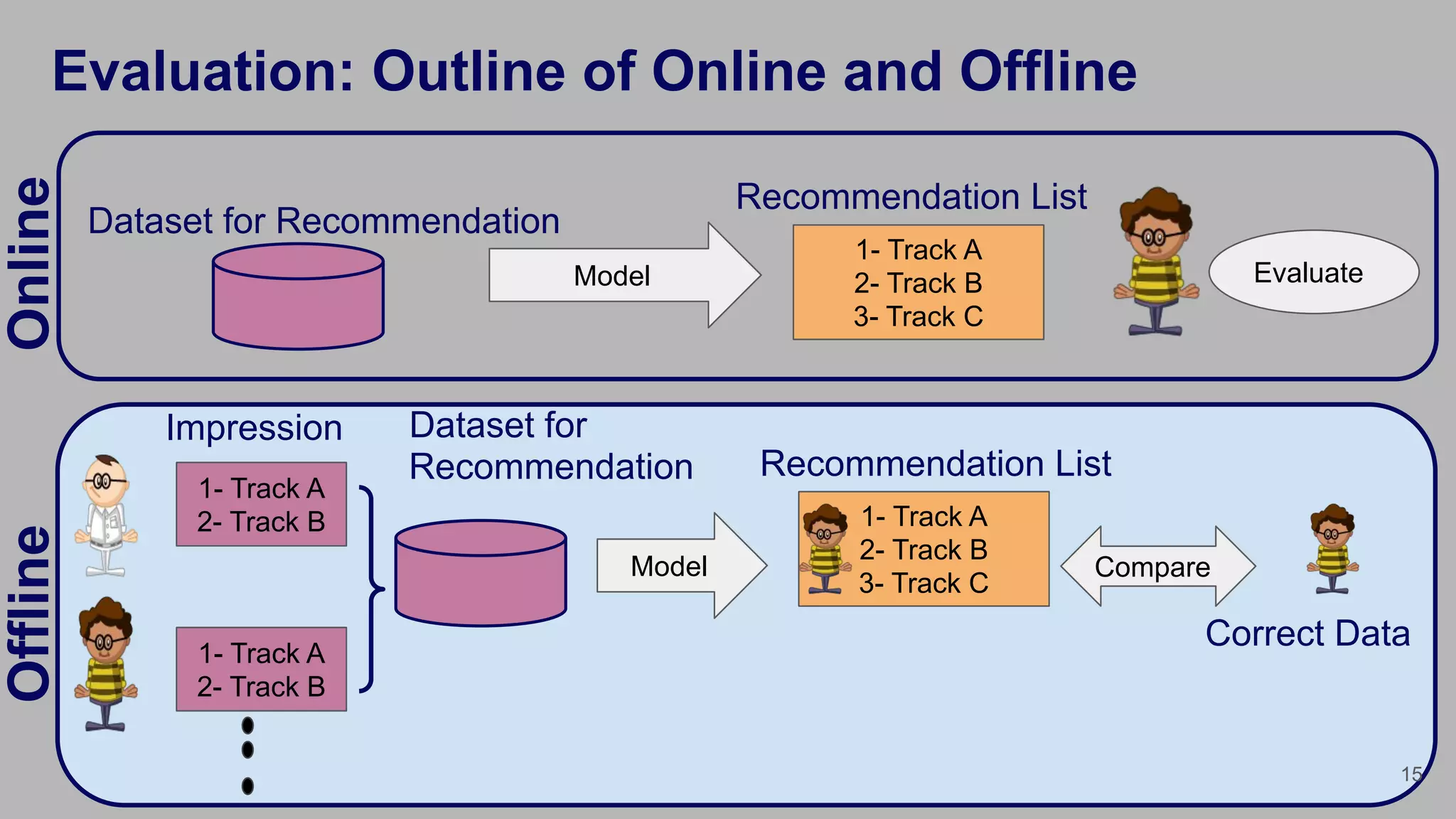
Framework for evaluating recommendations using online and offline evaluation methods.
Explanation of how training and test datasets were derived from a large dataset of user actions.
Metrics showing user interactions with tracks, including their impressions, durations, and pricing.
Introduction to evaluating the model’s performance using Mean Absolute Error on the test dataset.
