Downloaded 25 times







![SELECT
# SELECT * FROM test.test where id = 42;
use Net::HandlerSocket;
my $args = { host => 'master', port => 9998 };
my $hs = new Net::HandlerSocket($args);
my $res = $hs>open_index(0, 'test', 'test', 'PRIMARY', 'id,data,ts');
$res = $hs>execute_single(0, '=', [ '42' ], 1, 0);
shift(@$res);
for (my $row = 0; $row < 1; ++$row) {
print "$idt$datat$tsn";
}
$hs>close();
www.fromdual.com 9](https://image.slidesharecdn.com/mysqlnosql-120207101732-phpapp01/85/NoSQL-with-MySQL-9-320.jpg)



![SELECT
// SELECT * FROM cars;
const NdbDictionary::Dictionary* myDict= myNdb>getDictionary();
const NdbDictionary::Table *myTable= myDict>getTable("cars");
myTrans = myNdb>startTransaction();
myScanOp = myTrans>getNdbScanOperation(myTable);
myScanOp>readTuples(NdbOperation::LM_CommittedRead)
myRecAttr[0] = myScanOp>getValue("REG_NO");
myRecAttr[1] = myScanOp>getValue("BRAND");
myRecAttr[2] = myScanOp>getValue("COLOR");
myTrans>execute(NdbTransaction::NoCommit);
while ((check = myScanOp>nextResult(true)) == 0) {
std::cout << myRecAttr[0]>u_32_value() << "t";
std::cout << myRecAttr[1]>aRef() << "t";
std::cout << myRecAttr[2]>aRef() << std::endl;
}
myNdb>closeTransaction(myTrans);
www.fromdual.com 15](https://image.slidesharecdn.com/mysqlnosql-120207101732-phpapp01/85/NoSQL-with-MySQL-15-320.jpg)



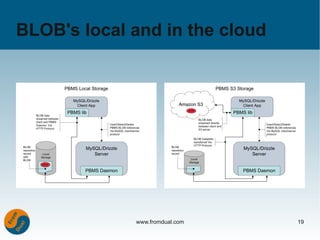













The document discusses several technologies for using MySQL as a NoSQL database system by bypassing SQL overhead: HandlerSocket allows direct access to indexes; the NDB API provides a NoSQL interface to MySQL Cluster; the BLOB Streaming Engine improves BLOB handling; the Handler Interface skips parsing and optimization; and the OQGRAPH storage engine enables graph queries and computations. Benchmarks show these techniques providing significant performance gains over standard SQL.




















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











