Downloaded 23 times





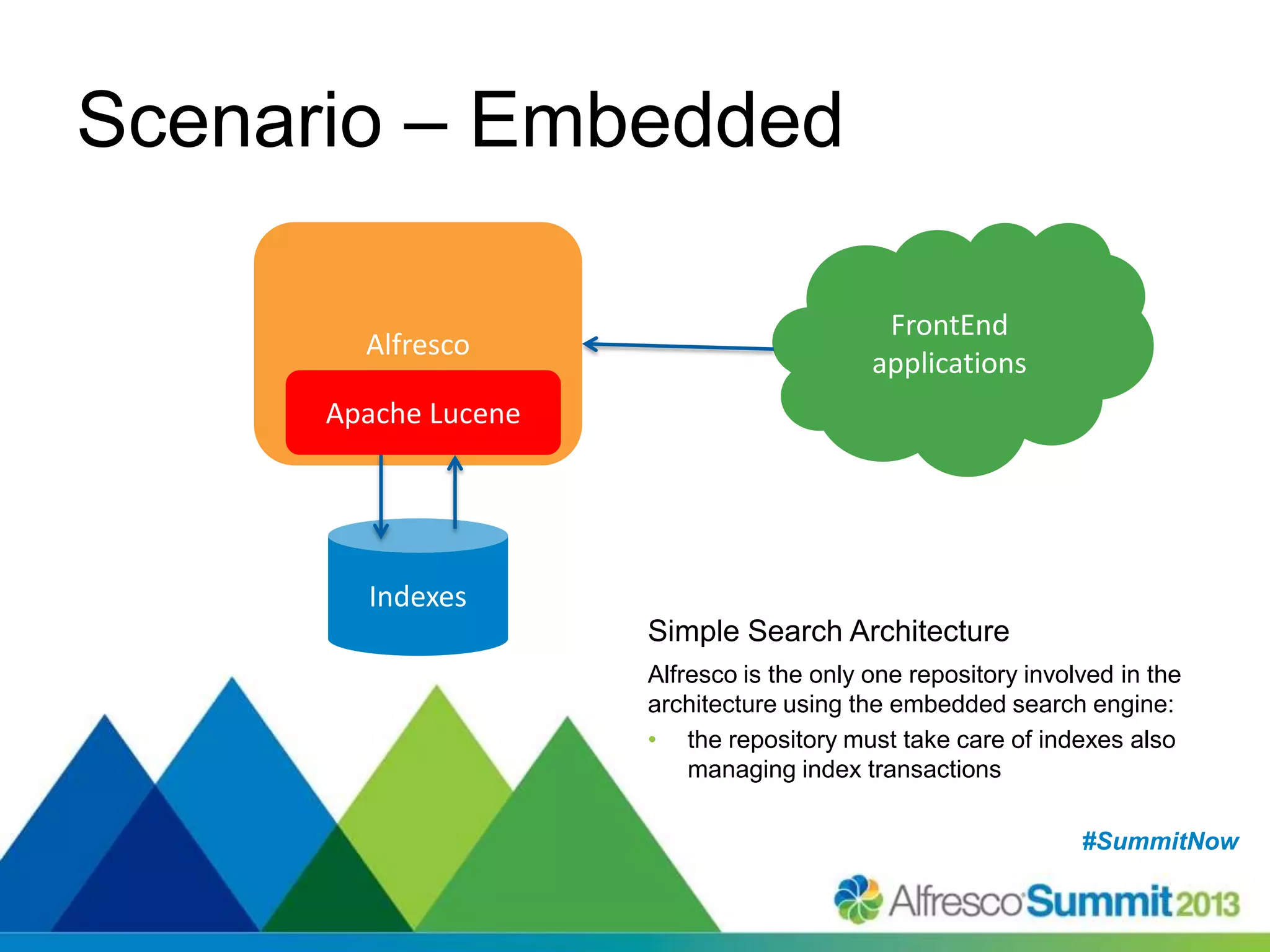
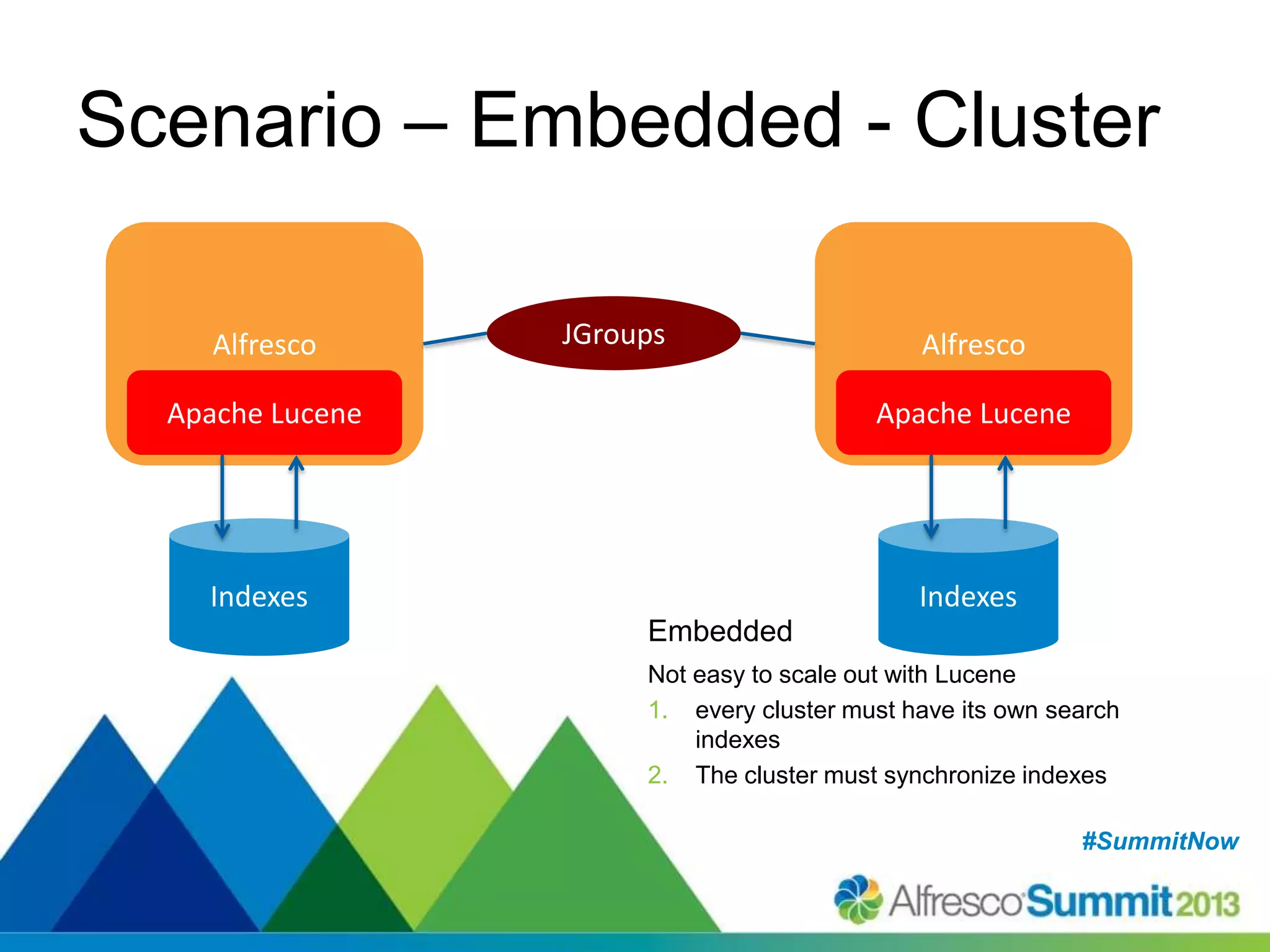


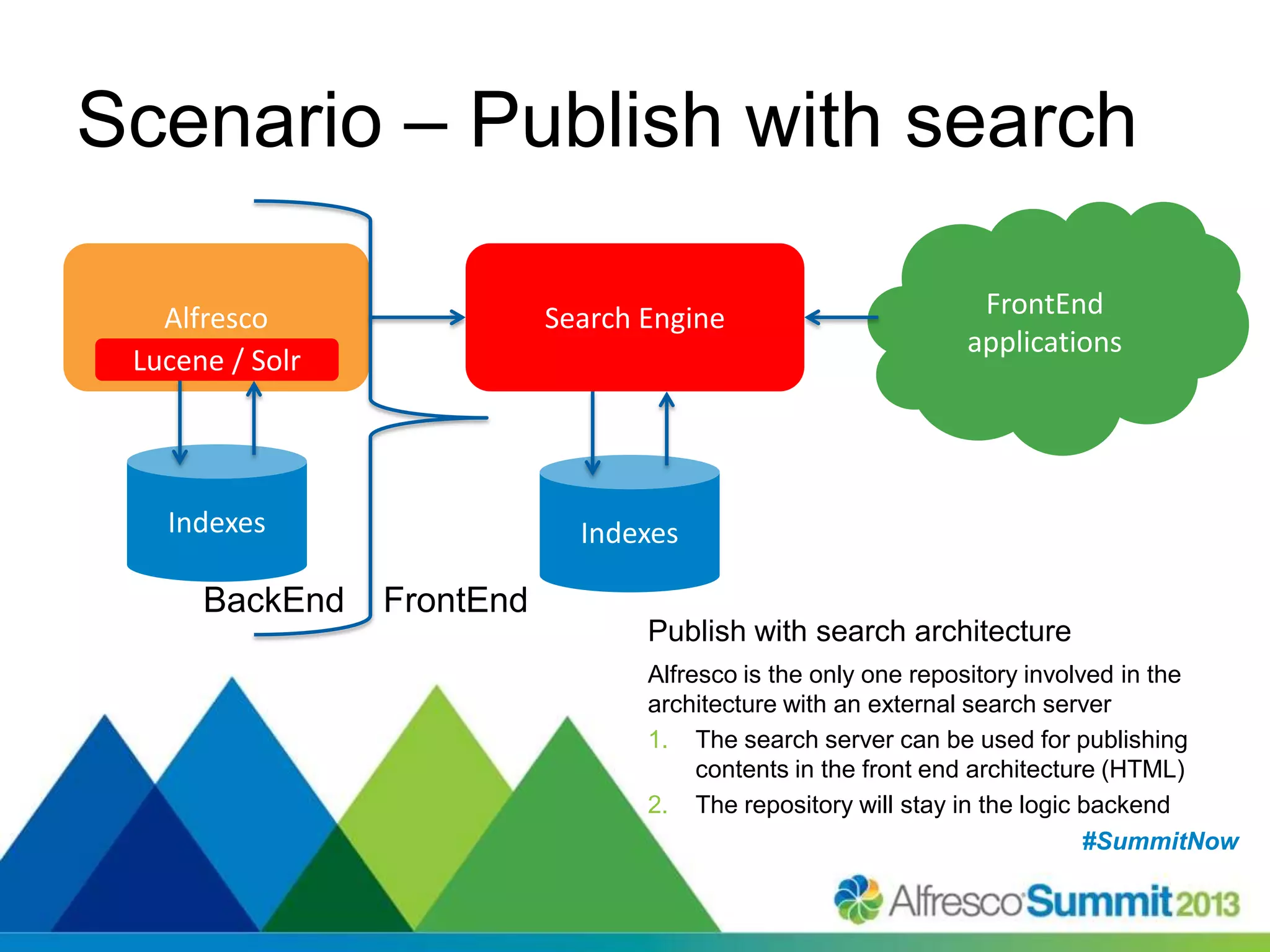