Focus on the tools and methods used for regression evaluation in the recommender system context.
Describes how correlations are computed between user-item matrices to enhance recommendation quality.
Outlines the tools used in memory-based collaborative filtering, focusing on various ML tasks.
Visualization of user-item interactions showing the matrix factorization approach for recommendations.
Discusses the advantages of using matrix factorization techniques in dimensionality reduction.
Introduction to ALS as a matrix factorization algorithm that enhances computational efficiency.
Describes how ALS solves issues related to the scalability and sparseness of user ratings.
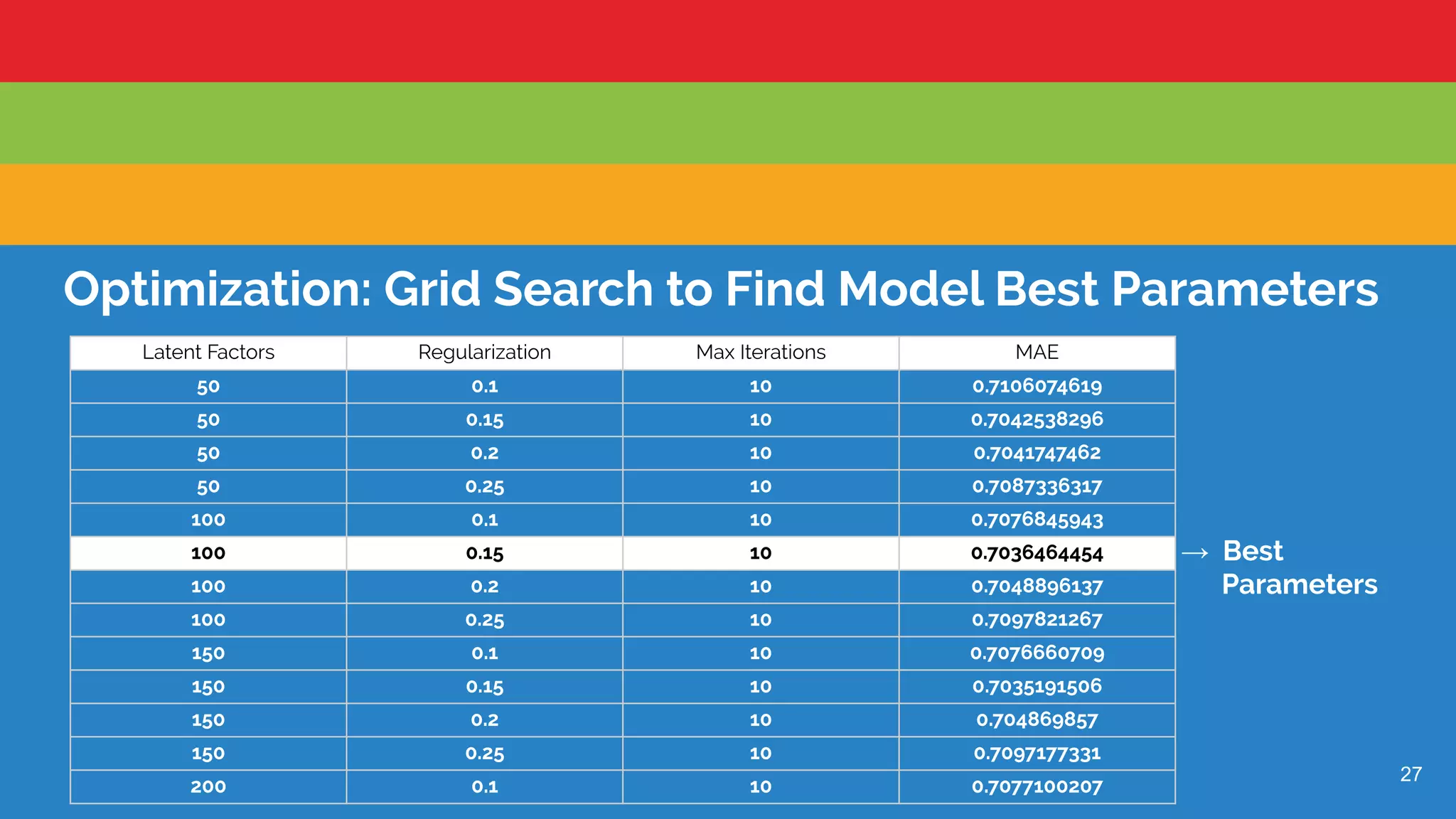
Optimization strategy using a grid search to determine the best parameters for model performance.
