Download as PDF, PPTX












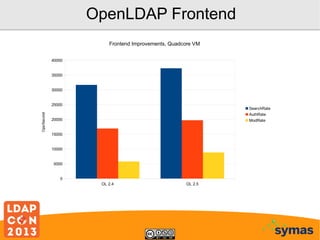


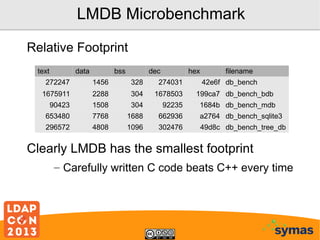





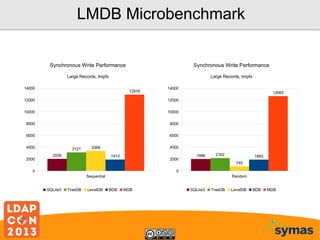
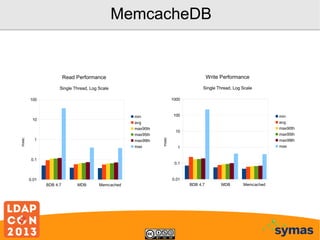






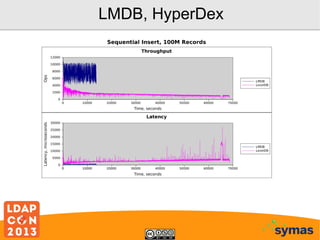










This document provides an overview of recent developments with the OpenLDAP project. It discusses the adoption of the Lightning Memory-Mapped Database (LMDB) which has improved performance and efficiency both within OpenLDAP and for other projects. It also outlines new work on the HyperDex clustered backend and Samba4/Active Directory integration. While performance gains have been made, more work remains, including deprecating the old BerkeleyDB backends and improving transaction support.















!["[WORKSHOP] K8S for developers", Denis Romanuk](https://cdn.slidesharecdn.com/ss_thumbnails/k8sfordevs-210906100414-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