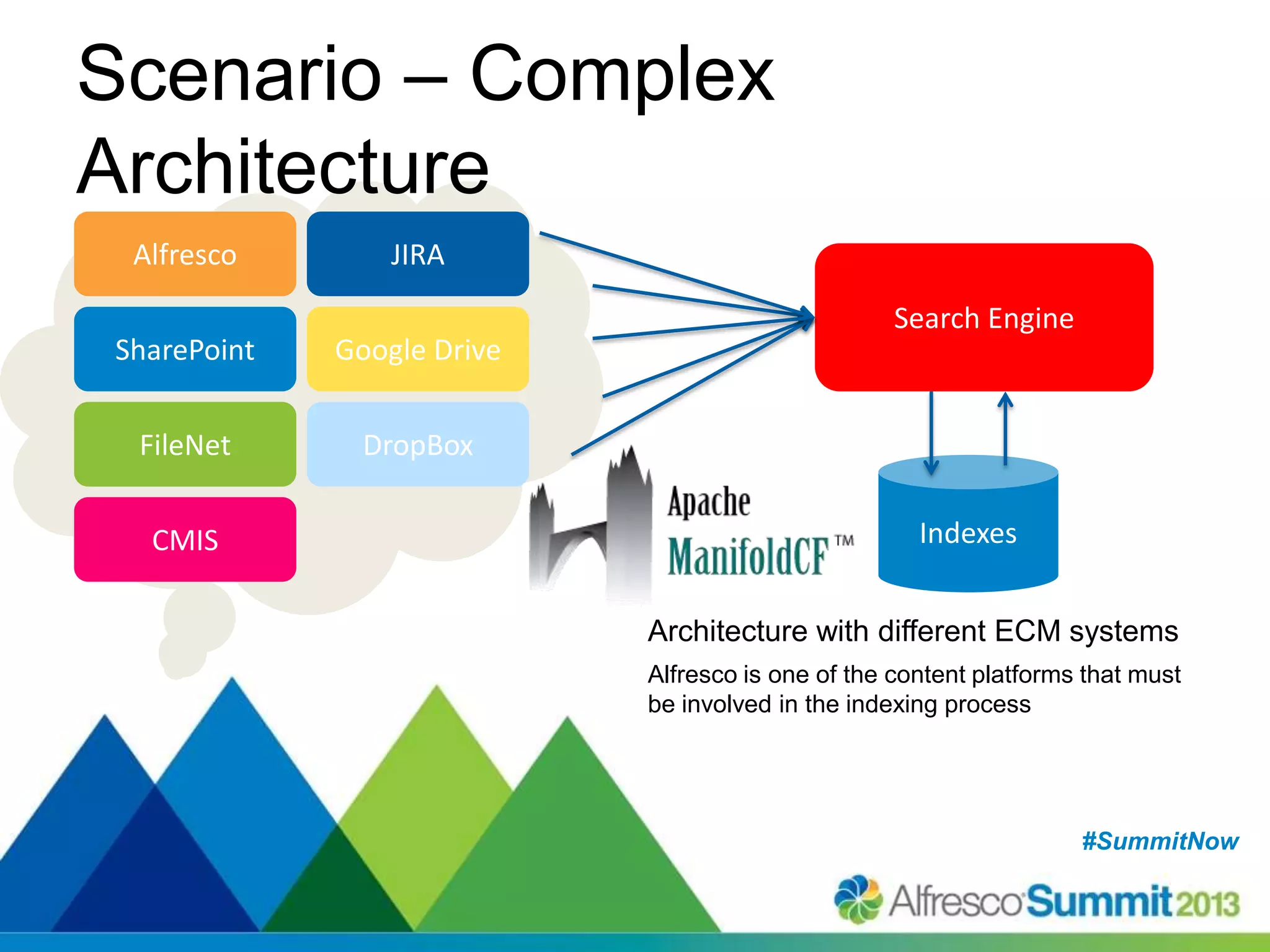



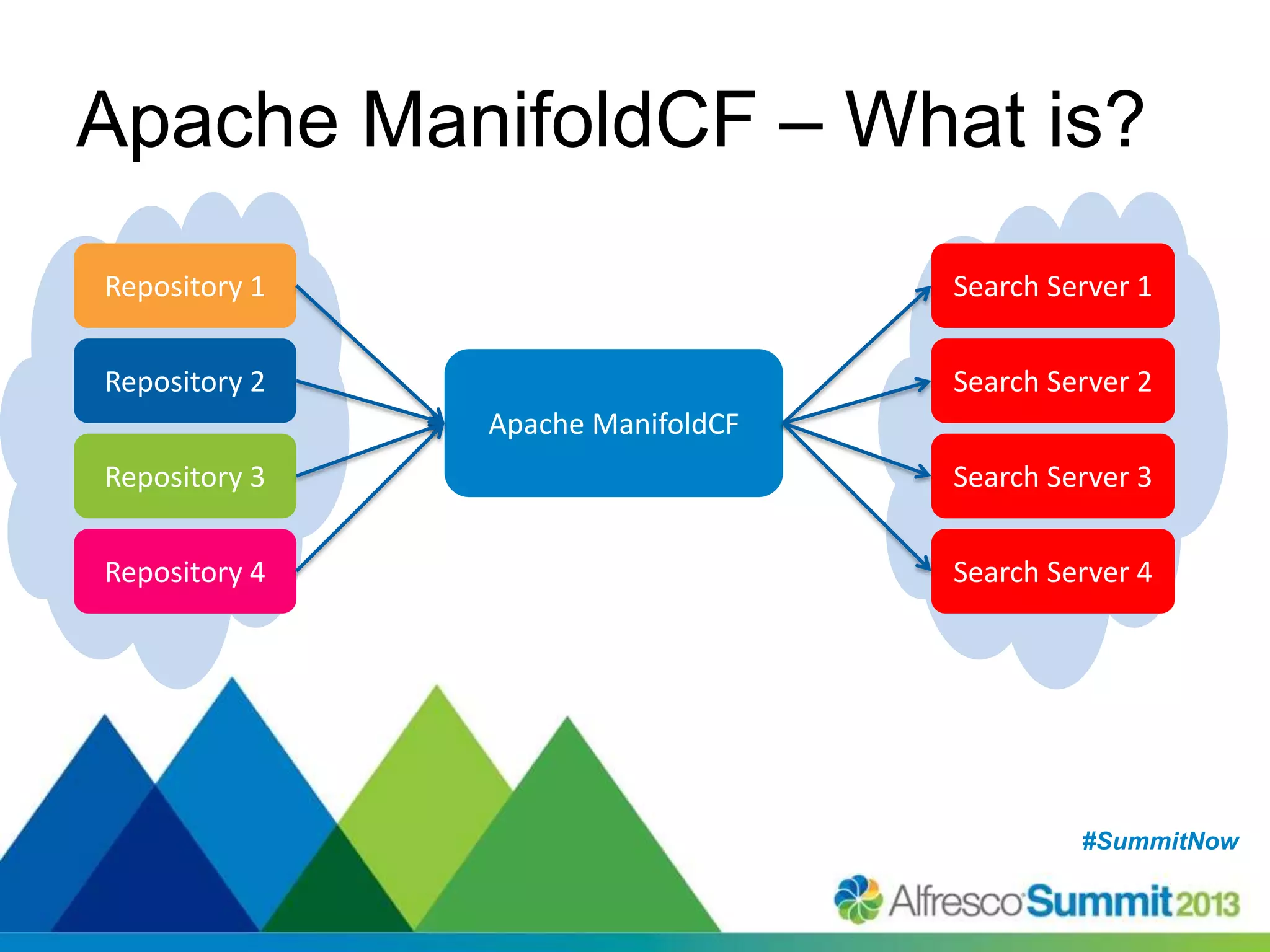







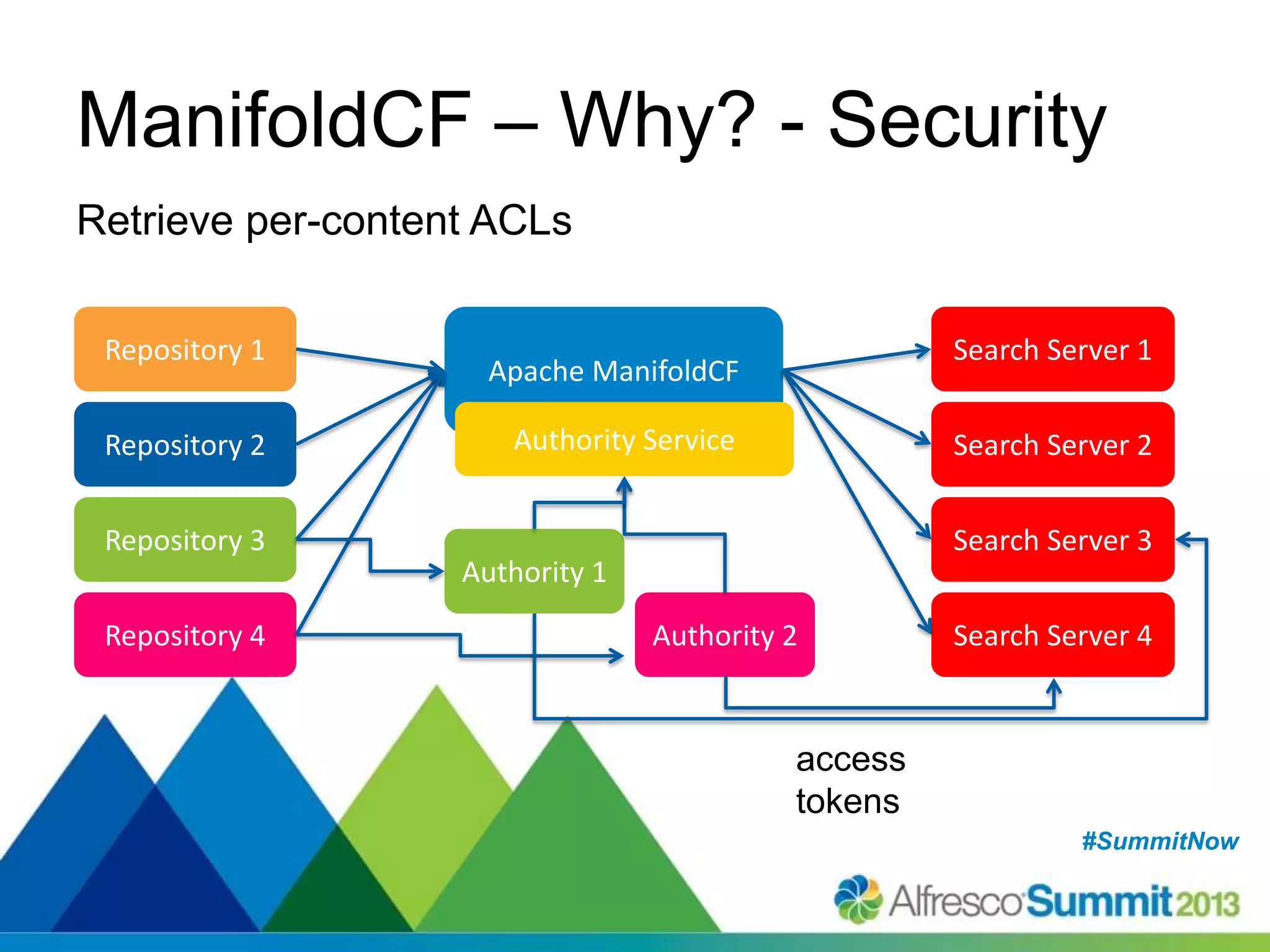



