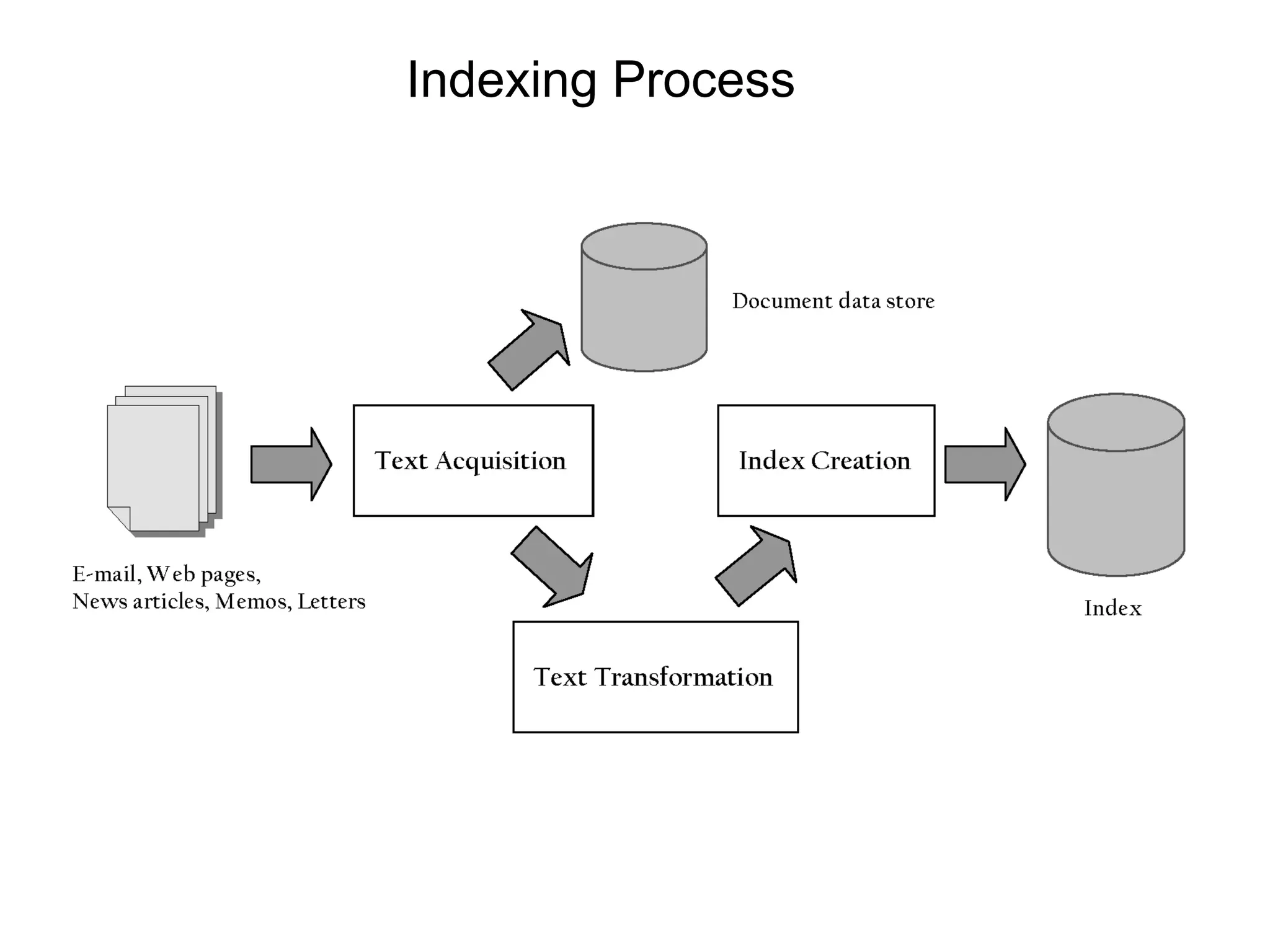
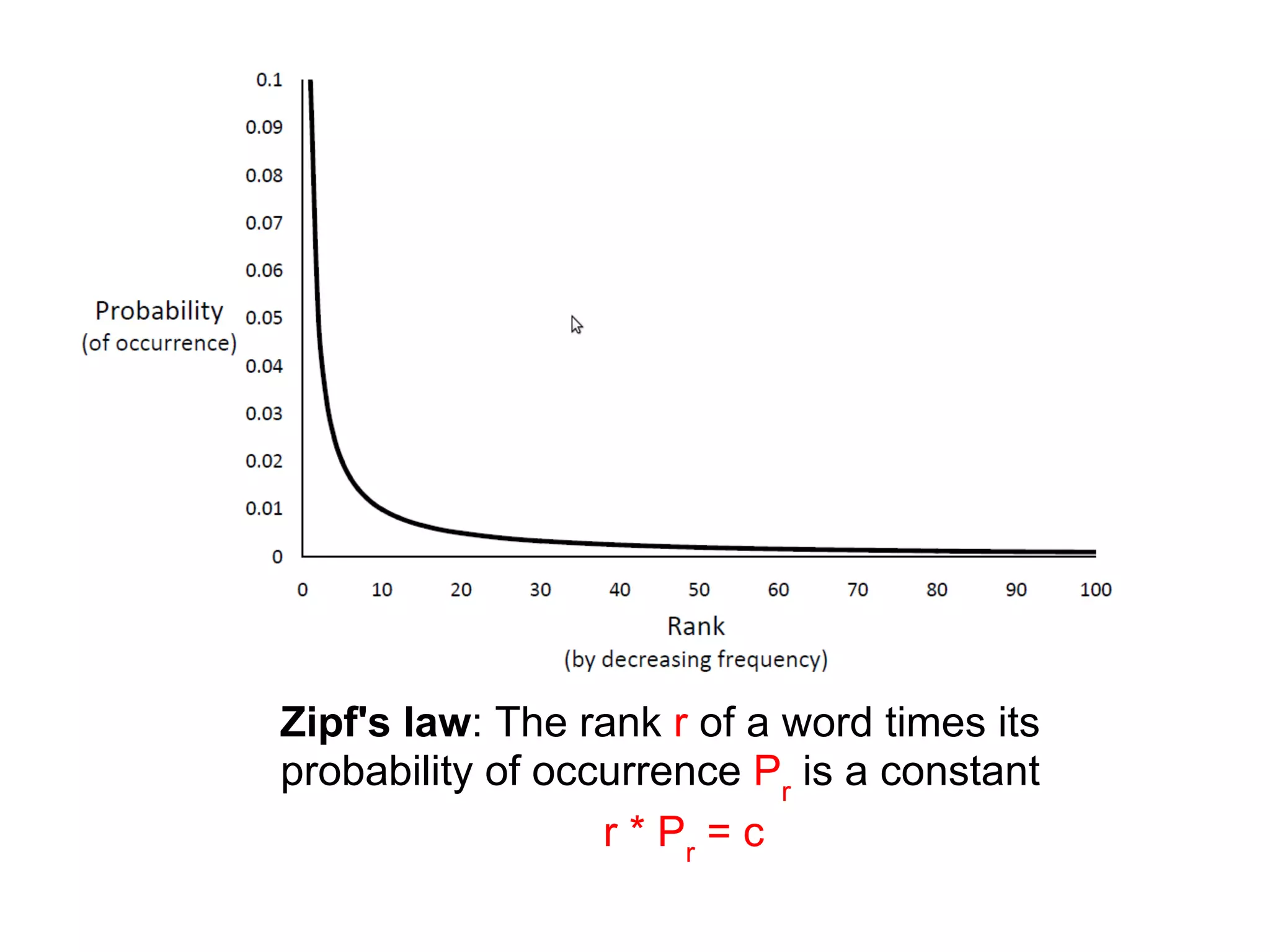
This document discusses the importance of text processing in information retrieval by transforming documents into index terms or features. It outlines key processes such as tokenization, stopping, stemming, and the use of phrases and n-grams to improve search efficiency and accuracy. The document also highlights the significance of document structure and statistical models in enhancing retrieval effectiveness.