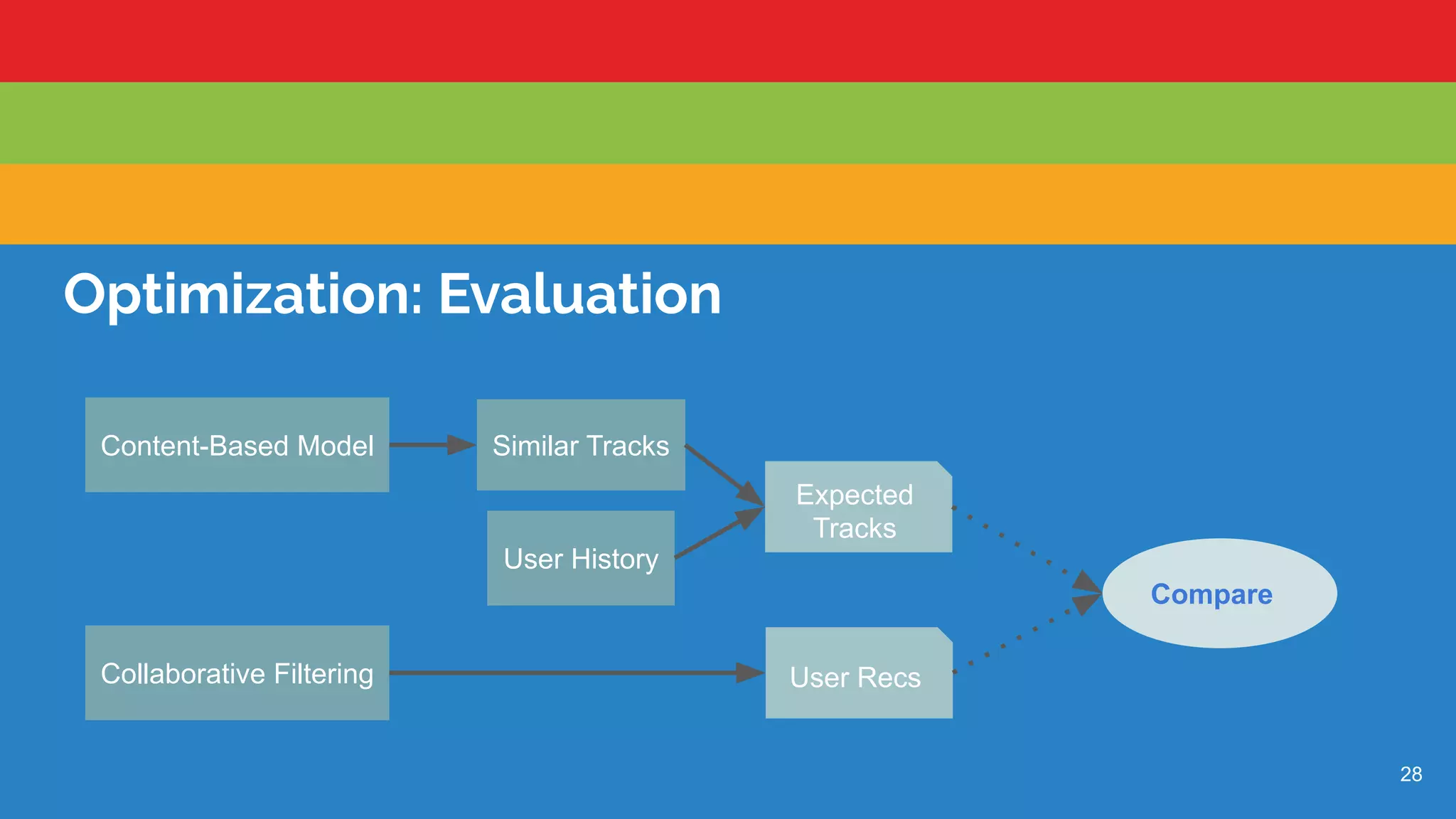
Evaluation comparing content-based and collaborative filtering recommendations.
