Download to read offline








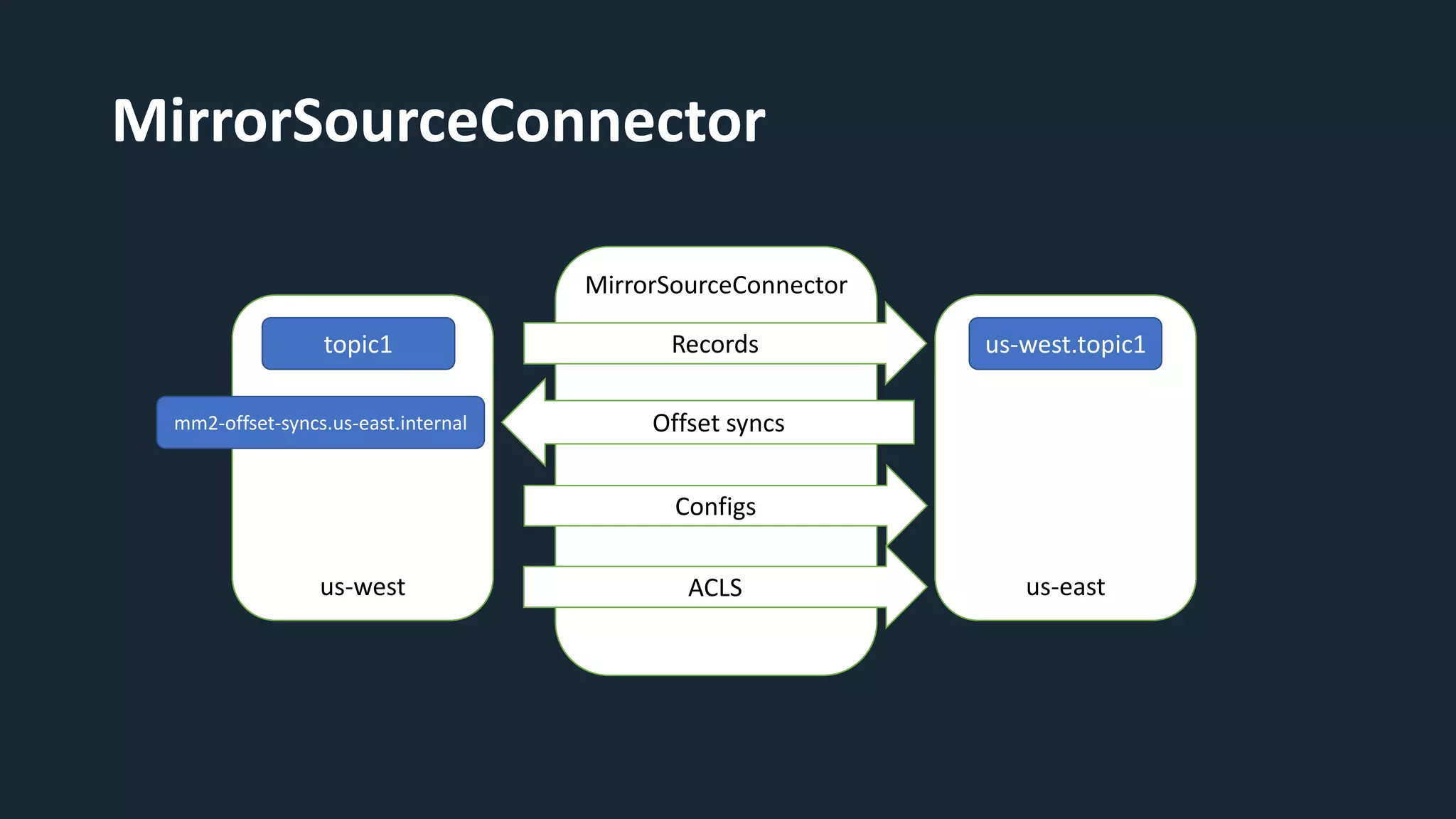
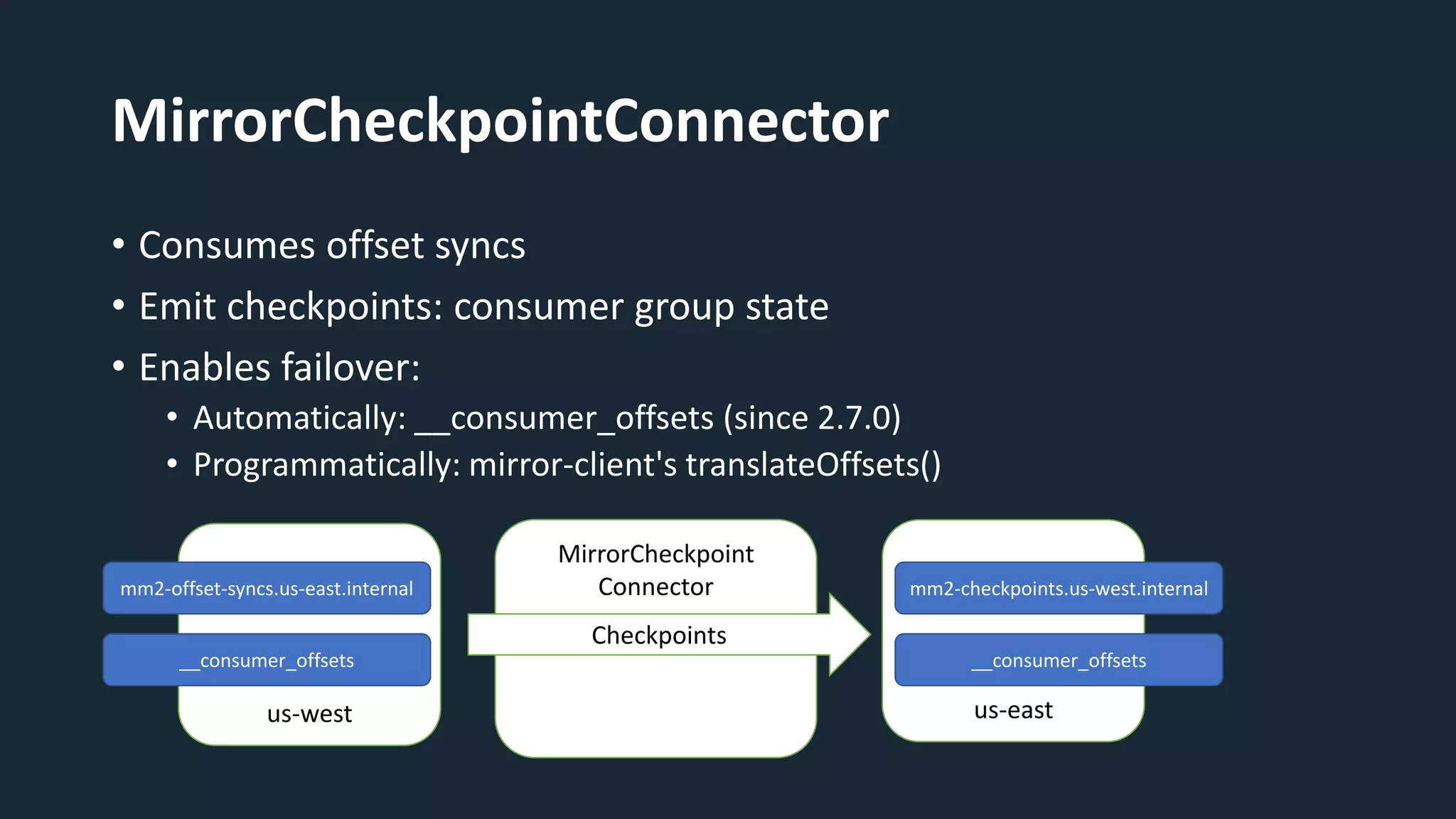
