Download as PDF, PPTX


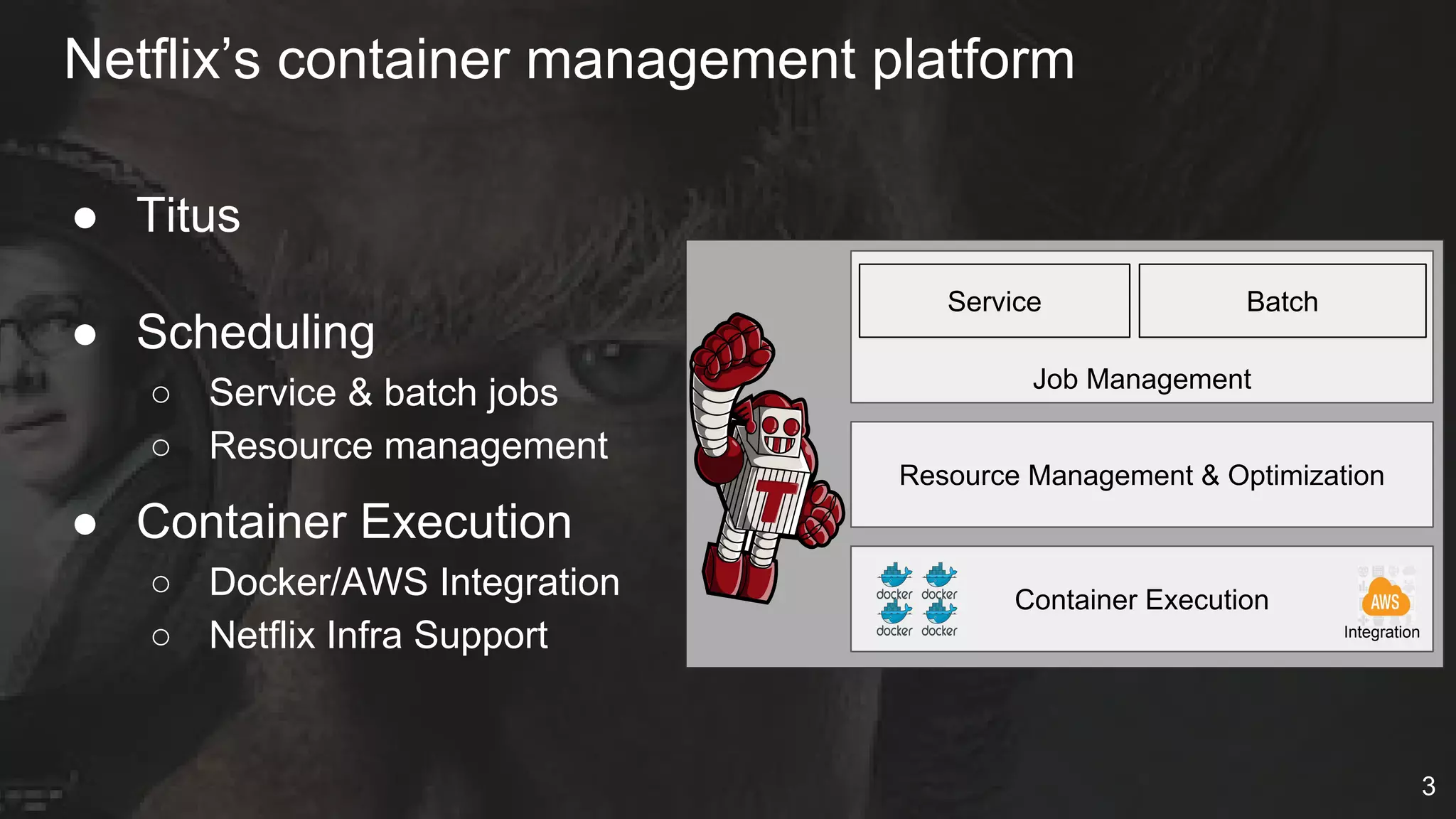





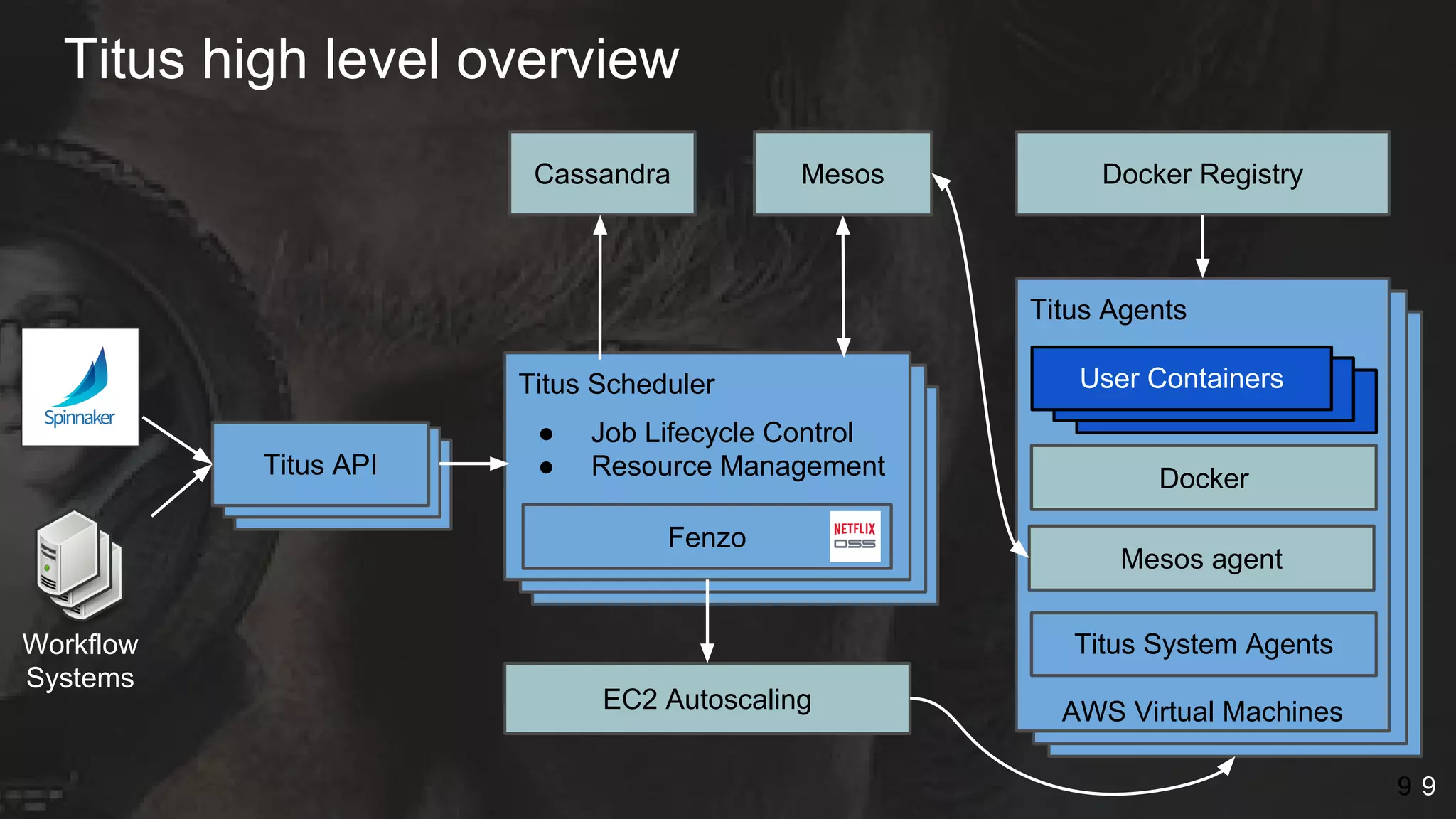


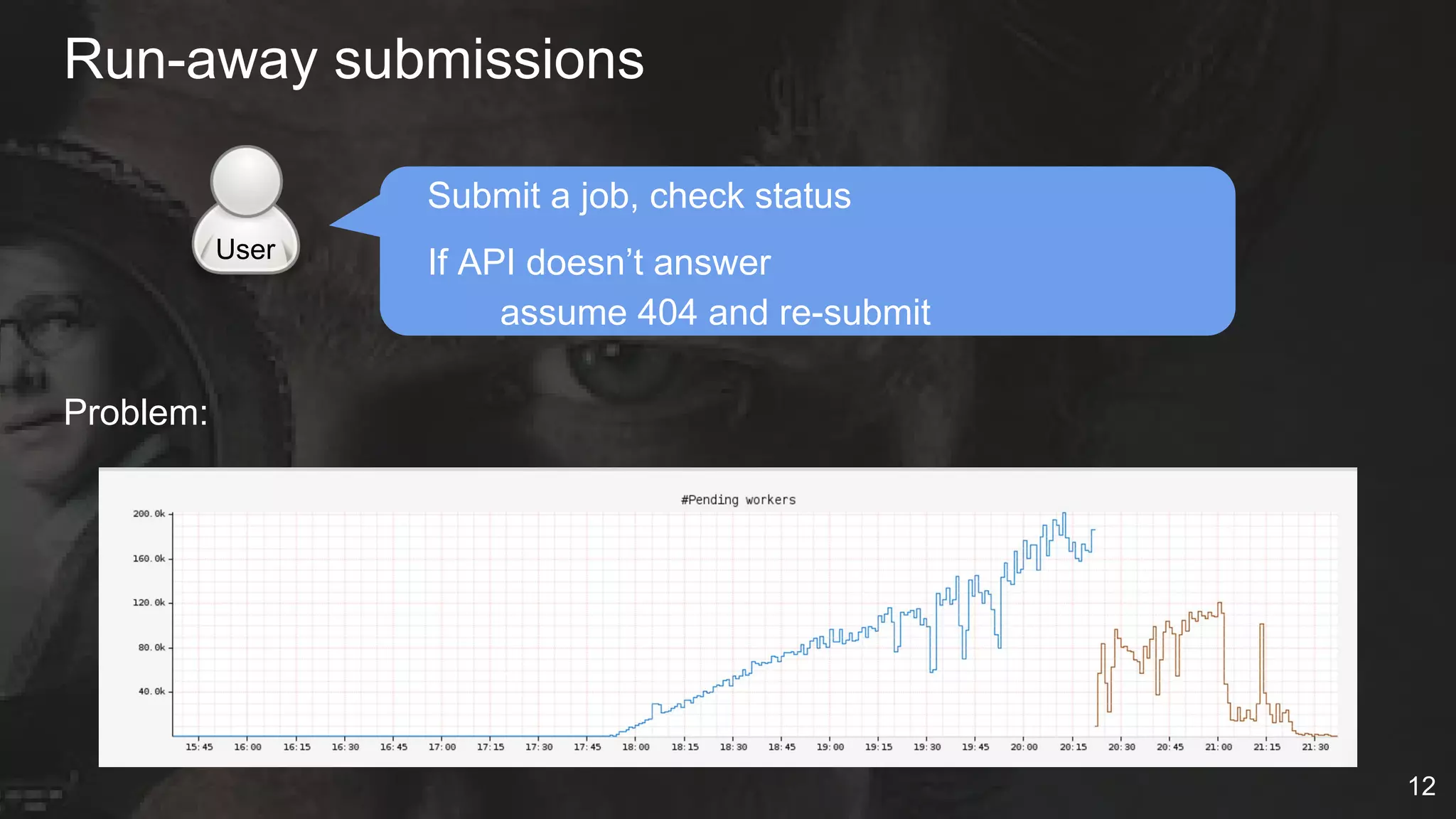