Summary of the evaluation results showing improvements in user recommendation metrics.
Recap of the different types of recommender systems including collaborative filtering and content-based.
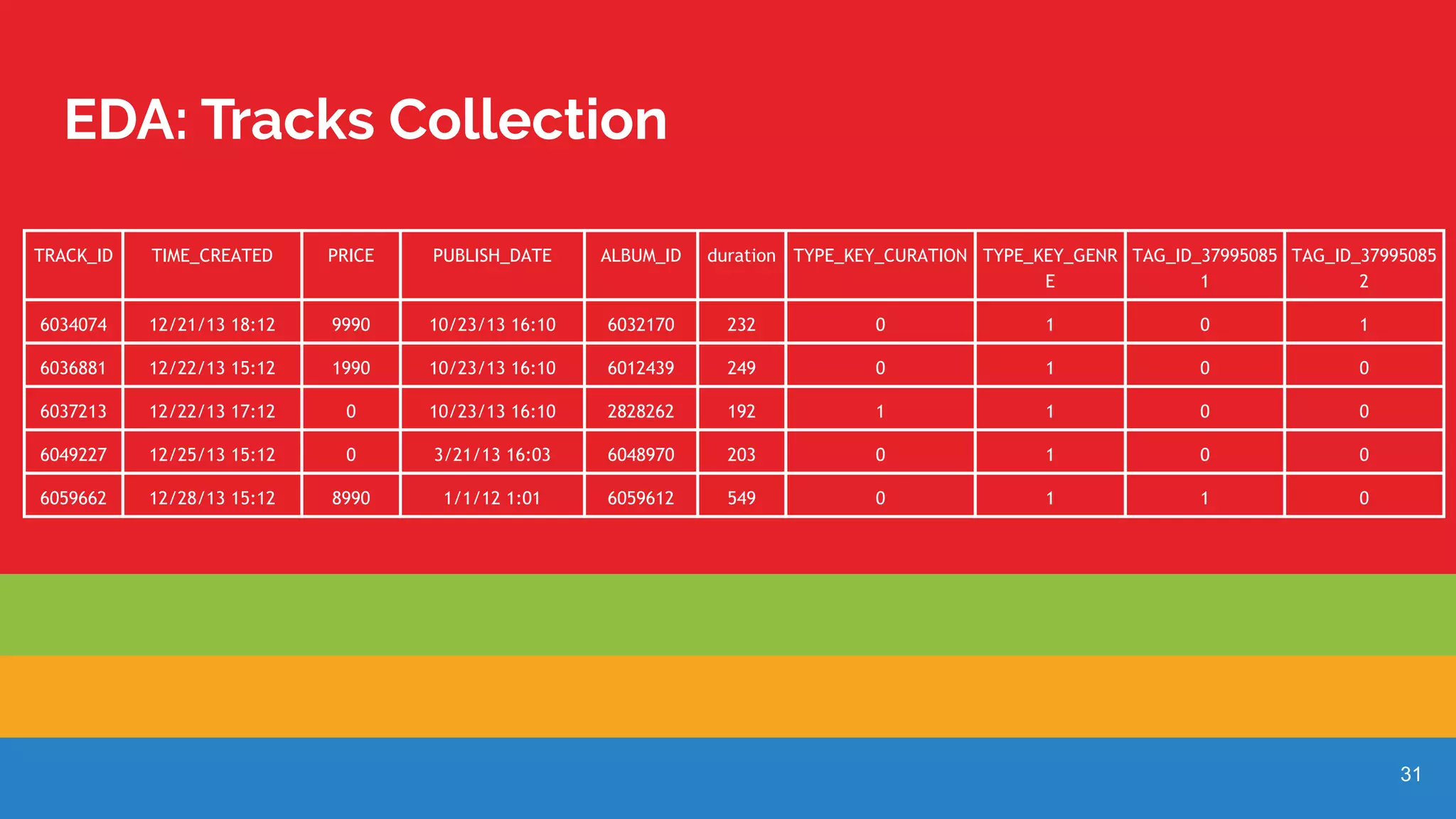
Details of track collection based on various metrics in exploratory data analysis.