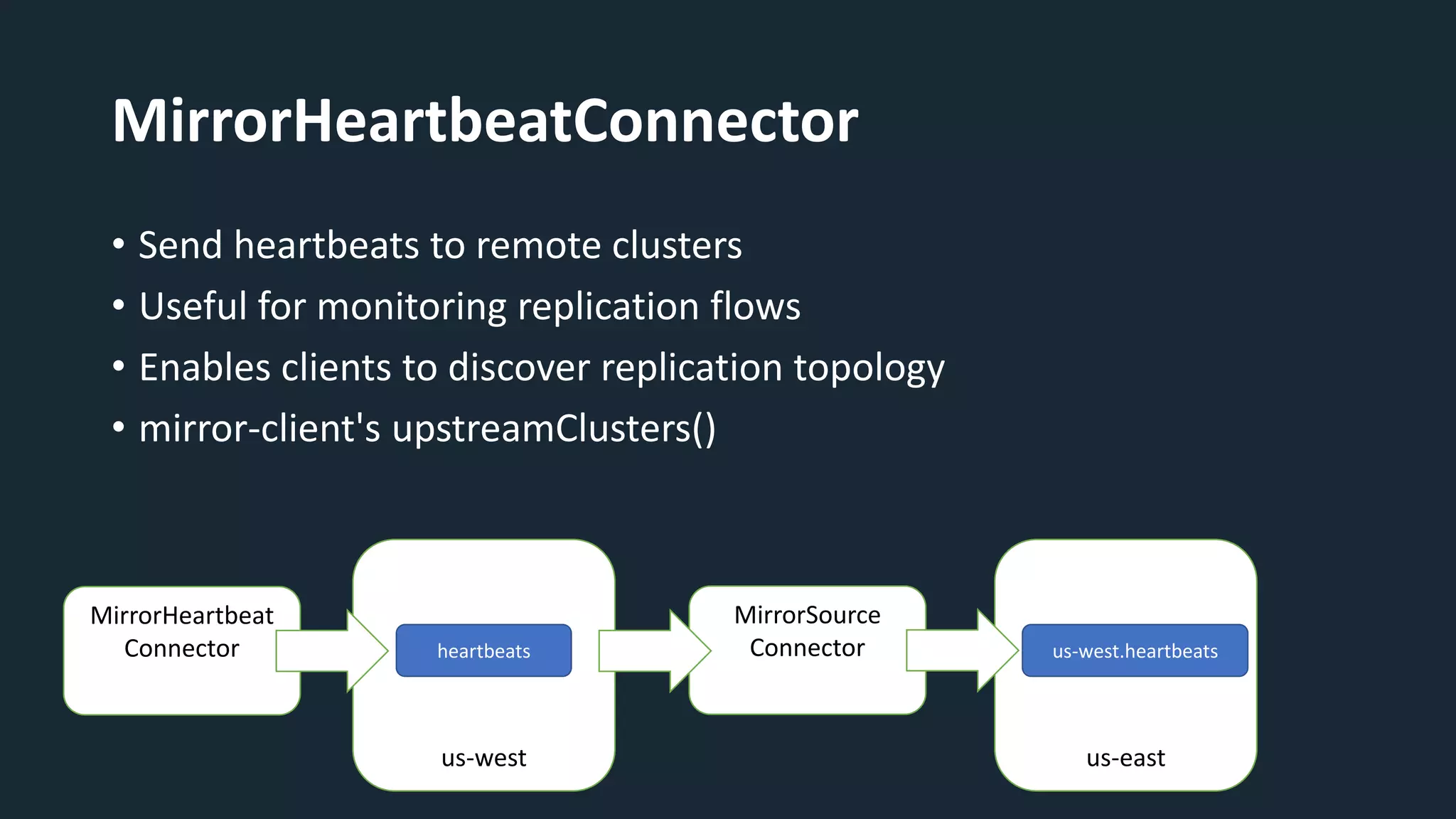


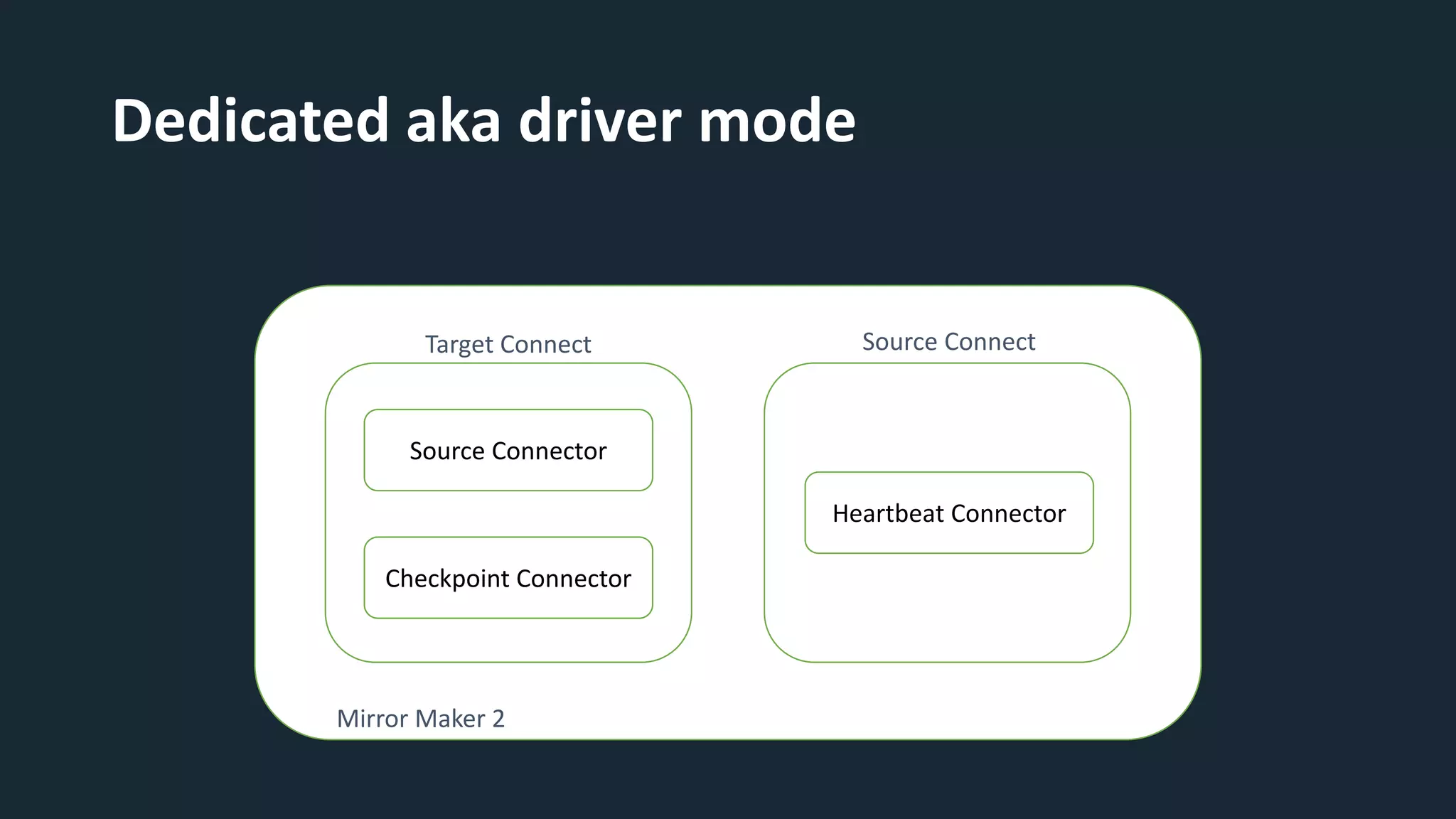


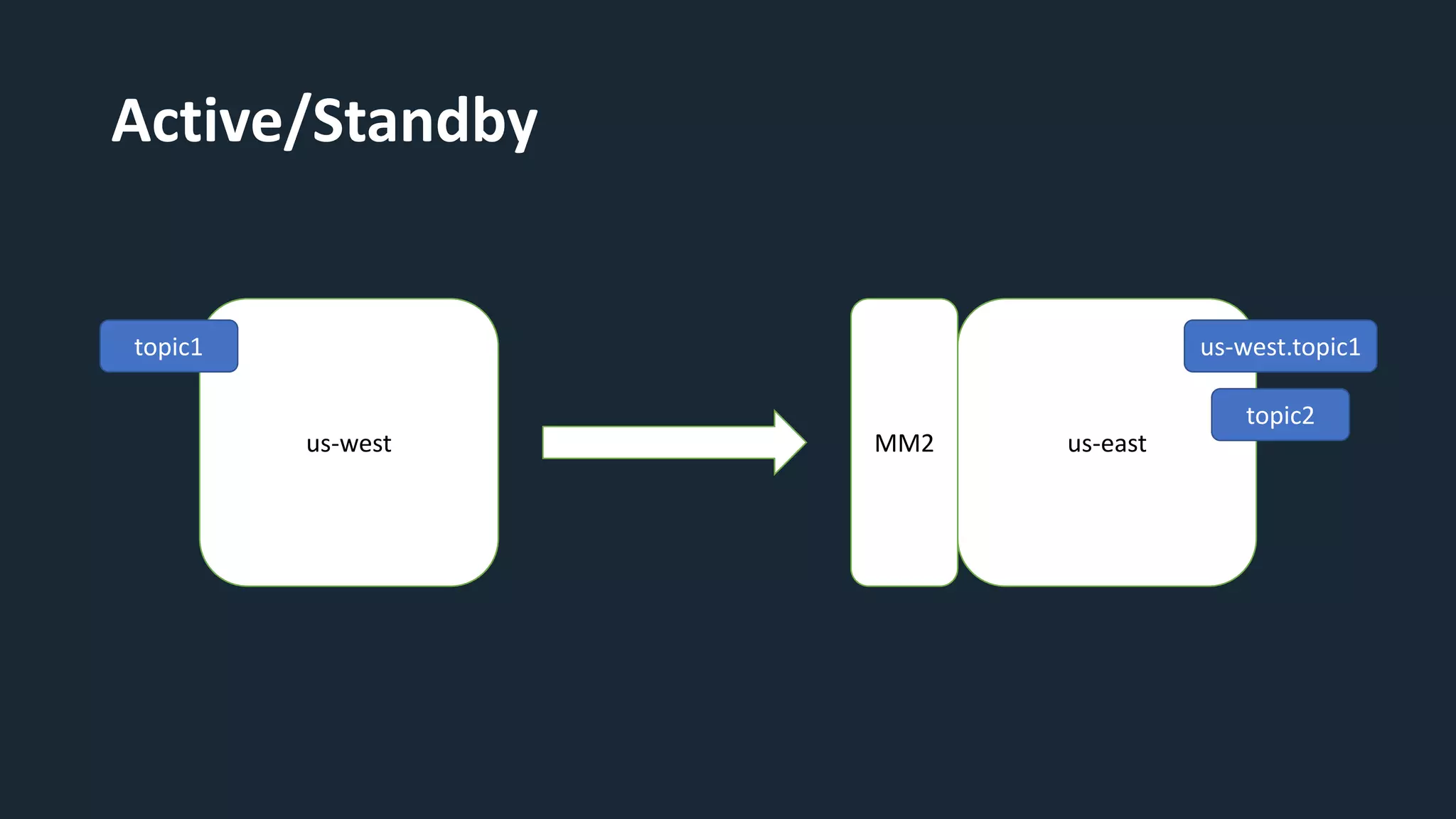
