Download to read offline









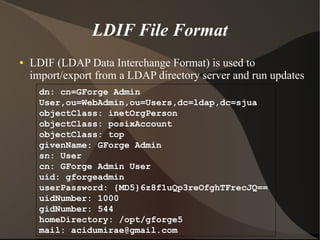






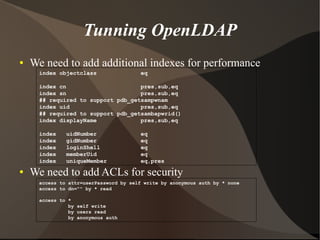


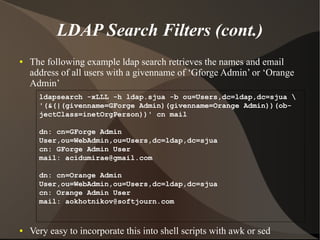





This document provides an overview of LDAP (Lightweight Directory Access Protocol). It discusses directory services and the need for LDAP, provides an introduction to LDAP including its benefits and basics, and covers setting up and tuning OpenLDAP as well as other LDAP tools and applications.


















![[Srijan Wednesday Webinar] Decoupled Demystified: The Present & Future of Dr...](https://cdn.slidesharecdn.com/ss_thumbnails/srijanwebinartemplatebypreston-170310083838-thumbnail.jpg?width=640&height=640&fit=bounds)