Explains how item and user profiles are constructed for content-based filtering.
Describes the creation of item profiles based on the features of each track.
Explanation of how user profiles are calculated based on interactions with weighted item profiles.
Mathematical formulation used in content-based filtering for calculating recommendations.
Advantages of content-based filtering such as recommending unique items to users.
Challenges of content-based filtering including overspecialization and feature identification difficulties.
Presentation of a sample track used for evaluating the recommender system.
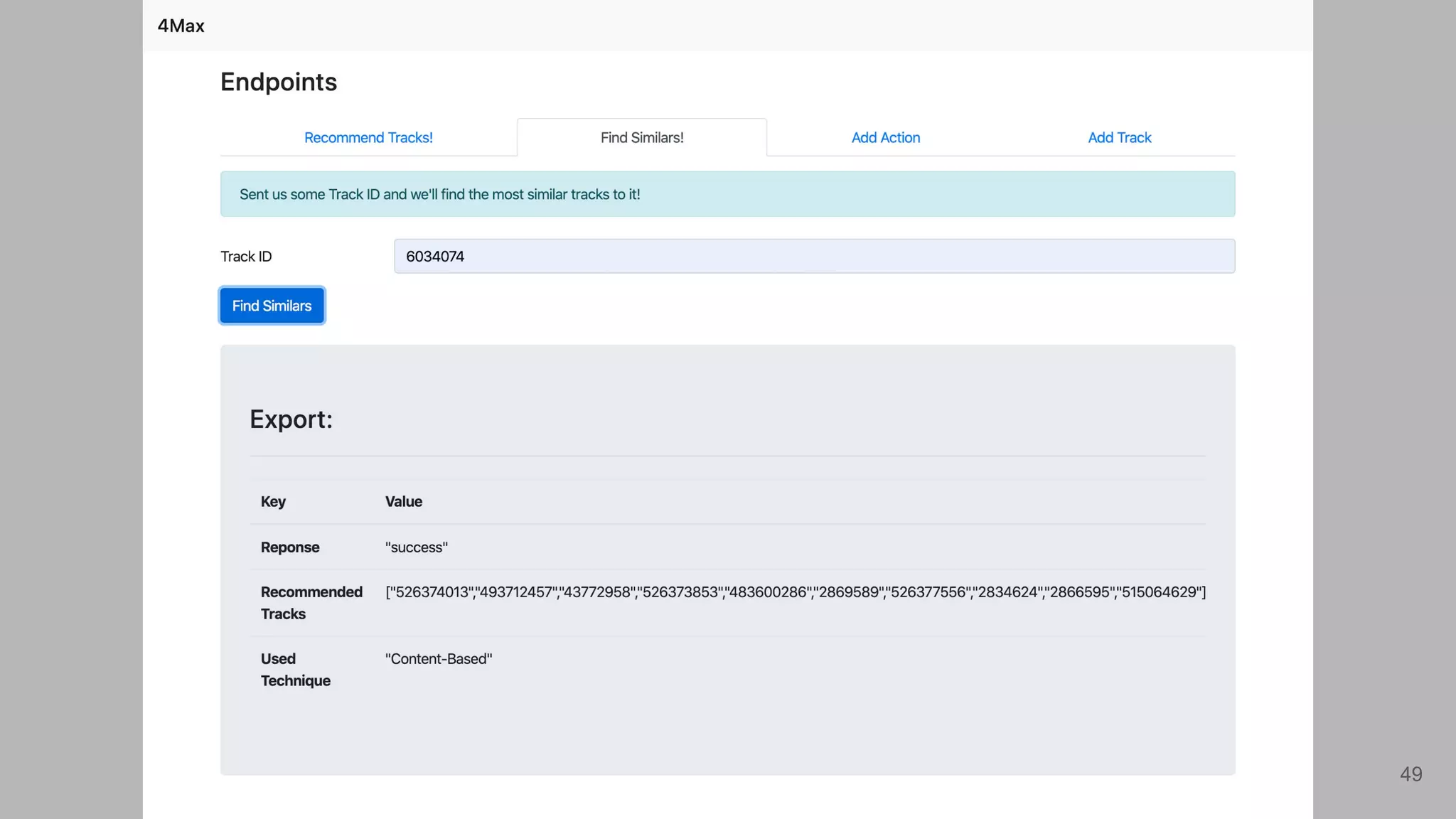
List of tracks found to be similar to the sample track using the content-based filtering model.