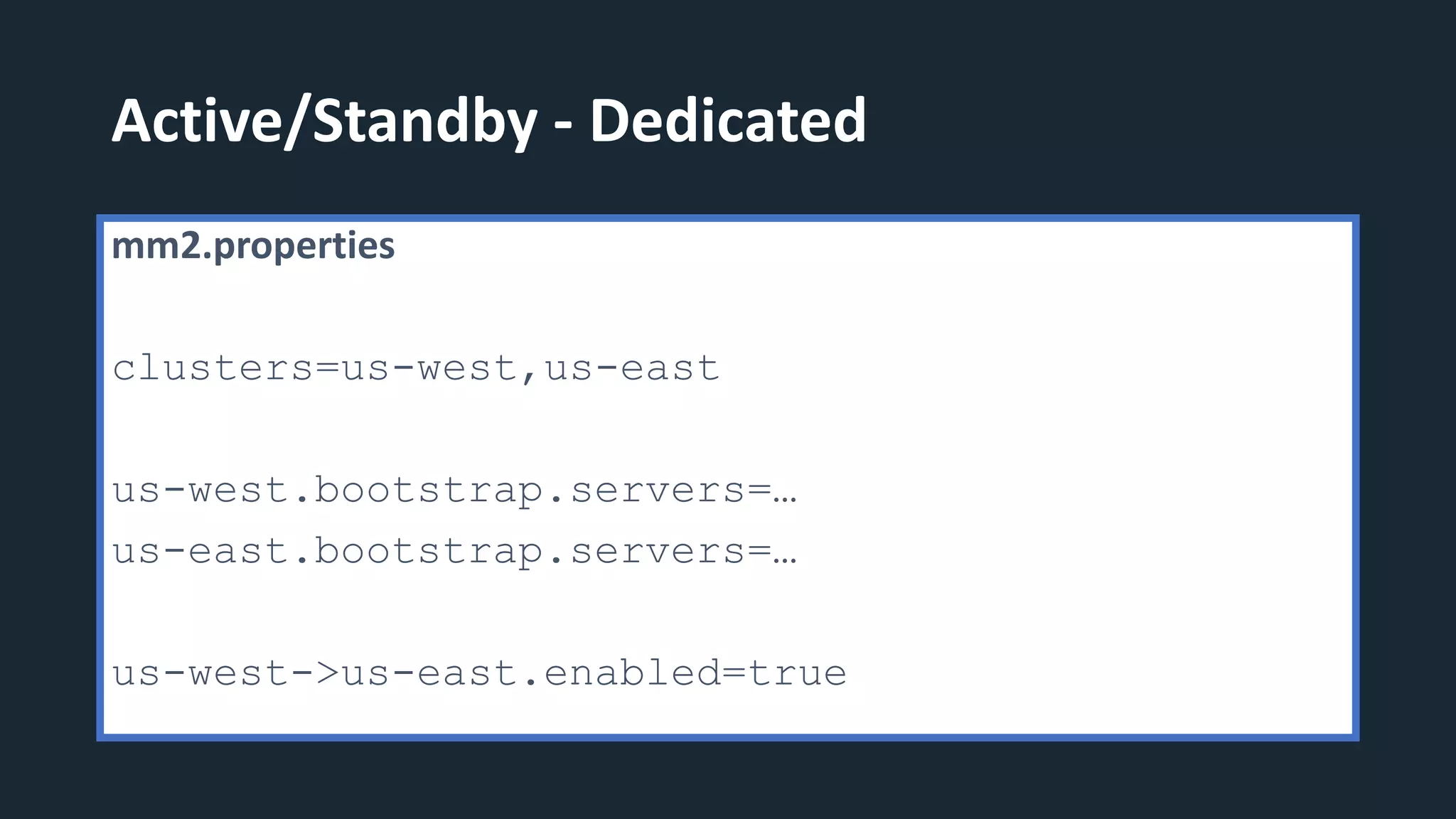

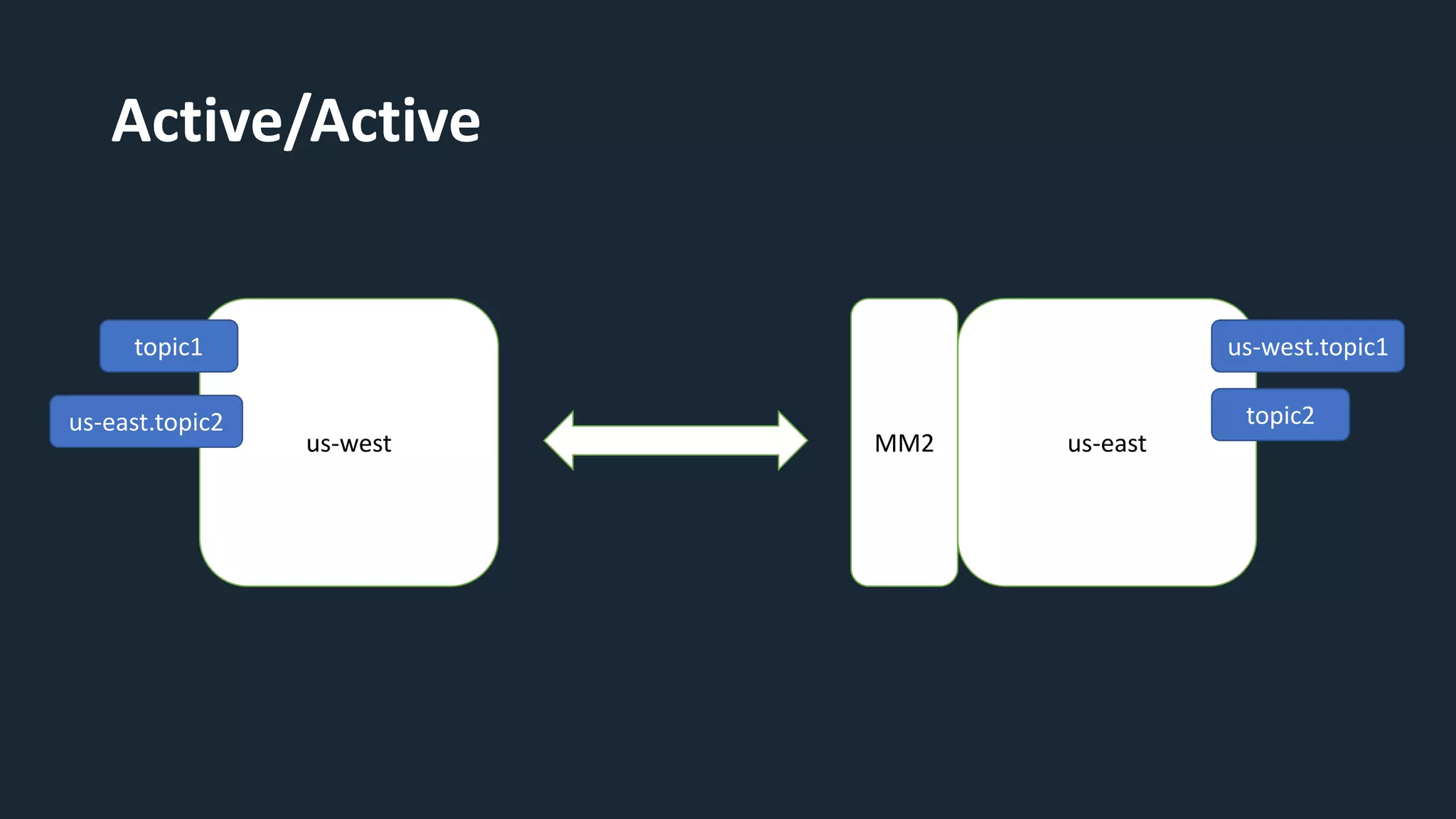
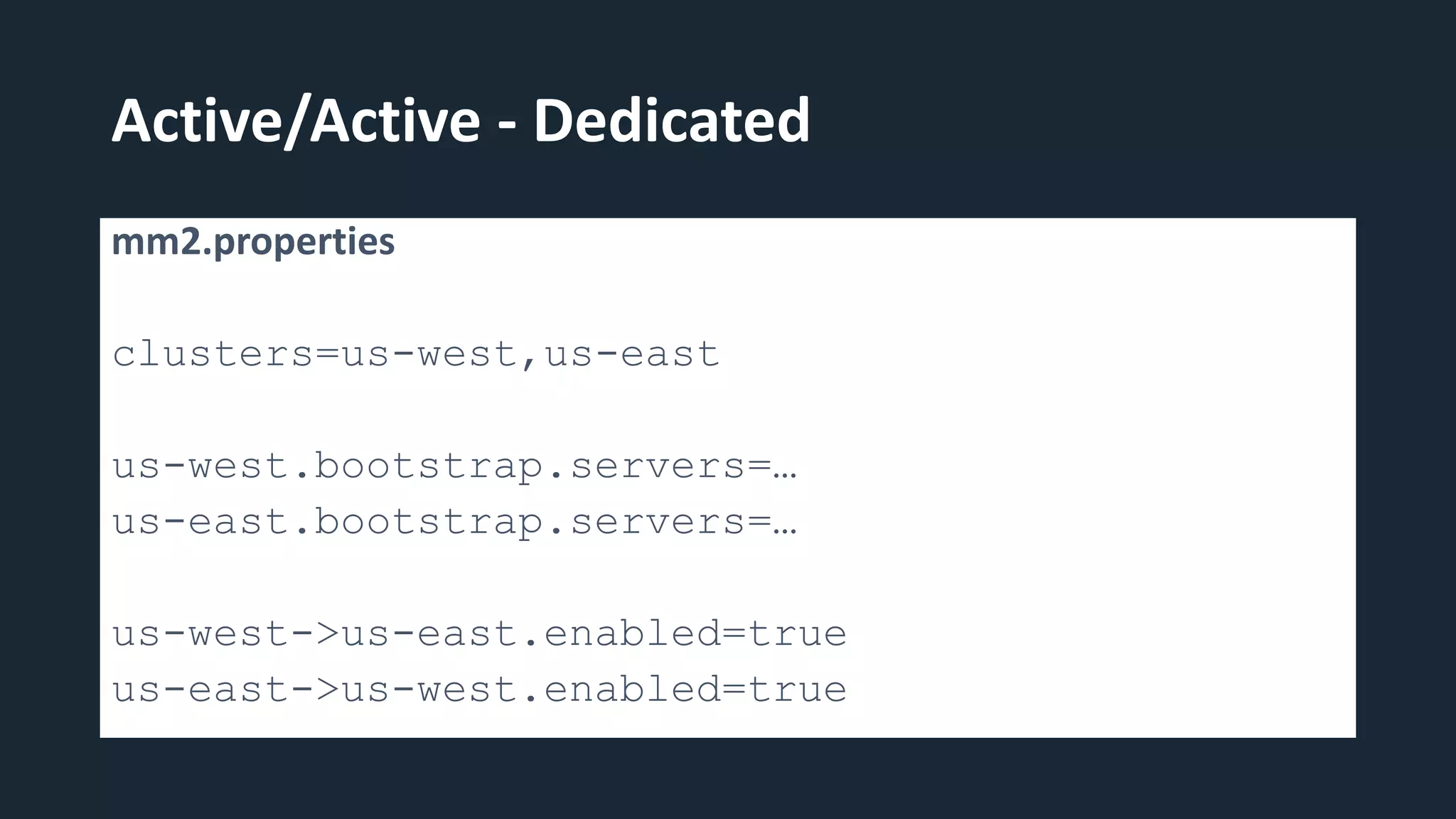