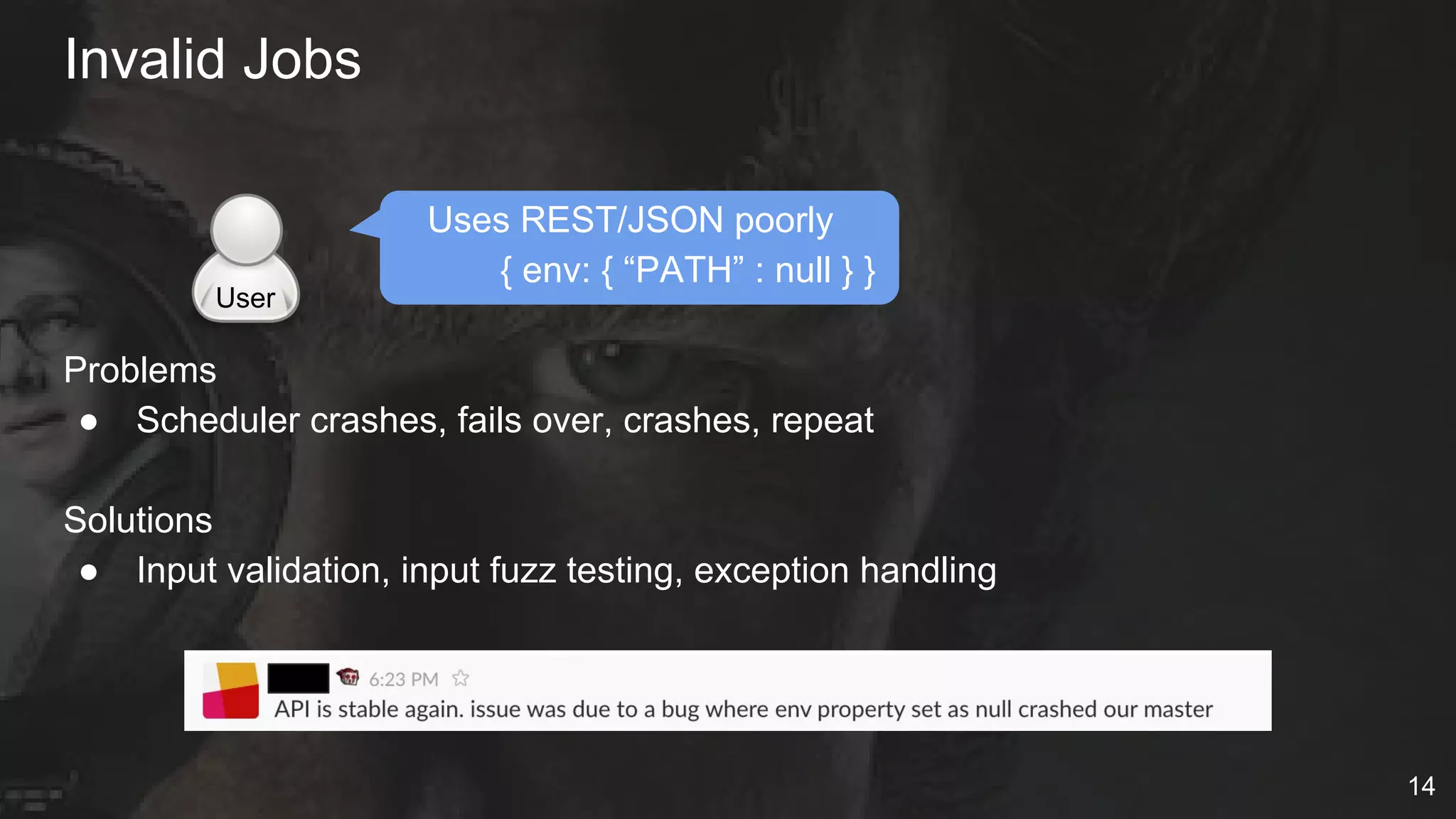
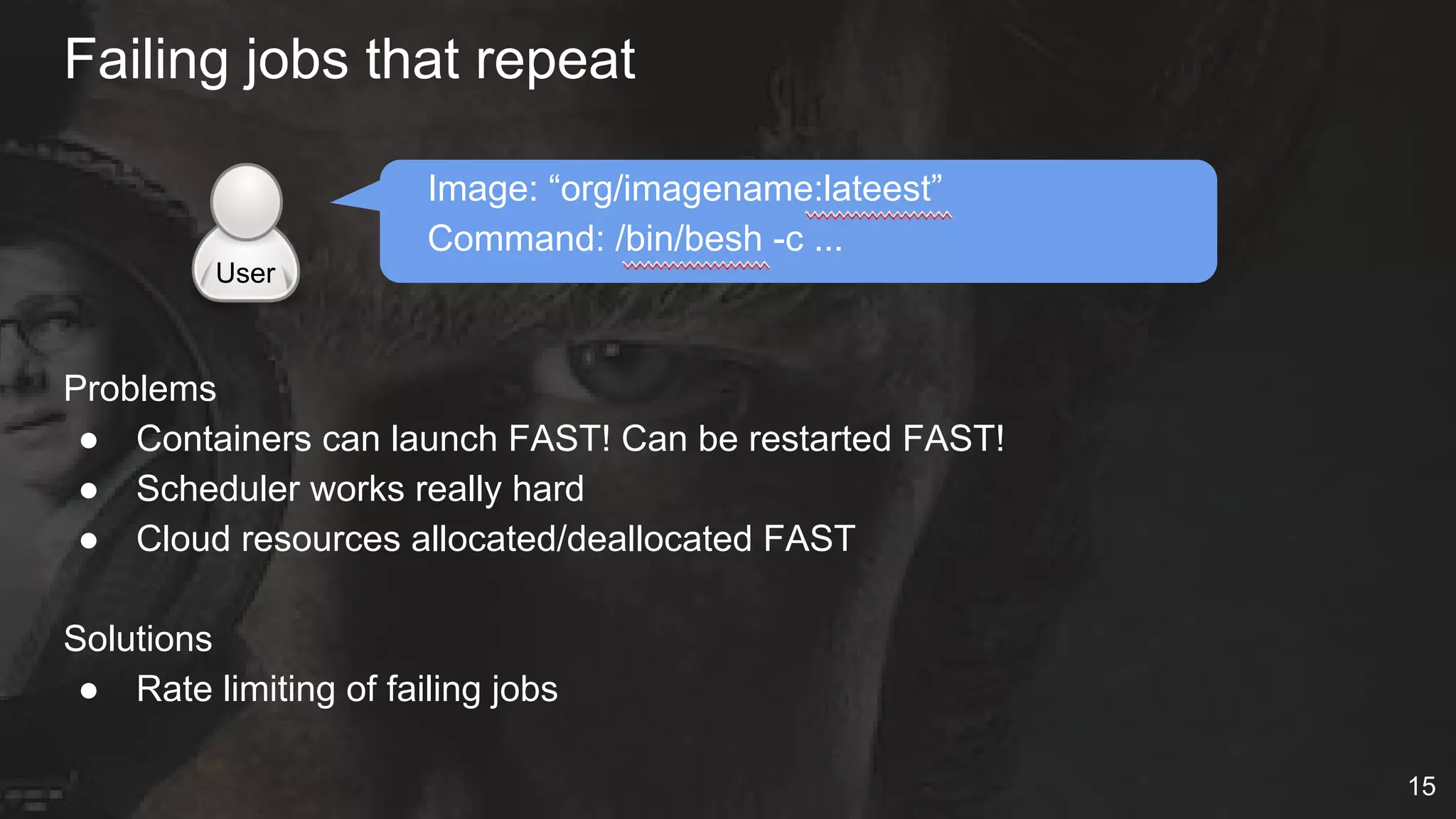
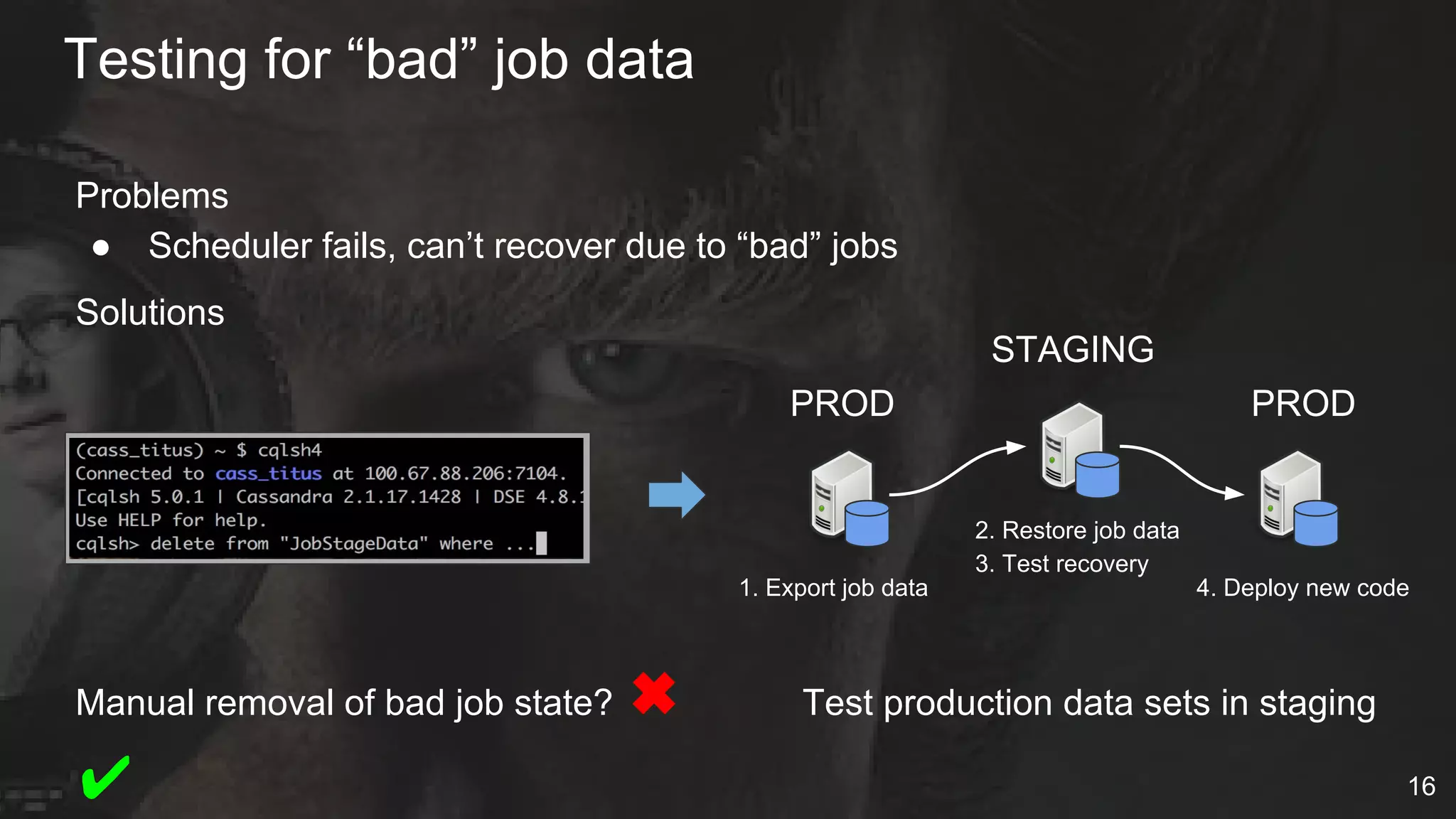