Instructions for executing a Spark job relevant to the collaborative filtering model.
Script showcasing how to update track collections for the recommender system.
Overview of scheduled jobs for updating track collections in the system.
Discussion on the cold start problem and its impact on recommender systems.
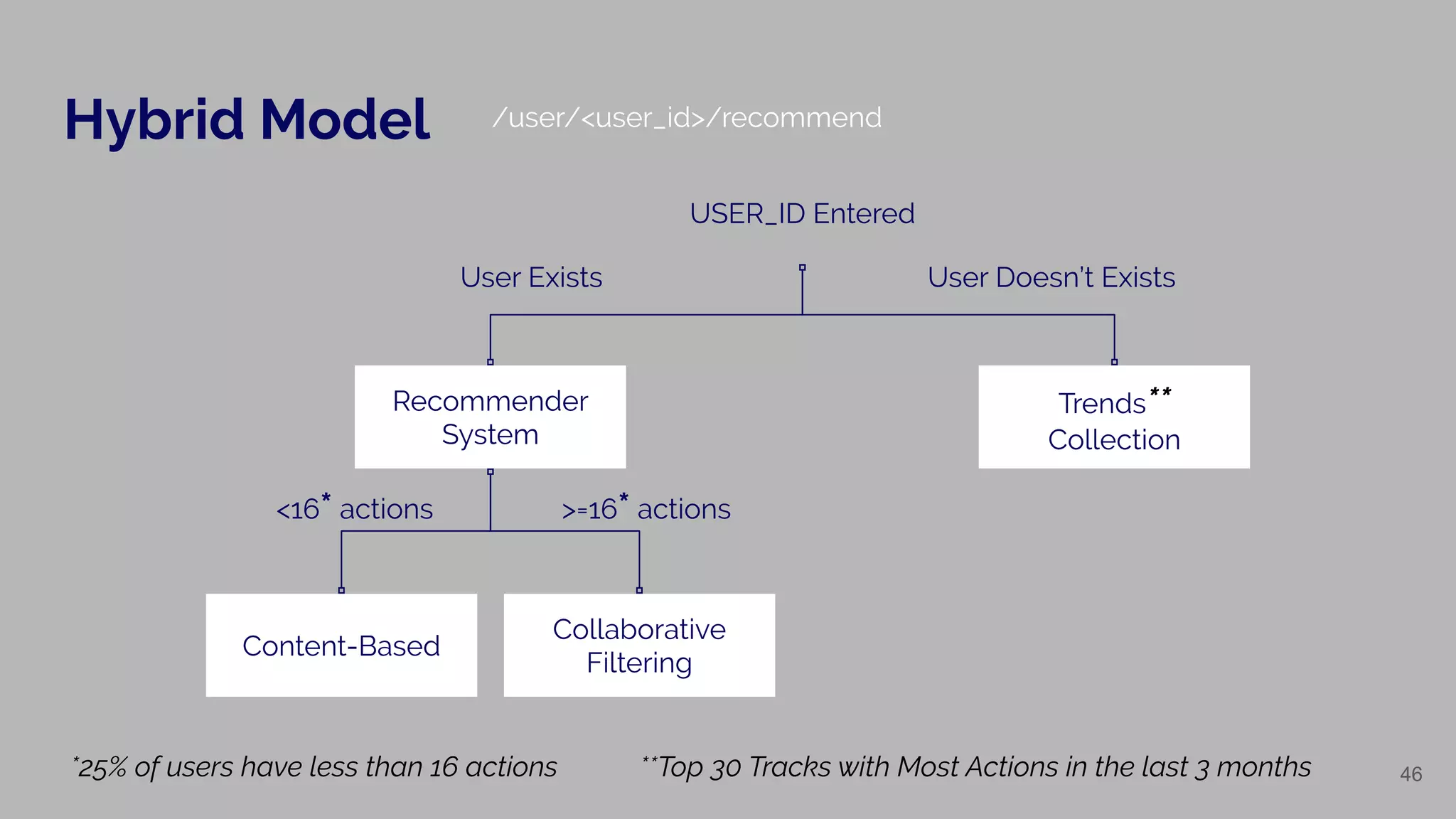
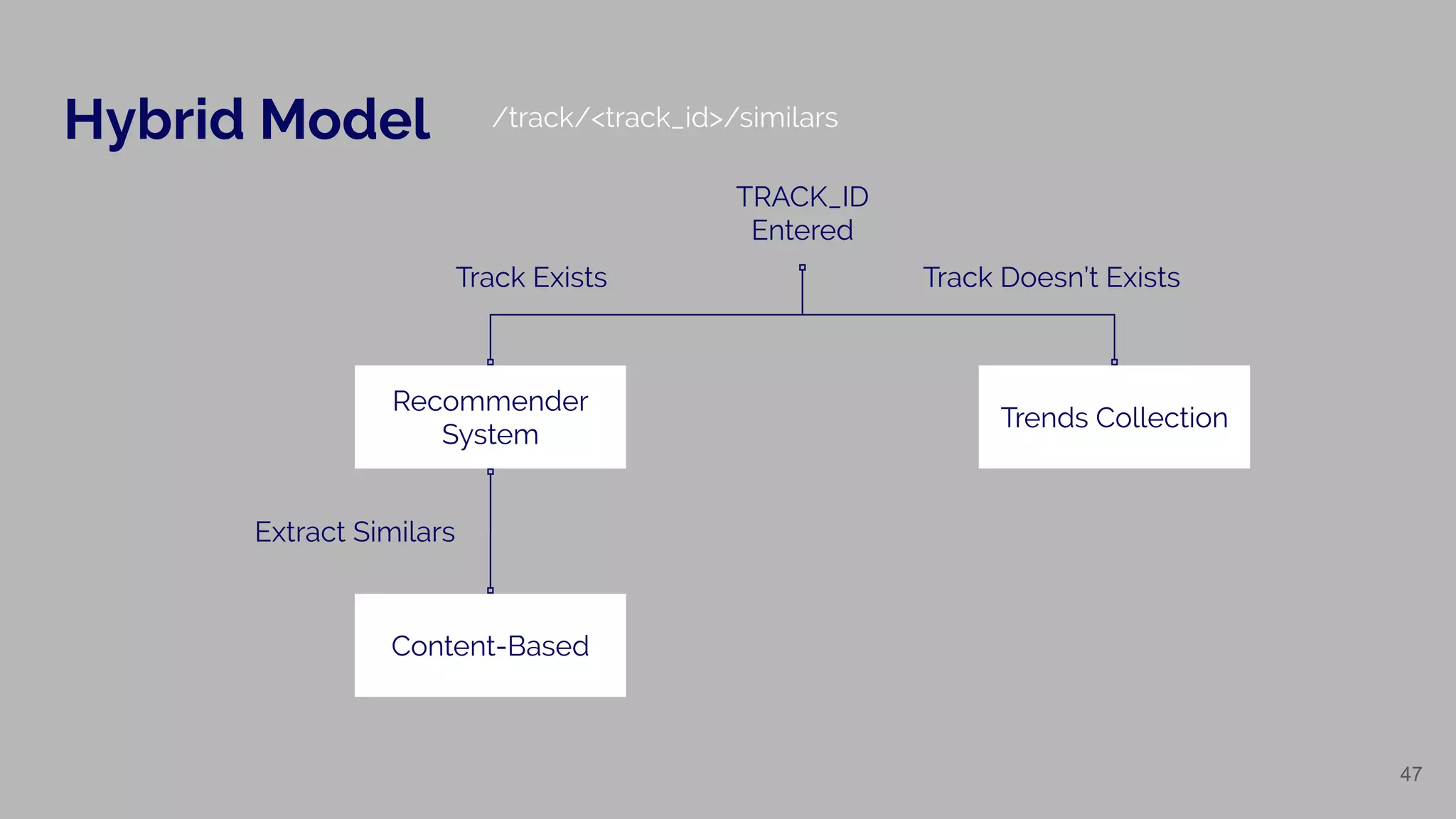
Details of utilizing hybrid models in recommending systems based on user actions.
