Download as PDF, PPTX





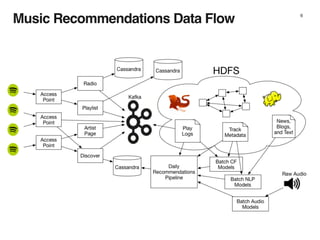


![The Genre Toplist Problem 9
•Assume we have access to daily log data for all plays on Spotify.
•Goal: Calculate the top 1k artists on for each genre based on total daily plays
{"User": “userA”, "Date": “2015-01-10", "Artist": “Beyonce", "Track": "Halo", "Genres": ["Pop", "R&B", "Soul"]}
{"User": “userB”, "Date": “2015-01-10”, "Artist": "Led Zeppelin”, "Track": "Achilles Last Stand", "Genres": ["Rock",
"Blues Rock", "Hard Rock"]}
……….](https://image.slidesharecdn.com/ddtx15-150112083927-conversion-gate01/85/Scala-Data-Pipelines-for-Music-Recommendations-9-320.jpg)





(implicit ord :
Ordering[K]) extends Monoid[PriorityQueue[K]]](https://image.slidesharecdn.com/ddtx15-150112083927-conversion-gate01/85/Scala-Data-Pipelines-for-Music-Recommendations-16-320.jpg)
![sortWithTake 17
•Uses PriorityQueueMonoid from Algebird
•PriorityQueue aggregations form a commutative monoid!
1. Associative:
PQ1 = [ (Jay Z, 545), (Miles Davis, 272), …]
PQ2 = [ (Beyonce, 731), (Kurt Vile, 372), …]
PQ3 = [ (Twin Shadow, 87), … ]
PQ1 ++ (PQ2 ++ PQ3) = (PQ1 ++ PQ2) ++ PQ3
2.Commutative:
PQ1 ++ PQ2 = PQ2 ++ PQ1
3.Identity:
PQ1 ++ EmptyPQ = PQ1
class PriorityQueueMonoid[K](max : Int)(implicit ord :
Ordering[K]) extends Monoid[PriorityQueue[K]]](https://image.slidesharecdn.com/ddtx15-150112083927-conversion-gate01/85/Scala-Data-Pipelines-for-Music-Recommendations-17-320.jpg)
(implicit ord :
Ordering[K]) extends Monoid[PriorityQueue[K]]
reduced traffic](https://image.slidesharecdn.com/ddtx15-150112083927-conversion-gate01/85/Scala-Data-Pipelines-for-Music-Recommendations-18-320.jpg)




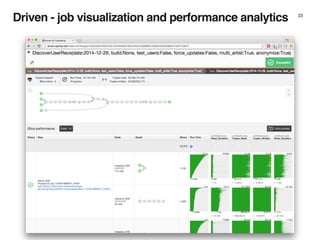

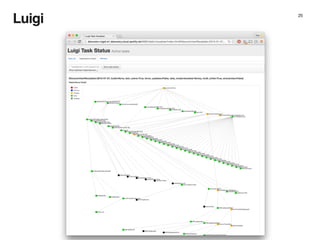



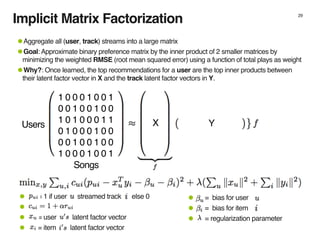





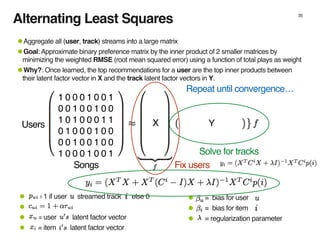
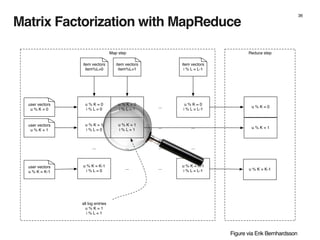
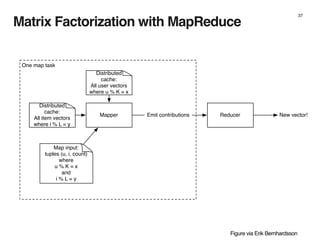

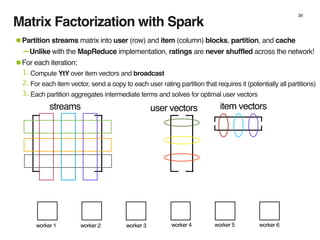
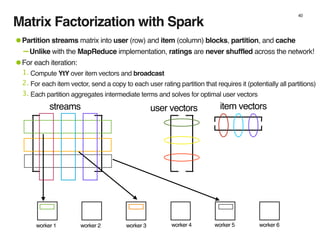
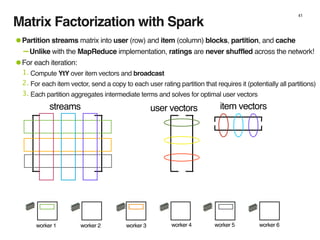
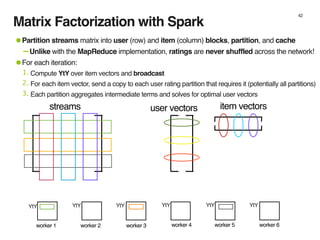
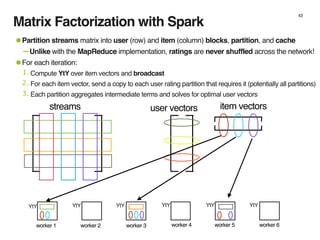
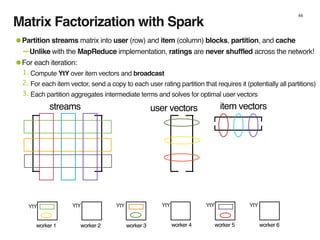
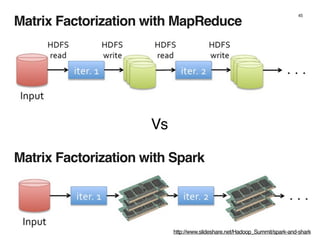
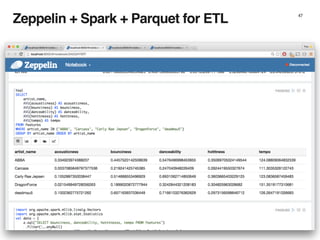
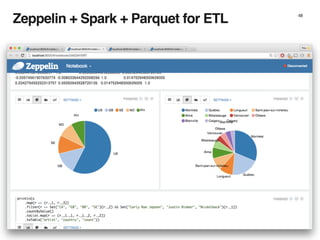



The document discusses the architecture and design of music recommendation systems at Spotify, emphasizing the use of machine learning techniques like collaborative filtering and matrix factorization. It details the data pipelines for processing user listening data and generating genre-specific artist toplists using tools such as Scalding and Apache Parquet. Additionally, the document covers various methodologies for efficiently handling and analyzing large datasets to improve music recommendations.

































