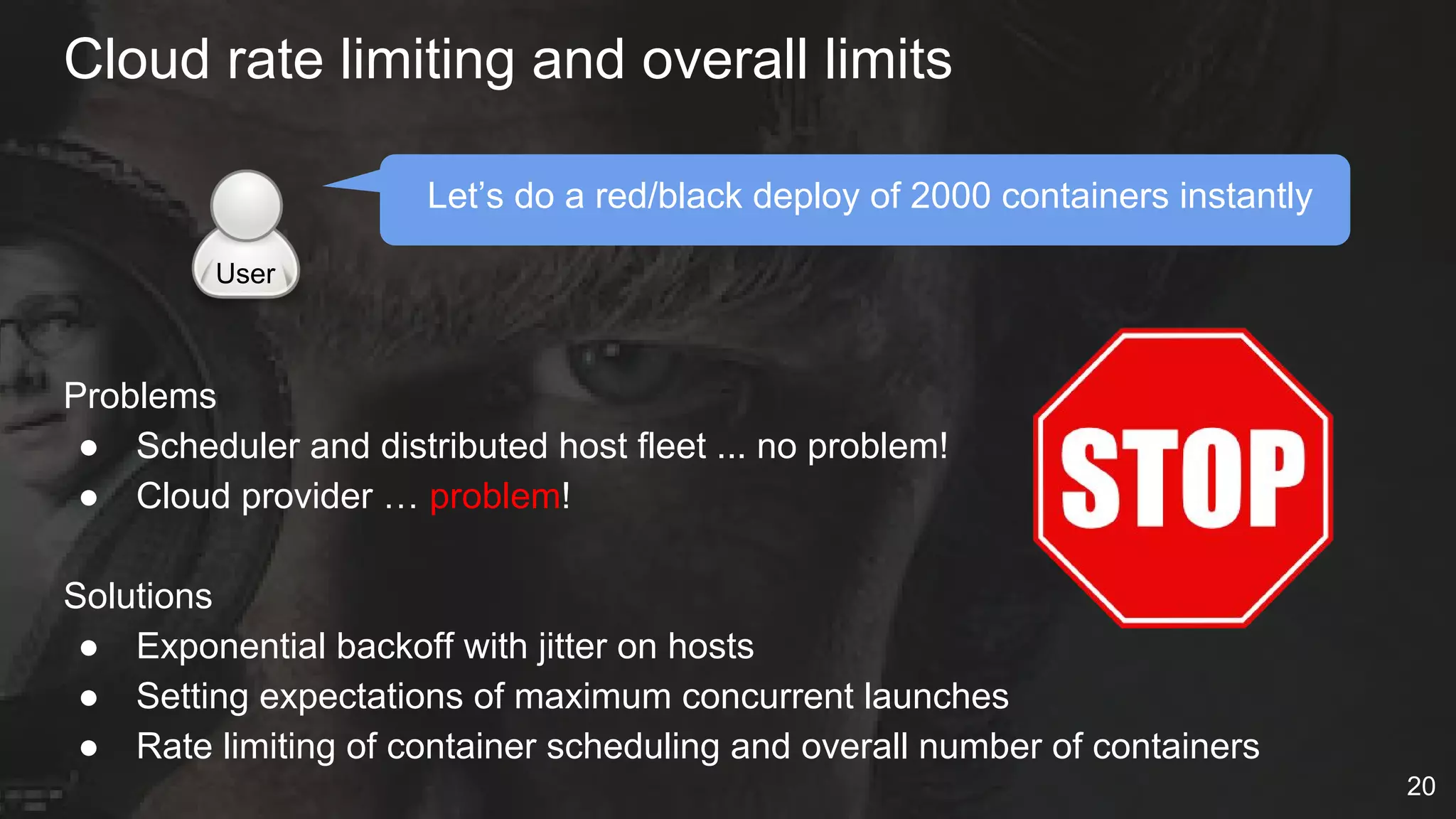











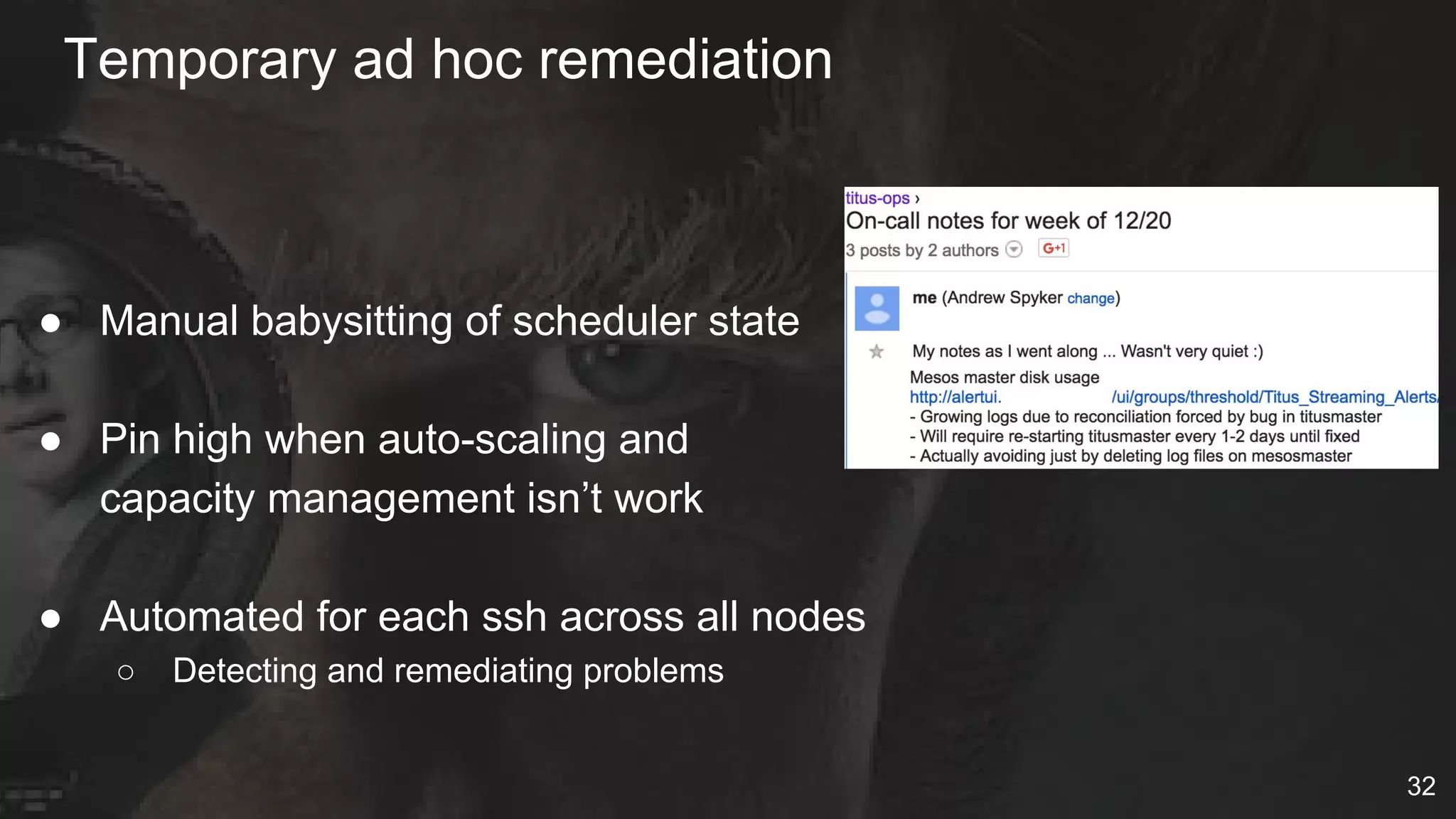



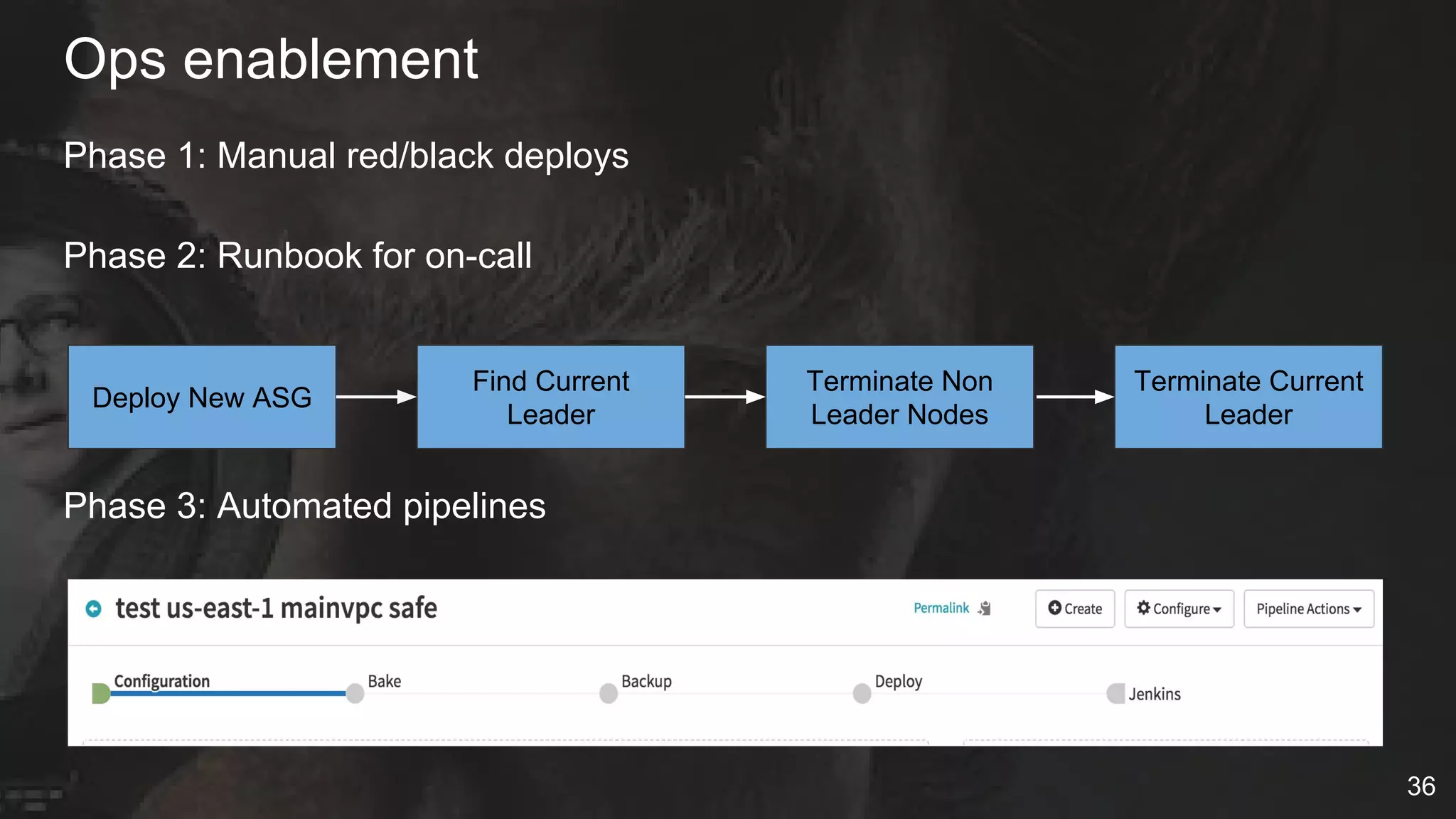