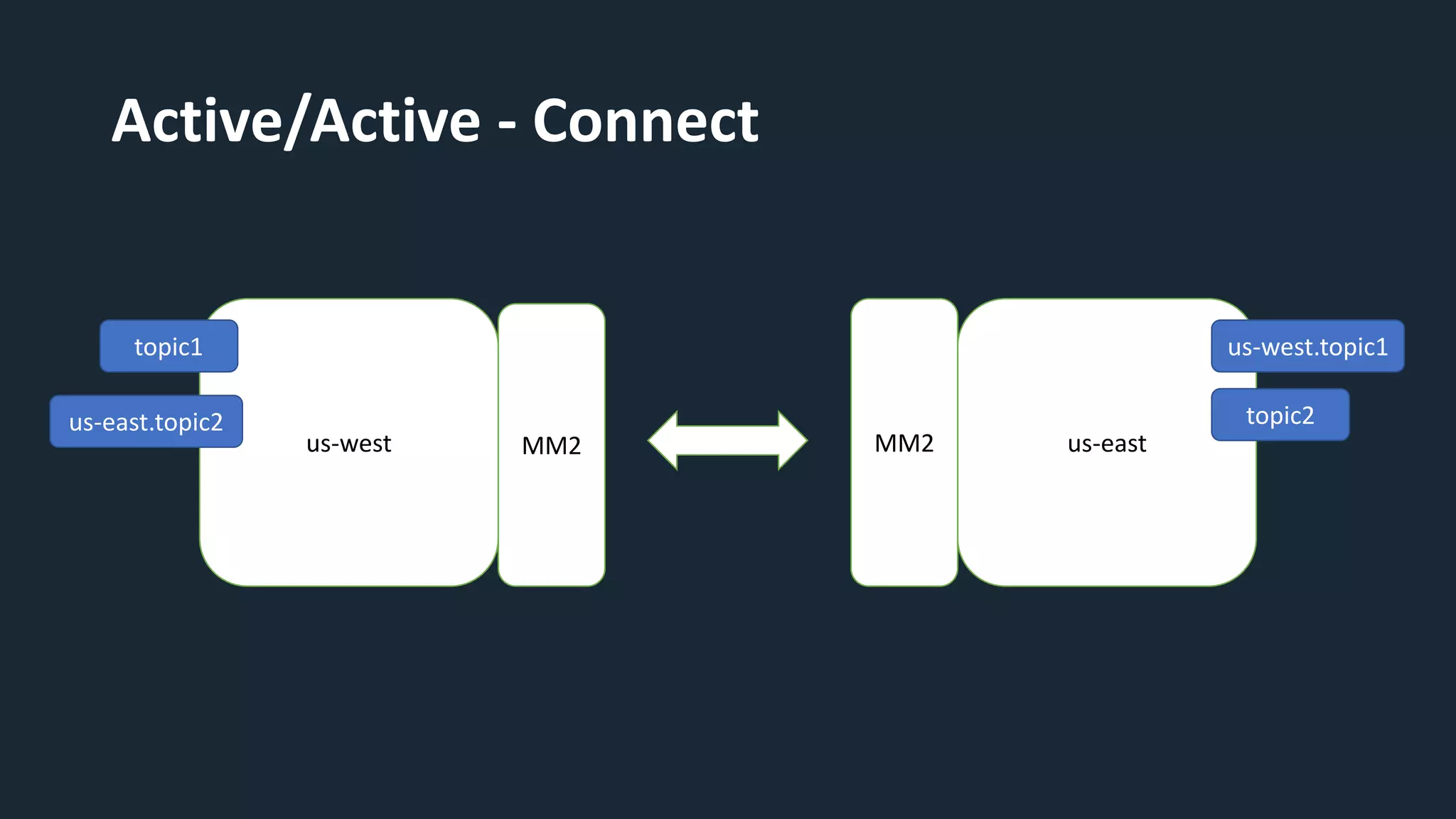
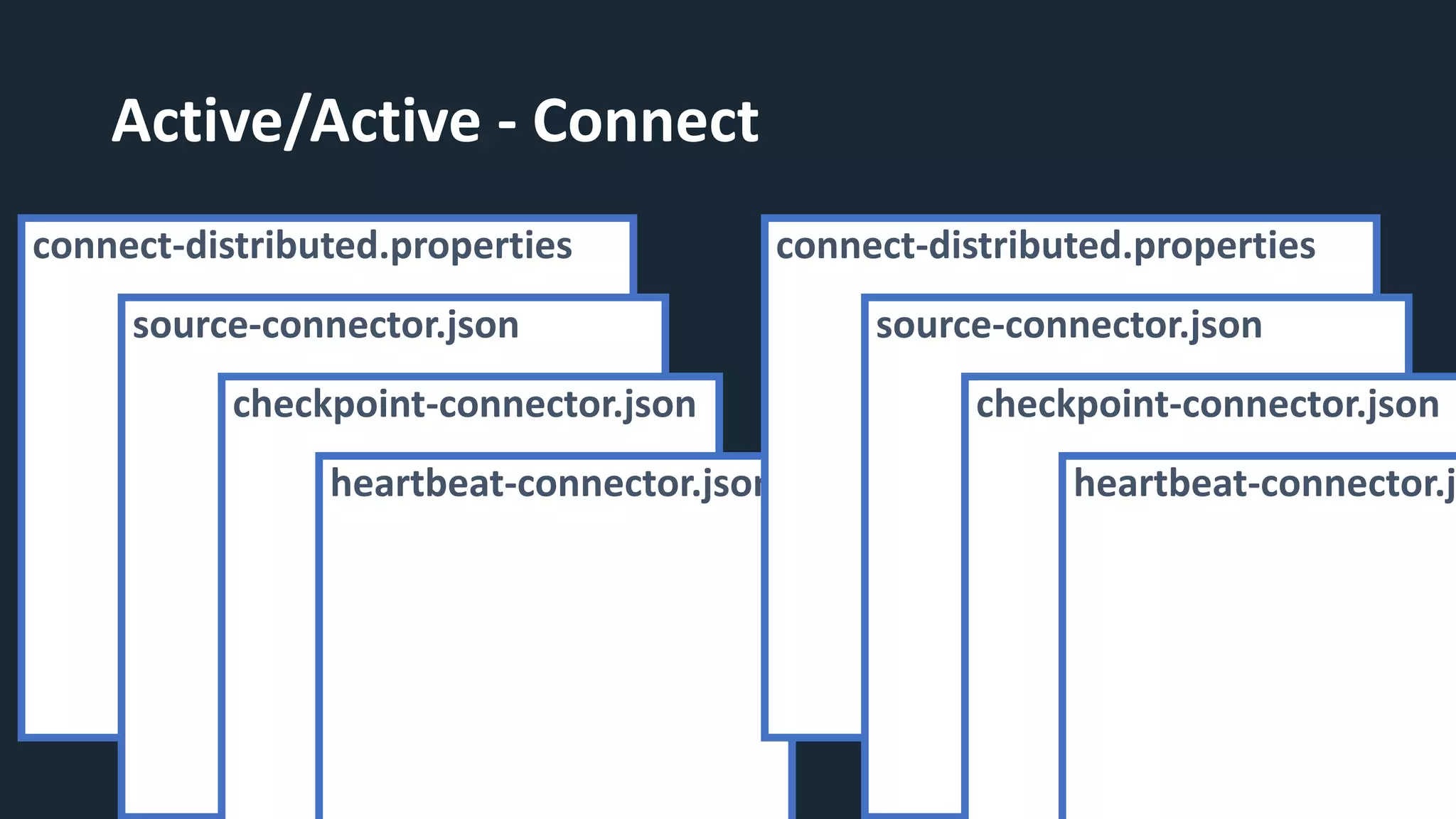






The document provides an overview of MirrorMaker 2 (MM2) and its improvements over the legacy MirrorMaker 1 (MM1), addressing pain points such as consumer offset mirroring, deployment issues, and synchronization of topics. It describes deployment modes, available connectors, and various use cases, including active/standby and active/active configurations. Additionally, it outlines monitoring best practices and relevant Kafka Improvement Proposals (KIPs) related to MM2.
















































