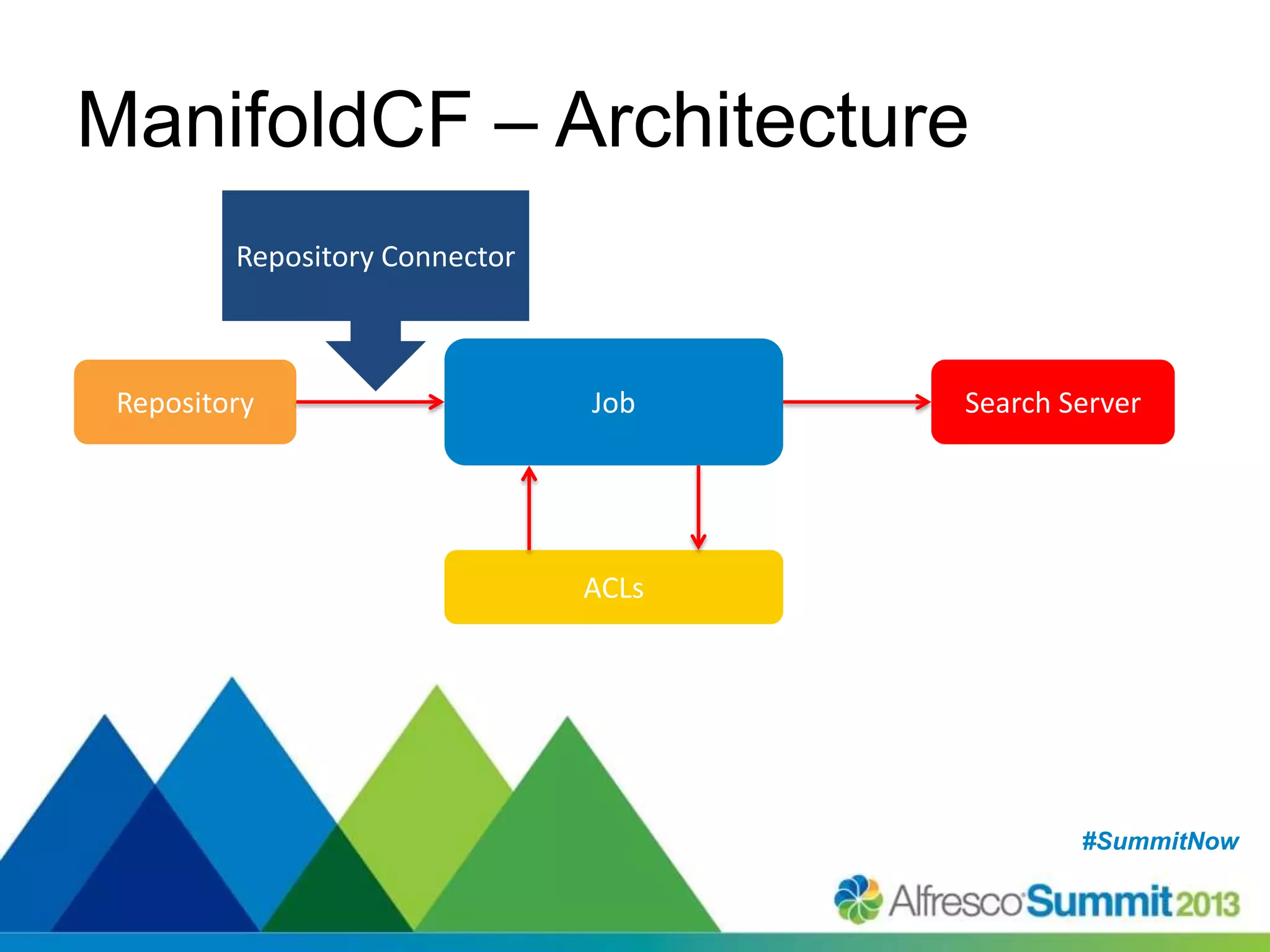



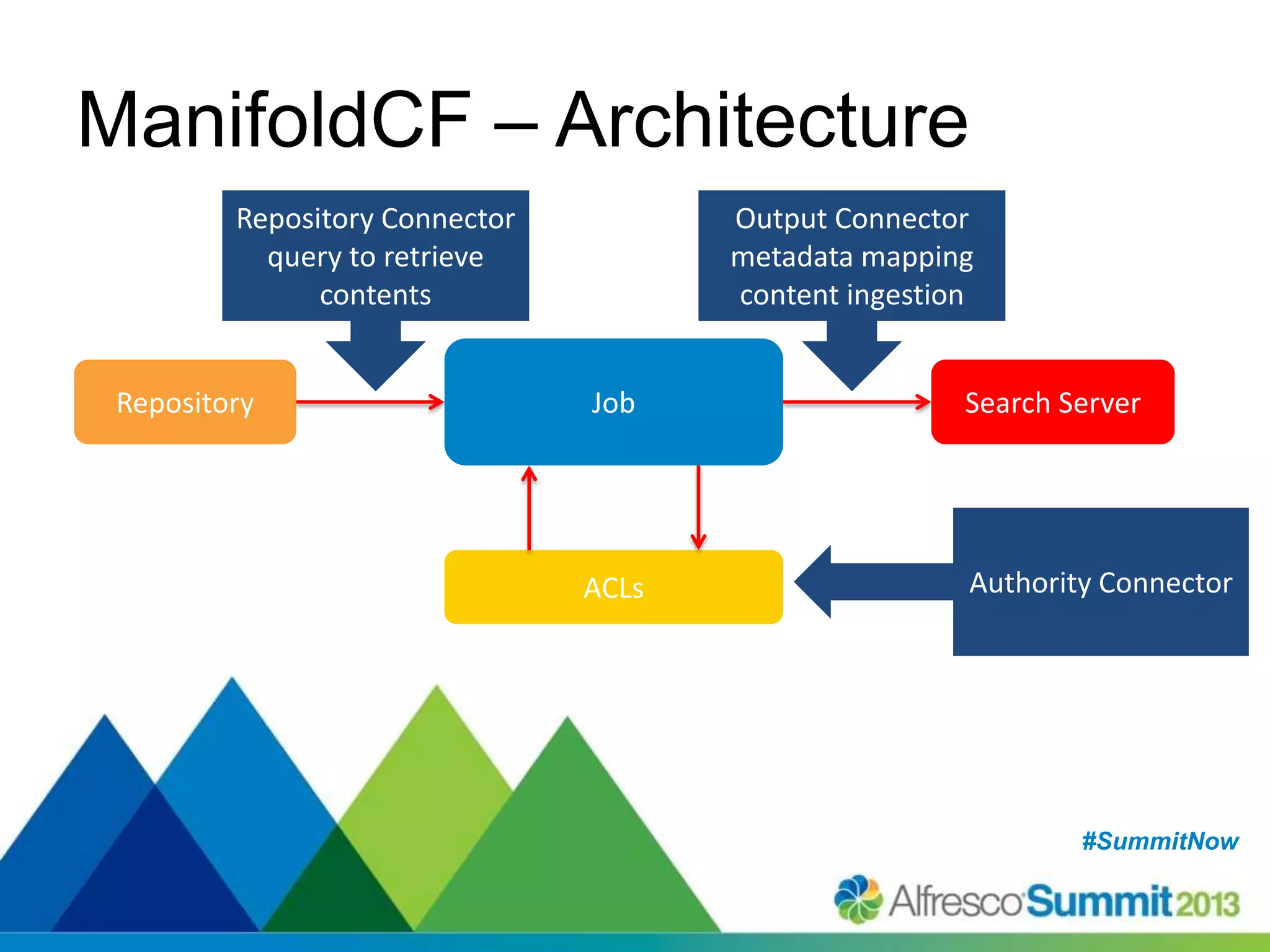
