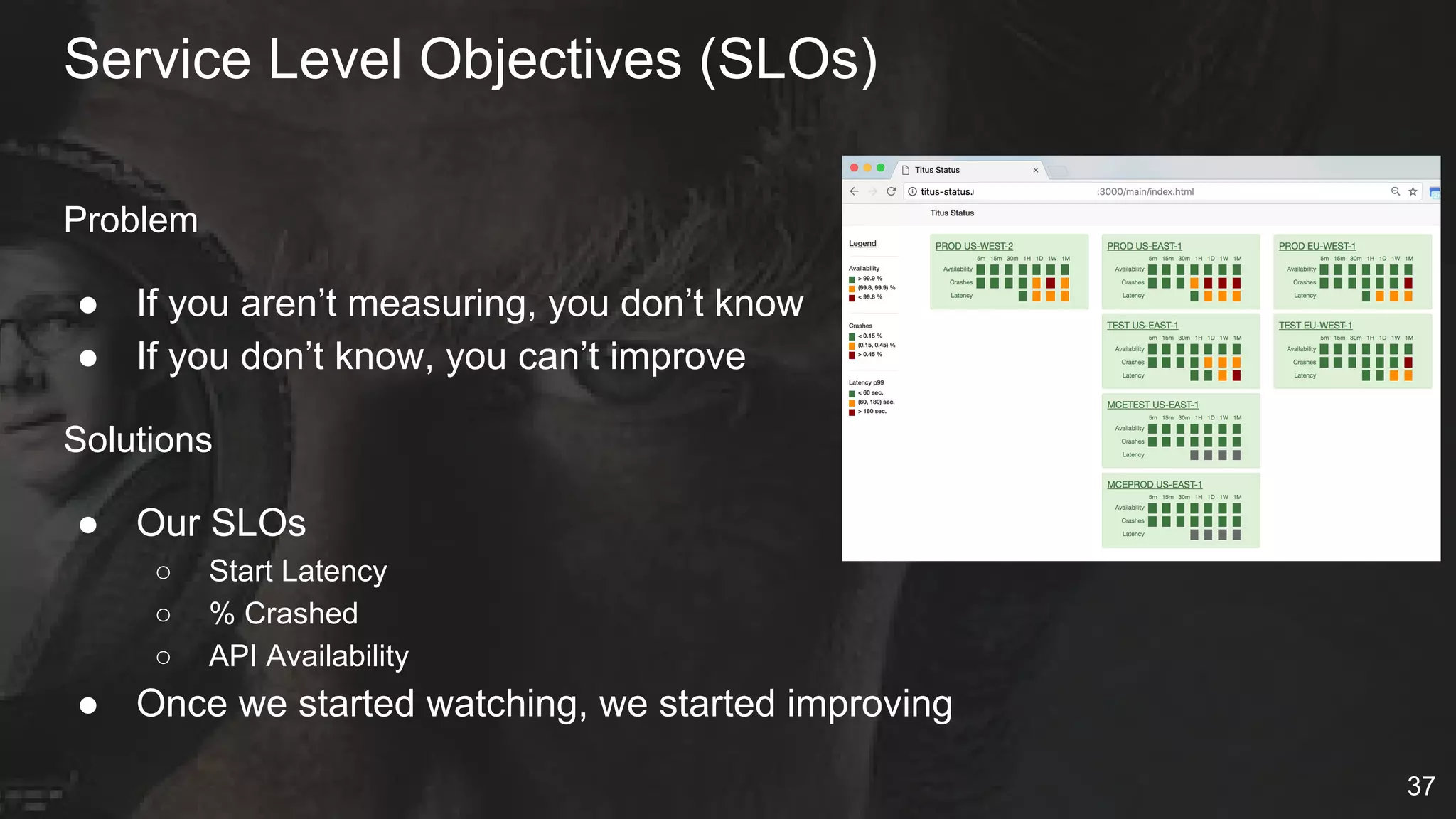








The document details Netflix's container management platform, Titus, outlining lessons learned from its production deployment, issues encountered, and solutions implemented. It emphasizes the complexities of container scheduling, management, and the challenges of integrating with AWS, alongside the importance of monitoring and alerting systems. Key takeaways highlight the necessity for operational enablement and the evolving nature of cloud environments to effectively support container workloads.






































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















