Download as PDF, PPTX
















![Challenges, what lies ahead
Side information in embedding models, remove regional
biases, external genre information, lyrics, Facebook /
Twitter account data, [ cover art, who knows :) ]
Deep Learning
Transfer Learning
Outlier Detection](https://image.slidesharecdn.com/reworkpersonalizedplaylistsatspotify-170111050910/85/Personalized-Playlists-at-Spotify-19-320.jpg)


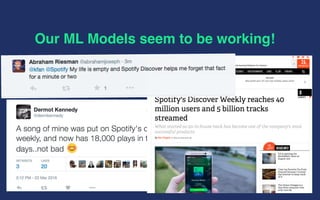
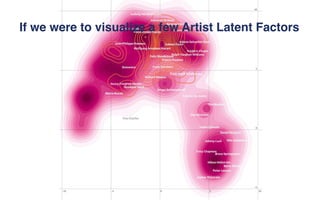
Spotify uses various machine learning models to power personalized playlist and track recommendations for its over 100 million active users. Latent factor models represent users and songs as vectors in a shared dimensional space to predict listener preferences. Deep learning models analyze audio features to learn song representations. Natural language processing models like Word2Vec represent user listening histories as sequences to predict future interests. While current models are effective, future work includes incorporating more contextual data into embeddings to remove biases and better capture long-term user intents.

































![Human presence detection based room light controller using pir2.pptx [repaired]](https://cdn.slidesharecdn.com/ss_thumbnails/humanpresencedetectionbasedroomlightcontrollerusingpir2-160418083434-thumbnail.jpg?width=640&height=640&fit=bounds)




















