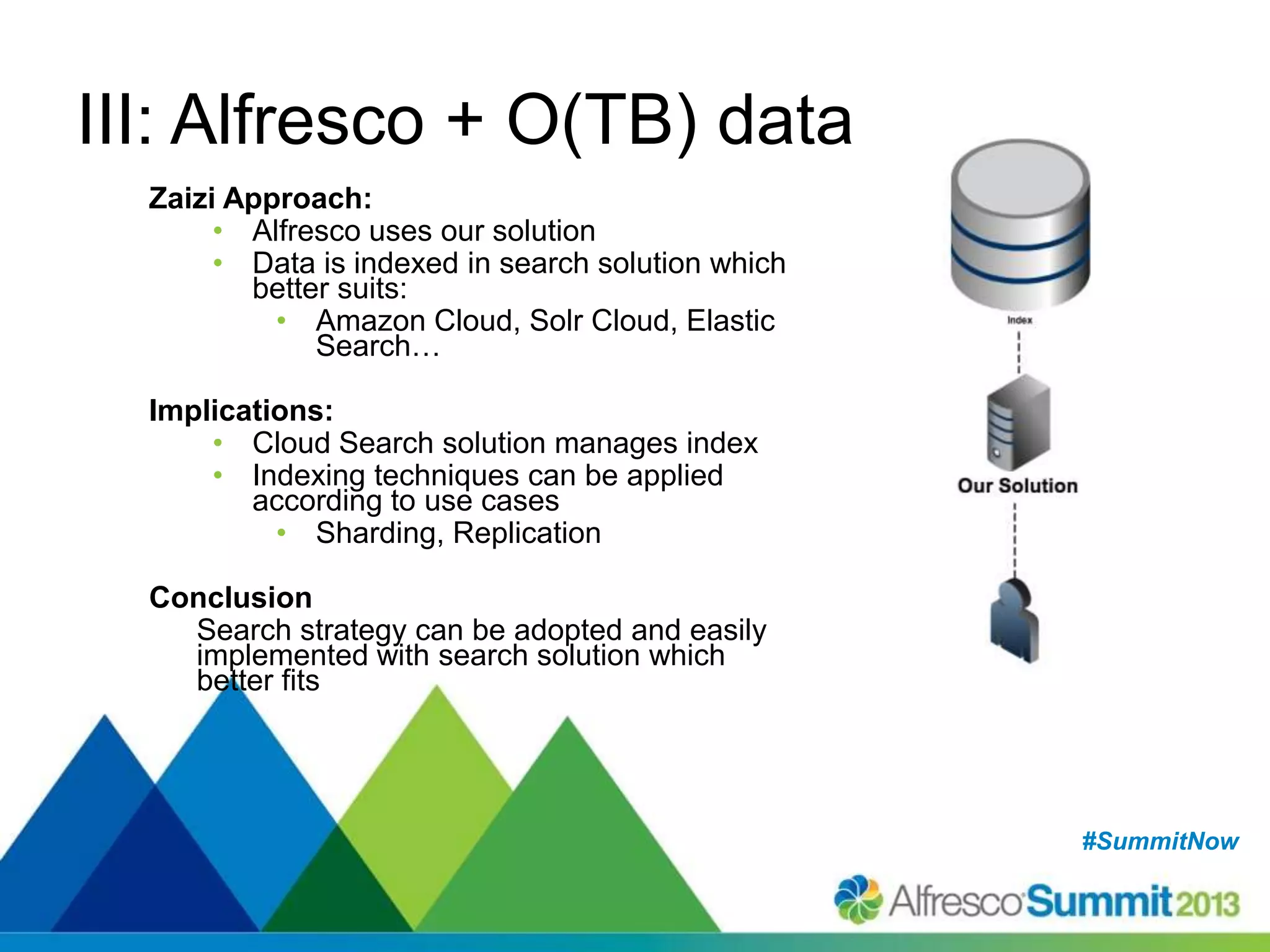



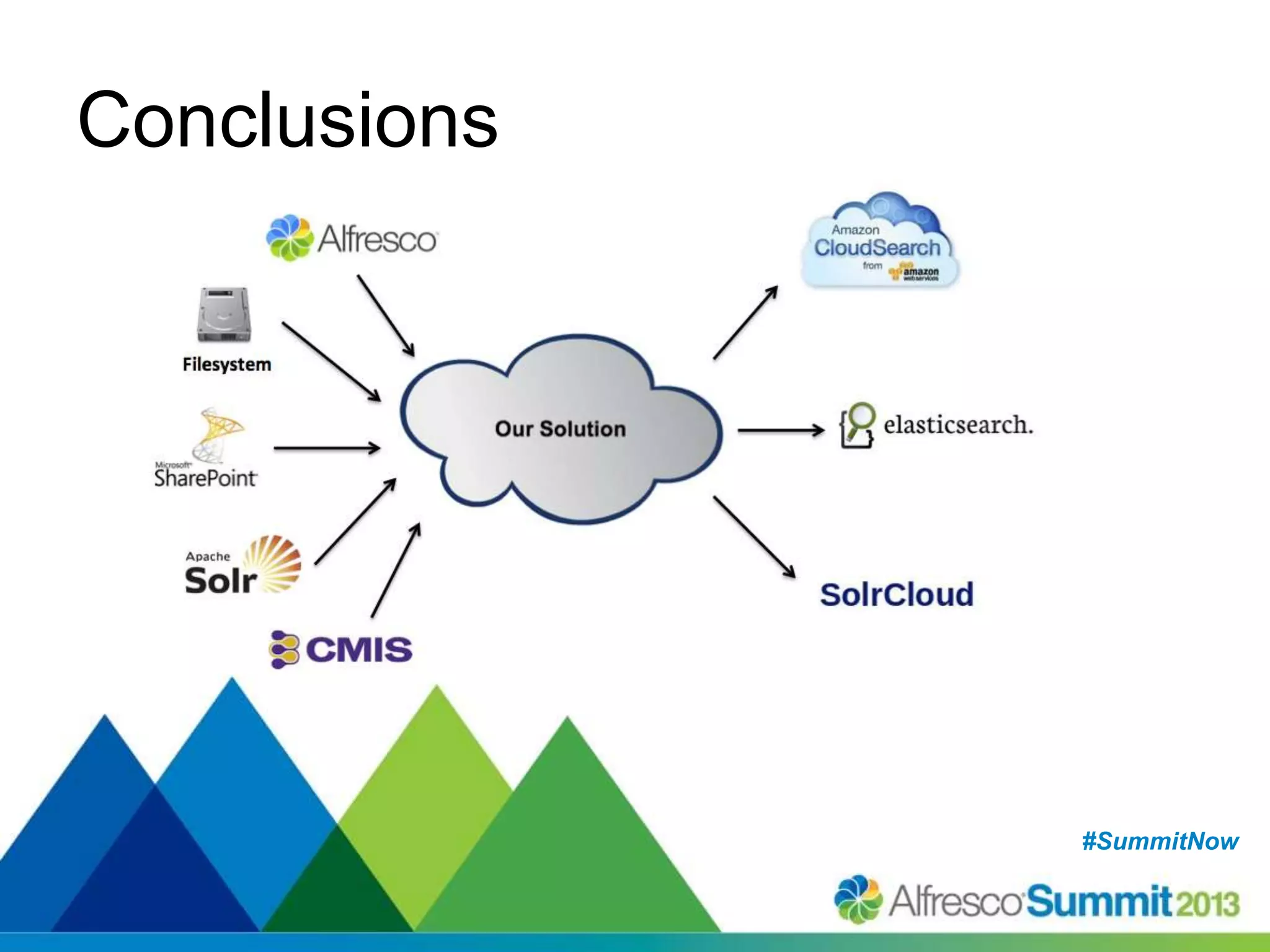
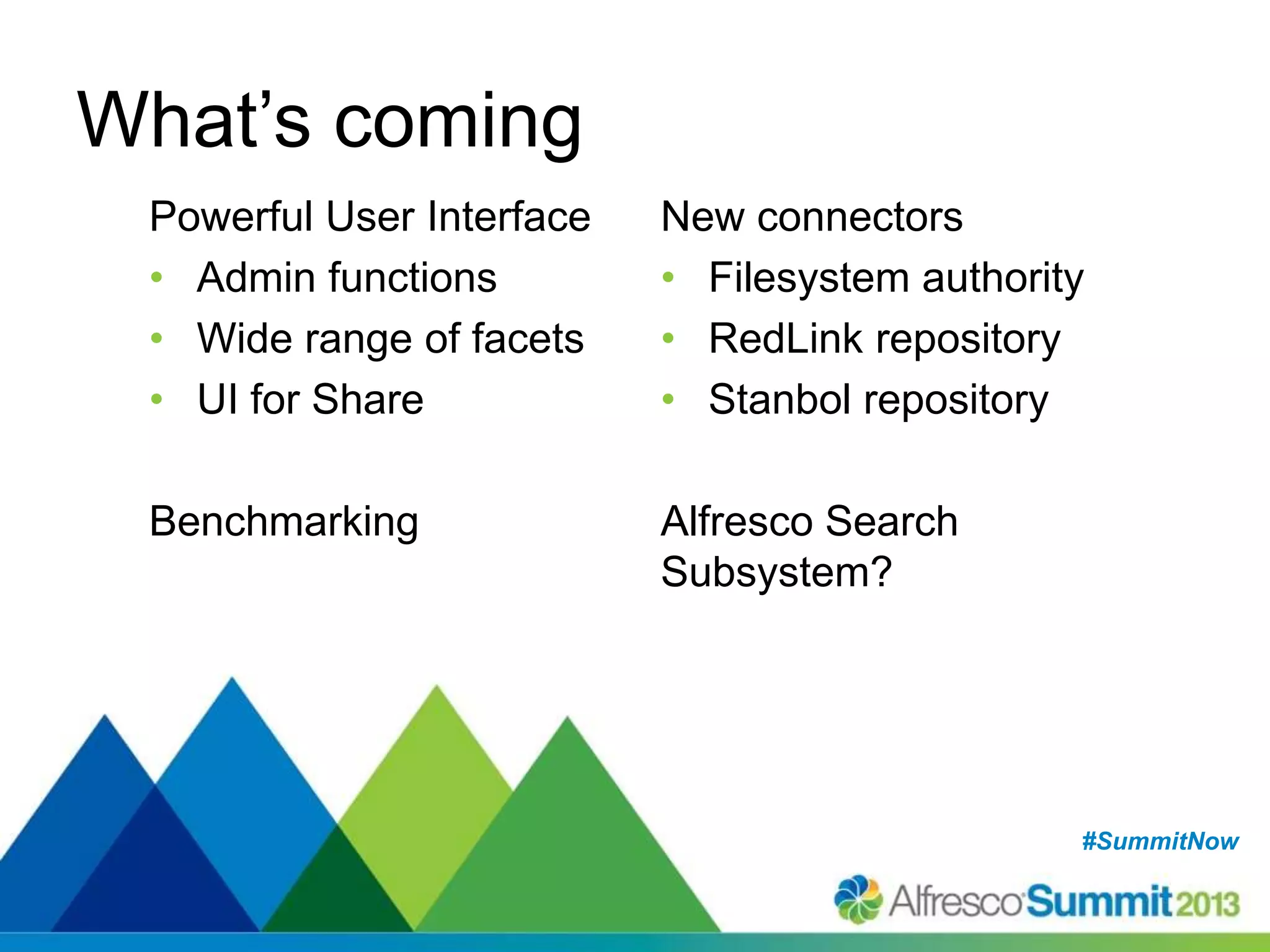


The document discusses strategies for enhancing search capabilities within Alfresco systems using Apache ManifoldCF and Zaizi solutions. It outlines various architectures, limitations of existing search solutions, and the benefits of integrating search engines like Solr and Elasticsearch, especially in multi-repository environments. Additionally, the document emphasizes the importance of maintaining security and permissions during indexing and retrieval processes.















































































