Download as KEY, PPTX


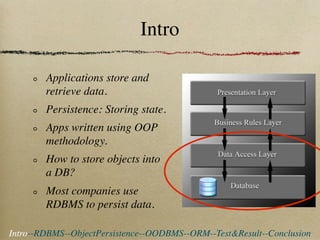














This document compares the performance of object databases and ORM tools for object persistence. It finds that object databases have easier setup and are faster for storing and retrieving complex objects. However, relational databases with ORM provide better configuration of domain models and easier reporting and data mining. Performance tests showed object databases were faster for create, store, traverse, and query operations while an ORM was slower, especially for queries.



































