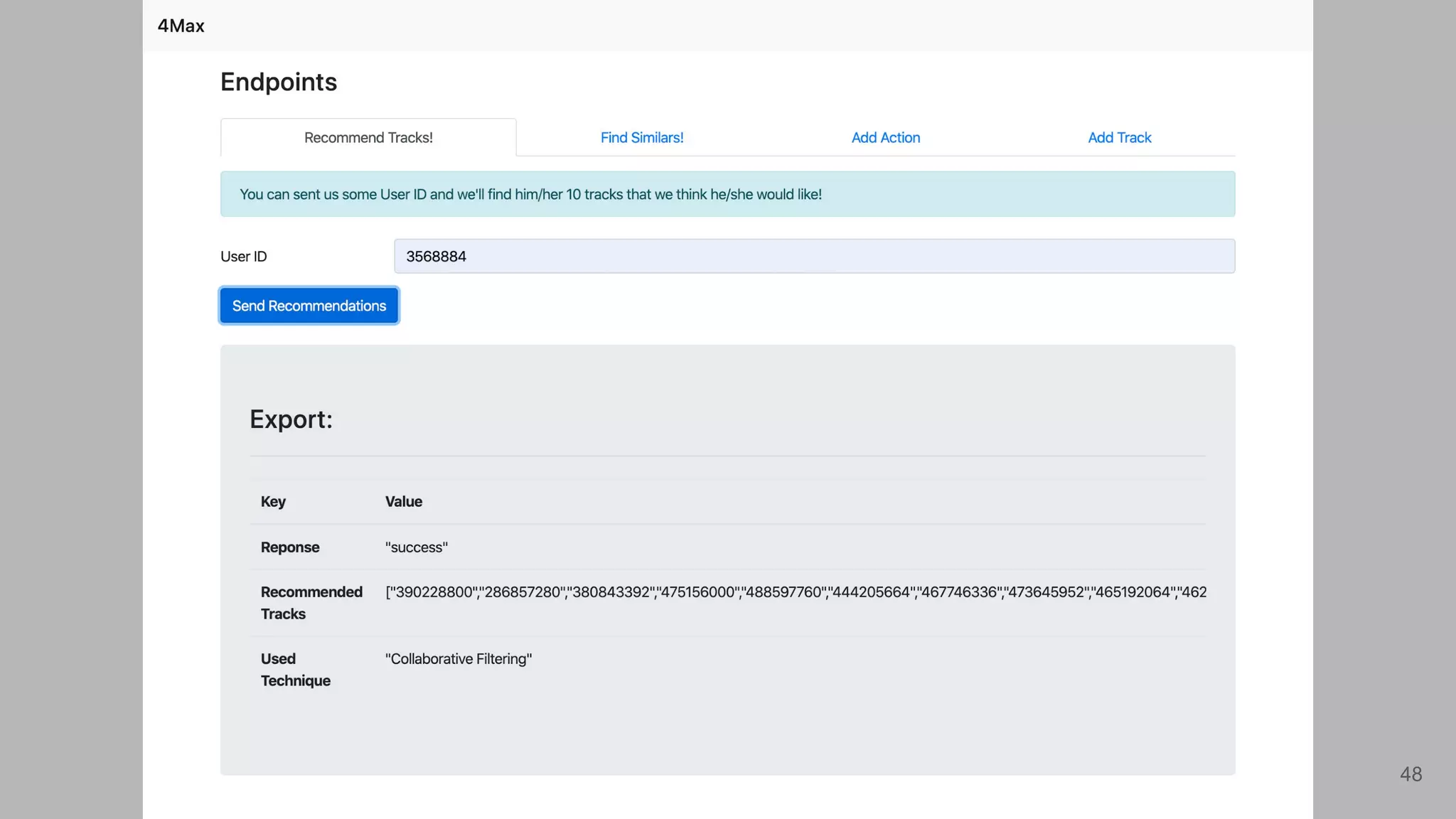
Describes the method for extracting similar tracks based on user input.
Acknowledgment of the team members involved in the project.
Final thank you to the audience and conclusion of the presentation.






























![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)












